2019独角兽企业重金招聘Python工程师标准>>> 
学习目标
了解ELK是什么,用途。
掌握beats的用途、种类、使用。
掌握logstash的用途、工作原理、安装、配置。
掌握logstash的使用
掌握kibana的使用
ELK简介
ELK是什么?
Elasticsearch Logstash Kibana 原来称为 ELK Stack ,现在称为Elastic Stack,加入了 beats 来优化Logstash。
从官网介绍了解它们:https://www.elastic.co/cn/products
ELK的主要用途是什么?
大型分布式系统的日志集中分析。
为什么要用ELK来做日志集中分析?
问1:在生产系统中出现问题,你该如何来定位问题?
问2:在大型的分布式系统中如出现问题,你该如何定位问题?
一个完整的集中式日志系统,需要包含以下几个主要特点
收集-能够采集多种来源的日志数据
传输-能够稳定的把日志数据传输到中央系统
转换— 能够对收集的日志数据进行转换处理
存储-如何存储日志数据
分析-可以支持 UI 分析
告警-能够提供错误报告,监控机制
ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。目前主流的一种日志系统。
ELK架构(一) 老的架构
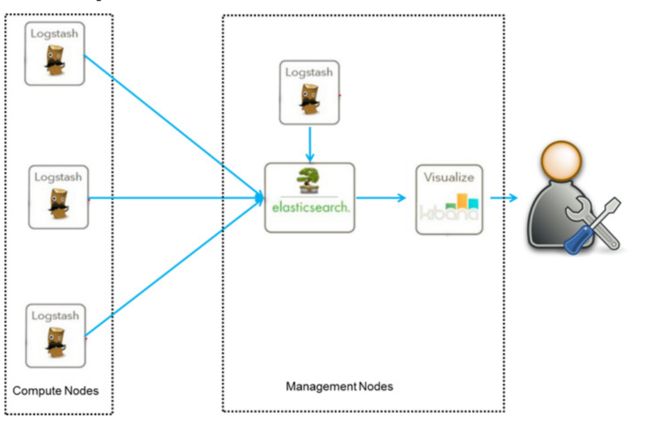
ELK架构(二) 用beats来进行采集的架构

Beats
Beats是什么?
轻量型数据采集器。负责从目标源上采集数据。
官网介绍:https://www.elastic.co/cn/products/beats
Beats 的已有种类





FileBeat 日志文件采集器 工作原理
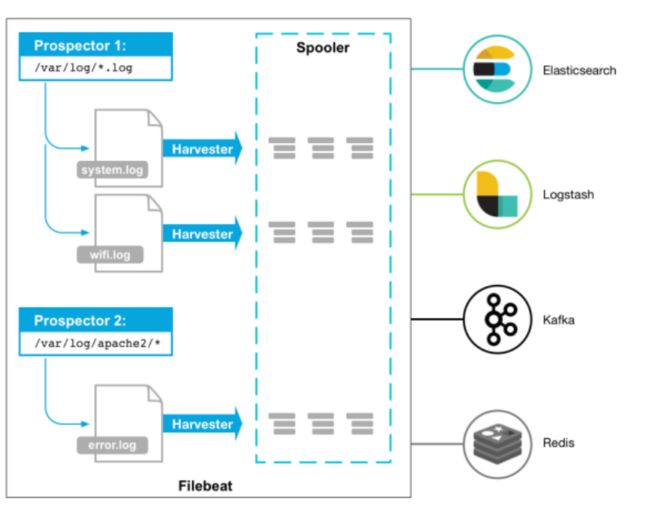
Prospector 勘测者
负责管理Harvester并找到所有读取源。 6.3开始叫 input 了。
Harvestor 收割机
负责读取单个文件内容,发送到输出
获取 FileBeat
6.2.4 版本下载地址: https://www.elastic.co/downloads/past-releases/filebeat-6-2-4
最新版下载地址:https://www.elastic.co/cn/downloads/beats/filebeat

