2019独角兽企业重金招聘Python工程师标准>>> 
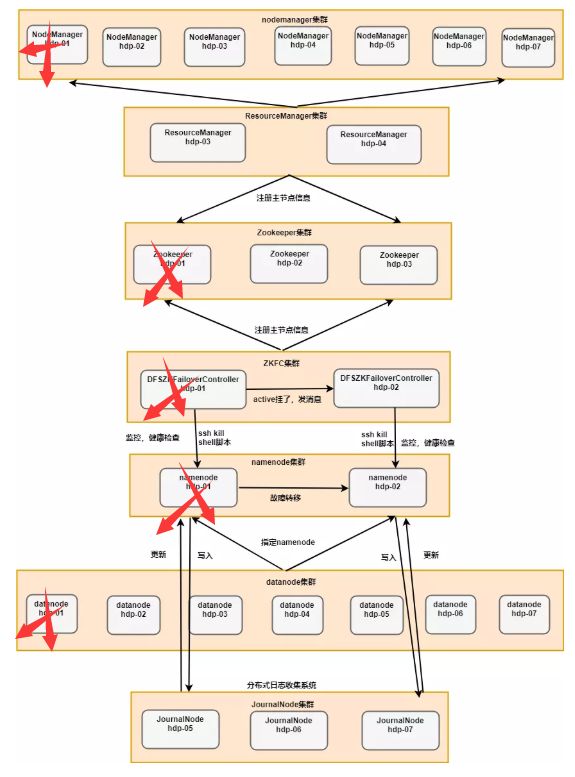
Hadoop的HA工作机制示意图
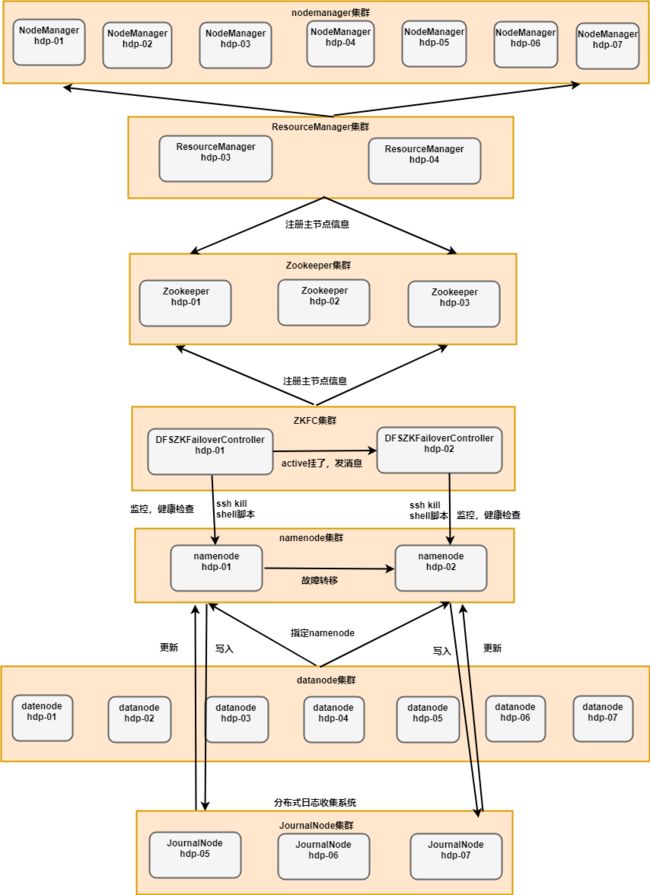
下面我们开始搭建这一套高可用集群环境
hadoop2.0已经发布了稳定版本了,增加了很多特性,比如HDFS HA、YARN等。最新的hadoop-2.6.4又增加了YARN HA
注意:apache提供的hadoop-2.6.4的安装包是在32位操作系统编译的,因为hadoop依赖一些C++的本地库,
所以如果在64位的操作上安装hadoop-2.6.4就需要重新在64操作系统上重新编译
前期准备
1.修改Linux主机名
2.修改IP
3.修改主机名和IP的映射关系 /etc/hosts
######注意######如果你们公司是租用的服务器或是使用的云主机(如华为用主机、阿里云主机等)
/etc/hosts里面要配置的是内网IP地址和主机名的映射关系
4.关闭防火墙
5.ssh免登陆
6.安装JDK,配置环境变量等
集群规划:
主机名 IP 安装的软件 运行的进程
hdp-01 192.168.150.11 jdk、hadoop、zk NodeManager、DataNode、NameNode、QuorumPeerMain、DFSZKFailoverController
hdp-02 192.168.150.12 jdk、hadoop、zk NodeManager、DataNode、NameNode、QuorumPeerMain、DFSZKFailoverController
hdp-03 192.168.150.13 jdk、hadoop、zk NodeManager、DataNode、ResourceManager、QuorumPeerMain
hdp-04 192.168.150.14 jdk、hadoop NodeManager、DataNode、ResourceManager
hdp-05 192.168.150.15 jdk、hadoop NodeManager、DataNode、JournalNode
hdp-06 192.168.150.16 jdk、hadoop NodeManager、DataNode、JournalNode
hdp-07 192.168.150.17 jdk、hadoop NodeManager、DataNode、JournalNode
说明:
1.在hadoop2.0中通常由两个NameNode组成,一个处于active状态,另一个处于standby状态。Active NameNode对外提供服务,而Standby NameNode则不对外提供服务,仅同步active namenode的状态,以便能够在它失败时快速进行切换。
hadoop2.0官方提供了两种HDFS HA的解决方案,一种是NFS,另一种是QJM。这里我们使用简单的QJM。在该方案中,主备NameNode之间通过一组JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。通常配置奇数个JournalNode
这里还配置了一个zookeeper集群,用于ZKFC(DFSZKFailoverController)故障转移,当Active NameNode挂掉了,会自动切换Standby NameNode为standby状态
2.hadoop-2.2.0中依然存在一个问题,就是ResourceManager只有一个,存在单点故障,hadoop-2.6.4解决了这个问题,有两个ResourceManager,一个是Active,一个是Standby,状态由zookeeper进行协调安装步骤
1.安装配置zooekeeper集群(在hdp-01、hdp-02、hdp-03上)
1.1解压
tar -zxvf zookeeper-3.4.5.tar.gz -C /home/hadoop/app/
1.2修改配置
cd /home/hadoop/app/zookeeper-3.4.5/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
修改:dataDir=/home/hadoop/app/zookeeper-3.4.5/tmp
在最后添加:
server.1=hdp-01:2888:3888
server.2=hdp-02:2888:3888
server.3=hdp-03:2888:3888
保存退出
然后创建一个tmp文件夹
mkdir /home/hadoop/app/zookeeper-3.4.5/tmp
echo 1 > /home/hadoop/app/zookeeper-3.4.5/tmp/myid
1.3将配置好的zookeeper拷贝到其他节点(首先分别在hdp-02、hdp-03根目录下创建一个hadoop目录:mkdir /hadoop)
scp -r /home/hadoop/app/zookeeper-3.4.5/ hdp-02:/home/hadoop/app/
scp -r /home/hadoop/app/zookeeper-3.4.5/ hdp-03:/home/hadoop/app/
注意:修改hdp-02、hdp-03对应/hadoop/zookeeper-3.4.5/tmp/myid内容
hdp-02:
echo 2 > /home/hadoop/app/zookeeper-3.4.5/tmp/myid
hdp-03:
echo 3 > /home/hadoop/app/zookeeper-3.4.5/tmp/myid
2.安装配置hadoop集群(在hdp-01上操作)
