----本节内容-------
1.大数据基础
1.1大数据平台基本框架
1.2学习大数据的基础
1.3学习Spark的Hadoop基础
2.Hadoop生态基本介绍
2.1Hadoop生态组件介绍
2.2Hadoop计算框架介绍
3.Spark概述
3.1 Spark出现的技术背景
3.2 Spark核心概念介绍
4.Spark运行模式
4.1.Spark程序组成
4.2.Spark运行模式
5.参考资料
---------------------

1.大数据基础
1.1 大数据平台基本框架
从全局了解一下大数据技术的基本框架,在宏观上有个认识,不至于盲人摸象。董先生贴出来的这个图,可以说是非常通用且普遍的一张图, 不管你是哪个行业,框架用这个套,准没错。通用就是大而全的东西,不会考虑细节了。在实际生产中,每一个细节都不是省油的灯。当然 全局的整体把握,对spark理解非常重要,它在整个体系中扮演什么角色,这个很基础 。
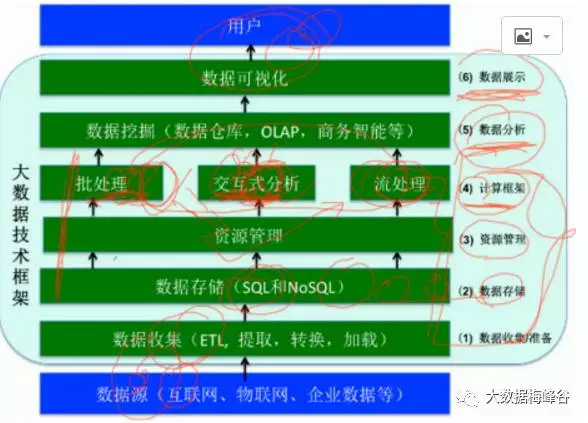
整体架构分为6个层面
1) 数据收集
数据采集,是汇聚的一个过程,如淘宝,商家,用户,用户行为,买其他公司数据,数据集市等,要收集数据过来,使用的技术组件有Flume、kafka、Ftp、Sqoop、DataX等等。一些自己走的坑,主要有:a.稳定和安全,生产中首要是确保生产,不能把对端系统给搞瘫了,很多时候,对端系统已经弱不禁风了,达到了各种瓶颈,如网络带宽,内存和CPU硬件限制等,汇聚数据稍加马力,就要出事(曾经sqoop抽oralce生产库,不知道对端oralce那么脆弱,上来就猛一抽,完蛋);b.网络复杂,跨网段的数据汇聚,很头疼,做过几次汇聚,网络有N多种,公安网、视频专网、政务网、互联网,经过各种跳转机和网闸等等,各种网络限制,很可能别人鼓吹的神器,因为网络问题,都是浮云,c.数据质量垃圾,不敢恭维,数据能拿过来了,但是数据质量真的都不敢恭维,ETL工作做起来,杀人的心都有,d.跨部门沟通和协调问题,人的问题永远比技术问题还要难解决,是你主动过去取,还是让人家送过来,是你去协调别人,还是别人来找你要做数据汇聚,这是一个问题;沟通是一门艺术,coding则是一门技术。
2)存储数据
传统关系型数据库,很难存海量数据,采用分布式的架构,其实分布式存储数据并不是传统数据库不能解决的问题,oralce也能做到集群,mysql也没问题,关键的关键还是如何将存起来的数据用起来,除非你真的只想做个网盘。
3)资源管理
一般公司都不仅仅是做网盘,还有挖掘,分析,产生价值,管理cpu,内存等资源,资源管理系统来管理,上百台,千台,分布式集群的资源管理很讲究。
4)计算层
分布式程序作分析和挖掘, 分三类:批处理,交互式分析,流处理。
批处理:10T的数据如何处理,分布式的程序进行处理,讲究高吞吐率,对时间要求不严格,分钟或者消失级别
交互式分析:很多数据,通过语言表达查询意图,马上反馈结果,支持sql,速度足够快, 2~3秒,交互的,时间长就不是交互了,秒级;
流式处理:对时间要求很高,毫秒级处理完数据,不想批处理那样,数据来了就处理
spark可以解决这三类问题。
5)数据分析层
偏向平台,比较通用,银行,电商,都可以用这些引擎来分析问题,改成和应用相关
6)数据可视化
很重要,很多创业公司在做这个,并且根据行业细分,做的都非常不错。
spark在第四层,不做收集,资源管理,数据存储,可视化,仅仅是一个计算框架,可以解决很多实际问题,不是大数据的全部,是数据分析技术
问题1:为什么不采用oralce技术来实现大数据?
oralce不能解决所有的问题,l虽然oralce有load加载数据,oralce也能做做存储,不需要做资源管理,一个节点而已,能做sql做分析,但是数据小可以,没问题;数据大了,收集,存储,都要拿出来做独立模块,各种模块和场景都很复杂,oralce打包一起做不了。
问题2:如何实现大数据平台?
可以自己玩,在生产中可以使用ambari或者CM这样的部署工具来搭建大数据平台,自己搭建和运维;也可以用别人搞好的服务,,如用阿里云,付钱,每个环节都实现了, 也可以google、亚马逊,数据放在他们那里,不安全 。在国内,属于劳动力密集型的地方,很多企业都愿意自己搭建运维,各种坑自己一个个的趟过去;而在国外,如欧洲,人力成本贵的要命,宁愿花钱买别人的服务,而且他们相信专业的人干专业的事情。
1.2 基本技能素养
大数据之所以有点学习的门槛,其实不是因为它有多难,而是要有一颗耐的主寂寞的心,有些人看到这幅图可能就要打退堂鼓了。这些技术栈不见得非要精通,至少得用到知道怎么百度和google,能迅速上手,基于我自己对大数据技术的理解做如下阐述,