使用步骤 https://www.elastic.co/guide/en/beats/filebeat/6.2/filebeat-getting-started.html
1、安装
windows:解压到安装目录即可
linux: rpm -ivh filebeat-6.2.4-x86_64.rpm
安装后的目录结构:
https://www.elastic.co/guide/en/beats/filebeat/6.2/directory-layout.html
使用步骤
2、配置:在 filebeat.yml 中配置从哪些文件读取数据,送到哪里去
1、配置勘测采集源
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/*.log
#- c:\programdata\elasticsearch\logs\*
2、配置输出送到es中去
output.elasticsearch:
hosts: ["192.168.1.42:9200"]
若ES有认证,配置用户密码
output.elasticsearch:
hosts: ["myEShost:9200"]
username: "elastic"
password: "elastic"
3、启动filebeat
linux rpm : sudo service filebeat start
windows:
安装了服务:PS C:\Program Files\Filebeat> Start-Service filebeat
如果没有安装服务,在安装目录直接运行启动程序 filebeat
sudo ./filebeat
可加启动选项:-e 输入日志到标准输出, -c 指定配置文件
如:sudo ./filebeat -e -c filebeat.yml
GET /_cat/indices?v 查看创建的索引
GET /filebeat*/_search?q=* 查看索引的数据格式
4、配置索引模板 https://www.elastic.co/guide/en/beats/filebeat/6.2/filebeat-template.html
默认情况下,如果输出是elasticsearch,filebeat自动创建推荐的索引模板(定义在fields.yml中)。
如果你想使用自定义的模板,可在 filebeat.yml中配置指定你的模板
setup.template.name: "your_template_name"
setup.template.fields: "path/to/fields.yml"
覆盖已存在的模板
setup.template.overwrite: true
改变索引的名字。默认为filebeat-6.2.4-yyyy.MM.dd
output.elasticsearch.index: "customname-%{[beat.version]}-%{+yyyy.MM.dd}"
setup.template.name: "customname"
setup.template.pattern: "customname-*" 名字中应包含版本和日期部分
#setup.dashboards.index: "customname-*" 使用kibana的dashboard时需要
重启filebeat后才会创建
手动载入模板。当输出是logstash时,需手动执行命令来向es创建模板
filebeat setup --template -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=["localhost:9200"]'
5、配置使用kibana的dashboards。在 filebeat.yml 中:
setup.dashboards.enabled: true
setup.kibana:
host: "mykibanahost:5601"
有认证的配置
setup.kibana:
host: "mykibanahost:5601"
username: "elastic"
password: "elastic"
重启filebeat,在kibana中浏览 Discover Visualize DashBoard
配置输出到logstash
output.logstash:
hosts: ["127.0.0.1:5044"]
请记得,需要手动载入索引模板。
Filebeat的各种配置的详细说明请参考:
https://www.elastic.co/guide/en/beats/filebeat/6.2/configuring-howto-filebeat.html
FileBeat 的运行命令说明
https://www.elastic.co/guide/en/beats/filebeat/6.2/command-line-options.html
FileBeat modules 模块
思考:
1、日志信息只是作为一个文本字段放入ES中,还是应该将其解析为多个特定意义的字段,方便统计分析?
2、各种应用(如 nginx tomcat mysql redis )输出的日志格式一样吗?包含的信息域一样吗?