2.1解压
tar -zxvf hadoop-2.6.4.tar.gz -C /home/hadoop/app/
2.2配置HDFS(hadoop2.0所有的配置文件都在$HADOOP_HOME/etc/hadoop目录下)
#将hadoop添加到环境变量中
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.7.0_55
export HADOOP_HOME=/hadoop/hadoop-2.6.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
#hadoop2.0的配置文件全部在$HADOOP_HOME/etc/hadoop下
cd /home/hadoop/app/hadoop-2.6.4/etc/hadoop
2.2.1修改hadoo-env.sh
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_55###############################################################################
2.2.2修改core-site.xml
fs.defaultFS
hdfs://hdp24/
hadoop.tmp.dir
/root/hdptmp/
ha.zookeeper.quorum
hdp-05:2181,hdp-06:2181,hdp-07:2181
###############################################################################
2.2.3修改hdfs-site.xml
dfs.nameservices
hdp24
dfs.ha.namenodes.hdp24
nn1,nn2
dfs.namenode.rpc-address.hdp24.nn1
hdp-01:9000
dfs.namenode.http-address.hdp24.nn1
hdp-01:50070
dfs.namenode.rpc-address.hdp24.nn2
hdp-02:9000
dfs.namenode.http-address.hdp24.nn2
hdp-02:50070
dfs.namenode.name.dir
/root/hdpdata/name
dfs.datanode.data.dir
/root/hdpdata/data
dfs.namenode.shared.edits.dir
qjournal://hdp-05:8485;hdp-06:8485;hdp-07:8485/hdp24
dfs.journalnode.edits.dir
/root/hdpdata/journaldata
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.hdp24
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
###############################################################################
2.2.4修改mapred-site.xml
###############################################################################
mapreduce.framework.name
yarn
2.2.5修改yarn-site.xml
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
yrc
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
hdp-03
yarn.resourcemanager.hostname.rm2
hdp-04
yarn.resourcemanager.zk-address
hdp-01:2181,hdp-02:2181,hdp-03:2181
yarn.nodemanager.aux-services
mapreduce_shuffle
2.2.6修改slaves(slaves是指定子节点的位置,因为要在hdp-01上启动HDFS、在hdp-03、hdp-04启动yarn,所以hdp-01上的slaves文件指定的是datanode的位置,hdp-03、hdp-04上的slaves文件指定的是nodemanager的位置)hdp-01 hdp-02 hdp-03 hdp-04 hdp-05 hdp-06 hdp-072.2.7配置免密码登陆
#首先要配置hdp-01到hdp-01、hdp-02、hdp-03、hdp-04、hdp-05、hdp-06、hdp-07的免密码登陆
#在hdp-01上生产一对钥匙
ssh-keygen -t rsa
#将公钥拷贝到其他节点,包括自己
ssh-coyp-id hdp-01
ssh-coyp-id hdp-02
ssh-coyp-id hdp-03
ssh-coyp-id hdp-04
ssh-coyp-id hdp-05
ssh-coyp-id hdp-06
ssh-coyp-id hdp-07
#配置hdp-03到hdp-01、hdp-02、hdp-03、hdp-04、hdp-05、hdp-06、hdp-07的免密码登陆
#在hdp-03上生产一对钥匙
ssh-keygen -t rsa
#将公钥拷贝到其他节点
ssh-coyp-id hdp-01
ssh-coyp-id hdp-02
ssh-coyp-id hdp-03
