- 简介
- 安装
- 启动
- 注意事项
- 使用命令
- 通用命令
- 数据结构
- 字符串(string)
- 哈希(hash)
- 队列(list)
- 集合(set)
- 有序集合(zset)
- 位图(bitcount)
- 事务
- 订阅与发布
- 配置
- Units(单位)
- INCLUDES(模块)
- GENERAL(常用项)
- SNAPSHOTING(RDB相关)
- REPLICATION(主从复制)
- SECURITY(安全)
- LIMITS(限制策略)
- APPEND ONLY MODE(AOF相关)
- LUA SCRIPTING(Lua脚本)
- REDIS CLUSTER(集群)
- SLOW LOG(慢查询日志)
- LATENCY MONITOR(延迟监控)
- EVENT NOTIFICATION(事件订阅)
- ADVANCED CONFIG(高级配置)
- VIRTUAL MEMORY(虚拟内存)
- 场景分析
- 设置密码
- 远程连接
- 持久化
- RDB
- AOF
- 主从复制
- 集群
- 订阅发布
- 普通订阅
- 模式订阅
简介
redis全称remote dictionary server(远程字典服务器)
redis是NoSQL(No Only SQL,非关系型数据库)的一种,NoSQL是以Key-Value的形式存储数据。当前主流的分布式缓存技术有redis,memcached,ssdb,mongodb等。
既可以把redis理解为理解为缓存技术,因为它的数据都是缓存在内从中的;
也可以理解为数据库,因为redis可以周期性的将数据写入磁盘或者把操作追加到记录文件中。
而我个人更倾向理解为缓存技术,因为当今互联网应用业务复杂、高并发、大数据的特性,正是各种缓存技术引入最终目的
问:redis这货凭什么能取代memcached?
1.支持的value类型相对于memcached更多。
2.支持持久化
redis数据存储在内存,会周期性地写入到磁盘。memcached则不会
问:本身程序的数据就是存储在内存里,为什么用redis?
1.自身程序里的数据不能序列化
2.自身数据的读取不是原子性
因为redis是单进程单线程,之所以很快是因为底层用了io多路复用(epoll)
3.利于不同语言的后端程序间通讯
安装
一般来说,开发者只需要本机使用包管理工具(apt,brew)下载即可。
但若想使用编译源码安装这一方式,点击这里
启动
- 配置后台启动
daemonize no ---- >daemonize yes
bind 127.0.0.1 ---> bind 0.0.0.0
- 启动redis服务端
redis-server /usr/local/etc/redis.conf
- 验证服务端是否启动成功
ps -ef | grep redis netstat -tunpl | grep 6379
- 客户端连接
/usr/local/redis/bin/redis-cli -h 192.168.2.128 -p 6379
# /usr/local/redis/bin/redis-cli -h 192.168.2.129 -p 6379 -a 12345
- 停止redis服务端
/usr/local/redis/bin/redis-cli shutdown #或者 pkill redis-server
注意事项
使用命令
命令手册
通用命令
select 1 # 切换到数据库1,范围是0~15。redis只能有16个db,不同mysql(mysql的database可以有无数个) help set # 查看set到帮助信息 save # 手动持久化 flushdb # 清空当前库 flushall #16个库的数据全删了 dbsize # 看看有多少个值
info # 各个库的键值情况
keys * # 查看所有键,这是运维禁忌
keys z*,keys k? # 通配符匹配
exists key1 # 判断key1是否存在 move key1 2 # 将key1从当前数据库移动到2号数据库 expire key1 60 # 将key1设置为60秒后过期 ttl key1 # 查看key1还有多少秒过期 type key1 # 看看key1是什么类型 del key1 #删掉
rename k1 k2 # 改名
数据结构
相关原理
字符串(string)
string类型是二进制安全的,意思是可以包含任何数据,比如jpg图片或者序列化的对象。字符串value最多是512M
增 set k1 ‘ddd’ ex 3 # 设置3秒之后过期 setex k1 3 'ddd' # 同上,set with expire set k1 'ddd' NX # 和字典的setdefault效果一样 setnx k1 ddd # 同上,set if not exist set love ‘ddd' XX # 只有love这个key存在时这条命令才生效 getset k1 fuck # 先get再set mset apple 12000 xiaomi 2000 oppo 3300 # 批量设置,{'apple':12000,'xiaomi':2000,'oppo':3300} msetnx apple 12000 xiaomi 2000 # 只要有一个键存在,全体跪 查 get k1
strlen k1 # 返回k1字符串的长度,注意是字节长度(汉字是三个字节) 切片 getrange k1 0 -1 #切片 setrange k1 0 xxxxx # 这个注意,0代表设置字符的位置,多余的字符会覆盖掉后续已经存在的字符 数字加减 incr count # count为数字类型的字符串变量,count++ decr count # count-- incrby count 20 # count+=20 decyby count 20 # count-=20
哈希(hash)
value是一个小字典,常用于存储一个对象的详细信息。例如存储用户的具体信息等
若嵌套的话,API方法会帮你将列表,字典转化为字符串,无论递归到多深也不怕
增 hset info a 1 # {'info':{'a':1}} hmset info a 1 b 2 # {'info':{'a':1,'b':2}},其实hset就可以批量设置 hsetnx info a 1 # set if not exist 查 hgetall info # 获取hash的键值对元组 hkeys info # 取出所有键 hvals info # 取出所有值 hget info a # {'info':{'a':1,'b':2}},取value里面a键对应的值 hmget info a b # 批量取 删 hdel info a # 删除info里面的a 数字操作 hincrby info age 2 # 将age对应的value加2 hincrbyfloat info price 2.5 将price对应的value加2.5 通配符匹配指定key hscan info 0 match e* # 0代表全局匹配
队列(list)
value是一个列表,底层其实是双向链表,有lpush,rpush
性能的话,由于是链表,头尾性能高,中间插入性能低
增 lpush li a b c # {'li':['a','b','c']} rpush li a # right push rpoplpush 源列表 目的列表 # 将源列表的右边的(rpop)弹出的值,lpush进新的列表 删 lpop # 左边弹出 rpop # 右边弹出 lrem li 2 3 # 删除2个'3' 查 lindex li 1 # 取出li[1] llen li # 长度 改 lset li 0 ff # li[0]='ff' linsert li before/after a aa # 在元素a之前(之后)插入aa,注意,这里用的不是索引值而是元素 切片 lrange li 0 -1 # 范围取值 ltrim key1 0 3 # 截取索引位置0~3多范围的值赋值给key1 数字操作 hincrby info age 2 # 将age对应的value加2 hincrbyfloat info price 2.5 将price对应的value加2.5 通配符匹配指定key hscan info 0 match e* # 0代表全局匹配
集合(set)
value是一个set
增 sadd s 1 2 2 3 3 4 # {'s':{'1','2','3','4'}} smove s1 s2 val_of_s1 # 将s1中的val的val_of_s1移动到s2 查 smembers s # 取出s的所有值 scard s1 # 获得s1集合里面元素个数 sismember s1 2 # 判断2是否为s1的元素 删 srem s1 fuck # 删除s1中的fuck srandmember s1 2 # 随机从s1删除2个元素 spop key # 随机删除一个元素 集合操作 sdiff s1 s2 #差集 ,即s1-s2 ,s1有的,s2没有 sinter s1 s2 #交集 sunion s1 s2 #并集
有序集合(zset)
有序集合,按照指定的权重进行排序
增 zadd s1 60 v1 80 v2 100 v3 #数字是权重(计算机术语中score代表的是权重) 查 zcard s1 #返回val的数目 zcount s1 60 80 #统计权重60到80之间的数目 zrank s1 v3 #返回v3的下标,注意是类似数组的顺序 zrevrank s1 v3 # 逆序返回v3的下标 zscore s1 v3 #返回v3的权重值 zrange s1 0 -1 withscores # 显示权重 zrange s1 0 -1 # 只显示值,不显示权重。注意:0,-1是下标范围。不是像mysql limit一样的参数 zrevrange s1 0 -1 # 只显示值,不显示权重。注意:0,-1是下标范围。 zrevrangebyscore s1 90 20 # 逆向显示权重范围的,注意参数1要大于参数2 zrangebyscore s1 60 80 # 显示指定权重范围的 zrangebyscore s1 (60 (80 # '('为不包含 zrangebyscore s1 60 80 limit 2 2 #类似于mysql数据库 zrevrangebyscore s1 90 60 #由于是反转,权重是90到60 删 zrem s1 v3 #删除v3
位图(bitcount)
二进制变量,常用于位计数法,节省内存
bitcount usercount # 定义 setbit usercount 999 1 # 设置bitcount 第999位为1, getbit usercount 22 # 获取第22位的值(0或1) bitcount usercount # usercount里1的个数
事务
redis事务可以一次执行一组命令的集合,按顺序地执行而不会被其他命令插入。
redis会将命令集合中的命令依次塞入一个执行队列。
当使用exec命令时,要么一次性成功,要么全部失败(语法等严重错误),但若像incr username这种命令,运行时会报错但是其他命令得以正常执行(运行时异常)
问:redis不是单线程的吗,应该不用担心数据竞争问题,为啥还要搞事务?
