https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247492538&idx=2&sn=9a2bd9fe2d7fd681c10ebd368ef81c9c&chksm=fbea5a75cc9dd3636c148ebe6e296621d0c07132938a62f0b3643f34af414b3fd85e616e754b&scene=0&key=f9325dcb38245ddcc4d3ff16d58d0602dc8b5a680b011fb377597865a73a9fe39fb1a37a2ac92b1374a6e89170f0e7d366ebdfd286651f10ac319eb028a94291f051cce5ac3c287c1ab69751b6dc19cd&ascene=1&uin=MjgwMTEwNDQxNg%3D%3D&devicetype=Windows-QQBrowser&version=6103000b&lang=zh_CN&pass_ticket=DXC1954%2BK1SGTbNf0BfROhv9qHwlnnEPi%2BhWkN5VYUoPmHizjz4O33VIful%2FVDWv
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
一.概述关于 Apache Beam 实战指南系列文章
随着大数据 2.0 时代悄然到来,大数据从简单的批处理扩展到了实时处理、流处理、交互式查询和机器学习应用。近年来涌现出诸多大数据应用组件,如 HBase、Hive、Kafka、Spark、Flink 等。开发者经常要用到不同的技术、框架、API、开发语言和 SDK 来应对复杂应用的开发,这大大增加了选择合适工具和框架的难度,开发者想要将所有的大数据组件熟练运用几乎是一项不可能完成的任务。
面对这种情况,Google 在 2016 年 2 月宣布将大数据流水线产品(Google DataFlow)贡献给 Apache 基金会孵化,2017 年 1 月 Apache 对外宣布开源 Apache Beam,2017 年 5 月迎来了它的第一个稳定版本 2.0.0。在国内,大部分开发者对于 Beam 还缺乏了解,社区中文资料也比较少。InfoQ 期望通过 Apache Beam 实战指南系列文章 推动 Apache Beam 在国内的普及。
大数据发展趋势从普通的大数据,发展成 AI 大数据,再到下一代号称万亿市场的 lOT 大数据。技术也随着时代的变化而变化,从 Hadoop 的批处理,到 Spark Streaming,以及流批处理的 Flink 的出现,整个大数据架构也在逐渐演化。
Apache Beam 作为新生技术,在这个时代会扮演什么样的角色,跟 Flink 之间的关系是怎样的?Apache Beam 和 Flink 的结合会给大数据开发者或架构师们带来哪些意想不到的惊喜呢?
二.大数据架构发展演进历程2.1 大数据架构 Hadoop
图 2-1 MapReduce 流程图
最初做大数据是把一些日志或者其他信息收集后写入 Hadoop 的 HDFS 系统中,如果运营人员需要报表,则利用 Hadoop 的 MapReduce 进行计算并输出,对于一些非计算机专业的统计人员,后期可以用 Hive 进行统计输出。
2.2 流式处理 Storm
图 2-2Storm 流程图
业务进一步发展,运营人员需要看到实时数据的展示或统计。例如电商网站促销的时候,用于统计用户实时交易数据。数据收集也使用 MQ,用流式 Storm 解决这一业务需求问题。
2.3 Spark 批处理和微批处理
图 2-3 Spark 流程图
业务进一步发展,服务前端加上了网关进行负载均衡,消息中心也换成了高吞吐量的轻量级 MQ Kafka,数据处理渐渐从批处理发展到微批处理。
2.4 Flink:真正的流批处理统一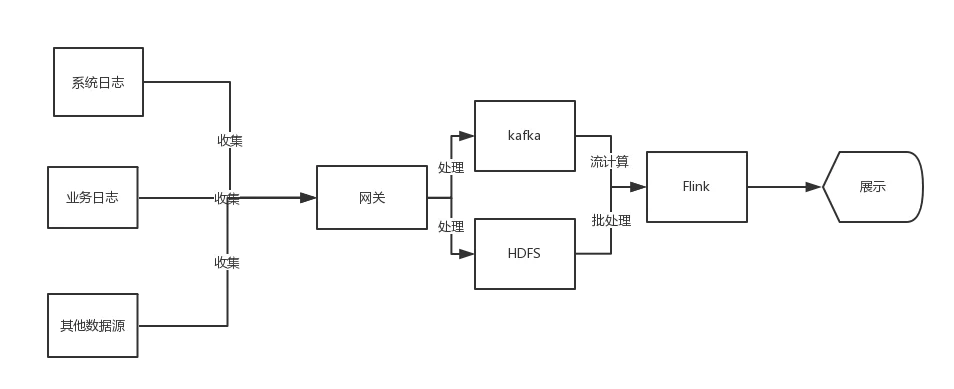
图 2-4 Flink 流程图
随着 AI 和 loT 的发展,对于传感设备的信息、报警器的警情以及视频流的数据量微批计算引擎已经满足不了业务的需求,Flink 实现真正的流处理让警情更实时。
2.5 下一代大数据处理统一标准 Apache Beam
图 2-5 Apache Beam 流程图
BeamSDKs 封装了很多的组件 IO,也就是图左边这些重写的高级 API,使不同的数据源的数据流向后面的计算平台。通过将近一年的发展,Apache Beam 不光组件 IO 更加丰富了,并且计算平台在当初最基本的 Apache Apex、Direct Runner、Apache Flink、Apache Spark、Google Cloud Dataflow 之上,又增加了 Gearpump、Samza 以及第三方的 JStorm 等计算平台。
为什么说 Apache Beam 会是大数据处理统一标准呢?