ssh-coyp-id hdp-04
ssh-coyp-id hdp-05
ssh-coyp-id hdp-06
ssh-coyp-id hdp-07
#注意:两个namenode之间要配置ssh免密码登陆,别忘了配置hdp-01到hdp-02的免登陆
2.4将配置好的hadoop拷贝到其他节点
scp -r /hadoop/ hdo-02:/
scp -r /hadoop/ hdp-03:/
scp -r /hadoop/hadoop-2.6.4/ hadoop@hdp-04:/hadoop/
scp -r /hadoop/hadoop-2.6.4/ hadoop@hdp-05:/hadoop/
scp -r /hadoop/hadoop-2.6.4/ hadoop@hdp-06:/hadoop/
scp -r /hadoop/hadoop-2.6.4/ hadoop@hdp-07:/hadoop/
###注意:严格按照下面的步骤!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
2.5启动zookeeper集群(分别在hdp-01、hdp-02、hdp-03上启动zk)
cd /hadoop/zookeeper-3.4.5/bin/
./zkServer.sh start
#查看状态:一个leader,两个follower
./zkServer.sh status
2.6手动启动journalnode(分别在在hdp-05、hdp-06、hdp-07上执行)
cd /hadoop/hadoop-2.6.4
sbin/hadoop-daemon.sh start journalnode
#运行jps命令检验,hdp-05、hdp-06、hdp-07上多了JournalNode进程
2.7格式化namenode
#在hdp-01上执行命令:
hdfs namenode -format
#格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,这里我配置的是/hadoop/hadoop-2.6.4/tmp,然后将/hadoop/hadoop-2.6.4/tmp拷贝到hadoop02的/hadoop/hadoop-2.6.4/下。
scp -r tmp/ hadoop02:/home/hadoop/app/hadoop-2.6.4/
##也可以这样,建议hdfs namenode -bootstrapStandby
2.8格式化ZKFC(在hdp-01上执行即可)
hdfs zkfc -formatZK
2.9启动HDFS(在hdp-01上执行)
sbin/start-dfs.sh2.10启动YARN(#####注意#####:是在hdp-03上执行start-yarn.sh,把namenode和resourcemanager分开是因为性能问题,因为他们都要占用大量资源,所以把他们分开了,他们分开了就要分别在不同的机器上启动)
sbin/start-yarn.sh
到此,hadoop-2.6.4配置完毕,可以统计浏览器访问:
http://hdp-01:50070
NameNode 'hdp-01:9000' (active)
http://hdp-01:50070
NameNode 'hdp-02:9000' (standby)http://hdp-03:8088/cluster/nodes (active)
http://hdp-04:8088/cluster/nodes (standby)
手动启动journalnode(分别在在hdp-05、hdp-06、hdp-07上执行)
[root@hdp-05 ~]# hadoop-daemon.sh start journalnode
starting journalnode, logging to /root/apps/hadoop-2.7.2/logs/hadoop-root-journalnode-hdp-05.out
[root@hdp-05 ~]# jps
3317 JournalNode
3368 Jps
[root@hdp-05 ~]#
[root@hdp-06 ~]# hadoop-daemon.sh start journalnode
starting journalnode, logging to /root/apps/hadoop-2.7.2/logs/hadoop-root-journalnode-hdp-06.out
[root@hdp-06 ~]# jps
3304 JournalNode
3355 Jps
[root@hdp-07 ~]# hadoop-daemon.sh start journalnode
starting journalnode, logging to /root/apps/hadoop-2.7.2/logs/hadoop-root-journalnode-hdp-07.out
[root@hdp-07 ~]# jps
3362 Jps
3311 JournalNode
[root@hdp-07 ~]#
启动HDFS(在hdp-01上执行)
[root@hdp-01 ~]# start-dfs.sh
Starting namenodes on [hdp-01 hdp-02]
hdp-02: starting namenode, logging to /root/apps/hadoop-2.7.2/logs/hadoop-root-namenode-hdp-02.out
hdp-01: starting namenode, logging to /root/apps/hadoop-2.7.2/logs/hadoop-root-namenode-hdp-01.out