本来redis就是单线程的io多路复用,按道理说不应该考虑事务问题。
问题是在于,对于单一命令是不用考虑,但是对于一组命令要保证正确执行,就得做成事务。
若一个一个分散执行,结果很可能不如人意
问:为啥说redis对事务是部分支持?
1.不能回滚
当事务如果在执行过程中有一条命令出异常(不是严重错误),其后的命令仍然会被执行,不会回滚
2.虽说有隔离性。但是没有隔离级别概念
事务在执行过程中,不会被其他客户端发送过来的命令请求所打断,因为事务提交前任何指令都不会被实际地执行,也就不存在“事务内的查询要看到事务里的更新,在事务外查询不能看到”这个头疼的问题
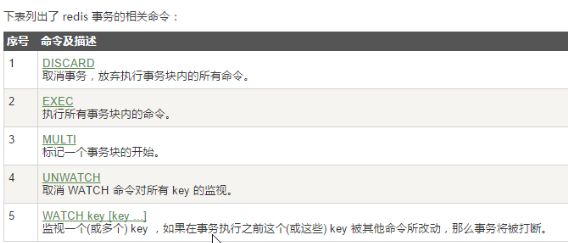
正常执行 1. multi 2. XXXXX命令 3. exec 放弃执行 multi XXXXX命令 discard #发现xxxx命令,我写入了不想执行的命令 watch 监控 # redis的乐观锁,若watch之后有任何key发生了变化,exec命令执行的事务都会被放弃,同时返回Nullmult-bulk应答以通知调用者事务执行失败 1. watch account # 盯着数据别让它改 2. multi 3. XXXXX命令 4. exec # account有人改了,返回nil。注意:一旦执行了exec之前watch锁都会被取消掉 5. unwatch # 取消对所有key的监控 6.从1 开始从头来过
订阅与发布
先说说消息中间件这个概念。进程间的一种消息通信模式:发送者发送消息,订阅者接收消息。常用于解藕
这个比RabbitQ简单很多,没有乱七八糟的交换机过滤啊,没有什么消息的持久化和确认性等待机制
这个就是,发布,你在线就收到,不在线就收不到
所以,redis可以做消息中间件,但是企业里面消息中间件肯定不是用它做
subscribe c1,c2 c3 # 一次性订阅c1,c2,c3三个频道 publish c2 deep_dark_fantasity # 在c2频道发布消息 psubscribe c* # 使用通配符订阅多个频道
配置
redis默认配置文件,点这里
Units(单位)
Units单位指明里面的1K、1G等指的是大小,而且是大小写敏感
INCLUDES(模块)
INCLUDES可以引入其他被分拆的配置文件
GENERAL(常用项)
# 默认情况下 redis 不是作为守护进程运行的,如果你想让它在后台运行,你就把它改成 yes。 # 当redis作为守护进程运行的时候,它会写一个 pid 到 /var/run/redis.pid 文件里面,该文件可以通过pidfile制定 daemonize yes # 当 Redis 以守护进程的方式运行的时候,Redis 默认会把 pid 文件放在/var/run/redis.pid # 注意:当运行多个 redis 服务时,需要指定不同的 pid 文件和端口 # 指定存储Redis进程号的文件路径 pidfile /var/run/redis.pid # 端口,默认端口是6379,生产环境中建议更改端口号,安全性更高 # 如果你设为 0 ,redis 将不在 socket 上监听任何客户端连接。 port 6379 # TCP 监听的最大容纳数量,此参数确定了TCP连接中已完成队列(完成三次握手之后)的长度, # 当系统并发量大并且客户端速度缓慢的时候,你需要把这个值调高以避免客户端连接缓慢的问题。 # Linux 内核会一声不响的把这个值缩小成 /proc/sys/net/core/somaxconn 对应的值,默认是511,而Linux的默认参数值是128。所以可以将这二个参数一起参考设定,你以便达到你的预期。 tcp-backlog 511 # 有时候为了安全起见,redis一般都是监听127.0.0.1 但是有时候又有同网段能连接的需求,当然可以绑定0.0.0.0 用iptables来控制访问权限,或者设置redis访问密码来保证数据安全 # 不设置将处理所有请求,建议生产环境中设置,有个误区:bind是用来限制外网IP访问的,其实不是,限制外网ip访问可以通过iptables;如:-A INPUT -s 10.10.1.0/24 -p tcp -m state --state NEW -m tcp --dport 9966 -j ACCEPT ; # 实际上,bind ip 绑定的是redis所在服务器网卡的ip,当然127.0.0.1也是可以的 #如果绑定一个外网ip,就会报错:Creating Server TCP listening socket xxx.xxx.xxx.xxx:9966: bind: Cannot assign requested address # bind 192.168.1.100 10.0.0.1 # 当客户端闲置多少时间后关闭其连接,默认是0,表示永不超时。 timeout 0 # tcp 心跳包。 # 如果设置为非零,则在与客户端缺乏通讯的时候使用 SO_KEEPALIVE 发送 tcp acks 给客户端。 # 这个之所有有用,主要由两个原因: # 1) 防止死的 peers # 2) Take the connection alive from the point of view of network # equipment in the middle. # # 推荐一个合理的值就是60秒 tcp-keepalive 0 # 日志记录等级,4个可选值debug,verbose,notice,warning # 可以是下面的这些值: # debug (适用于开发或测试阶段) # verbose (many rarely useful info, but not a mess like the debug level) # notice (适用于生产环境) # warning (仅仅一些重要的消息被记录) # 默认为verbose loglevel notice #配置 log 文件地址,默认打印在命令行终端的窗口上,也可设为/dev/null屏蔽日志 #若配置redis为守护进程方式运行,而这里又配置为日志记录为标准输出,则日志将会发送给/dev/null logfile "/data/logs/redis/redis.log" # 要想把日志记录到系统日志,就把它改成 yes, # syslog-enabled no # 设置 syslog 的 identity(标识)。 # syslog-ident redis # Specify the syslog facility. Must be USER or between LOCAL0-LOCAL7. # syslog-facility local0 # 可用的数据库数,默认值为16,默认数据库为0,数据库范围在0-(database-1)之间 databases 16
SNAPSHOTING(RDB相关)