linux基础:linux得入门啊,最基本的命令得会,这个没有入门的,推荐一下老男孩的linux运维系列视频课程
编程语言:java,scala,python
开发工具: (1) intellij开发工具,scala程序推荐该工具,eclipse对scala支持的比较差,高亮,自动提示等都比较若,(2)maven项目构建工具,好好学习一下,如何 打包测试,发布;(3)代码管理工具git,使用git来下载和管理代码
hadoop生态组件:hdfs、yarn、pig、hive和zookeeper等
不求样样精通,你不是神,根据职业角色划分,有所侧重。角色划分我的有限理解,通常有做Hadop平台运维、大数据ETL开发、数据建模分析、大数据可视化等等,每一个工种角色都不一样,掌握技能侧重点也不一样。
1.3 Hadoop生态系统基础
Hadoop生态组件是Spark的学习基础,Spark建立在HDFS之上,是Mapreduce的改良,使用Yarn做资源调度,通过Zookeeper做主节点的HA,所以学习Spark至少也有点Hadoop的基础。另外对于Spark有几个言论误解,主要有:(1)spark会取代hadoop,其实不然,他们不是不是一个量级的东西,是一个生态系统,Spark就是一个小小的组件,只是逐步替代Mapreduce编程;(2)Spark诸如强Hadoop百倍,也不全然,只能说个别场景如此,谣言止于智者。
2.Hadoop生态基本介绍
2.1Hadoop生态组件介绍

