本文希望通过《统计学习方法》 第六章的学习,由表及里地系统学习最大熵模型。文中使用Python实现了逻辑斯谛回归模型的3种梯度下降最优化算法,并制作了可视化动画。针对最大熵,提供一份简明的GIS最优化算法实现,并注解了一个IIS最优化算法的Java实现。
本文属于初学者的个人笔记,能力有限,无法对著作中的公式推导做进一步发挥,也无法保证自己的理解是完全正确的,特此说明,恳请指教
逻辑斯谛回归模型
逻辑斯谛分布
首先介绍逻辑斯谛分布,该分布的定义是
设X是连续随机变量,X服从逻辑斯谛分布是指X服从如下分布函数和密度函数:
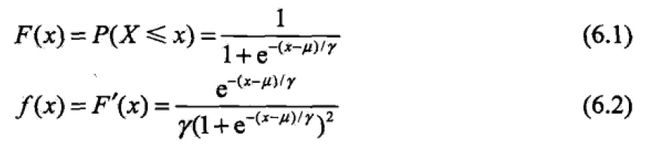
其中,u为位置参数,

> 0 为形状参数。
可以通过其图像观察:
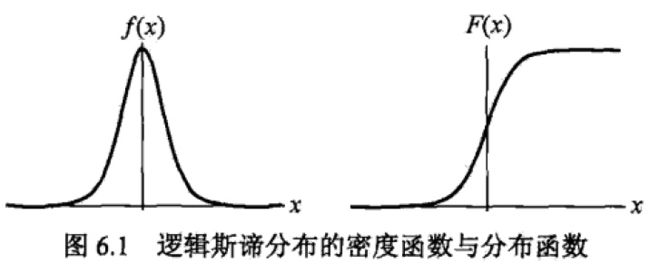
右边的逻辑斯蒂分布函数以点

中心对称,即满足:
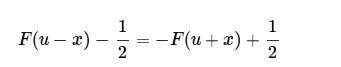
二项逻辑斯蒂回归模型
这是一种由条件概率表示的模型,其条件概率模型如下:
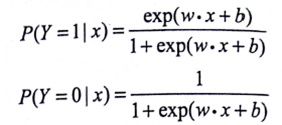
其中,exp为以e为底的指数函数,x∈Rn是输入,y∈{0,1}输出,w,b是模型参数——w是权值向量,b称作偏置,w·x是向量内积。
有了后验概率,逻辑斯蒂回归模型选择二分类中较大的那一个完成分类。
另外,逻辑斯特回归模型还有一个方便的形式,如果将权值向量w和输入向量x拓充为w=(w(1),w(2),…w(n),b)T,x=(x(1),…x(n),1)T,此时逻辑斯谛模型可以表示为:
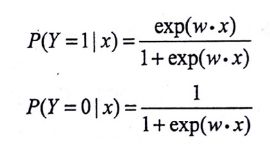
为什么要重新提一个形式出来呢?这是因为,这个形式跟几率的表达式很像。
定义事件的几率:发生概率与不发生概率的比值
定义对数几率:
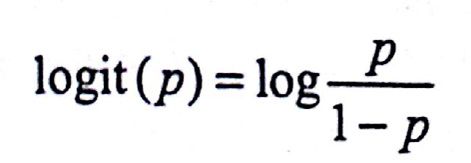
将逻辑斯蒂模型的便捷形式做一个变换恰好可以得到:
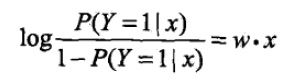
这也就是说,在逻辑斯蒂回归模型中,输出Y=1的对数几率是输入x的线性函数。或者说输出Y=1的对数几率是由输入x的线性函数表示的模型,即逻辑斯蒂回归模型。反过来讲,如果知道权值向量,给定输入x,就能求出Y=1的概率:
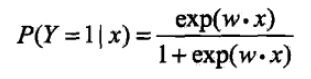
线性函数w·x的值越接近正无穷,概率值越接近1;反之,越接近负无穷,概率值越接近0——这就是逻辑斯谛回归模型。
模型参数估计
在模型学习的时候,对于给定训练集T = {(x1,y1)…(xN,yN)},x∈Rn,y∈{0,1}
设
定义似然函数
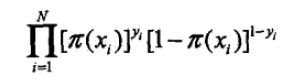
则有对数似然函数
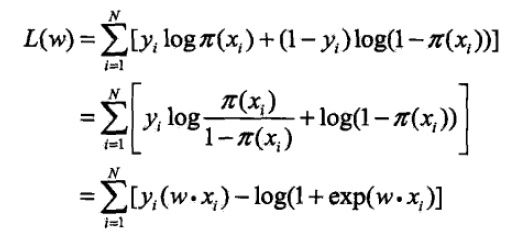
这个好说,把后面括号里的负π提到前面去就行了。
对L(w)求极大值就可以得出权值向量w的估计值。
解决以L(w)为目标函数的最优化问题的一般方法是梯度下降法及拟牛顿法,前者书上让参考附录,后者在后面会介绍。
逻辑斯谛回归实现
本着自己动手的良好习惯,这里参考《机器学习实战》中讲解,深入学习一下梯度下降最优化算法。
不过写代码之前,还是得先有数据才行。
测试数据
《机器学习实战》中给出了一个testSet.txt:
-0.017612 14.053064 0