# 在 900 秒内最少有 1 个 key 被改动,或者 300 秒内最少有 10 个 key 被改动,又或者 60 秒内最少有 1000 个 key 被改动,以上三个条件随便满足一个,就触发一次保存操作。 # if(在60秒之内有10000个keys发生变化时){ # 进行镜像备份 # }else if(在300秒之内有10个keys发生了变化){ # 进行镜像备份 # }else if(在900秒之内有1个keys发生了变化){ # 进行镜像备份 # } save 900 1 save 300 10 save 60 10000 # 默认情况下,如果 redis 最后一次的后台保存失败,redis 将停止接受写操作, # 这样以一种强硬的方式让用户知道数据不能正确的持久化到磁盘,否则就会没人注意到灾难的发生。如果后台保存进程重新启动工作了,redis 也将自动的允许写操作。 # 然而你要是安装了靠谱的监控,你可能不希望 redis 这样做,那你就改成 no 好 stop-writes-on-bgsave-error yes # 指定存储至本地数据库时是否压缩数据,默认为yes,Redis采用LZF压缩,如果为了节省CPU时间,可以关闭改选项,但会导致数据库文件变得巨大 # 默认设为 yes rdbcompression yes # 读取和写入的时候是否支持CRC64校验,默认是开启的 rdbchecksum yes # 备份文件的文件名,默认为dump.rdb dbfilename dump.rdb # 数据库备份的文件放置的路径 # 路径跟文件名分开配置是因为 Redis 备份时,先会将当前数据库的状态写入到一个临时文件 # 等备份完成时,再把该临时文件替换为上面所指定的文件 # 而临时文件和上面所配置的备份文件都会放在这个指定的路径当中,换句话说。这个配置项也关乎临时文件的存放位置 # 默认值为 ./ # dir ./ dir /data/redis/
REPLICATION(主从复制)
# 设置该数据库为其他数据库的slave数据库时,设置master服务的IP及端口,在redis启动时,它会自动从master进行数据同步 # slaveof# 当master服务设置了密码保护时,slave服务连接的master的密码 # masterauth # 当slave服务器和master服务器失去连接后,或者当数据正在复制传输的时候,如果此参数值设置“yes”,slave服务器可以继续接受客户端的请求,否则,会返回给请求的客户端如下信息“SYNC with master in progress”,除了INFO,SLAVEOF这两个命令 slave-serve-stale-data yes # 是否允许slave服务器节点只提供读服务 slave-read-only yes # Slaves 在一个预定义的时间间隔内发送 ping 命令到 server。你可以改变这个时间间隔。默认为 10 秒。 # repl-ping-slave-period 10 # 设置主从复制过期时间 # 这个值一定要比 repl-ping-slave-period 大 # repl-timeout 60 # 指定向slave同步数据时,是否禁用socket的NO_DELAY选 项。若配置为“yes”,则禁用NO_DELAY,则TCP协议栈会合并小包统一发送,这样可以减少主从节点间的包数量并节省带宽,但会增加数据同步到slave的时间。若配置为“no”,表明启用NO_DELAY,则TCP协议栈不会延迟小包的发送时机,这样数据同步的延时会减少,但需要更大的带宽。 通常情况下,应该配置为no以降低同步延时,但在主从节点间网络负载已经很高的情况下,可以配置为yes。 repl-disable-tcp-nodelay no # 设置主从复制容量大小。这个 backlog 是一个用来在 slaves 被断开连接时存放 slave 数据的 buffer,所以当一个 slave 想要重新连接,通常不希望全部重新同步,只是部分同步就够了,即仅仅传递 slave 在断开连接时丢失的这部分数据。这个值越大,salve 可以断开连接的时间就越长。 # repl-backlog-size 1mb # 在某些时候,master 不再连接 slaves,backlog 将被释放。如果设置为 0 ,意味着绝不释放 backlog 。 # repl-backlog-ttl 3600 # 指定slave的优先级。在不只1个slave存在的部署环境下,当master宕机时,Redis Sentinel会将priority值最小的slave提升为master。这个值越小,就越会被优先选中 # 需要注意的是,若该配置项为0,则对应的slave永远不会自动提升为master。 slave-priority 100 # 如果主服务器超过一秒钟没有收到从服务器发来的REPLCONF ACK命令,那么主服务器就知道主从服务器之间的连接出现问题了。 # 通过向主服务器发送INFO replication命令,在列出的从服务器列表的lag一栏中,我们可以看到相应从服务器最后一次向主服务器发送REPLCONF ACK命令距离现在过了多少秒: # 127.0.0.1:6379> INFO replication # Replication # role:master # connected_slaves:2 # slave0:ip=127.0.0.1,port=12345,state=online,offset=211,lag=0 #刚刚发送过 REPLCONF ACK命令 # slave1:ip=127.0.0.1,port=56789,state=online,offset=197,lag=15 # 在一般情况下,lag的值应该在0秒或者1秒之间跳动,如果超过1秒的话,那么说明主从服务器之间的连接出现了故障。 # Redis的min-slaves-to-write和min-slaves-max-lag两个选项可以防止主服务器在不安全的情况下执行写命令。 # 下面配置的是在从服务器的数量少于3个,或者三个从服务器的延迟(lag)值都大于或等于10秒时,主服务器将拒绝执行写命令,这里的延迟值就是上面提到的INFO replication命令的lag值。 # min-slaves-to-write 3 # min-slaves-max-lag 10
SECURITY(安全)
# 设置连接redis的密码,默认无密码 # redis速度相当快,一个外部用户在一秒钟进行150K次密码尝试,需指定强大的密码来防止暴力破解 requirepass set_enough_strong_passwd # 重命名一些高危命令,用来禁止高危命令 rename-command FLUSHALL ZYzv6FOBdwflW2nX rename-command CONFIG aI7zwm1GDzMMrEi rename-command EVAL S9UHPKEpSvUJMM rename-command FLUSHDB D60FPVDJuip7gy6l
LIMITS(限制策略)
# 限制同时连接的客户数量,默认是10000。如果设置为0,表示不作限制 # 当连接数超过这个值时,redis 将不再接收其他连接请求,客户端尝试连接时将收到 error 信息 # maxclients 10000 # 设置redis最大内存闲置,redis会在启动时将数据加载到内存中,达到最大内存后,redis会尝试清除已到期或即将到期的key,此方法护理后,若仍到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。 # 在删除时,按照过期时间进行删除,最早将要被过期的key将最先被删除 # maxmemory的设置比较适合于把redis当作于类似memcached 的缓存来使用 # maxmemory# 达到最大内存时的缓存清除策略 # volatile-lru -> 使用LRU算法移除key,只对设置了过期时间的键 # allkeys-lru -> 使用LRU算法移除key # volatile-random -> 在设置了过期时间的key中随机移除,只对设置了过期时间的键 # allkeys-random -> 移除随机的key # volatile-ttl -> 移除那些ttl最小的key,即移除即将过期的key # noeviction -> 不进行移除,针对写操作,只是返回错误信息 # maxmemory-policy noeviction # 设置样本数量,lru算法和最小ttl算法都并非是精确的算法,而是估算值。所以你可以设置样本的大小。redis默认会检查这么多个key并选择其中lru的那个 # maxmemory-samples 5
APPEND ONLY MODE(AOF相关)