hdp-02: starting datanode, logging to /root/apps/hadoop-2.7.2/logs/hadoop-root-datanode-hdp-02.out
hdp-05: starting datanode, logging to /root/apps/hadoop-2.7.2/logs/hadoop-root-datanode-hdp-05.out
hdp-04: starting datanode, logging to /root/apps/hadoop-2.7.2/logs/hadoop-root-datanode-hdp-04.out
hdp-03: starting datanode, logging to /root/apps/hadoop-2.7.2/logs/hadoop-root-datanode-hdp-03.out
hdp-07: starting datanode, logging to /root/apps/hadoop-2.7.2/logs/hadoop-root-datanode-hdp-07.out
hdp-06: starting datanode, logging to /root/apps/hadoop-2.7.2/logs/hadoop-root-datanode-hdp-06.out
hdp-01: starting datanode, logging to /root/apps/hadoop-2.7.2/logs/hadoop-root-datanode-hdp-01.out
Starting journal nodes [hdp-05 hdp-06 hdp-07]
hdp-06: journalnode running as process 3304. Stop it first.
hdp-05: journalnode running as process 3317. Stop it first.
hdp-07: journalnode running as process 3311. Stop it first.
Starting ZK Failover Controllers on NN hosts [hdp-01 hdp-02]
hdp-02: starting zkfc, logging to /root/apps/hadoop-2.7.2/logs/hadoop-root-zkfc-hdp-02.out
hdp-01: starting zkfc, logging to /root/apps/hadoop-2.7.2/logs/hadoop-root-zkfc-hdp-01.out
[root@hdp-01 ~]# jps
4721 Jps
3635 QuorumPeerMain
4259 NameNode
4404 DataNode
[root@hdp-01 ~]#
启动YARN(#####注意#####:是在hdp-03/hdp-04上执行start-yarn.sh,把namenode和resourcemanager分开是因为性能问题,因为他们都要占用大量资源,所以把他们分开了,他们分开了就要分别在不同的机器上启动)
[root@hdp-03 ~]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /root/apps/hadoop-2.7.2/logs/yarn-root-resourcemanager-hdp-03.out
hdp-04: nodemanager running as process 3639. Stop it first.
hdp-06: starting nodemanager, logging to /root/apps/hadoop-2.7.2/logs/yarn-root-nodemanager-hdp-06.out
hdp-02: starting nodemanager, logging to /root/apps/hadoop-2.7.2/logs/yarn-root-nodemanager-hdp-02.out
hdp-05: starting nodemanager, logging to /root/apps/hadoop-2.7.2/logs/yarn-root-nodemanager-hdp-05.out
hdp-01: starting nodemanager, logging to /root/apps/hadoop-2.7.2/logs/yarn-root-nodemanager-hdp-01.out
hdp-07: starting nodemanager, logging to /root/apps/hadoop-2.7.2/logs/yarn-root-nodemanager-hdp-07.out
hdp-03: starting nodemanager, logging to /root/apps/hadoop-2.7.2/logs/yarn-root-nodemanager-hdp-03.out
[root@hdp-03 ~]# jps
3619 DataNode
4007 Jps
3879 NodeManager
[root@hdp-04 ~]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /root/apps/hadoop-2.7.2/logs/yarn-root-resourcemanager-hdp-04.out
The authenticity of host 'localhost (::1)' can't be established.
