关于java中的线程池,我一开始觉得就是为了避免频繁的创建和销毁线程吧,先创建一定量的线程,然后再进行复用。但是要具体说一下如何做到的,自己又说不出一个一二三来了,这大概就是自己的学习习惯流于表面,不经常深入的结果吧。所以这里决定系统的学习一下线程池的相关知识。
自己稍微总结了一下,学习一些新的知识或者技术的时候,大概都可以分为这么几个点:
1、为什么会有这项技术,用原来的方法有什么问题。
2、这项新技术具体是怎么解决这个问题的(这时可能就要涉及到一些具体的知识点和编码了)
3、是不是使用这项技术问题就可以得到完美解决了,有没有什么不同的方案?各自的优缺点是什么?(这是对一些具体的技术来说的,但是线程池是一个比较大的概念,可能不涉及这一点,但相应的线程池中有许多不同的种类,来应对不同的场景)
下面的内容是自己读过《实战java 高并发程序设计》之后加上自己的理解写的笔记,如果有错漏之处,请大家在评论区指出。
为什么要使用线程池?
1、正如前面的所说,频繁的创建和销毁时间消耗了太多的资源,占用了太多的时间
2、线程也是需要占用一定内存的,同时存在很多个线程的话,内存很快就溢出了,即使没有溢出,大量的线程回收也会对GC造成很大的压力,延长GC的停顿时间
这里可以举个例子来说明一下,比如你去银行办理业务时,首先得拿号排队吧,然后叫你去哪个窗口你就得去哪个窗口,在我看来,这就是一个很典型的线程池的例子。
我们可以想象一下,如果不按这种模式,会是什么样子……
你来到了银行的业务大厅,业务经理问你要办理什么业务,你说我想开个账户,于是经理拿起手机打通了职工大楼的电话,“让负责开账户的的那个小组派个人过来”(new 了一个开账户的对象),业务员马不停蹄的赶了过来然后帮你处理完了任务,只听经理又说到“这里没你事儿了,回去吧”,于是你又回到了职工大楼。
然后又来了一个客户……
于是你把上述的过程又执行了一遍,那么业务员在路上的时间可能比处理业务的时间还要长了。
更糟的是,如果有200个线程同时存在,并且每一个客户的业务处理时间都非常的长,那么业务大厅就可能同时存在200个客户和业务员了,大厅挤得都快赶上春运了。
ps : 上面这个小例子举得并不是很好,所以大家不要跟实际的知识点对号入座。比如说这里有10个业务员,那么10个业务员实际上是不能同时进行服务的,因为你的电脑没有10个cpu,只能是cpu不断的在线程之间进行切换,只要它换的够快,就可以给每一个客户一种他一直都在为我服务的感觉。
认识线程池
线程池的轮子我们已经不用自己造了,在jdk5版本之后,引入了Executor框架,用于管理线程。
Executor 框架包括:线程池,Executor,Executors,ExecutorService,CompletionService,Future,Callable 等
先放一张Executor框架的部分类图(下面这个类图就是用idea自带的工具做的,非常方便,有时间再写一下它的用法):
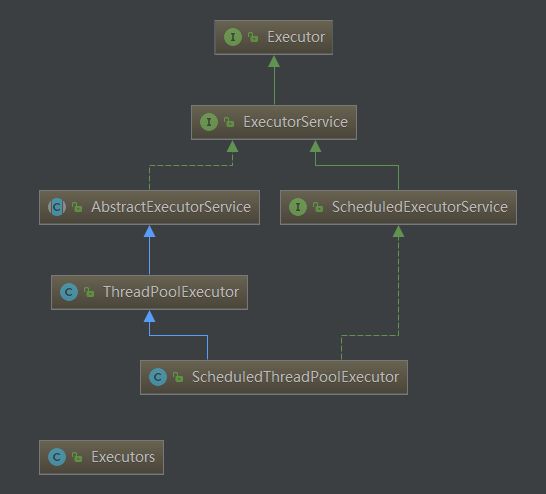
其中虚线箭头指的是实现,实线箭头指的是继承
而本文中我们需要了解的就是这个ThreadPoolExecutor 和 下面这个Executors了。
ThreadPoolExecutor:
从网上找了一个小例子,就是给一个集合添加2000个元素,我们分成两个测试,一个测试是添加一次元素就创建一个线程,另外一个测试是先创建好线程池,然后再添加。
不使用线程池版本:
//每一次添加操作都开一个线程 public static void getTimeWithThread() { System.out.println("使用多线程测试 start"); final Listlist = new LinkedList<>(); Random random = new Random(); long start = System.currentTimeMillis();