# redis 默认情况下时异步地把数据写入磁盘,即同步数据文件是按上面save条件来同步的,但如果发生诸如拉闸限电、拔插头等状况,那么将造成比较大范围的数据丢失。而且该备份非常耗时,且备份不宜太频繁。 # 所以redis提供了另外一种更加高效的数据库备份及灾难恢复方式aof # 开启append only 模式后,redis 将每一次写操作请求都追加到appendonly.aof 文件中。redis重新启动时,会从该文件恢复出之前的状态。但可能会造成 appendonly.aof 文件过大,所以redis支持BGREWRITEAOF 指令,对appendonly.aof重新整理,默认是不开启的。 appendonly no # 指定日志记录文件名,默认为appendonly.aof。 appendfilename "appendonly.aof" # 设置对 appendonly.aof日志更新的条件,有三种选择always、everysec、no,默认是everysec表示每秒同步一次。 # always 表示每次更新后手动滴哦啊用fsync()将数据写到磁盘(慢,安全) # no 表示等操作系统进行数据缓存同步到磁盘,都进行同步 # everysec 表示对写操作进行累积,每秒同步一次(折中) # appendfsync everysec # 指定是否在后台aof文件rewrite期间调用fsync,默认为no,表示要调用fsync(无论后台是否有子进程在刷盘)。Redis在后台写RDB文件或重写afo文件期间会存在大量磁盘IO,此时,在某些linux系统中,调用fsync可能会阻塞。 no-appendfsync-on-rewrite yes # 指定Redis重写aof文件的条件,默认为100,表示与上次rewrite的aof文件大小相比,当前aof文件增长量超过上次afo文件大小的100%时,就会触发background rewrite。若配置为0,则会禁用自动rewrite auto-aof-rewrite-percentage 100 # 指定触发rewrite的aof文件大小。若aof文件小于该值,即使当前文件的增量比例达到auto-aof-rewrite-percentage的配置值,也不会触发自动rewrite。即这两个配置项同时满足时,才会触发rewrite。 # 生产环境中5G起步 auto-aof-rewrite-min-size 64mb aof-load-truncated yes
LUA SCRIPTING(Lua脚本)
在redis中可以使用eval命令执行lua脚本代码
192.168.127.128:6379>eval "return redis.call('set',KEYS[1],ARGV[1])" 1 name liulei OK 192.168.127.128:6379>get name "liulei"
为了防止某个脚本执行时间过长导致Redis无法提供服务(比如陷入死循环),Redis提供了lua-time-limit参数限制脚本的最长运行时间,默认为5秒钟。当脚本运行时间超过这一限制后,Redis将开始接受其他命令但不会执行(以确保脚本的原子性,因为此时脚本并没有被终止),而是会返回“BUSY”错误
# 一个Lua脚本最长的执行时间,单位为毫秒,如果为0或负数表示无限执行时间,默认为5000 lua-time-limit 5000
REDIS CLUSTER(集群)
# 如果配置yes则开启集群功能,此redis实例作为集群的一个节点,否则,它是一个普通的单一的redis实例。 cluster-enabled yes # 虽然此配置的名字叫"集群配置文件",但是此配置文件不能人工编辑,它是集群节点自动维护的文件,主要用于记录集群中有哪些节点、他们的状态以及一些持久化参数等,方便在重启时恢复这些状态。通常是在收到请求之后这个文件就会被更新。 cluster-config-file nodes-6379.conf # 这是集群中的节点能够失联的最大时间,超过这个时间,该节点就会被认为故障。如果主节点超过这个时间还是不可达,则用它的从节点将启动故障迁移,升级成主节点。注意,任何一个节点在这个时间之内如果还是没有连上大部分的主节点,则此节点将停止接收任何请求。一般设置为15秒即可。 cluster-node-timeout 15000 # 如果设置成0,则无论从节点与主节点失联多久,从节点都会尝试升级成主节点。如果设置成正数,则cluster-node-timeout乘以cluster-slave-validity-factor得到的时间,是从节点与主节点失联后,此从节点数据有效的最长时间,超过这个时间,从节点不会启动故障迁移。假设cluster-node-timeout=5,cluster-slave-validity-factor=10,则如果从节点跟主节点失联超过50秒,此从节点不能成为主节点。注意,如果此参数配置为非0,将可能出现由于某主节点失联却没有从节点能顶上的情况,从而导致集群不能正常工作,在这种情况下,只有等到原来的主节点重新回归到集群,集群才恢复运作。 cluster-slave-validity-factor 10 # 主节点需要的最小从节点数,只有达到这个数,主节点失败时,它从节点才会进行迁移。更详细介绍可以看本教程后面关于副本迁移到部分。 cluster-migration-barrier 1 # 在部分key所在的节点不可用时,如果此参数设置为"yes"(默认值), 则整个集群停止接受操作;如果此参数设置为”no”,则集群依然为可达节点上的key提供读操作。 cluster-require-full-coverage yes
SLOW LOG(慢查询日志)
redis的slowlog是redis用于记录记录慢查询执行时间的日志系统。由于slowlog只保存在内存中,因此slowlog的效率很高,完全不用担心会影响到redis的性能
# slowlog-log-slower-than表示slowlog的划定界限,只有query执行时间大于slowlog-log-slower-than的才会定义成慢查询,才会被slowlog进行记录。slowlog-log-slower-than设置的单位是微妙,默认是10000微妙,也就是10ms slowlog-log-slower-than 10000 # slowlog-max-len表示慢查询最大的条数,当slowlog超过设定的最大值后,会将最早的slowlog删除,是个FIFO队列 slowlog-max-len 128
LATENCY MONITOR(延迟监控)
可以帮助我们检查和排查引起延迟的原因。
redis的slowlog在2.2.12版本引入,latency monitor在2.8.13版本引入。slowlog仅仅是记录纯命令的执行耗时,不包括与客户端的IO交互及redis的fork等耗时
latency monitor监控的latency spikes则范围广一点,监控事件的分类:
| 事件 | 事件内容 | 命令 | 详解 |
|---|---|---|---|
| command | 慢命令 | latency history command | 执行时长超过 latency-monitor-threshold阈值的慢命令 |
| fast-command | 时间复杂度为O(1)和O(logN)的命令 | latency history fast-command | 时间复杂度为O(1)和O(logN)的命令 |