2.Hadoop生态基本介绍
2.1Hadoop生态组件介绍
1)HDFS和Hbase
· HDFS
分布式文件系统,它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
必须要有HDFS的基础,明白HDFS的基本架构,基本的文件管理,如block、文件、目录等,熟悉基本的HDFS shell操作。1G数据,默认是几个block,5个节点,这些数据会存在哪几个节点.来自一篇论文,有13年时间了,GFS,很经典,hdfs是gfs的克隆版,google没有开源、容错性好,互联网公司抠门,常常是购买x86的机器,经常挂掉,所以要容错好;节点,机器,都是一台服务器,【同通常配置是24个cpu,128G内存,磁盘12*3T】,2万左右的RMB,挂掉 数据不会丢,一个文件切分成多个文件,存放在不同的节点上,一个文件多份,为并行化提供存储的基础,切成几块,并行都就是多少,【16个并行读,16个block】
基本原理:将文件且纷成等大的数据块block,默认是128M,存储在多台机器上;将数据切分、容错、负载均衡等功能透明化;可将HDFS看成是一个容量巨大的、具有高容错性的磁盘。
应用场景:海量数据的可靠性存储、数据归档
基本架构:主从架构,主节点会做HA,数据存放在datanode。
Hbase
HBase是一个针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。和传统关系数据库不同,HBase采用了BigTable的数据模型:增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。数据模型:Schema-->Table-->Column Family-->Column-->RowKey-->TimeStamp-->Value
2)YARN
群的资管管理和调度,在yarn上跑各种程序,spark不一定泡在yarn上,也可以mesos,甚至裸集群上,有很多分布式特点,扩展,容错,并行
是什么? Hadoop2.0新增的资源管理系统,负责集群的资源管理和调度,使得多个计算框架可以运行在一个集群上。
啥特点? 良好的扩展性、高可用性,对多种类型的应用程序进行统一管理和调度,自带多种用户调度器,适合共享集群环境。
要熟悉YARN的基本架构,各个角色的功能和交互流程,资源管理的基本方法等。
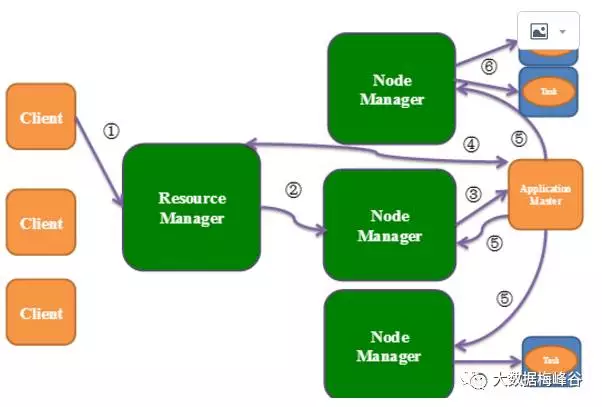
执行流程:
a.nodemanager管理资源,将资源,有cpu,内存等汇报给resourceManager,统一管理
b.客户client要执行任务
client查找rm->rm找nodemanager->rm找到nodemanager资源后,将资源分给client->client就直接去找nodemanager->nodemanager执行任务
3)MapReduce和Spark
Mapreduce
源自goole开源的mapreduce论文,发表于2004年12月,是google Mapreduce的克隆版MapReduce是一种计算模型,用以进行大数据量的计算。其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。要掌握MapReeduce的基本编程模型,WordCount的执行流程。Spark经常和mr对比,经典的最好是了解,不要一无所知,只能说你太虚伪了。
特点:良好的扩展性、高容错性、适合PB级以上海量数据的离线处理;分布式错误是一个正常现象,常态。转为2个阶段,map和reduce,就是计算机里面的汇编语言,难用