Runnable target = new Runnable() { @Override public void run() { list.add(random.nextInt()); } }; for (int i = 0; i < 20000 ; i++) { Thread thread = new Thread(target); thread.start(); try { thread.join(); } catch (InterruptedException e) { e.printStackTrace(); } } long end = System.currentTimeMillis(); long time = end - start; System.out.println("最终list的大小为:" + list.size()); System.out.println("使用多线程测试 end, 用时:" + time + "ms\n"); }
例子比较简单,我们需要创建线程,这里用的是实现Runnable接口的方式,然后为了保证子线程执行完成之后主线程(main线程)才执行,我们这里使用了join方法。
那么整个for循环的意思就是,我开启一个线程,然后你的main线程得等我执行完之后才能开启下一个线程继续执行。
使用线程池版本:
//使用线程池进行集合添加元素的操作 public static void getTimeWithThreadPool() { System.out.println("使用线程池测试 start"); final Listlist = new LinkedList<>(); Random random = new Random(); long start = System.currentTimeMillis();
Runnable target = new Runnable() { @Override public void run() { list.add(random.nextInt()); } }; ThreadPoolExecutor tp = new ThreadPoolExecutor(100, 100, 60, TimeUnit.SECONDS, new LinkedBlockingQueue(20000)); for (int i = 0; i < 20000 ; i++) { tp.execute(target); } tp.shutdown(); try { tp.awaitTermination(1,TimeUnit.DAYS); } catch (InterruptedException e) { e.printStackTrace(); } long end = System.currentTimeMillis(); long time = end - start; System.out.println("最终list的大小为:" + list.size()); System.out.println("使用线程池测试 end, 用时:" + time + "ms\n"); }
使用线程池就比较简单了,我们只要先创建好线程池,然后向它提交任务就行了,具体的线程该怎么操作,怎么管理都不用我们来操心。
execute() : 它是顶层接口Executor的一个方法(也是唯一一个),其实跟普通的创建线程执行run方法没有太大的区别
shutdown(): 顾名思义是关闭线程池,它会将已经提交但还没有执行的任务执行完成之后再关闭线程池(什么是提交?我们后面再说)
至于ThreadPoolExecutor里面那一大堆参数,我们慢慢再来看。
最后的测试结果:
不用线程池的话,我的机器跑出来大概要8000ms左右(人家网上的例子测出来只要2000ms左右,这差距,是我电脑垃圾,还是jvm没设置好啊,之后再来看这个问题),使用线程池的话是180ms左右。
可以看出来线程池相对于单纯的使用线程来说的话作用是相当大的。
ps:这里自己另外测试了一组,不使用线程直接添加,发现时间会快很多,这个问题其实还不是非常明白,多个线程一起执行难道不是执行的更快吗?暂时还没有得出结论,等更进一步的理解之后再写一篇文章来进行分析。
ThreadPoolExecutor里面那些参数都是干嘛用的?