| fork | 系统调用fork(2) | latency history fork | AOF 或RDB 子进程 |
# "CONFIG SET latency-monitor-threshold" if needed. latency-monitor-threshold 0
EVENT NOTIFICATION(事件订阅)
# 模式订阅的配置 # 例如 notify-keyspace-events "gsExe"。即是说只允许监控Set结构的所有事件,并且之启用了键事件通知,没有启用键空间通知。 notify-keyspace-events ""
ADVANCED CONFIG(高级配置)
# 当hash中包含超过指定元素个数并且最大的元素没有超过临界时, # hash将以一种特殊的编码方式(大大减少内存使用)来存储,这里可以设置这两个临界值 # Redis Hash对应Value内部实际就是一个HashMap,实际这里会有2种不同实现, # 这个Hash的成员比较少时Redis为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的HashMap结构,对应的value redisObject的encoding为zipmap, # 当成员数量增大时会自动转成真正的HashMap,此时encoding为ht。 hash-max-zipmap-entries 512 hash-max-zipmap-value 64 # list数据类型多少节点以下会采用去指针的紧凑存储格式。 # list数据类型节点值大小小于多少字节会采用紧凑存储格式。 list-max-ziplist-entries 512 list-max-ziplist-value 64 # set数据类型内部数据如果全部是数值型,且包含多少节点以下会采用紧凑格式存储。 set-max-intset-entries 512 # zsort数据类型多少节点以下会采用去指针的紧凑存储格式。 # zsort数据类型节点值大小小于多少字节会采用紧凑存储格式。 zset-max-ziplist-entries 128 zset-max-ziplist-value 64 # Redis将在每100毫秒时使用1毫秒的CPU时间来对redis的hash表进行重新hash,可以降低内存的使用 # # 当你的使用场景中,有非常严格的实时性需要,不能够接受Redis时不时的对请求有2毫秒的延迟的话,把这项配置为no。 # # 如果没有这么严格的实时性要求,可以设置为yes,以便能够尽可能快的释放内存 activerehashing yes
VIRTUAL MEMORY(虚拟内存)
# 指定是否启用虚拟内存机制,默认值为no,简单的介绍一下,VM机制将数据分页存放,由Redis将访问量较少的页即冷数据swap到磁盘上,访问多的页面由磁盘自动换出到内存中(在后面的文章我会仔细分析Redis的VM机制) vm-enabled no # 虚拟内存文件路径,默认值为/tmp/redis.swap,不可多个Redis实例共享 vm-swap-file /tmp/redis.swap # 将所有大于vm-max-memory的数据存入虚拟内存,无论vm-max-memory设置多小,所有索引数据都是内存存储的(Redis的索引数据 就是keys),也就是说,当vm-max-memory设置为0的时候,其实是所有value都存在于磁盘。默认值为0 vm-max-memory 0 # Redis swap文件分成了很多的page,一个对象可以保存在多个page上面,但一个page上不能被多个对象共享,vm-page-size是要根据存储的 数据大小来设定的,作者建议如果存储很多小对象,page大小最好设置为32或者64bytes;如果存储很大大对象,则可以使用更大的page,如果不 确定,就使用默认值 vm-page-size 32 # 设置swap文件中的page数量,由于页表(一种表示页面空闲或使用的bitmap)是在放在内存中的,,在磁盘上每8个pages将消耗1byte的内存。 vm-pages 134217728 # 设置访问swap文件的线程数,最好不要超过机器的核数,如果设置为0,那么所有对swap文件的操作都是串行的,可能会造成比较长时间的延迟。默认值为4 vm-max-threads 4 # 设置在向客户端应答时,是否把较小的包合并为一个包发送,默认为开启 glueoutputbuf yes # 指定在超过一定的数量或者最大的元素超过某一临界值时,采用一种特殊的哈希算法 hash-max-zipmap-entries 64 hash-max-zipmap-value 512 # 指定是否激活重置哈希,默认为开启(后面在介绍Redis的哈希算法时具体介绍) activerehashing yes
场景分析
设置密码
# 注意redis旨在做高速缓存,安全并不是主要策略,所以redis默认不像mysql一样一定要你指定一个密码 # 1.查看redis的密码 config get requirepass # 2.设置redis密码 config set requirepass '12345' # 3.输入密码 auth 12345
上面端设置只要redis服务端重启后就失效,若要长久有效,需要在配置文件里配置
requirepass 12345 # 如果真的要为安全考虑,就必须设置复杂密码,redis是高并发的,弱密码很容易受到暴力破解
注意:除了进入redis后使用auth命令认证,还可以客户端启动时传入密码参数
/usr/local/redis/bin/redis-cli -h 192.168.2.129 -p 6379 -a 12345
远程连接
在redis.conf中配置
1.远程连接redis要配置密码,而且还要修改bind 127.0.0.1 为 bind 0.0.0.0
2.设置密码
持久化
我们已经说过,既可以把redis理解为缓存技术,也可以理解为数据库,因为redis支持将内存中的数据周期性的写入磁盘或者把操作追加到记录文件中,这个过程称为redis的持久化。redis支持两种方式的持久化,一种是快照方式(snapshotting),也称RDB方式;两一种是追加文件方式(append-only file),也称AOF方式。RDB方式是redis默认的持久化方式。
RDB
- RDB方式原理
当redis需要做持久化时(执行SAVA或者BGSAVA命令,或者是达到配置条件时执行),redis会fork一个子进程,子进程将数据写到磁盘上一个临时RDB文件中,当子进程完成写临时文件后,将原来的RDB替换掉(默认文件名为dump.rdb)
- RDB命令
1、执行SAVE命令,在当前线程执行,会卡住
2、执行BGSAVE命令,在后台线程执行,马上返回
3、当符合用户给定的配置条件时Redis会自动将内存中的所有数据进行快照并存储在硬盘上。由两个参数构成:时间和改动的键的个数。当在指定的时间内被更改的键的个数大于指定的数值时就会进行快照
注意,SHUTDOWN命令会迅速生成dump.db文件(flushall+shutdown毁天灭地)
- RDB优缺点
定时备份,Redis效率高,但是容易造成数据丢失,丢失的多少和备份策略有关,例如:5分钟备份一次,但是第8分时宕机了,那么就丢失了后面的3分钟数据
AOF
AOF就可以做到全程持久化,Redis每执行一个修改数据的命令,都会把这个命令添加到AOF文件中,当Redis重启时,将会读取AOF文件进行“重放”以恢复到 Redis关闭前的最后时刻。
- 为什么aof会在rdb之后产生?