fileBeat中提供了很多常见应用日志格式的读取解析模块,来简化我们的使用。 官网参考:
https://www.elastic.co/guide/en/beats/filebeat/6.2/filebeat-modules-quickstart.html
https://www.elastic.co/guide/en/beats/filebeat/6.2/filebeat-modules-overview.html
https://www.elastic.co/guide/en/beats/filebeat/6.2/configuration-filebeat-modules.html
安装对应插件
sudo bin/elasticsearch-plugin install ingest-geoip
sudo bin/elasticsearch-plugin install ingest-user-agent
查看、启用模块
filebeat modules list
filebeat modules enable apache2 auditd mysql
Prospector (input) 配置详细介绍
https://www.elastic.co/guide/en/beats/filebeat/current/configuration-filebeat-options.html
搞清楚如何做下面的配置:
1.如何指定查找哪些文件?如何指定多个路径?以及排除哪些文件?paths exclude_files
2.如何过滤文件中行? exclude_lines include_lines
3.如何指定以何种编码来读取文件? encoding
4.如何为读取的数据加额外的标识字段? tags fields fields_under_root
5.如何对读取的数据进行处理? processors 详细了解见下面的链接
https://www.elastic.co/guide/en/beats/filebeat/current/filtering-and-enhancing-data.html https://www.elastic.co/guide/en/beats/filebeat/current/defining-processors.html
6.如何设置多行的信息如何读取?
https://www.elastic.co/guide/en/beats/filebeat/current/multiline-examples.html https://www.elastic.co/guide/en/beats/filebeat/current/_examples_of_multiline_configuration.html
7.如何对不同的文件设置不同的读取处理?
可配置多个prospector,定义不同的行为。
output 配置详细介绍
https://www.elastic.co/guide/en/beats/filebeat/current/configuring-output.html
可输出到:Elasticsearch Logstash Kafka Redis File Console
Elasticsearch output
https://www.elastic.co/guide/en/beats/filebeat/current/elasticsearch-output.html
重点搞清楚:
如何指定索引? index
如何为不同的数据指定不同的索引? Indices
如何指定管道? pipeline pipelines
https://www.elastic.co/guide/en/beats/filebeat/current/configuring-ingest-node.html
Logstash output
https://www.elastic.co/guide/en/beats/filebeat/current/logstash-output.html
重点搞清楚: 注意:一定要记得需要手动创建索引模板
如何设置负载均衡? loadbalance
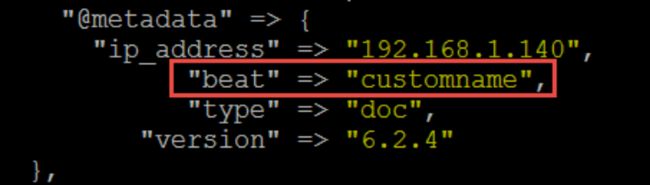
如何指定索引? index + @metadata
1、指定索引前缀名,默认值为 filebeat
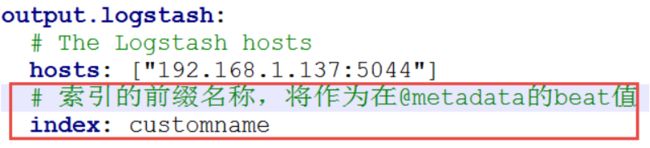
2、配置logstash的管道输出的索引(使用@metadata)
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
}
}
@metadata字段在最终的输出中是没有的,如想看可配置logstash的out如下:
output {
stdout { codec => rubydebug { metadata => true } }
}
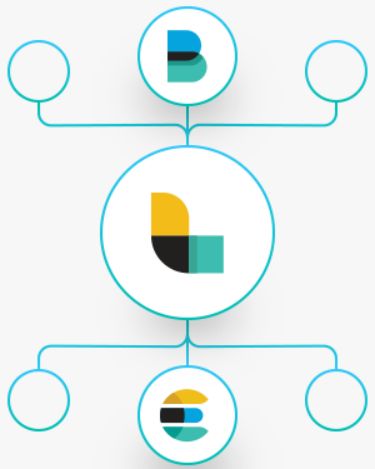
Logstash
Logstash的角色
https://www.elastic.co/cn/products/logstash