因为很多现在大型公司都在建立自己的“大中台”,建立统一的数据资源池,打通各个部门以及子公司的数据,以解决信息孤岛问题,把这些数据进行集中式管理并且进行后期的数据分析、BI、AI 以及机器学习等工作。这种情况下会出现很多数据源,例如之前用的 MySQL、MongodDB、HDFS、HBase、Solr 等,如果想建立中台就会是一件令人非常苦恼的事情,并且多计算环境更是让技术领导头疼。Apache Beam 的出现正好迎合了这个时代的新需求,它集成了很多数据库常用的数据源并把它们封装成 SDK 的 IO,开发人员没必要深入学习很多技术,只要会写 Beam 程序就可以了,大大节省了人力、时间以及成本。
三.Apache Beam 和 Flink 的关系随着阿里巴巴 Blink 的开源,Flink 中国社区开始活跃起来。很多人会开始对各种计算平台进行对比,比如 Storm、Spark、JStorm、Flink 等,并且有人提到之前阿里巴巴开源的 JStorm 比 Flink 性能高出 10-15 倍,为什么阿里巴巴却转战基于 Flink 的 Blink 呢? 在最近 Flink 的线下技术会议上,阿里巴巴的人已经回答了这一问题。其实很多技术都是从业务实战出来的,随着业务的发展可能还会有更多的计算平台出现,没有必要对此过多纠结。
不过,既然大家最近讨论得这么火热,这里也列出一些最近问的比较多的、有代表性的关于 Beam 的问题,逐一进行回答。
1. Flink 支持 SQL,请问 Beam 支持吗?现在 Beam 是支持 SQL 处理的,底层技术跟 Flink 底层处理是一样的。
Beam SQL 现在只支持 Java,底层是 Apache Calcite 的一个动态数据管理框架,用于大数据处理和一些流增强功能,它允许你自定义数据库功能。例如 Hive 使用了 Calcite 的查询优化,当然还有 Flink 解析和流 SQL 处理。Beam 在这之上添加了额外的扩展,以便轻松利用 Beam 的统一批处理 / 流模型以及对复杂数据类型的支持。 以下是 Beam SQL 具体处理流程图:
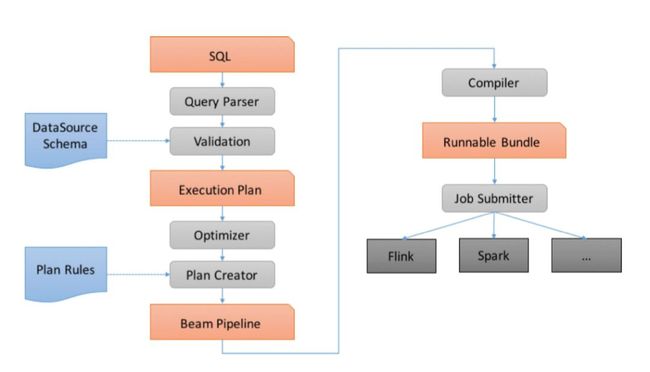
Beam SQL 一共有两个比较重要的概念:
SqlTransform:用于 PTransforms 从 SQL 查询创建的接口。
Row:Beam SQL 操作的元素类型。例如:PCollection。
在将 SQL 查询应用于 PCollection 之前,集合中 Row 的数据格式必须要提前指定。 一旦 Beam SQL 指定了 管道中的类型是不能再改变的。PCollection 行中字段 / 列的名称和类型由 Schema 进行关联定义。您可以使用 Schema.builder() 来创建 Schemas。
示例:
// Define the schema for the records.