RDB方式是周期性的持久化数据, 如果未到持久化时间点,Redis 因为某些原因而造成故障停机, 那么服务器将丢失最近写入、且仍未保存到快照中的那些数据。所以从redis 1.1开始引入了AOF方式,AOF 持久化记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集。 AOF 文件中的命令全部以 Redis 协议的格式来保存,新命令会被追加到文件的末尾。
AOF方式仍然有丢失数据的可能,因为收到写命令后可能并不会马上将写命令写入磁盘,因此我们可以修改redis.conf,配置redis调用write函数写入命令到文件中的时机。如下
#######################APPEND ONLY MODE ############################# ...... # AOF and RDB persistence can be enabled at the same time without problems. # If the AOF is enabled on startup Redis will load the AOF, that is the file # with the better durability guarantees. # # Please check http://redis.io/topics/persistence for more information. #启用AOF方式 appendonly yes #每次有新命令追加到 AOF 文件时就执行一次 fsync :非常慢,也非常安全 appendfsync always #每秒 fsync 一次:足够快(和使用 RDB 持久化差不多),并且在故障时只会丢失 1 秒钟的数据 appendfsync everysec #从不 fsync :将数据交给操作系统来处理。更快,也更不安全的选择 appendfsync no
从上面三种AOF持久化时机来看,为了保证不丢失数据,appendfsync always是最安全的。
- AOF优缺点
优点:AOF基本可以保证数据不丢失,数据完整性比rdb要高。
缺点: 1.AOF持久化文件会变的越来越大。例如我们调用incr test命令100次,文件中必须保存全部的100条命令,其实有99条都是多余的。
2.频繁的IO和aof文件过大时的rewrite会带来系统波动,并且由于语句过多且不断变化,导致恢复数据速度慢于rdb,并且备份数据库可能会出bug。所以一般不单独使用(以防万一)
- 如果一个系统里面,同时存在rdb和aof,它们是冲突还是协作?
两者可以共存,先加载的是aof。如果aof错误,redis-server起不来
- aof文件修复
redis-check-aof --fix xxx.aof 用来修复错误的aof文件,去除里面的错误数据(延时,丢包,病毒,大程序异常导致的文件错损等都会产生错误数据)
主从复制
主从复制主要用于容灾恢复(主机挂了,能迅速切换到从机,然后去修从机)和读写分离。
主从复制有延迟这个不可避免的缺点,但是不妨碍其成为流行的技术
- 主从复制的特点
一个主服务器可以有多个从服务器。不仅主服务器可以有从服务器, 从服务器也可以有自己的从服务器。
Redis 支持异步复制和部分复制(这两个特性从Redis 2.8开始),主从复制过程不会阻塞主服务器和从服务器。
Master Server是以非阻塞的方式为Slaves提供服务。所以在Master-Slave同步期间,客户端仍然可以提交查询或修改请求。Slave Server同样是以非阻塞的方式完成数据同步。在同步期间,如果有客户端提交查询请求,Redis则返回同步之前的数据。
一般是主写从读。如让多个从服务器处理只读命令,使用复制功能来让主服务器免于频繁的执行持久化操作。即只有主机可以写,从机不可以写
Master可以将数据保存操作交给Slaves完成,从而避免了在Master中要有独立的进程来完成此操作。
主机down了,从机不上位等待主机回归。若已经有从机上位(哨兵模式或者手动调整)之前的master将会变为slave为新的master服务
从机挂了,要重新使用slave of命令认主(可以写入配置文件避免)
- 主从复制过程
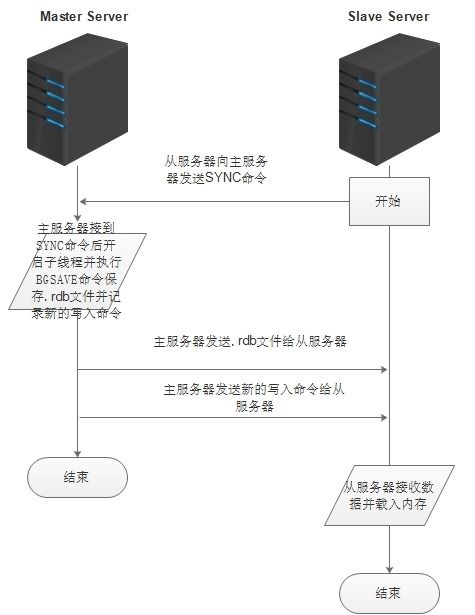
Redis主从复制过程示意图
从上面的示意图可以看出,主服务器与从服务器建立连接之后,Redis主从复制过程主要有下面几步:
- 从服务器向主服务器发送SYNC命令;
- 收到SYNC命令的主服务器执行BGSAVE命令,在后台生成一个RDB文件,并使用一个缓冲区记录从现在开始执行的所有写命令;
- 当主服务器的BGSAVE命令执行完毕时,主服务器会将BGSAVE命令生成的RDB文件发送给从服务器,从服务器接收并载入这个RDB文件,将自己的数据库状态更新至主服务器执行BGSAVE命令时的数据库状态。
- 主服务器将记录在缓冲区里面的所有写命令发送给从服务器,从服务器执行这些写命令,将自己的数据库状态更新至主服务器数据库当前所处的状态。
从服务器对主服务器的复制可以分为以下两种情况:
- 初次复制:从服务器以前没有复制过任何主服务器,或者从服务器当前要复制的主服务器和上一次复制的主服务器不同;
- 断线后重复制:处于命令传播阶段的主从服务器因为网络原因而中断了复制,但从服务器通过自动重连接重新连上了主服务器,并继续复制主服务器。
但是SYNC命令是非常消耗资源的,SYNC是一个如此消耗资源的命令,所以Redis最好在真需要的时候才需要执行SYNC命令。
因为每次执行SYNC命令,主从服务器需要执行一下操作:
- 主服务器需要执行BGSAVE命令来生成RDB文件,这个生成操作会耗费主服务器大量的CPU、内存和磁盘I/O资源;
- 主服务器需要将自己生成的RDB文件发送给从服务器,这个发送操作会耗费主从服务器大量的网络资源(带宽和流量),并对主服务器响应命令请求的时间产生影响;
- 接收到RDB文件的从服务器需要载入主服务器发来的RDB文件,并且在载入期间,从服务器会因为阻塞而没办法处理命令请求。
为了解决旧版复制功能在处理断线重复制情况时的低效问题,Redis从2.8版本开始,使用PSYNC命令代替SYNC命令来执行复制时的同步操作。
PSYNC命令具有完整重同步(full resynchronization)和部分重同步(partial resynchronization)两种模式:
- 其中完整重同步用于处理初次复制情况:完整重同步的执行步骤和SYNC命令的执行步骤基本一样,它们都是通过让主服务器创建并发送RDB文件,以及向从服务器发送保存在缓冲区里面的写命令来进行同步;
- 而部分重同步则用于处理断线后重复制情况:当从服务器在断线后重新连接主服务器时,如果条件允许,主服务器可以将主从服务器连接断开期间执行的写命令发送给从服务器,从服务器只要接收并执行这些写命令,就可以将数据库更新至主服务器当前所处的状态。
配置
配从不配主
info replication #查看当前redis的角色
slave of 127.0.0.1 6379 #从机认主
slaveof no one # 丛机上位
见如下步骤: 1). 同时启动两个Redis服务器,可以考虑在同一台机器上启动两个Redis服务器,分别监听不同的端口,如6379和6380。 2). 在Slave服务器上执行一下命令: /> redis-cli -p 6380 #这里我们假设Slave的端口号是6380 redis 127.0.0.1:6380> slaveof 127.0.0.1 6379 #我们假设Master和Slave在同一台主机,Master的端口为6379 OK 上面的方式只是保证了在执行slaveof命令之后,redis_6380成为了redis_6379的slave,一旦服务(redis_6380)重新启动之后,他们之间的复制关系将终止。 如果希望长期保证这两个服务器之间的Replication关系,可以在redis_6380的配置文件中做如下修改: /> cd /etc/redis #切换Redis服务器配置文件所在的目录。 /> ls 6379.conf 6380.conf /> vi 6380.conf 将 # slaveof改为 slaveof 127.0.0.1 6379 保存退出。 这样就可以保证Redis_6380服务程序在每次启动后都会主动建立与Redis_6379的Replication连接了。