-1.395634 4.662541 1
-0.752157 6.538620 0
-1.322371 7.152853 0
0.423363 11.054677 0
0.406704 7.067335 1
0.667394 12.741452 0
-2.460150 6.866805 1
0.569411 9.548755 0
-0.026632 10.427743 0
每一列分别代表X0、X1、Y。
加载代码如下:
def loadDataSet():
"""
加载数据集
:return:输入向量矩阵和输出向量
"""
dataMat = []; labelMat = []
fr = open('testSet.txt')
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])]) #X0设为1.0,构成拓充后的输入向量
labelMat.append(int(lineArr[2]))
return dataMat,labelMat
注意,代码中并不是按照上述w=(w(1),w(2),…w(n),b)T,x=(x(1),…x(n),1)T进行拓展的,而是w=(b,w(1),w(2),…w(n))T,x=(1,x(1),…x(n))T。
可以利用如下代码进行可视化:
def plotBestFit(weights):
"""
画出数据集和逻辑斯谛最佳回归直线
:param weights:
"""
import matplotlib.pyplot as plt
dataMat,labelMat=loadDataSet()
dataArr = array(dataMat)
n = shape(dataArr)[0]
xcord1 = []; ycord1 = []
xcord2 = []; ycord2 = []
for i in range(n):
if int(labelMat[i])== 1:
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
if weights is not None:
x = arange(-3.0, 3.0, 0.1)
y = (-weights[0]-weights[1]*x)/weights[2] #令w0*x0 + w1*x1 + w2*x2 = 0,其中x0=1,解出x1和x2的关系
ax.plot(x, y) #一个作为X一个作为Y,画出直线
plt.xlabel('X1'); plt.ylabel('X2');
plt.show()
现在还没有训练,所以直接传None进去:
plotBestFit(None)
梯度下降算法
在《机器学习实战》中,称求函数最小值的时候用的是梯度下降算法,而此处求的是对数似然函数的最大值,所以应该称为梯度上升算法。其实梯度下降算法在《感知机》里也有涉及,此处再次复习。
函数的梯度由其偏导数构成:
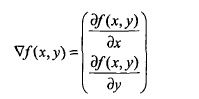

梯度是函数增长最快的方向,记移动补偿为α,则梯度算法的迭代公式为:
假定权值向量w有了,怎么计算模型输出呢?
特征向量乘以权值向量得出一个实数z
希望通过该实数输出一个0或1的类别,这时候就需要利用Sigmoid函数了:
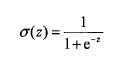
其图像如下:

将该实数代入Sigmoid函数后,得到一个0~1之间的数,大于0.5归入1,小于0.5归入0即可。
利用Sigmoid函数,梯度上升算法的伪码如下:

