以下内容为由4月27日由将门主办的“计算机视觉”主题技术专家微信群分享嘉宾实录。
分享嘉宾:阿里云研究员华先胜博士
![]() 自我介绍
自我介绍
我在2001年北大数学系十年寒窗博士毕业以后加入了微软亚洲研究院,在之后9年半的时间在研究院一直从事图像和视频的分析工作。2010年底我突然变得有点迷盲,虽然一直也在做产品,但实际上还没有真正地上过“战场”,所以当时就做了一个大家都不太看好的决定——我觉得应该真正地到“战场上打仗”,看看我们实际当中的图像搜索的困难到底在哪里,用户的需求和痛点到底在哪里?因此之后我去了微软美国总部必应产品组做了两年的图像搜索,也发现很多东西需要深入研究。当时微软的图像搜索在这两年之内也发生了很大的变化,从比Google差,到很多地方都胜过了Google。
两年后我转到微软雷德蒙研究院,做图像识别方面的研究。又做了两年多后,渐渐发觉需要更多的资源来实现自己的想法,于是我又选择回到了国内并加入了阿里巴巴的搜索事业部,开始做电商的图像搜索研究。
在我加入阿里的一年后,电商图像搜索取得了很大的进展。当时在阿里云上有很多图像视频分析方面的需求,但阿里云没有一个这样的组能够去处理这些大量地需求。所以我当时又做了一个很艰难的决定离开了搜索,来到了阿里云——也就是说我现在是在云上做视频图像的分析、识别和搜索。
今天我主要会为大家介绍图像的搜索过去、现在和未来,以电商为背景,包括其中的一些困难和机会在哪里,最后怎么样才能把电商的图像搜索做到比较好的效果。
![]() 热闹非凡的视觉识别和搜索
热闹非凡的视觉识别和搜索
这些年计算机视觉识别和搜索这个领域非常热闹,出现了很多的创业公司,大公司在这方面也花了很多力气在做。大家可以从下面的这张图里看到的一些例子。

亚马逊出品的Firefly当时引起了很大的轰动,虽然这个产品也很难说是不是成功,但是当时确实是很大胆的一个举动。百度也有图像搜索和图像识别,微软也有。Google很早也有了Google Goggles这个产品,虽然技术跟现在有很大的差别。Pinterest在去年也有这样的功能问世,就是在它自己的分享照片上,可以去搜相似的照片或者是相似的产品。当然这个搜索是用网上的图片去搜网上的图片,和我们今天要分享的还是有一点区别。阿里巴巴的一个图片搜索——拍立淘强调的是用自己手机去拍照片去搜索网上相同或者相似的商品。这两者听起来差不多,但是实际上在难度上是有很大的差别。