Spark:UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点,支持整个目录读取支持通配符读取支持压缩文件读取,基于gz的压缩不带分片参数,会将每个block创建一个分片,每个分片上运行一个task支持读取目录中的小文件, 支持整个目录读取支持通配符读取支持压缩文件读取,基于gz的压缩不带分片参数,会将每个block创建一个分片,每个分片上运行一个task支持读取目录中的小文件
4)Hive和Pig
Hive:由facebook开源,最初用于解决海量结构化的日志数据统计问题。Hive定义了一种类似SQL的查询语言(HQL),将SQL转化为MapReduce任务在Hadoop上执行。
通常用于离线分析。
Pig:由yahoo!开源,设计动机是提供一种基于MapReduce的ad-hoc(计算在query时发生)数据分析工具定义了一种数据流语言—Pig Latin,将脚本转换为MapReduce任务在Hadoop上执行。
通常用于进行离线分析。
5)Oozie和Zookeeper
Zookeeper:源自Google的Chubby论文,发表于2006年11月,Zookeeper是Chubby克隆版解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
6)Flume和sqoop
Sqoop是SQL-to-Hadoop的缩写,主要用于传统数据库和Hadoop之前传输数据。数据的导入和导出本质上是Mapreduce程序,充分利用了MR的并行化和容错性。
Flume:Cloudera开源的日志收集系统,具有分布式、高可靠、高容错、易于定制和扩展的特点。
它将数据从产生、传输、处理并最终写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在Flume中定制数据发送方,从而支持收集各种不同协议数据。同时,Flume数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。此外,Flume还具有能够将日志写往各种数据目标(可定制)的能力。总的来说,Flume是一个可扩展、适合复杂环境的海量日志收集系统。
7)Ambari
由hortworks开源,是一种基于Web的工具,支持Apache Hadoop集群的供应、管理和监控。Ambari目前已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeper、Sqoop和Hcatalog等。1000个机器,如何部署,拷贝数据都考死人,自动化安装工具ambari,点击鼠标自动安装,修改配置,启动服务。
目前来说,只有可视化功能,hadoop生态系统没有提供,
2.2 Hadoop计算框架介绍
通常来说,计算引擎的分类,
1)批处理:对时间没有严格要求,离线分析,不关系时间,关注吞吐率
2)交互式:支持sql,对数据进行快速分析,人机交互,时间要求高
3)流式处理:流水一样流入系统,实时分析,来一条处理一条。对每一条数据时间要求高,吞吐率要求不高
4) 迭代式与DAG计算:机器学习算法,离线分析
当然有些公司也有自己的划分方法,比如hortworks(已经上市了的大数据公司),划分方式:
用时间来划分0~5秒实时分析,和其他公司划分就不一样,比如在线查询有些公司要求毫秒,作为参考而已
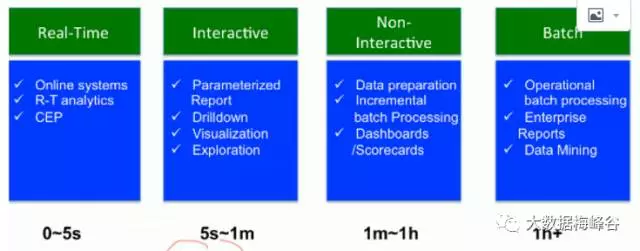
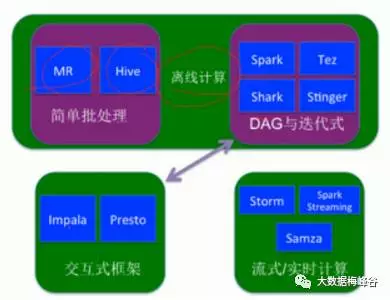
hortworks将计算框架也划分了几类
简单批处理:MapReduce和hive
DAG与迭代式: tez逐步替代hive,Spark替代shark,简单批处理和DAG迭代式都是离线分析
交互式框架:Impala,Presto
流/实时计算:Stoam,Samz,Spark Streaming
涵盖三类应用场景,如果spark能解决的就用spark把,Spark架构如下
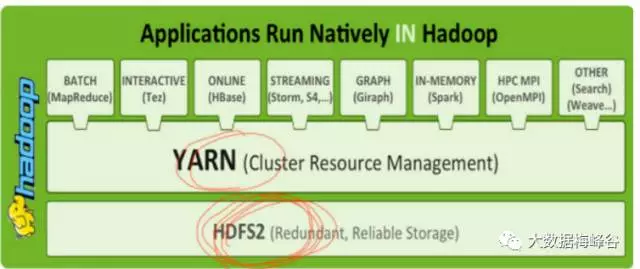
1)计算框架
分布式,基于内存,弹性
2)数据存储
在hadoop生态系统,如hdfs,hbase,分布式存储引擎
3)资源管理
由yarn管理,或者mesos等,有一个内核,spark core,在这之上,构建了很多计算引擎,方便用户编写
4)spark sql
写sql,将sql转为spark程序
5)spark streaming
6)graphx:图计算
7)MLLib:机器学习,通用的机器学习算法,聚类,分类,避免重复造轮子
8)Spark R:用r语言写spark程序
Spark不是一门孤立的技术,社区很活跃,支持linux和windows;微软怕被淘汰,给大数据社区贡献了一些windows运行的patch,但依然很少有人用,spark不断在发展过程中,版本的升级都是内核变动,api层很少变动,一般不会该使用和优化为主,
3.Spark概述
3.1 Spark出现的技术背景
1)Mapreduce的局限性
mapreduce框架的局限性主要表现在
· 仅仅支持map和reduce两种操作
· 处理效率低(中间结果写磁盘,多个mr之间通过hdfs交换数据;任务调度和启动开销大;无法充分利用内存,不管什么操作map和reduce都要排序),为什么写磁盘,因为当时磁盘便宜,内存贵,现在内存很便宜。
· 不适合做复杂的计算,如迭代计算,如机器学习图计算、交互处理和流计算。
· 编程不灵活,基本就是分布式编程界的汇编语言。
2)各种计算框架多样化
spark之前,很多,各种框架部署和管理都比较乱,spark可以同时解决这三种场景,学习一类解决三类问题,写程序和管理都很简单。 现有的各种计算框架各自为战,批处理mapreduce、Hive、Tez,流式计算storm,交互式计算Impala,Spark同时处理批处理、流计算、交互式计算等。
3)Spark特点
· 高效:快10~100倍,取决于逻辑和具体的计算,内存计算引擎,提供驾驭内存的机制,灵活利用内存,DAG的计算杨引擎,减少开销,使用多线程,减少启动开销,shuffle减少不必要的开销和磁盘IO。
· 易用,非常丰富的API,支持JAVA,scala,pyhon,R四种语言,spark之前,scala很小众
spark带动scala的销量,scala代码少2~5倍,更短,出错更少,
·与hadoop集成的很好,和yarn很好的集成
给人更多的选择,你不喜欢可以使用mr,我比mr更快,你自己看着办,如下面的sql语句, mapreduce程序启动就会有4个mr,并且读写hdfs非常频繁,效率很低;而使用Spark,DAG模式大大节省磁盘IO。
在一个统一的框架下,进行批处理、流计算、交互式计算