参考《机器学习实战》,加了一些注释的代码:
from numpy import *
def sigmoid(inX):
return 1.0/(1+exp(-inX))
def gradAscent(dataMatIn, classLabels):
"""
逻辑斯谛回归梯度上升优化算法
:param dataMatIn:输入X矩阵(100*3的矩阵,每一行代表一个实例,每列分别是X0 X1 X2)
:param classLabels: 输出Y矩阵(类别标签组成的向量)
:return:权值向量
"""
dataMatrix = mat(dataMatIn) #转换为 NumPy 矩阵数据类型
labelMat = mat(classLabels).transpose() #转换为 NumPy 矩阵数据类型
m,n = shape(dataMatrix) #矩阵大小
alpha = 0.001 #步长
maxCycles = 500
weights = ones((n,1))
for k in range(maxCycles): #最大迭代次数
h = sigmoid(dataMatrix*weights) #矩阵内积
error = (labelMat - h) #向量减法
weights += alpha * dataMatrix.transpose() * error #矩阵内积
return weights
调用方法:
dataArr, labelMat = loadDataSet()
weights = gradAscent(dataArr, labelMat)
plotBestFit(weights)
还可以更生动吗?可以,借助《Matplotlib和Imagemagick》,我们可以将权值向量的变化做成动画,更加感性地将梯度上升算法展示出来:
# -*- coding:utf-8 -*-
# Filename: gradDescent.py
# Author:hankcs
# Date: 2015/2/4 15:01
from matplotlib import pyplot as plt
from matplotlib import animation
from numpy import *
def loadDataSet():
"""
加载数据集
:return:输入向量矩阵和输出向量
"""
dataMat = []; labelMat = []
fr = open('testSet.txt')
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])]) #X0设为1.0,构成拓充后的输入向量
labelMat.append(int(lineArr[2]))
return dataMat,labelMat
def sigmoid(inX):
return 1.0/(1+exp(-inX))
def gradAscent(dataMatIn, classLabels, history_weight):
"""
逻辑斯谛回归梯度上升优化算法
:param dataMatIn:输入X矩阵(100*3的矩阵,每一行代表一个实例,每列分别是X0 X1 X2)
:param classLabels: 输出Y矩阵(类别标签组成的向量)
:return:权值向量
"""
dataMatrix = mat(dataMatIn) #转换为 NumPy 矩阵数据类型
labelMat = mat(classLabels).transpose() #转换为 NumPy 矩阵数据类型
m,n = shape(dataMatrix) #矩阵大小
alpha = 0.001 #步长
maxCycles = 500
weights = ones((n,1))
for k in range(maxCycles): #最大迭代次数
h = sigmoid(dataMatrix*weights) #矩阵内积
error = (labelMat - h) #向量减法
weights += alpha * dataMatrix.transpose() * error #矩阵内积
history_weight.append(copy(weights))
return weights
history_weight = []
dataMat,labelMat=loadDataSet()
gradAscent(dataMat, labelMat, history_weight)
fig = plt.figure()
currentAxis = plt.gca()
ax = fig.add_subplot(111)
line, = ax.plot([], [], 'b', lw=2)
def draw_line(weights):
x = arange(-5.0, 5.0, 0.1)
y = (-weights[0]-weights[1]*x)/weights[2] #令w0*x0 + w1*x1 + w2*x2 = 0,其中x0=1,解出x1和x2的关系
line.set_data(x, y)
return line,
# initialization function: plot the background of each frame
def init():
dataArr = array(dataMat)
n = shape(dataArr)[0]
xcord1 = []; ycord1 = []
xcord2 = []; ycord2 = []
for i in range(n):
if int(labelMat[i])== 1:
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2])
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
plt.xlabel('X1'); plt.ylabel('X2');
return draw_line(zeros((n,1)))
# animation function. this is called sequentially
def animate(i):
return draw_line(history_weight[i])
# call the animator. blit=true means only re-draw the parts that have changed.
anim = animation.FuncAnimation(fig, animate, init_func=init, frames=len(history_weight), interval=10, repeat=False,
blit=True)
plt.show()
anim.save('gradAscent.gif', fps=2, writer='imagemagick')
可视动画:
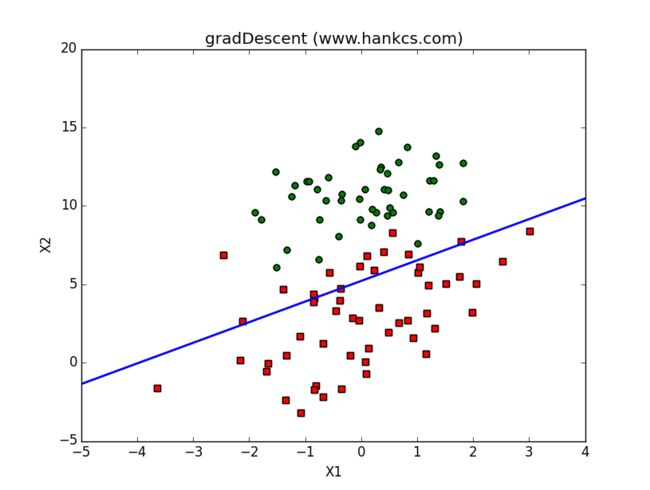
随机梯度上升算法
梯度下降算法在每次更新权值向量的时候都需要遍历整个数据集,该方法对小数据集尚可。但如果有数十亿样本和成千上万的特征时,它的计算复杂度就太高了。一种改进的方法是一次仅用一个样本点的回归误差来更新权值向量,这个方法叫随机梯度下降算法。由于可以在遇到新样本的时候再对分类器进行增量式更新,所以随机梯度上升算法是一个在线学习算法;与此对应,一次处理完所有数据的算法(如梯度上升算法)被称作“批处理”。
随机梯度上升算法的伪代码:

Python实现:
def stocGradAscent0(dataMatrix, classLabels, history_weight):
"""
随机梯度上升算法
:param dataMatIn:输入X矩阵(100*3的矩阵,每一行代表一个实例,每列分别是X0 X1 X2)
:param classLabels: 输出Y矩阵(类别标签组成的向量)
:return:权值向量
"""
dataMatrix = array(dataMatrix)
m,n = shape(dataMatrix)
alpha = 0.01
weights = ones(n) #初始化为单位矩阵
for i in range(m):
h = sigmoid(sum(dataMatrix[i]*weights)) #挑选(伪随机)第i个实例来更新权值向量
error = classLabels[i] - h
weights = weights + dataMatrix[i] * alpha * error
history_weight.append(copy(weights))
return weights
可见随机梯度上升算法中h和error都是数值,没有进行复杂的矩阵运算。
可视化:
将原程序中的gradAscent换成stocGradAscent0,得出如下结果——

可以看到,最终拟合出来的直线效果并不如梯度上升算法,大约错了1/3的样本。
不过这种比较并不公平,毕竟随机梯度上升算法每次迭代的复杂度小得多,而且也只迭代了样本个数(200)次。
改进的随机梯度上升算法
既然随机梯度上升算法最终给出的参数不好,那是否仅仅是因为参数没有足够收敛,而算法本质是优秀的呢?对此,可以逐步减小步长,避免参数周期性的抖动。
Python代码:
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
"""
改进的随机梯度上升算法
:param dataMatIn:输入X矩阵(100*3的矩阵,每一行代表一个实例,每列分别是X0 X1 X2)
:param classLabels: 输出Y矩阵(类别标签组成的向量)
:param numIter: 迭代次数
:return:
"""
dataMatrix = array(dataMatrix)
m,n = shape(dataMatrix)
weights = ones(n) #初始化为单位矩阵
for j in range(numIter):
dataIndex = range(m)
for i in range(m):
alpha = 4/(1.0+j+i)+0.0001 #步长递减,但是由于常数存在,所以不会变成0
randIndex = int(random.uniform(0,len(dataIndex))) #总算是随机了
h = sigmoid(sum(dataMatrix[randIndex]*weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * dataMatrix[randIndex]
del(dataIndex[randIndex]) #删除这个样本,以后就不会选到了
return weights
可视化:
发现拟合直线抖动得非常狂野,但最终效果还是不错的(图大杀猫)——

三者的收敛速度如图:

最大熵模型
最大熵原理
首先还是不厌其烦地介绍熵的定义
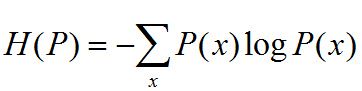
熵满足以下不等式:
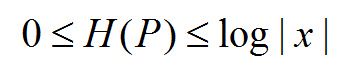
|X|为X取值个数,仅当X均匀分布时,右等号成立,熵最大。
熵反应的是事物的无序程度,或者说随机变量分布的均匀程度。直观地讲,最大熵原理认为,在所有可能的概率模型(分布)中,熵最大的模型是最好的模型。也就是说,在那些满足已有事实(或约束条件)的概率模型中,那些不确定的部分都是无序的、混乱的、等可能的、均匀分布的。这个“等可能、混乱”只是个感性的词语,需要一个量化的标准,这个标准就是熵。
用一个例子介绍最大熵原理——
例 6.1 随机变量X取值{A,B,C,D,E},要估计各值的概率P(A),P(B)…
解:
约束条件:P(A)+P(B)+P(C)+P(D)+P(E)=1
满足条件的分布有无穷多,一个办法认为等可能的 §P(A)=P(B)=P(C)=P(D)=P(E)=1/5
有时,能从先验知识得到一些约束条件,如:
P(A)+P(B)=3/10 -> P(A)=P(B)=3/20
P(A)+P(B)+P(C)+P(D)+P(E)=1 -> P(C)=P(D)=P(E)=7/30
这时认为A,B等可能,C,D,E等可能。 以此类推,如果有3个约束条件等,以上模型学习方法正是遵循了最大熵原理
最大熵模型的定义
将最大熵原理应用于分类就得到了最大熵模型。
假设分类模型是一个条件概率分布P(Y|X),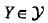
分别表示输入和输出集合。该模型表示的是对于给定的输入X,以条件概率P(Y|X)输出Y。
给定一个训练数据集
学习的目标是用最大熵原理选择最好的分类模型。
首先,模型必需满足联合分布P(X,Y)的经验分布和边缘分布P(X)的经验分布,即
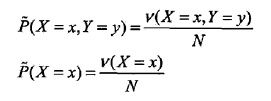
其中,v(X=x,Y=y)表示T中(x,y)出现频数,v(X=x)表示x出现的频数,N表示样本容量。
用特征函数f(x,y)定义x,y之间某一事实,其定义是:

这是一个二值函数,接受x和y作为参数,输出0或1。
特征函数f(x,y)关于经验分布表示。
表示。
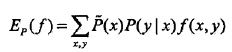
如果模型能获取训练数据中的规律的话,那么这两个期望应该是相等的,也即
或

这个式子就是最大熵模型学习的约束条件,如果有n个特征函数,那么就有n个这样的约束条件。
最大熵模型的定义 假设满足约束条件的模型集合为
定义在条件概率分布P(Y|X)上的条件熵为
则模型集合C中条件熵H(P)最大的模型称为最大熵模型。
最大熵模型的学习
最大熵模型的学习可以形式化为约束最优化问题。
给定训练数据集和特征函数fi(x,y),最大熵模型的学习等价于约束最优化问题:
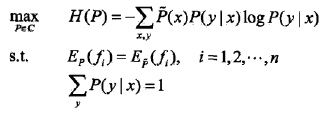
等价于求最小值问题:
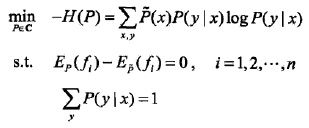
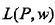
:
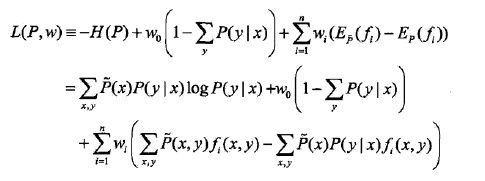
注意每个w乘上的部分恰好都是为0的约束。
最优化的原始问题是
对偶问题是
《统计学习方法》介绍说由于拉格朗日函数是P的凸函数,所以可以做这种等价。这样,就可以通过求解对偶问题来求解原始问题了。
首先,求解对偶问题内部的极小化问题是w的函数,将其记作

称为对偶函数,同时,将其解记作
对P的偏导数
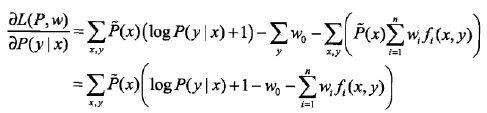
令偏导数等于0,又因为经验分布P(x)肯定大于0,所以解得