计算机视觉涉及到的领域有安防、广告、娱乐方面等各行各业,这些年尤其是在深度学习出现后,在技术上也有了很大的发展。那么是不是计算机视觉这个问题已经解决了?是不是几十年的图像搜索研究真的在我们的日常生活中可以用起来了?下面我们会来探讨这些问题。
![]() 热图像搜索的定义和分类
热图像搜索的定义和分类
图像搜索的方法从Query角度可分为三类:
-
以文本搜索作为搜索的入口。
-
以图像样例作为搜索的入口。
-
文本、图像的组合搜索。
文本搜索又可以细分为三种:
第一种,用人来对文本做标记
最早期上个世纪七八十年代时是很小的图片集, 是通过人来添加图像的文本标签,然后通过文本来搜索就够了。之后就发展到了2004年前后的社交媒体时代,那个时候像Flicker上图片的Tag,虽然也是人加的,但是通过草根人群加的,量就变得非常地大。通过这个也能做比较不错的图片搜索。再往后的标注就不是人给自己的图片加标签了,而是通过设计一些标注的平台——比较有名的是Google收购的Image Labeler——以游戏的方式对图片进行标注。这些标注当然可以用来做图像的搜索,这就是通过人工加文本标注的方式进行图像的搜索。
第二种,通过网页的文本对图片进行索引
目前的互联网通用图片搜索引擎,基本上都是基于这一套技术。通过网页的文本来对图片进行索引,当然这里面也涉及到很多的细节,包括怎样从网页上提取有效的文字,以及2008年之后也有很多图像分析的内容引进到基于网页的图片搜索里来。也就是说虽然图像是网页中的图片,但是也会对其进行内容分析——不管是打标签还是特征抽取等——来改进文本搜索存在的一些缺陷,提升搜索的精准性。
第三种,自动标注
大量的学术论文是这个方向上的,一种叫concept detection,或者叫tagging。规模上小到几十个、几百个,大到上千个、上万个的标签。这一类严格来讲又可细分为几类:
-
Predefined categories。比如预先定好只分一千类,然后就去训练一个分类器,把这个图片标好。
-
不限定标签的范围,或者说标签的范围非常大,然后去学习图片和标签的一个共同的描述方式,从而可以实现近似于free text的文本标注。
-
Implicit tagging,即隐式的自动标注。搜索引擎在运行的过程中,用户在搜索时会点击搜索结果,这个时候搜索的词和搜索的结果就通过被点击这个动作建立起了一个关联,这种方式也可以认为是一种标注。虽然它有一些噪声,但是实际上也是非常有效的,并且也可以用一些方法降低其噪声,甚至在相似图像之间传递标签,从而扩大标签的覆盖率。这种标注对基于网页的图像搜索引擎对搜索质量的提升起到了非常关键的作用。
当然文本的搜索不是我们今天介绍的重点,我们今天的重点讲的是基于图像的搜索。这个其实也可以分成两类,一类是图像本身作为查询输入(example-based),这也是我们今天重点要去看的。另外一个是sketch的画图方法,包括画形状、画线、画颜色分布等。
![]() 图像搜索——从火热到没落,再到兴起
图像搜索——从火热到没落,再到兴起
下面我们回到example-based的搜索主题,这个方向在图像搜索历史上也经历了不同的阶段。
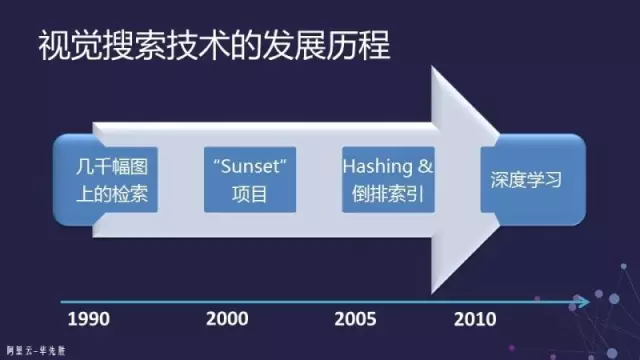
最早在二十世纪九十年代时,那个时候叫做CBIR(Content-Based Image Retrieval),即基于内容的图像检索。但是那时基本上只能在几千、几万幅图上进行检索,而且检索的效果很难保证。当时有一个一直流行到现在的词叫做“语义鸿沟”,这也是当时我们经常用来质疑基于图像的搜索或CBIR到底靠不靠谱。因为当时的特征难以区分下图所示的两种Case。

所以这个方向到了2000年之后,我们有时候开玩笑把它叫做Sunset Project,也就是像落日一样没有太大的希望了。这种基于样例的检索其实在之前也经常被人质疑:
-
样例从哪里来?如果我有了这个样例为什么还要搜索呢?当然这个问题从今天来看已经不是问题了,因为在上个世纪九十年代的时候,获取一个图像的样本还不是那么容易。在手机相机那么普及的今天,获取一个图像是易如反掌的,所以今天一般没有人会问这个问题。
-
只有像落日这样的颜色分布非常鲜艳且明确的图,搜索结果才会非常好,因此在很多时候我们的搜索结果不是很好。
图像搜索的没落直到2008年左右才有所起色,当时出现了一家叫TinEye的公司提供这样一种网络服务:你提交一个图片后,它可以帮你找互联网上跟此图非常相似的图片。这在当时引起了非常多的讨论,也就是说它解决了当时那些技术无法解决的scalability的问题。
那么这个scalability是个什么意思呢?做图像的检索当图片的量非常大时,是没有办法把Query图像的特征与数据库里面的图像进行一一对比的。以现在的计算能力,如果图像只有几千个甚至上万个问题都不是很大的。但是当你的图像再往大,到千万、亿级,甚至到十亿、千亿级别的时候就没有办法了。
所以此时就要把图片进行索引。索引在文本搜索里面是通过倒排的方法来做,这个是非常容易实现的。但是图像不一样,图像的描述是它的特征,而这个特征是一个向量。这个向量怎样能够有效地组织起来实现快速地检索,这是当时TinEye系统往前走了一步的问题。