3.2 Spark核心概念介绍
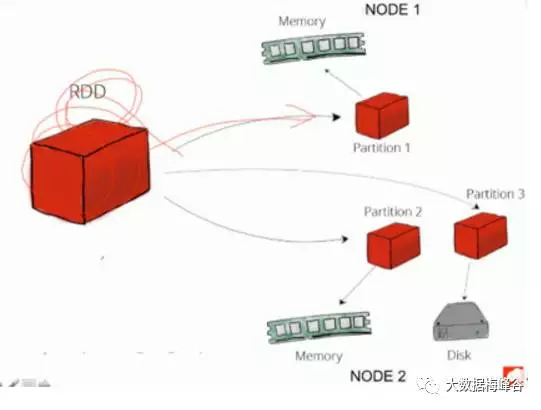
1.RDD弹性分布式数据集
· 数据集的抽象,以前学过很多数据集,array,list,map数据集等,抽象成不同的数据结构,
分布式:数据被分解成很多块放到不同节点
弹性:相对于存储介质而言,可以放在磁盘,可以放在内存,这就是弹性的意思
· 分布在集群上,只读
一个RDD被分解成很多块partition,这些partition分布在不同的机器上。多个partion组成,hdfs的block有什么关系,2套术语,都叫块不可以,2个团队2个社区的人,命名方式不同了。
· 可以在内存或者磁盘上
· 可以并行的构造,一个或者2个可以产生新的
· 失效后,自动重构
2.基本操作Transfoation和Action
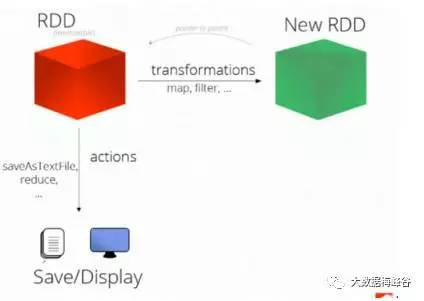
rdd是数据,有数据,就有计算操作,基本操作分成2类(为什么分成2类),
1)transformation:一类算子的简称,完成转换功能,函数和算子一个意思,看成一个大的数组,里面有元素,被切分放到各个节点上。
2)action:把rdd变换成一个或者一组值,这些是单机的,前面transformation都是分布式的值,
3)Spark提供了大量的函数
transformation:参数也是函数,输入T类型rdd,输出U类型也是RDD,
aciton:输入rdd,输出不是rdd了,可能是基本类型或者数组等,都是单机的类型