这里我们假设Master-Slave已经建立。 #启动master服务器。 [root@Stephen-PC redis]# redis-cli -p 6379 redis 127.0.0.1:6379> #情况Master当前数据库中的所有Keys。 redis 127.0.0.1:6379> flushdb OK #在Master中创建新的Keys作为测试数据。 redis 127.0.0.1:6379> set mykey hello OK redis 127.0.0.1:6379> set mykey2 world OK #查看Master中存在哪些Keys。 redis 127.0.0.1:6379> keys * 1) "mykey" 2) "mykey2" #启动slave服务器。 [root@Stephen-PC redis]# redis-cli -p 6380 #查看Slave中的Keys是否和Master中一致,从结果看,他们是相等的。 redis 127.0.0.1:6380> keys * 1) "mykey" 2) "mykey2" #在Master中删除其中一个测试Key,并查看删除后的结果。 redis 127.0.0.1:6379> del mykey2 (integer) 1 redis 127.0.0.1:6379> keys * 1) "mykey" #在Slave中查看是否mykey2也已经在Slave中被删除。 redis 127.0.0.1:6380> keys * 1) "mykey"
- 哨兵模式
通俗地讲,让哨兵(一个进程)盯着主机,主机一挂立即组织从机投票选取新的老大
反客为主的自动版,能都后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库

集群
我所在的公司用不上redis集群,不过还是作一下了解
详细
订阅发布
Redis从2.X版本开始,就支持一种基于非持久化消息的、使用发布/订阅模式实现的事件通知机制。
redis当消息订阅机制,简单一句就是你在线就收到,不在线就收不到。当消息订阅者由于各种异常情况而被迫断开连接,在其重新连接后,其离线期间的事件是无法被重新通知的(一些redis资料中也称为即发即弃)。
其使用的发布/订阅模式的机制并不是由订阅者周期性的从Redis服务拉取事件通知,而是由Redis服务主动推送事件通知到符合条件的若干订阅者。
Redis订阅/发布功能的不足
Redis提供的订阅/发布功能并不完美,更不能和ActiveMQ/RabbitMQ提供的订阅/发布功能相提并论。
-
首先这些消息并没有持久化机制,属于即发即弃模式。也就是说它们不能像ActiveMQ中的消息那样保证持久化消息订阅者不会错过任何消息,无论这些消息订阅者是否随时在线。
-
由于本来就是即发即弃的消息模式,所以Redis也不需要专门制定消息的备份和恢复机制。
-
也是由于即发即弃的消息模式,所以Redis也没有必要专门对使用订阅/发布功能的客户端连接进行识别,用来明确该客户端连接的ID是否在之前已经连接过Redis服务了。ActiveMQ中保持持续通知的功能的前提,就是能够识别客户端连接ID的历史连接情况,以便确定哪些订阅消息这个客户端还没有处理。
-
Redis当前版本有一个简单的事务机制,这个事务机制可以用于PUBLISH命令。但是完全没有ActiveMQ中对事务机制和ACK机制那么强的支持。而在我写作的“系统间通讯”专题中,专门讲到了ActiveMQ的ACK机制和事务机制。
-
Redis也没有为发布者和订阅者准备保证消息性能的任何方案,例如在大量消息同时到达Redis服务是,如果消息订阅者来不及完成消费,就可能导致消息堆积。而ActiveMQ中有专门针对这种情况的慢消息机制。
第一类:基于Channel的消息事件
这一类消息和Redis中存储的Keys没有太多关联,也就是说即使不在Redis中存储任何Keys信息,这类消息事件也可以独立使用。
第二类:消息事件可以对(也可以不对)Redis中存储的Keys信息的变化事件进行通知
普通订阅
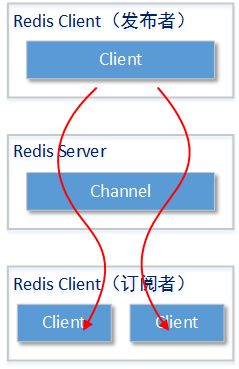
我们先从比较简单的publish命令和subscribe命令开始介绍,因为这组命令所涉及到的Channel(通道)和Redis中存储的数据相对独立。publish命令由发送者使用,负责向指定的Channel发送消息;subscribe命令由订阅者使用,负责从指定的一个或者多个Channel中获取消息。
以下是 publish 命令和 subscribe 命令的使用示例:
// 该命令向指定的channel名字发送一条消息(字符串) PUBLISH channel message // 例如:向名叫FM955的频道发送一条消息,消息信息为“hello!” PUBLISH FM955 "hello!" // 再例如:向名叫FM900的频道发送一条消息,消息信息为“ doit!” PUBLISH FM900 "doit!" // 该命令可以开始向指定的一个或者多个channel订阅消息 SUBSCRIBE channel [channel ...] // 例如:向名叫FM955的频道订阅消息 SUBSCRIBE FM955 // 再例如:向名叫FM955、FM900的两个频道订阅消息 SUBSCRIBE FM955 FM900
如果您使用需要使用publish命令和subscribe命令,您并不需要对Redis服务的配置信息做任何更改。以下示例将向读者展示两个命令的简单使用方式——前提是您的Redis服务已经启动好了:
由客户端A充当订阅者,在ChannelA和ChannelB两个频道上订阅消息
-- 我们使用的Redis服务地址为192.168.61.140,端口为默认值 [root@kp2 ~]# redis-cli -h 192.168.61.140 192.168.61.140:6379> SUBSCRIBE ChannelA ChannelB Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "ChannelA" 3) (integer) 1 1) "subscribe" 2) "ChannelB" 3) (integer) 2
- 有客户端B从当订阅者,通过ChannelB发送消息给所有订阅者
-- 连接到Redis服务器后,直接运行PUBLISH命令,发送信息[root@kp1 ~]# redis-cli -h 192.168.61.140 192.168.61.140:6379> PUBLISH ChannelB "hello" (integer) 1
- 以下是订阅者客户端A所受到的message信息
-- 这时订阅者收到消息如下:1) "message" 2) "ChannelB" 3) "hello"
从以上示例中可以看到,客户端A确实收到了客户端B所发送的消息信息,并且收到三行信息。这三行信息分别表示消息类型、消息通道和消息内容。注意,以上介绍的这组publish命令和subscribe命令的操作过程并没有对Redis服务中已存储的任何Keys信息产生影响。
模式订阅psubscribe
Redis中还支持一种模式订阅,它主要依靠psubscribe命令向技术人员提供订阅功能。模式订阅psubscribe最大的特点是,它除了可以通过Channel订阅消息以外,还可以配合配置命令来进行Keys信息变化的事件通知。
模式订阅psubscribe的Channel订阅和subscribe命令类似,这里给出一个命令格式,就不再多做介绍了(可参考上文对subscribe命令的介绍):
// 该命令可以开始向指定的一个或者多个channel订阅消息 // 具体使用示例可参见SUBSCRIBE命令 PSUBSCRIBE channel [channel ...]