上面这张图是尽我所知把当时和后来的Large Scale Image Indexing的方法分了四类,也就是用高维的特征怎样去建索引的方法。这些方法都是在解决怎样把高维空间的数据组织起来而方便查找的问题。
-
Partition tree:是用各种各样tree的方法,把数据进行分割、分块,使得查找起来比较方便。
-
Hashing:关于图像搜索的Paper基本上都是在做Hashing。
-
Neighborhood Graph:用邻接图的方法来建索引的方法。
-
Invert Index:把所有的图像特征转化成视觉词,然后用倒排的方法来做。
这几个方法之间基本上都是可以互相转化的,当然转化时有时是有信息损失的。如果做大规模的、数据量非常大的图像搜索,我个人认为用倒排的方法来做比较合适。
以上是关于索引这一部分。但是索引这件事情解决了之后,是不是就解决了基于内容的图像搜索问题?很遗憾,实际上是没有的。因为索引只是解决了scalability的问题,而且这些方法在做有效性的评估的时候,都是与brute-force的方法来比,也就是和一个一个比距离的方法来比,来判断索引的方法和brute-force有多接近。但是,图像的表征问题,也就是怎么样有效描述这个图像的问题,还没有很好地解决。只有描述得好才能够比较两幅图像——基于内容的图像搜索问题实际上就是两个图像比较的问题。当然一个真正的搜索系统,其实比这个要复杂得多,但它最核心的问题是两幅图像怎么比较。
![]() 深度学习的威力
深度学习的威力
如上所说,还有一个问题是当时没有解决的,就是什么样的特征才是有效的,即可以让我们“认为的”相似的图像在特征上也是相似的,特征上相似的也是我们认为相似的,这样一个问题。
这个问题真正取得进展确实是在深度学习出来之后,它可以让我们去按照自己所想要达到的目标,去学习一个神经网络,通过这个神经网络去抽取图像的特征。
实际上搜索跟识别是密不可分的,尤其是在做大规模图像搜索时,识别、检测必不可少。识别有时也是要通过搜索来完成的,例如,如果你类别非常多的时候,往往要通过搜索的方法来实现,而不是通过模型的方法来做识别。所以搜索和识别在大数据时代的界限变得越来越模糊了,它们之间互相需要,互相利用。
![]() 五. 图像搜索系统的四个基本要求
五. 图像搜索系统的四个基本要求
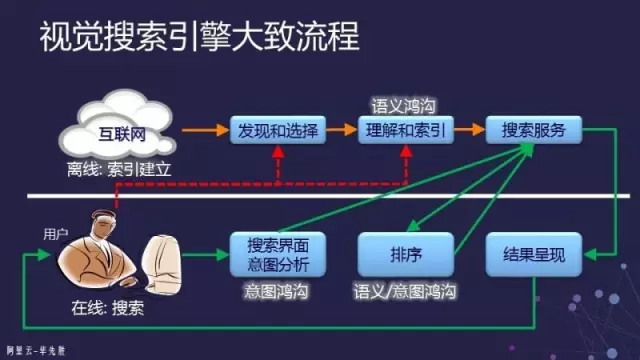
上图是一个通用的视觉搜索或者图像搜索的大致流程。一个视觉搜索引擎分成两块:
-
在索引建立的过程,首先我们要到互联网上去找到这些图,发现它以后还要选择它。看起来简单的两个词——发现和选择,里面包含的文章却很多。因为互联网上的图很多,不可能把所有的图都放在索引里面去,这时候就涉及到应该把什么图放进去才能满足用户的搜索需求。这个要求是说选择出来的图片应该能满足当前时间点上大部分人搜索的需求就可以了,这实际上会转换成为一个机器学习的问题来解决。
-
选择好后就要进行理解和索引:要知道这个图片里有什么内容。如果基于网页,就要从网页上抽信息;如果是完全基于图像,就要抽取图像的特征进行理解并建索引。建立索引以后,再把这些索引推到搜索服务的机器上去,比如一个互联网图片搜索引擎,这个时候可能要几千台机器才能hold住这个图片库的索引。
那么这样的图像或者视觉搜索系统,在宏观上来看应该有一些什么样的要求呢?我总结为以下四个方面:

首先是相关性,这是一个最基本的要求。也就是说当给了一幅图像进去,出来的东西要跟给出的图像要是相关的。如何定义“相关”?一般对于图片搜索而言,基本上是认为“跟它一样”,或者是“相像”。例如产品,同款产品不管颜色是否一样,但它是相同的东西,这就叫做相关性。相关性一般来说是做搜索的人最关心的一个问题,在关于图像搜索的学术论文里面,基本上我们大多只关心这个问题。
第二个是覆盖率,这就跟产品非常相关。这里面有好几个因素,最直接的一个就是我希望搜什么都能给我结果。不是我只能搜衣服,不能搜其他的商品;或者我只能搜商品,又不能搜别的东西。否则用户的体验就很不好。甚至是在电商的搜索引擎里面,如果用户输入了一个非商品,我们该怎么反馈给用户?这都是涉及到覆盖率的问题。
伸缩性主要是两方面的问题:1)是否能够高效快速地处理大量的商品和商品的变化,即是否能够非常快速地将大量商品放到索引里面去,而且索引能够很方便地更新。也就是对于商品建造索引过程而言的一个伸缩性。2)能否响应大量用户的搜索请求。即当有大量的用户同时访问搜索服务时,要能够快速地响应所有的请求。
用户体验比较偏交互式用户界面设计方面,因此在此处不做详述。
![]() 图像搜索的主要应用领域
图像搜索的主要应用领域
图片搜索经常被质疑的是,到底什么情况下会用到图像搜索,为什么要用图像搜索?这个问题从上个世纪到现在一直不断的被提及。我总结一下,图像搜索主要可以在以下领域应用:
-
信息的获取。例如这个图片的对象是什么、在哪里,这个人是谁,或者这个花是什么。
-
拍照购物。当看到一个商品,我不知道怎么用文字描述它,能不能通过照片来搜索?这个会在后面具体讲述。
-
娱乐。例如一些视频、电影、新闻、体育等也可能涉及一些搜索的问题。
-
监控。监控里面可能涉及到的搜索。
-
其他。我个人认为,目前端到端的应用,电商拍照购物搜索是最solid的一个应用场景。
电商的图片搜索跟一般的图片搜索相比,其实有更多的挑战:
-
用户对相关性的期望更高。因为它的目的性非常明显,用户搜索完了是要买东西的,所以对相关性的期望也非常地高。
-
对覆盖率的期望也非常高。比如用户在尝试“衣服”可以搜到之后,他可能就会继续搜“鞋子”,鞋子搜完以后可能又会搜花、插座等。
-
用户所查询的图像质量变化非常大。比如搜索一个玻璃杯,它可能是透明的,可能有反光、曝光不足、模糊,甚至拍的东西是倒的等各种情况。
-
对系统性能要求很高。用户会希望马上就获得结果,你如果在后台算两三分钟才给到结果,肯定大家都跑掉了。
-
有非常具体的衡量标准。如果做算法的话,经常会有一些衡量标准,但是这些标准是不是真的对之后的业务是合适的一个标准呢?
实际上在做真正的产品应用时,我经常讲一个叫做“照妖镜”的东西,就是衡量这个东西到底做得有没有道理。比如UV(独立的访客量)是多少、GMV(成交的金额)是多少、转化率有多高,这些都是照妖镜。但照妖镜也不是只跟算法有关,也会跟其他的产品设计有关——但最关键的还是系统的相关性和覆盖性以及伸缩性。
当然我们的机会也是很多的,因为在电商这个领域,除了基础的技术(分布式计算的技术、深度学习的技术)外,首先商品的量非常多,商品的图片非常多;第二个是用户的量非常大,这也让这个事情有了更多的机会。
![]() 商品图像搜索的关键技术
商品图像搜索的关键技术
现在以电商的图片搜索作为背景,具体阐述其关键技术的实现。
1. 相关性

首先,要知道一个图片的大致类型。例如,如果是一个商品,需要知道它到底是上衣——是男士的上衣还是女士的上衣,还是鞋子等。这样来避免搜索出的结果完全不靠谱,这个我们一般把它叫做分类或识别。通过这个其实也可以看到,识别在搜索里面也是非常的关键,第一步也是必不可少的。

