/* 版权声明:能够随意转载,转载时请务必标明文章原始出处和作者信息 .*/
author: 张俊林
节选自《大数据日知录:架构与算法》十四章。书籍文件夹在此
Pregel是Google提出的大规模分布式图计算平台,专门用来解决网页链接分析、社交数据挖掘等实际应用中涉及的大规模分布式图计算问题。
1.计算模型
Pregel在概念模型上遵循BSP模型。整个计算过程由若干顺序运行的超级步(Super Step)组成,系统从一个“超级步”迈向下一个“超级步”,直到达到算法的终止条件(见图14-13)。
Pregel在编程模型上遵循以图节点为中心的模式,在超级步S中。每一个图节点能够汇总从超级步S-1中其它节点传递过来的消息,改变图节点自身的状态。并向其它节点发送消息。这些消息经过同步后。会在超级步S+1中被其它节点接收并做出处理。用户仅仅须要自己定义一个针对图节点的计算函数F(vertex),用来实现上述的图节点计算功能。至于其它的任务,比方任务分配、任务管理、系统容错等都交由Pregel系统来实现。
典型的Pregel计算由图信息输入、图初始化操作,以及由全局同步点分割开的连续运行的超级步组成,最后可将计算结果进行输出。

每一个节点有两种状态:活跃与不活跃,刚開始计算的时候,每一个节点都处于活跃状态,随着计算的进行,某些节点完毕计算任务转为不活跃状态,假设处于不活跃状态的节点接收到新的消息,则再次转为活跃,假设图中全部的节点都处于不活跃状态,则计算任务完毕,Pregel输出计算结果。
以下以一个详细的计算任务来作为Pregel图计算模型的实例进行介绍,这个任务要求将图中节点的最大值传播给图中全部的其它节点,图14-14是其示意图,图中的实线箭头表明了图的链接关系,而图中节点内的数值代表了节点的当前数值,图中虚线代表了不同超级步之间的消息传递关系,同一时候,带有斜纹标记的图节点是不活跃节点。

从图中能够看出。数值6是图中的最大值。在第0步超级步中,全部的节点都是活跃的,系统运行用户函数F(vertex):节点将自身的数值通过链接关系传播出去,接收到消息的节点选择当中的最大值,并和自身的数值进行比較,假设比自身的数值大。则更新为新的数值。假设不比自身的数值大,则转为不活跃状态。
在第0个超级步中,每一个节点都将自身的数值通过链接传播出去,系统进入第1个超级步。运行F(vertex)函数。第一行和第四行的节点由于接收到了比自身数值大的数值。所以更新为新的数值6。
第二行和第三行的节点没有接收到比自身数值大的数,所以转为不活跃状态。
在运行完函数后。处于活跃状态的节点再次发出消息。系统进入第2个超级步。第二行节点本来处于不活跃状态。由于接收到新消息。所以更新数值到6。又一次处于活跃状态,而其它节点都进入了不活跃状态。Pregel进入第3个超级步,全部的节点处于不活跃状态,所以计算任务结束,这样就完毕了整个任务,最大数值通过4个超级步传递给图中全部其它的节点。
算法14.1是体现这一过程的Pregel C++代码。