模式订阅psubscribe对Keys变化事件的支持分为两种类型:keyspace(键空间通知)和keyevent(键事件通知),这两类事件都是依靠Key的变化触发的,而关键的区别在于事件描述的焦点,举例说明:
当Redis服务中0号数据库的MyKey键被删除时,键空间和键事件向模式订阅者分别发送的消息格式如下:
// 以下命令可订阅键空间通知 // 订阅0号数据库任何Key信息的变化 192.168.61.140:6379> psubscribe __keyspace@0__:* Reading messages... (press Ctrl-C to quit) 1) "psubscribe" 2) "__keyspace@0__:*" 3) (integer) 1 // 出现以上信息,说明订阅成功 // 当其他客户端执行 set mykey 123456 时,该订阅可收到以下信息 1) "pmessage" 2) "__keyspace@0__:*" 3) "__keyspace@0__:mykey" 4) "set"
以上收到的订阅信息,其描述可以概括为:“mykey的键空间发生了事件,事件为set”。这样的事件描述着重于key的名称,并且告诉客户端key的事件为set。我们再来看看订阅键事件通知时,发生同样事件所得到的订阅信息:
// 以下命令可订阅键空间通知 // 订阅0号数据库任何Key信息的变化 192.168.61.140:6379> psubscribe __keyspace@0__:* Reading messages... (press Ctrl-C to quit) 1) "psubscribe" 2) "__keyspace@0__:*" 3) (integer) 1 // 出现以上信息,说明订阅成功 // 当其他客户端执行 set mykey 123456 时,该订阅可收到以下信息 1) "pmessage" 2) "__keyspace@0__:*" 3) "__keyspace@0__:mykey" 4) "set"
以上收到的订阅信息中事件是主体,其信息可以概括为:“0号数据库发生了set事件,发生这个事件的key信息为mykey”。
模式订阅的配置
1、配置和通配符
要使用psubscribe命令进行键事件的订阅,就首先需要在Redis的主配置文件中对模式订阅进行设定。注意,如果您只是使用psubscribe命令通过Channel发送消息到订阅者,或者更单纯的使用publish命令和subscribe命令组合通过Channel发送和接收消息,就不需要进行这样的配置。
默认情况下Redis服务下的键空间通知和键事件通知都是关闭的。在redis.conf文件下,有专门的“EVENT NOTIFICATION”区域进行设定,设置的格式为:
notify-keyspace-events [通配符]
通配符的定义描述如下:
- K:启用keyspace键空间通知,客户端可以使用keyspace@为前缀的格式使用订阅功能;
- E:启用keyevent键事件通知,客户端可以使用keyevent@为前缀的格式使用订阅功能;
- g:监控一般性事件,包括但不限于对del,expire,rename事件的监控;
- $:启用对字符串格式(即一般K-V结构)命令的监控;
- l:启用对List数据结构命令的监控;
- s:启用对Set数据结构命令的监控;
- h:启用对Hash数据结构命令的监控;
- z:启用对ZSet数据结构命令的监控;
- x:启用对过期事件的监控;
- e:启用对驱逐事件的监控,当某个键因maxmemory达到设置时,使用策略进行内存清理,会产生这个事件;
- A:g$lshzxe通配符组合的别名,也就是说”AKE”这样的通配符组合,意味着所有事件。
以下的几个实例说明了配置格式中通配符的用法:
// 监控任何数据格式的所有事件,包括键空间通知和键事件通知 notify-keyspace-events "AKE" // 只监控字符串结构的所有事件,包括键空间通知和键事件通知 notify-keyspace-events "g$KExe" // 只监控所有键事件通知 notify-keyspace-events "AE" // 只监控Hash数据解构的键空间通知 notify-keyspace-events "ghKxe" // 只监控Set数据结构的键事件通知 notify-keyspace-events "gsExe"
注意,在Redis主配置文件中进行事件通知的配置,其配置效果是全局化的。也就是说所有连接到Redis服务的客户端都会使用这样的Key事件通知逻辑。但如果单独需要为某一个客户端会话设置独立的Key事件通知逻辑,则可以在客户端成功连接Redis服务后,使用类似如下的命令进行设置:
...... 192.168.61.140:6379> config set notify-keyspace-events KEA OK
2、键事件订阅
完成键事件的配置后,就可以使用psubscribe命令在客户端订阅消息通知了。这个过程还是需要使用通配符参数,才能完成订阅指定。通配符格式如下所示:
psubscribe __[keyspace|keyevent]@__:[prefix] // 例如: // 订阅0号数据库中,所有的键变化事件,进行键空间通知 psubscribe __keyspace@0__:* // 订阅0号数据库,所有的键变化事件,进行键空间通知和键事件通知 psubscribe __key*@0__:*
注意,就如上文所提到的那样,客户端能够进行键信息变化事件订阅的前提是Redis服务端或者这个客户端会话本身开启了相应配置。以下举例说明psubscribe命令中参数的使用方式:
// 注意,Redis服务上的配置信息如下 // notify-keyspace-events "gsExe" // 即是说只允许监控Set结构的所有事件,并且之启用了键事件通知,没有启用键空间通知。 // 客户端使用以下命令开始订阅Key的变化事件 192.168.61.140:6379> psubscribe __key*@0__:* // 以上命令订阅了0号数据库所有键信息的变化通知,包括键事件通知和键空间通知 Reading messages... (press Ctrl-C to quit) 1) "psubscribe" 2) "__key*@0__:*" 3) (integer) 1 // 接着,已连接到Redis服务上的另一个客户端执行了如下命令 // > sadd mysetkey rt // 那么收到的消息通知为 1) "pmessage" 2) "__key*@0__:*" 3) "__keyevent@0__:sadd" 4) "mysetkey"
以上实例操作中有两个问题需要单独进行说明:
当客户端使用psubscribe命令进行订阅时(psubscribe key*@0:*),实际上是连同keyspace(键空间通知)和keyevent(键事件通知)一起订阅了。那么按照上文介绍的内容来说,这个订阅者本该收到两条事件消息。一条消息的描述重点在key上,另一条消息的描述重点在sadd事件上。但实际情况是,这个订阅者只收到了以描述重点在事件上的键事件通知。这是因为在以上实例中特别说明的一点:Redis服务端只开启键事件通知的配置。所以无论客户端如何订阅键空间通知,也收不到任何消息。
另外,包括Redis官方资料在内的资料都在阐述这样一个事实,既是通过sadd命令对一个Set结构中的元素进行变更和直接通过“PUBLISH keyevent@0:sadd mysetkey”这样的命令向订阅者发送消息,在消息订阅者看来效果都是一样。但是这两种不同的操作过程对于Redis存储的Key数据,则是完全不一样的。前者的操作方式会改变Redis中存储的数据状况,但后者则不会。