/** * Creates a new {@code ThreadPoolExecutor} with the given initial * parameters. * * @param corePoolSize the number of threads to keep in the pool, even * if they are idle, unless {@code allowCoreThreadTimeOut} is set * @param maximumPoolSize the maximum number of threads to allow in the * pool * @param keepAliveTime when the number of threads is greater than * the core, this is the maximum time that excess idle threads * will wait for new tasks before terminating. * @param unit the time unit for the {@code keepAliveTime} argument * @param workQueue the queue to use for holding tasks before they are * executed. This queue will hold only the {@code Runnable} * tasks submitted by the {@code execute} method. * @param threadFactory the factory to use when the executor * creates a new thread * @param handler the handler to use when execution is blocked * because the thread bounds and queue capacities are reached * @throws IllegalArgumentException if one of the following holds:
* {@code corePoolSize < 0}
* {@code keepAliveTime < 0}
* {@code maximumPoolSize <= 0}
* {@code maximumPoolSize < corePoolSize} * @throws NullPointerException if {@code workQueue} * or {@code threadFactory} or {@code handler} is null */ public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueueworkQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
corePoolSize : 指定了线程池的线程数量
maximumPoolSize : 指定了线程池中的最大线程数量
keepAliveTime : 超过了corePoolSize时多余线程的存活时间
unit : KeepAliveTime的时间单位
workQueue : 任务队列,被提交但尚未被执行的任务
threadFactory: 线程工厂,用于创建线程
handler : 拒绝策略,当任务太多来不及处理的时候,如何拒绝任务
corePoolSize 和 maximumPoolSize(这里假设corePoolSize是5,maximumPoolSize是10 )
线程池的工作原理是你来一个线程,我就帮你在线程池中新创建一个线程,创建了5个线程之后,再来一个线程,我就不是在第一时间去创建一个新的线程,而是把它加入到一个等待队列中去,等线程池中有了空余的线程再从队列中拿一个出来进行 处理,等待队列的容量是我们一开始设置好的,如果等待队列也满了的话再去创建新的线程。
当线程池也满了,等待队列也满了(线程池数量达到了maximumPoolSize)的时候就拒绝执行线程的任务,这就涉及到了拒绝的策略。
而经过一段时间之后发现,业务没有那么繁忙了,就不需要一直维持着10个线程,可以清除掉一部分,以免占据多余的空间。
keepAliveTime 和 unit
有了上面的结束,这个参数就比较好理解了,上面说线程满了再经过一段时间之后就会被清除掉一部分线程,这个经过的时间就是有keepAliveTime 和 unit决定的
比如 keepAliveTime = 1 ,unit = TimeUnit.Days ,那么就是经过一天之后再去清理线程池。
workQueue :
我们前面也提到了当线程的数量超过了coreSize之后会添加到一个等待队列中去,这个队列就是workQueue。workQueue 采用的是一个实现了BlockingQueue的接口的对象
work也分为不同的几种,采取不同的策略
- ArrayBlockingQueue(有界的任务队列) :
pubic ArrayBlockingQueue( int capacity )
首先是最容易想到的,就是给等待队列设置一个容量,超过这个容量之后再创建新的线程。
- SynchronousQueue :该队列没有容量,每插入一个元素都要等待一个删除操作,使用这个队列的话,任务不会实际保存到队列中去,会直接提交到线程池中,如果线程池还没有满(还没达到maximumPoolSize),则分配线程,否则执行拒绝策略。
- LinkedBlockingQueue(无界的任务队列) : 顾名思义,这个队列是没有界限的,就是说你可以一直往队列里添加元素,直到内存资源被耗尽。
- PriorityBlockingQueue(优先任务队列,同时也是一个无界的任务队列):可以控制任务的优先级(优先级是通过实现Comparable接口实现的,具体可百度)
handler(拒绝策略):
当线程池和等待队列都满了之后,线程池就会拒绝执行新的任务了,那么该怎么拒绝呢,直接就说你走吧,哥们儿hold不住了吗?显然没这么简单。。
AbortPlicy 策略 : 直接抛出异常,阻止系统正常工作
CallerRunsPolicy策略 : 只要线程池没有关闭,就在调用者线程之中执行这个任务。比如说是主线程提交的这个任务,那我就直接在主线程之中执行这个任务。
DiscardOledestPolicy策略:该策略会丢掉最老的一个请求,也就是即将被执行的那个请求。并尝试再次发起请求。
DiscardPolicy策略:直接丢,不做任何处理
以上策略都是通过实现RejectedExecutionHandler接口实现的,如果上述策略还无法满足你的话,那么你也可以自己实现这个接口。
Executors:
介绍了基本的线程池之后就可以介绍一些jdk为我们写好的一些线程池了。
它由Executors类生成的。有以下几种:
- newFIxedThreadPool :固定大小线程池,大小固定,所以它不存在corePoolSize 和 maximumPoolSize ,并且使用无界队列作为等待队列
- newSingleThreadExecutor : 与newFixedThreadPool基本没有什么区别,但是数量只有1个线程
- newCachedThreadPool :一个corePoolSize,maximumPoolSize无限大的线程池,也就是说没有任务时,线程池中就没有线程,任务被提交时会看线程池有有没有空闲的线程,如果有的话,就交给它执行,如果没有的话,就交给SynchronousQueue, 也就是说会直接交给线程池,而由于maximumPoolSize是无限大的,所以它会再添加一个线程