2.系统架构
Pregel採用了“主从结构”来实现总体功能,图14-15是其架构图,当中一台server充当“主控server”,负责整个图结构的任务切分,採用“切边法”将其分割成子图(Hash(ID)=ID mod n ,n是工作server个数)。并把任务分配给众多的“工作server”,“主控server”命令“工作server”进行每一个超级步的计算。并进行障碍点同步和收集计算结果。“主控server”仅仅进行系统管理工作,不负责详细的图计算。
每台“工作server”负责维护分配给自己的子图节点和边的状态信息,在运算的最初阶段。将全部的图节点状态置为活跃状态,对于眼下处于活跃状态的节点依次调用用户定义函数F(Vertex)。
须要说明的是。全部的数据都是载入到内存进行计算的。除此之外,“工作server”还管理本机子图和其它“工作server”所维护子图之间的通信工作。
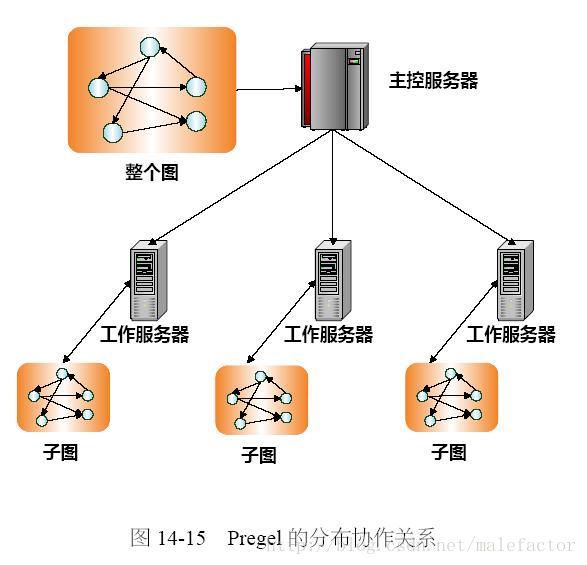
在兴许的计算过程中,“主控server”通过命令通知“工作server”開始一轮超级步的运算。“工作server”依次对活跃节点调用F(Vertex),当全部的活跃节点运算完毕,“工作server”通知“主控server”本轮计算结束后剩余的活跃节点数,直到全部的图节点都处于非活跃状态为止。计算到此结束。
Pregel採用“检查点”(CheckPoint)作为其容错机制。
在超级步開始前,“主控server”能够命令“工作server”将其负责的数据分片内容写入存储点。内容包含节点值、边值以及节点相应的消息。
“主控server”通过心跳监測的方式监控“工作server”的状态。当某台“工作server”发生问题时。“主控server”将其负责的相应数据分片又一次分配给其它“工作server”,接收又一次计算任务的“工作server”从存储点读出相应数据分片的近期“检查点”以恢复工作。“检查点”所处的超级步可能比方今系统所处的超级步慢若干步。此时,全部的“工作server”回退到与“检查点”一致的超级步又一次開始计算。
从上述描写叙述能够看出,Pregel是一个消息驱动的、遵循以图节点为中心的编程模型的同步图计算框架。
考虑到“主控server”的功能独特性和物理唯一性。非常明显,Pregel存在单点失效的可能。
请思考:在容错周期选择方面,每一轮超级步都能够进行一次,也能够选择相隔若干超级步进行一次,那么这两种做法各自有何优缺点?
解答:假设选择较短周期的容错措施,在完毕任务的过程中。须要的额外开销会较多,可是优点在于假设机器发生问题,整个系统回退历史较近,有利于任务尽快完毕;较长周期的容错措施正好相反,由于频次低。所以寻常开销小,可是假设机器发生问题,则须要回退较多的超级步。导致拉长任务的运行过程。
所以这里也有一个总体的权衡。
3.Pregel应用
本节通过若干常见的图计算应用,来说明Pregel框架下怎样构造详细的应用程序。
(1)PageRank计算
PageRank是搜索引擎排序中重要的參考因子,其基本思路和计算原理在本章前面有所说明。此处不再赘述。以下是利用Pregel进行PageRank计算的C++演示样例代码。

Compute()函数即为前面介绍的针对S超级步中图节点的计算函数F(Vertex)。用户通过继承接口类Vertex并改写Compute(MessageIterator* msgs)接口函数,就可以高速完毕应用开发。当中MessageIterator* msgs是S-1超级步传递给当前节点的消息队列。该计算函数首先累加消息队列中传递给当前节点的部分PageRank得分,之后依据计算公式得到图节点当前的PageRank得分,假设当前超级步未达循环终止条件30次。则继续将新的PageRank值通过边传递给邻接节点,否则发出结束通知。使得当前节点转为不活跃状态。
(2)单源最短路径
在图中节点间查找最短的路径是非经常见的图算法。所谓“单源最短路径”,就是指给定初始节点StartV,计算图中其它随意节点到该节点的最短距离。以下是怎样在Pregel平台下计算图节点的单源最短路径的C++代码演示样例。

从代码中可看出,某个图节点v从之前的超级步中接收到的消息队列中查找眼下看到的最短路径,假设这个值比节点v当前获得的最短路径小。说明找到更短的路径,则更新节点数值为新的最短路径,之后将新值通过邻接节点传播出去。否则将当前节点转换为不活跃状态。在计算完毕后,假设某个节点的最短路径仍然标为INF,说明这个节点到源节点之间不存在可达通路。
(3)二部图最大匹配
二部图最大匹配也是经典的图计算问题,以下给出Pregel利用随机匹配思想解决该问题的一个思路。


上面的Pregel程序採用随机匹配的方式来解决二部图最大匹配问题。每一个图节点维护一个二元组:('L/R',匹配节点ID),'L/R'指明节点是二部图中的左端节点还是右端节点,以此作为身份识别标记。二元组的还有一维记载匹配上的节点ID。
算法运行经过以下四个阶段。
阶段一:对于二部图中左端尚未匹配的节点。向其邻接节点发出消息,要求进行匹配。之后转入非活跃状态。
阶段二:对于二部图中右端尚未匹配的节点。从接收到的请求匹配消息中随机选择一个接收。并向接收请求的左端节点发出确认信息,之后主动转入非活跃状态。
阶段三:左端尚未匹配的节点接收到确认信息后,从中选择一个节点接收,写入匹配节点ID以表明已经匹配,然后向右端相应的节点发送接收请求的消息。左端节点已经匹配的节点在本阶段不会有不论什么动作,由于这类节点在第一阶段中根本就没有发送不论什么消息。
阶段四:右端尚未匹配的节点至多选择一个阶段三发过来的请求,然后写入匹配节点ID以表明已经匹配。
通过上述相似于两次握手的四个阶段的不断迭代,就可以获得一个二部图最大匹配结果。