Schema appSchema =
Schema
.builder()
.addInt32Field("appId")
.addStringField("description")
.addDateTimeField("rowtime")
.build();
// Create a concrete row with that type.
Row row =
Row
.withSchema(appSchema)
.addValues(1, "Some cool app", new Date())
.build();
// Create a source PCollection containing only that row
PCollection<Row> testApps =
PBegin
.in(p)
.apply(Create
.of(row)
.withCoder(appSchema.getRowCoder()));也可以是其他类型,不是直接是 Row,利用 PCollection通过应用 ParDo 可以将输入记录转换为 Row 格式。如:
// An example POJO class.
class AppPojo {
Integer appId;
String description;
Date timestamp;
}
// Acquire a collection of POJOs somehow.
PCollection pojos = ...
// Convert them to Rows with the same schema as defined above via a DoFn.
PCollection apps = pojos
.apply(
ParDo.of(new DoFn() {
@ProcessElement
public void processElement(ProcessContext c) {
// Get the current POJO instance
AppPojo pojo = c.element();
// Create a Row with the appSchema schema
// and values from the current POJO
Row appRow =
Row
.withSchema(appSchema)
.addValues(
pojo.appId,
pojo.description,
pojo.timestamp)
.build();
// Output the Row representing the current POJO
c.output(appRow);
}
}));
Beam 在抽象 Flink 的时候已经把这个参数抽象出来了,在 Beam Flink 源码解析中会提到。
3. 我这里有个流批混合的场景,请问 Beam 是不是支持?这个是支持的,因为批也是一种流,是一种有界的流。Beam 结合了 Flink,Flink dataset 底层也是转换成流进行处理的。
4. Flink 流批写程序的时候和 Beam 有什么不同?底层是 Flink 还是 Beam?打个比喻,如果 Flink 是 Lucene,那么 Beam 就是 Solr,把 Flink 的 API 进行二次重写,简化了 API,让大家使用更简单、更方便。此外,Beam 提供了更多的数据源,这是 Flink 不能比的。当然,Flink 后期可能也会往这方面发展。
四.Apache Beam KafkaIO 源码剖析KafkaIO 对 kafka-clients 支持依赖情况KafkaIO 是 Kafka 的 API 封装,主要负责 Apache Kafka 读取和写入消息。如果想使用 KafkaIO,必须依赖 beam-sdks-java-io-kafka ,KafkaIO 同时支持多个版本的 Kafka 客户端,使用时建议用高版本的或最新的 Kafka 版本,因为使用 KafkaIO 的时候需要包含 kafka-clients 的依赖版本。
Apache Beam KafkaIO 对各个 kafka-clients 版本的支持情况如下表:
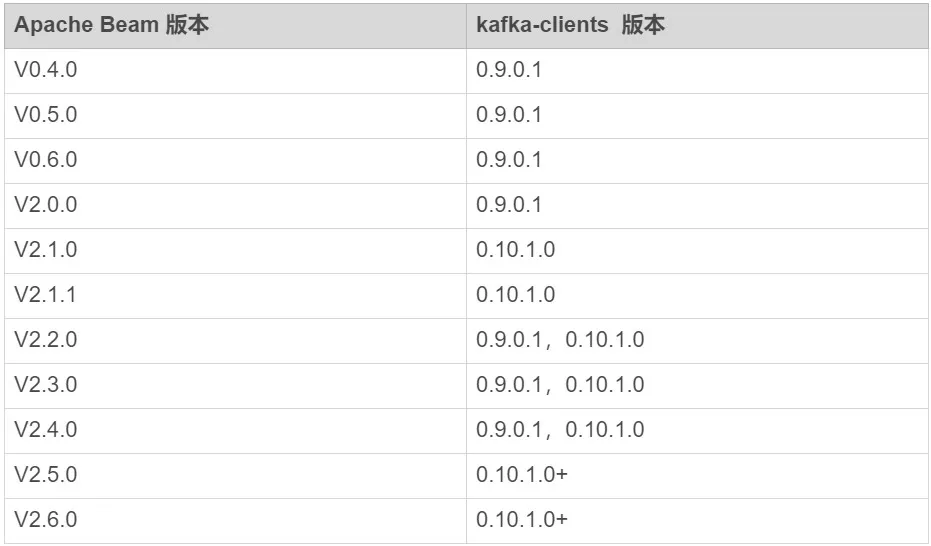
表 4-1 KafkaIO 与 kafka-clients 依赖关系表
Apache Beam V2.1.0 版本之前源码中的 pom 文件都显式指定了特定的 0.9.0.1 版本支持,但是从 V2.1.0 版本和 V2.1.1 两个版本开始已经替换成了 kafka-clients 的 0.10.1.0 版本,并且源码中提示 0.10.1.0 版本更安全。这是因为去年 Kafka 0.10.1.0 之前的版本曝出了安全漏洞。在 V2.2.0 以后的版本中,Beam 对 API 做了调整和更新,对之前的两种版本都支持,不过需要在 pom 中引用的时候自己指定 Kafka 的版本。但是在 Beam V2.5.0 和 V2.6.0 版本,源码中添加了以下提示:
* Supported Kafka Client Versions
* KafkaIO relies on kafka-clients for all its interactions with the Kafka cluster.
* kafka-clients versions 0.10.1 and newer are supported at runtime. The older versions
* 0.9.x - 0.10.0.0 are also supported, but are deprecated and likely be removed in near future.
* Please ensure that the version included with the application is compatible with the version of
* your Kafka cluster. Kafka client usually fails to initialize with a clear error message in
* case of incompatibility.
*/也就说在这两个版本已经移除了对 Kafka 客户端 0.10.1.0 以前版本的支持,旧版本还会支持,但是在以后不久就会删除。所以大家在使用的时候要注意版本的依赖关系和客户端的版本支持度。
如果想使用 KafkaIO,pom 必须要引用,版本跟 4-1 表中的对应起来就可以了。
<dependency>
<groupId>org.apache.beamgroupId>
<artifactId>beam-sdks-java-io-kafkaartifactId>
<version>...version>
dependency>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>a_recent_versionversion>
<scope>runtimescope>
dependency>KafkaIO 源码链接如下:
https://github.com/apache/beam/blob/master/sdks/java/io/kafka/src/main/java/org/apache/beam/sdk/io/kafka/KafkaIO.java
在 KafkaIO 里面最主要的两个方法是 Kafka 的读写方法。
KafkaIO 读操作
pipeline.apply(KafkaIO.String>read()
.withBootstrapServers("broker_1:9092,broker_2:9092")//
.withTopic("my_topic") // use withTopics(List) to read from multiple topics.
.withKeyDeserializer(LongDeserializer.class)
.withValueDeserializer(StringDeserializer.class)
// Above four are required configuration. returns PCollection>
// Rest of the settings are optional :
// you can further customize KafkaConsumer used to read the records by adding more
// settings for ConsumerConfig. e.g :
.updateConsumerProperties(ImmutableMap.of("group.id", "my_beam_app_1"))
// set event times and watermark based on 'LogAppendTime'. To provide a custom
// policy see withTimestampPolicyFactory(). withProcessingTime() is the default.
// Use withCreateTime() with topics that have 'CreateTime' timestamps.
.withLogAppendTime()
// restrict reader to committed messages on Kafka (see method documentation).
.withReadCommitted()
// offset consumed by the pipeline can be committed back.