,右边等于Zw(x)/exp(1-w0),其中

于是exp(1-w0)=Zw(x),将这个式子代入上面的分母,就得到了最大熵模型
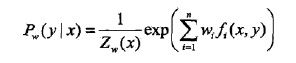
是特征函数;wi是特征的权重,所有的从1到n的wi构成最大熵模型中的参数向量w。
之后,求解对偶问题外部的极大化问题
将其解记为w*,即
的极大化。
极大似然估计
最大熵模型可以表示为两个式子表示的条件概率分布:

其中
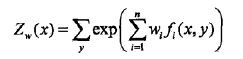
下面证明对偶函数的极大化等价于最大熵模型的极大似然估计。
已知训练数据的经验概率分布,那么条件概率分布P(Y|X)的对数似然函数表示为
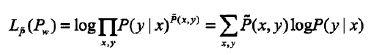
为
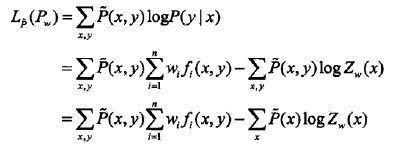
,由以下两个式子
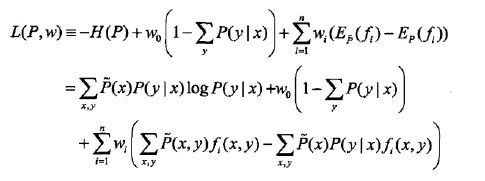
和
可得
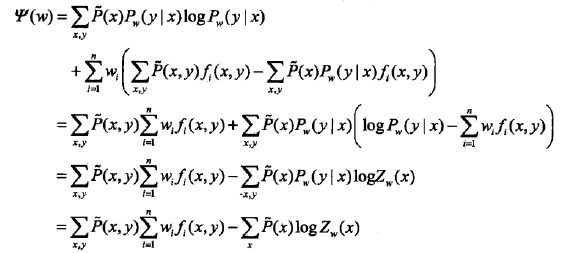
。
推到这一步,发现一摸一样,于是有
这说明最大熵模型学习中的对偶函数极大化等价于最大熵模型的极大似然估计。
所以最大熵模型的学习问题就转换为求解对偶函数极大化的问题。可以将最大熵模型写成更一般的形式。
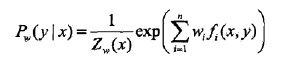
其中
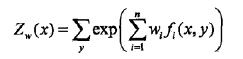
最大熵模型和逻辑斯蒂模型有类似的形式,它们又称为对数线性模型。模型学习就是在给定的训练数据条件下对模型进行极大似然估计或者正则化的极大似然估计。
模型学习的最优化算法
常用的方法有改进的迭代尺度法、梯度下降法、牛顿法或拟牛顿法,牛顿法或拟牛顿法一般收敛速度更快。
Generalized Iterative Scaling
已知最大熵模型为
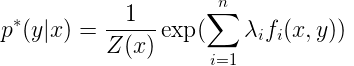
其中,
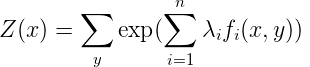
GIS的算法流程如下:
1. 初始化所有λi 为任意值,一般可以设置为0,即:
初始化.gif
其中λ的上标(t)表示第t论迭代,下标i表示第i个特征,n是特征总数。
2. 重复下面的权值更新直至收敛:
权值更新.gif
收敛的判断依据可以是λi 前后两次的差价足够小。其中C一般取所有样本数据中最大的特征数量
一份简明的Python实现(作者为fuqingchuan,请参考Reference):
# -*- coding:utf-8 -*-
# Filename: maxent.py
# Author:hankcs
# Date: 2015/10/2 23:23
import sys
import math
from collections import defaultdict
class MaxEnt:
def __init__(self):
self._samples = [] #样本集, 元素是[y,x1,x2,...,xn]的元组
self._Y = set([]) #标签集合,相当于去重之后的y
self._numXY = defaultdict(int) #Key是(xi,yi)对,Value是count(xi,yi)
self._N = 0 #样本数量
self._n = 0 #特征对(xi,yi)总数量
self._xyID = {} #对(x,y)对做的顺序编号(ID), Key是(xi,yi)对,Value是ID
self._C = 0 #样本最大的特征数量,用于求参数时的迭代,见IIS原理说明
self._ep_ = [] #样本分布的特征期望值
self._ep = [] #模型分布的特征期望值
self._w = [] #对应n个特征的权值
self._lastw = [] #上一轮迭代的权值
self._EPS = 0.01 #判断是否收敛的阈值
def load_data(self, filename):
for line in open(filename, "r"):
sample = line.strip().split("\t")
if len(sample) < 2: #至少:标签+一个特征
continue
y = sample[0]
X = sample[1:]
self._samples.append(sample) #labe + features
self._Y.add(y) #label
for x in set(X): #set给X去重
self._numXY[(x, y)] += 1
def _initparams(self):
self._N = len(self._samples)
self._n = len(self._numXY)
self._C = max([len(sample) - 1 for sample in self._samples])