Logstash 介绍
https://www.elastic.co/guide/en/logstash/current/introduction.html

获取 Logstash
https://www.elastic.co/cn/downloads/logstash
6.2.4 版本:https://www.elastic.co/downloads/past-releases/logstash-6-2-4
安装
开箱即用:
压缩包:解压到安装目录
rpm包:rpm -ivh logstash-6.2.4.rpm
logstash Pipeline 管道 工作原理
启动logstash实例时需为其指定管道定义。
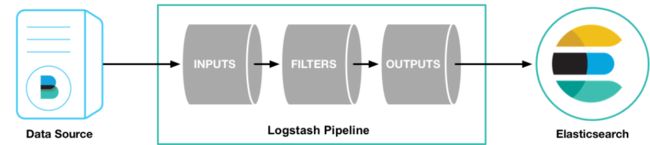
https://www.elastic.co/guide/en/logstash/6.2/pipeline.html
https://www.elastic.co/guide/en/logstash/6.2/execution-model.html
试用
用最简单的管道定义来启动logstash实例
cd logstash-6.2.4
bin/logstash -e 'input { stdin { } } output { stdout {} }'

用logstash来解析日志
1、配置 Filebeat 将日志发送给logstash
filebeat.prospectors:
- type: log
paths:
- /path/to/file/logstash-tutorial.log
output.logstash:
hosts: ["localhost:5044"]
2、配置Logstash的管道输入为 Filebeat
管道定义模板
# The # character at the beginning of a line indicates a comment. Use
# comments to describe your configuration.
input {
}
# The filter part of this file is commented out to indicate that it is
# optional.
# filter {
#
# }
output {
}
在logstash home目中创建文件管道配置文件 first-pipeline.conf,配置如下:
input {
beats { //定义 beats 输入
port => "5044"
}
}
# The filter part of this file is commented out to indicate that it is
# optional.
# filter {
#
# }
output {
stdout { codec => rubydebug } //定义 输出到标准输出
}
测试管道配置是否正确
bin/logstash -f first-pipeline.conf --config.test_and_exit
启动logstash实例
bin/logstash -f first-pipeline.conf --config.reload.automatic
3、配置filter 来解析日志
input {
beats {
port => "5044"
}
}
filter { //配置使用 grok 过进行滤转换
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
}
output {
stdout { codec => rubydebug }
}
4、再加入一个过滤器
geoip {
source => "clientip" //实现ip转地理坐标
}
关闭filebeat实例,执行 sudo rm data/registry 删除filebeat记录,再启动filebeat
5、配置输出到elasticsearch
output {
elasticsearch {
hosts => [ "localhost:9200" ]
}
}
关闭filebeat实例,执行 sudo rm data/registry 删除filebeat记录,再启动filebeat
了解 input
Logstash中实现了很多input 插件,可满足我们各种来源数据的接收:
https://www.elastic.co/guide/en/logstash/current/input-plugins.html
配置从多个input获取数据
input {
stdin { }
file {
path => "/tmp/*_log"
}
beats {
port => "5044"
}
}
了解 filter
Logstash中实现了很多filter 插件:
https://www.elastic.co/guide/en/logstash/current/filter-plugins.html
可多重过滤处理
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
geoip {
source => "clientip"
}
}
如何解析日志文本为字段
用 grok 过滤器 https://www.elastic.co/guide/en/logstash/current/plugins-filters-grok.html
掌握 Grok match 表达式语法
%{SYNTAX:SEMANTIC}
了解从哪里去查看预定义的正则表达式
https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
知道如何定义自己的正则表达式
直接定义正则表达式
如果要重用就定义一各模式文件,用patterns_dir => [“./patterns”] 指定模式目录
55.3.244.1 GET /index.html 15824 0.043
%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}
如何加入、替换、删除字段
了解filter通用属性 add_field add_tag remove_field remove_tag
了解alter、date、range filter的用法
如何筛选数据
了解drop filter的用法。
如何进行条件过滤或条件输出
了解: https://www.elastic.co/guide/en/logstash/current/event-dependent-configuration.html
了解 output
Logstash中实现了很多output 插件:
https://www.elastic.co/guide/en/logstash/current/output-plugins.html
输出到多个地方
output {
elasticsearch {
hosts => ["IP Address 1:port1", "IP Address 2:port2", "IP Address 3"]
}
file {
path => "/path/to/target/file"
}
stdout { codec => rubydebug }
}
如何设置输出的索引?
https://www.elastic.co/guide/en/logstash/current/plugins-outputs-elasticsearch.html#plugins-outputs-elasticsearch-template
Filebeat中 logstash output 配置的介绍(p28页)
https://www.elastic.co/guide/en/beats/filebeat/current/logstash-output.html
如何配置将不同的数据发送给不同的输出目标
条件选择输出: https://www.elastic.co/guide/en/logstash/current/event-dependent-configuration.html
输出索引名称上带动态字段引用。
了解 codec
Logstash中实现了很多codec插件,可以在input 中指定用什么codec来读取输入内容;可以在output中指定输出为什么格式。
https://www.elastic.co/guide/en/logstash/current/codec-plugins.html
logstash的详细配置说明
请参考官网: https://www.elastic.co/guide/en/logstash/current/configuration.html

logstash插件扩展
请参考官网: https://www.elastic.co/guide/en/logstash/current/contributing-to-logstash.html

Kibana
kibana需要学会使用的点
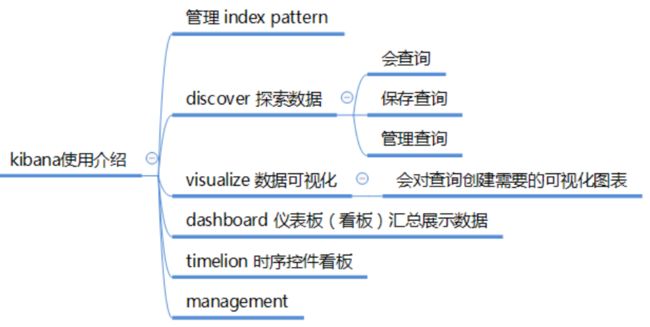
kibana的学习资源
Kibana 用户手册:
https://www.elastic.co/guide/cn/kibana/current/index.html
kibana使用的基本流程