- newScheduledThreadPool :定时执行任务的线程池(可以是延时执行,也可以是周期性的执行任务)
- newSingleThreadScheduledExecutor :与上面的线程池差不多,只不过线程池的大小为1。
以newFixedThreadPool为例展示一下它的使用方法。
package thread; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; /** * 展示Executors的简单用法 */ public class Lesson15_ThreadPool02 { public static void main(String[] args) { Runnable task = new Runnable() { @Override public void run() { System.out.println(System.currentTimeMillis() + ": Thread Id : " + Thread.currentThread().getId()); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } }; ExecutorService ex = Executors.newFixedThreadPool(5); for (int i = 0; i < 10 ; i++) { ex.submit(task); } ex.shutdown(); } }
1541580732981: Thread Id : 13 1541580732981: Thread Id : 14 1541580732981: Thread Id : 11 1541580732981: Thread Id : 12 1541580732981: Thread Id : 15 1541580733981: Thread Id : 13 1541580733981: Thread Id : 15 1541580733981: Thread Id : 12 1541580733981: Thread Id : 11 1541580733981: Thread Id : 14
关于定时线程池的两个方法的区别:
- scheduleAtFixedRate :以给定的的周期执行任务,任务开始于给定的初始延时,经过period之后开始下一个任务
举个例子,比如说,初始延时是1秒,period是5秒,任务实际的执行时间是2秒,那么第一个任务开始执行的时间是1秒,再第二个任务执行的时间是6秒,你看跟任务的实际执行时间并没有什么关系。
但是这里会有一个显而易见的问题,按照上面的说法,如果我的任务执行时间是10秒怎么办,远比period要大,那么此时会等待上一个任务执行完成之后立即执行下一个任务,
你也可以理解成period变成了8秒
public ScheduledFuture scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit);
- scheduleWithFixedDelay :这个方法则规定了上一个任务结束到下一个任务开始这之间的时间,还是上面那个例子,只不过将period改成delay还是5秒,那么第一个任务在第1秒开始执行,第2个任务在(1 + 2 + 5) = 8 时开始执行,也就是第一个任务执行完成之后再等5秒开始执行下一个任务。
public ScheduledFuture scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit);
以schedeleAtFixedRate为例,简单写一下代码的用法:
package thread; import java.util.concurrent.Executors; import java.util.concurrent.ScheduledExecutorService; import java.util.concurrent.TimeUnit; /** * 这里演示定时线程池的功能 */ public class Lesson15_ThreadPool03 { public static void main(String[] args) { Runnable task = new Runnable() { @Override public void run() { System.out.println(System.currentTimeMillis()/1000 + ": Thread Id : " + Thread.currentThread().getId()); try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } } }; System.out.println(System.currentTimeMillis()/1000); ScheduledExecutorService ses = Executors.newScheduledThreadPool(5); ses.scheduleAtFixedRate(task,1,3,TimeUnit.SECONDS); try { Thread.sleep(10000); } catch (InterruptedException e) { e.printStackTrace(); } ses.shutdown(); } }
1541584928
1541584929: Thread Id : 11
1541584932: Thread Id : 11
1541584935: Thread Id : 12
Process finished with exit code 0
从28开始执行定时线程池的任务,1秒钟(初始延时)之后开始执行第一个任务,之后每过三秒钟执行下一个任务
这里如果不关闭线程池的话,任务会一直执行下去。
线程池的分析暂时先到这里,还有一部分内容,例如扩展线程池,如何决定线程池的线程数量,fork/join框架等。等认真读过下一部分之后再继续把线程池部分的笔记凑齐。
package thread;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
/**
* 这里演示定时线程池的功能
*/
public class Lesson15_ThreadPool03 {
public static void main(String[] args) {
Runnable task = new Runnable() {
@Override
public void run() {
System.out.println(System.currentTimeMillis()/1000 +
": Thread Id : " + Thread.currentThread().getId());
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
System.out.println(System.currentTimeMillis()/1000);
ScheduledExecutorService ses = Executors.newScheduledThreadPool(5);
ses.scheduleAtFixedRate(task,1,5,TimeUnit.SECONDS);
}
}