第二个问题是图片中我感兴趣的商品在哪里?如果我们不做商品检测或者主体检测,通常商品不是很大,且背景也比较复杂,而电商图片数据库里很多都是这种图。其实复杂的背景对于电商的商品销售量也是有影响的,我们做过研究,如果照片拍的背景比较好,如街拍等,其实是会促进商品的销售的。
所以我们要做主体的检测。主体的检测方法在计算机视觉领域也有很多,快速的方法基本上是先要找Proposal Window,然后对其进行分类。这个场景通常要求速度非常快,一个搜索请求进来后,所有的操作——包括上述分类、主体检测以及后面的一些步骤到最终的返回结果——都是要在几百毫秒之内返回给用户的。因此我们的Proposal Window就不能那么多,否则计算量就相当的大,所以这就会涉及到后续Proposal Window的refinement这样一个步骤。

当已经知道这个商品在图片中的位置后,更关键的一条是到底用什么特征来描述商品呢?如何能让这个特征反映出商品的特性呢?这也就是前面讲过的,怎样让这个特征可以去比较两幅图像——也就是两个商品。
基本方法还是是利用深度学习这个工具,force神经网络收敛到一个地方,使得特征输出能够反映出这个商品的特性,例如些种类、风格、图案、颜色等。
综上,可以从三个角度在很大程度上解决相关性的问题,也就是从分类、主体的检测以及图像特征的角度让相关性得到很大的改善。
2. 覆盖率
覆盖率对用户的体验有相当大的影响——如果只能搜到这个而搜不到那个,或者本来应该搜到的商品但是没有找到,这样用户体验都会非常不好。
我把覆盖率分为三个角度来讲——
-
索引的覆盖率。这是我们一般提到覆盖率时所指的含义。简单说就是索引里多少货(商品),当然是越多越好,种类越全越好,这个比较容易理解。
-
特征的覆盖率。特征的覆盖率是指商品的描述能够覆盖各个种类,不是只能做鞋子或只能做服装,而不能做别的东西,甚至非商品是不是能做。为了描述的精准、描述能力的优化,实际上不同的类型一般用不同的特征来描述。
-
搜索的覆盖率。这个覆盖率是电商场景下所独有的,因为电商只有商品图像的索引,没有别的索引,那么用户如果输入的不是电商产品的图片该怎么办?比如用户在街上看到一条很可爱的狗并拍照后在平台上搜索,该怎么处理呢?——淘宝上可能没有卖狗的吧!这个时候我们可以把狗识别出来,然后返回给用户一些狗相关的产品,这是一种解决方案。如果是风景、食品的话,也可以对风景进行识别,对食品里面的热量进行识别,然后把这些信息返回给用户。
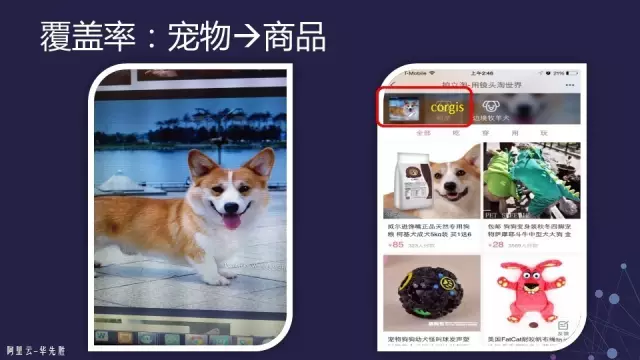
如果一定要返回电商商品的话,比如用户拍了一朵花,也可以force搜索引擎还是到fashion这个领域去搜,那么搜出来的衣服、饰品就会跟用户输入的图像有一点关系,看上去在某个方面很类似(如下图)。
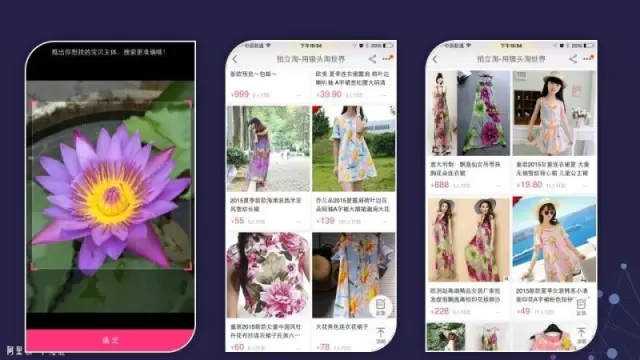
下图的例子很有意思,照片上是一个晚上的桥,通过它搜出来的东西很有意思:是格子样式很像这个桥的线条的上衣。