self._w = [0.0] * self._n
self._lastw = self._w[:]
self._sample_ep()
def _convergence(self):
for w, lw in zip(self._w, self._lastw):
if math.fabs(w - lw) >= self._EPS:
return False
return True
def _sample_ep(self):
self._ep_ = [0.0] * self._n
#计算方法参见公式(20)
for i, xy in enumerate(self._numXY):
self._ep_[i] = self._numXY[xy] * 1.0 / self._N
self._xyID[xy] = i
def _zx(self, X):
#calculate Z(X), 计算方法参见公式(15)
ZX = 0.0
for y in self._Y:
sum = 0.0
for x in X:
if (x, y) in self._numXY:
sum += self._w[self._xyID[(x, y)]]
ZX += math.exp(sum)
return ZX
def _pyx(self, X):
#calculate p(y|x), 计算方法参见公式(22)
ZX = self._zx(X)
results = []
for y in self._Y:
sum = 0.0
for x in X:
if (x, y) in self._numXY: #这个判断相当于指示函数的作用
sum += self._w[self._xyID[(x, y)]]
pyx = 1.0 / ZX * math.exp(sum)
results.append((y, pyx))
return results
def _model_ep(self):
self._ep = [0.0] * self._n
#参见公式(21)
for sample in self._samples:
X = sample[1:]
pyx = self._pyx(X)
for y, p in pyx:
for x in X:
if (x, y) in self._numXY:
self._ep[self._xyID[(x, y)]] += p * 1.0 / self._N
def train(self, maxiter = 1000):
self._initparams()
for i in range(0, maxiter):
print "Iter:%d..."%i
self._lastw = self._w[:] #保存上一轮权值
self._model_ep()
#更新每个特征的权值
for i, w in enumerate(self._w):
#参考公式(19)
self._w[i] += 1.0 / self._C * math.log(self._ep_[i] / self._ep[i])
print self._w
#检查是否收敛
if self._convergence():
break
def predict(self, input):
X = input.strip().split("\t")
prob = self._pyx(X)
return prob
if __name__ == "__main__":
maxent = MaxEnt()
maxent.load_data('data.txt')
maxent.train()
print maxent.predict("sunny\thot\thigh\tFALSE")
print maxent.predict("overcast\thot\thigh\tFALSE")
print maxent.predict("sunny\tcool\thigh\tTRUE")
sys.exit(0)A
data.txt。
一份简明的Java实现:https://github.com/hankcs/MaxEnt
改进的迭代尺度法
已知最大熵模型为

其中,
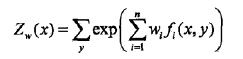
对数似然函数为
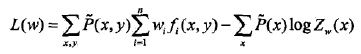
。
IIS的思路是,假设最大熵模型当前的参数向量是,那么就可以重复使用这一方法,直至找到对数似然函数的最大值。
对于给定的经验分布(测试集),对数似然函数的该变量是
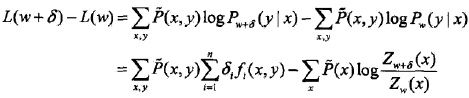
利用不等式
建立对数似然函数改变量的下界:

这一步就是先把不等式中的阿尔法换成∑,然后把Z还原而已。
将右端记为

于是有
是对数似然函数改变量的一个下界。
如果能找到适当的。
为达到这一目的,IIS进一步降低下界,
可以改写为
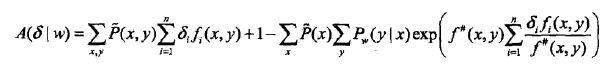
乘到∑里面去就和原式一摸一样。