RSA key fingerprint is 45:70:99:dc:00:b1:48:78:6f:ac:a4:47:a0:1b:7a:c5.
Are you sure you want to continue connecting (yes/no)? yes
localhost: Warning: Permanently added 'localhost' (RSA) to the list of known hosts.
root@localhost's password:
localhost: starting nodemanager, logging to /root/apps/hadoop-2.7.2/logs/yarn-root-nodemanager-hdp-04.out
[root@hdp-04 ~]# jps
3763 Jps
3639 NodeManager
3399 DataNode
[root@hdp-04 ~]#
访问结果
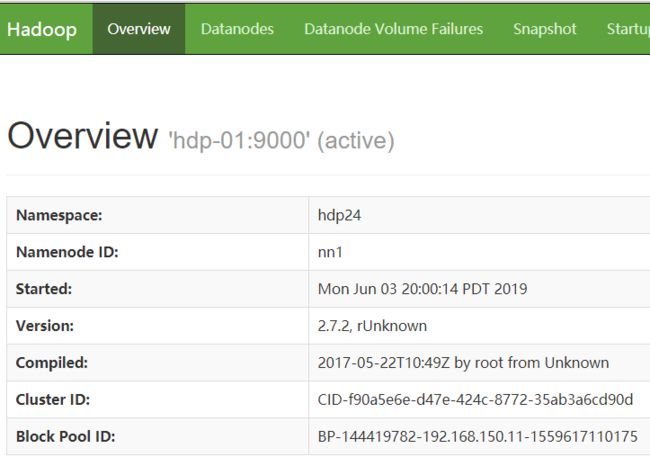
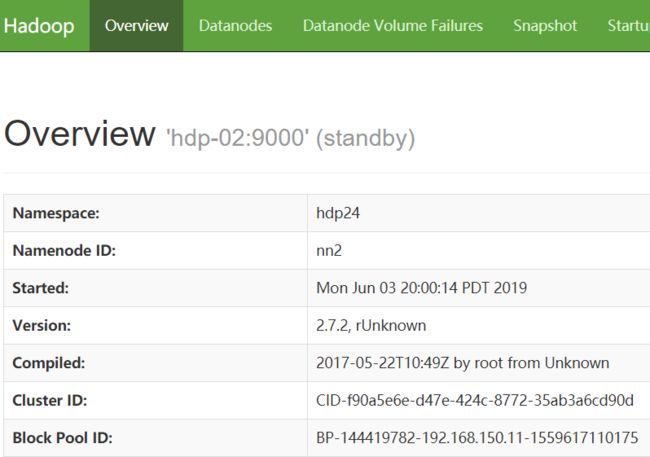
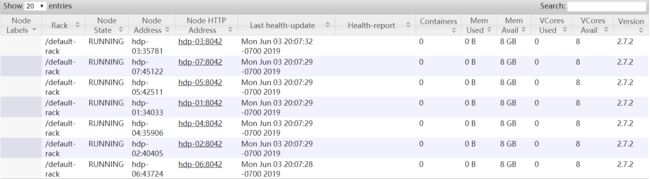
验证高可用:把hdp-01虚拟机关机,结果hdp-02变为active
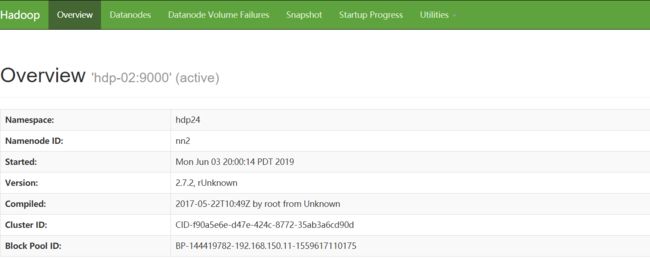
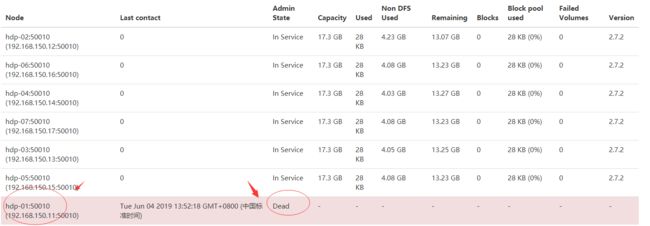

Hadoop的HA环境就搭建成功了
版权@须臾之余https://my.oschina.net/u/3995125