3. 伸缩性
伸缩性的实现方式主要有两种:
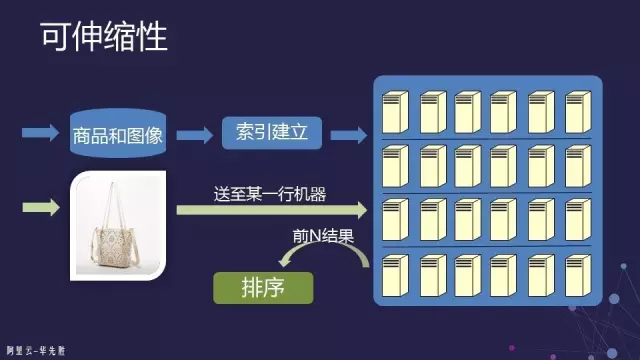
-
通过系统的方法,也就是通过大量的机器来实现。索引技术有了系统的方法来实现,因此对索引的要求其实没有那么高,有很多方法都可以完全满足搜索系统的构建需求。正如讲搜索引擎架构时所述,索引会分到很多机器上去,那么只要做到每一台机器上的数据搜索效率足够高的话,那么这个系统就可以完成大规模的搜索任务。
-
对于算法而言,就集中在一台机器上怎么样做到高效。那么一台机器上怎么做到高效,前面讲到的图像各种方法都可以用。
以上是关于电商图片搜索的内容,最后再给大家分享一些电商搜索产品的例子。下面这个产品叫做“拍立淘”,在手机淘宝搜索框的右边有一个小的摄象头图标,点这个图标就能进入“拍立淘”的界面。

以下是“拍立淘”图片搜索的一些例子。

总结而言,对于一个真正的应用产品来讲,视觉搜索和图像识别确实仍有很多的挑战,但同时也有很多的机会。尤其是现在这个时代,技术方面有深度学习的技术、大数据分析处理的技术,包括分布式计算这样一些平台。数据的获取也非常容易,人人都有手机,每个手机又都有相机,就有了大量的图形数据和大量活跃的用户,使得有机会让图像搜索的问题得到本质上的改善。虽然目前这个问题还没有完全解决,但是实际上在拍立淘里你也可以看到很多实际的例子,真的迈出了很大一步。

![]() 图像搜索的明天
图像搜索的明天
展望图像搜索和识别技术的未来,我个人认为这可能不是某一个算法能解决的,也不是仅凭深度学习就可以解决的,也不是说一个搜索系统、识别系统就可以解决的。我认为是四个方面结合起来:数据、用户、模型和系统。这四个方面放在一起,可能不断地缩小语义鸿沟,使得我们的搜索“所想”就能够得到“所得”。
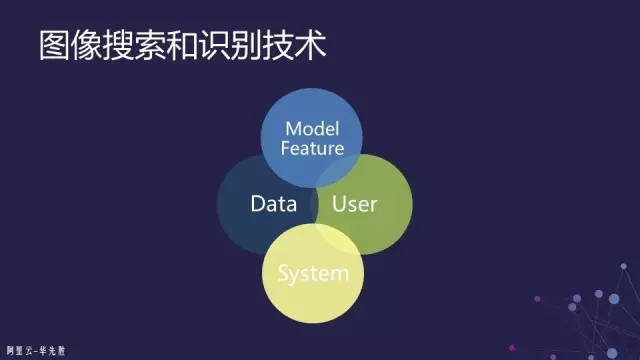
如果大家有兴趣的话,我现在阿里云带领视觉计算组,云上也涉及到一些视频搜索的任务,更多的还是识别、还有很多视频处理、视频分析、视频识别等这些方面的一些需求,包括教育、医疗方面、娱乐方面、体育方面可能都会有。

如果有想加入到我的项目组的朋友,欢迎发送简历到 [email protected]。
-END-