4)惰性执行
transformation只会记录RDD的转化关系,并不会触发计算
action是触发程序执行(分布式)的算子

3.缓存cache和persist
spark非常好的能力,能控制内存的使用量,就是通过cache和persist实现,称为控制语句
可以让rdd cache到内存或磁盘上。
问题: cache和persist 区别(面试会经常被问到) ,回答以下知识点
(1)cache和persist都是用于将一个RDD进行缓存的,这样在之后使用的过程中就不需要重新计算了,可以大大节省程序运行时间,
(2) cache只有一个默认的缓存级别MEMORY_ONLY ,cache调用了persist,而persist可以根据情况设置其它的缓存级别。
(3)executor执行的时候,默认60%做cache,40%做task操作,persist最根本的函数,最底层的函数
storagelever每个等级有5个参数
·是不是用磁盘
·是不是不内存
·是不是用tacyon
·是不是反序列化
·缓存保存多少份
序列化器,使用序列化节省内存但是消耗cpu,拿出来的时候要进行反序列化,缺省的,用自带的,但是性能很差,根据自己的需求是否进行序列化,不要用自带的序列化器
4.Spark运行模式
4.1.Spark程序组成
1)程序执行
· spark-shell,读取文件->RDD转换-> RDD触发执行->保存结果
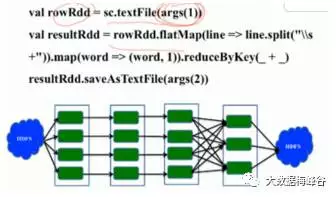
· spark-submit,很多参数,注意下参数:--master,指定程序运行的模式,可以本地,yarn,别的集群上

2)Spark程序架构
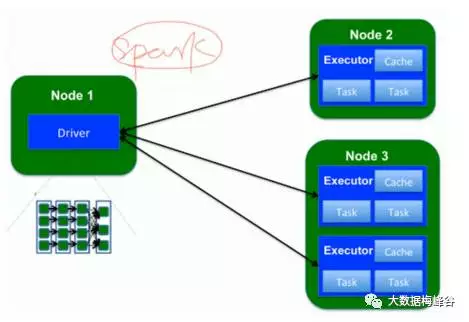
2个组件组成,application = driver(1个)+ executor(多个)
· driver:main函数,2g内存1个cpu,运行指定将相应的jar包和文件传给work node
· application:driver+executor,spark应用程序,2个应用程序是没有任何关联,如果共享数据只能hdfs或者tacyon. executor运行是指定,可以同时跑几个task,一个application转为多个task(driver转化),task扔给exe执行,
4.2.Spark程运行模式
1)本地模式
不一定非要跑在hadoop集群,可以在本地,起多个线程的方式来指定。将Spark应用以多线程的方式直接运行在本地,一般都是为了方便调试,本地模式分三类
· local:只启动一个executor
· local[k]:启动k个executor
· local[*]:启动跟cpu数目相同的 executor
2)独立模式
搭建一个集群跑,分布式环境中执行spark程序,资源管理和任务监控是Spark自己控制。

3)集群模式

driver运行在本地,没有容错,但是调试方便

driver运行在集群里面,yarn从slave里面选择一个跑driver,有个好处就是当driver挂掉了,resourceManager可以重新启动一个driver,实现容错,生产环境使用的模式。
5.参考资料
1.http://blog.csdn.net/woshiwanxin102213/article/details/19688393 Hadoop生态系统介绍
2.董西成ppt