.commitOffsetsInFinalize()
// finally, if you don't need Kafka metadata, you can drop it.g
.withoutMetadata() // PCollection>
)
.apply(Values.<String>create()) // PCollection 1) 指定 KafkaIO 的模型,从源码中不难看出这个地方的 KafkaIO
pipeline.apply(KafkaIO.read() 2) 设置 Kafka 集群的集群地址。
.withBootstrapServers("broker_1:9092,broker_2:9092")3) 设置 Kafka 的主题类型,源码中使用了单个主题类型,如果是多个主题类型则用 withTopics(List) 方法进行设置。设置情况基本跟 Kafka 原生是一样的。
.withTopic("my_topic") // use withTopics(List<String>) to read from multiple topics.4) 设置序列化类型。Apache Beam KafkaIO 在序列化的时候做了很大的简化,例如原生 Kafka 可能要通过 Properties 类去设置 ,还要加上很长一段 jar 包的名字。
Beam KafkaIO 的写法:
.withKeyDeserializer(LongDeserializer.class)
.withValueDeserializer(StringDeserializer.class)原生 Kafka 的设置:
Properties props = new Properties();
props.put("key.deserializer","org.apache.kafka.common.serialization.ByteArrayDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.ByteArrayDeserializer");5) 设置 Kafka 的消费者属性,这个地方还可以设置其他的属性。源码中是针对消费分组进行设置。
.updateConsumerProperties(ImmutableMap.of("group.id", my_beam_app_1"))6) 设置 Kafka 吞吐量的时间戳,可以是默认的,也可以自定义。
.withLogAppendTime()7) 相当于 Kafka 中"isolation.level", "read_committed" ,指定 KafkaConsumer 只应读取非事务性消息,或从其输入主题中提交事务性消息。流处理应用程序通常在多个读取处理写入阶段处理其数据,每个阶段使用前一阶段的输出作为其输入。通过指定 read_committed 模式,我们可以在所有阶段完成一次处理。针对"Exactly-once" 语义,支持 Kafka 0.11 版本。
.withReadCommitted()8) 设置 Kafka 是否自动提交属性"AUTO_COMMIT",默认为自动提交,使用 Beam 的方法来设置。
set CommitOffsetsInFinalizeEnabled(boolean commitOffsetInFinalize)
.commitOffsetsInFinalize()9) 设置是否返回 Kafka 的其他数据,例如 offset 信息和分区信息,不用可以去掉。
.withoutMetadata() // PCollection> 10) 设置只返回 values 值,不用返回 key。例如 PCollection,而不是 PCollection
.apply(Values.create()) // PCollection 写操作跟读操作配置基本相似,我们看一下具体代码。
PCollectionString>> kvColl = ...;
kvColl.apply(KafkaIO.String>write()
.withBootstrapServers("broker_1:9092,broker_2:9092")
.withTopic("results")
.withKeySerializer(LongSerializer.class)
.withValueSerializer(StringSerializer.class)
// You can further customize KafkaProducer used to write the records by adding more
// settings for ProducerConfig. e.g, to enable compression :
.updateProducerProperties(ImmutableMap.of("compression.type", "gzip"))
// You set publish timestamp for the Kafka records.
.withInputTimestamp() // element timestamp is used while publishing to Kafka
// or you can also set a custom timestamp with a function.
.withPublishTimestampFunction((elem, elemTs) -> ...)
// Optionally enable exactly-once sink (on supported runners). See JavaDoc for withEOS().
.withEOS(20, "eos-sink-group-id");
); 下面这个是 Kafka 里面比较重要的一个属性设置,在 Beam 中是这样使用的,非常简单,但是要注意这个属性.withEOS 其实就是 Kafka 中"Exactly-once"。
.withEOS(20, "eos-sink-group-id");在写入 Kafka 时完全一次性地提供语义,这使得应用程序能够在 Beam 管道中的一次性语义之上提供端到端的一次性保证。它确保写入接收器的记录仅在 Kafka 上提交一次,即使在管道执行期间重试某些处理也是如此。重试通常在应用程序重新启动时发生(如在故障恢复中)或者在重新分配任务时(如在自动缩放事件中)。Flink runner 通常为流水线的结果提供精确一次的语义,但不提供变换中用户代码的副作用。如果诸如 Kafka 接收器之类的转换写入外部系统,则这些写入可能会多次发生。
在此处启用 EOS 时,接收器转换将兼容的 Beam Runners 中的检查点语义与 Kafka 中的事务联系起来,以确保只写入一次记录。由于实现依赖于 runners checkpoint 语义,因此并非所有 runners 都兼容。Beam 中 FlinkRunner 针对 Kafka 0.11+ 版本才支持,然而 Dataflow runner 和 Spark runner 如果操作 kafkaIO 是完全支持的。
关于性能的注意事项"Exactly-once" 在接收初始消息的时候,除了将原来的数据进行格式化转换外,还经历了 2 个序列化 - 反序列化循环。根据序列化的数量和成本,CPU 可能会涨的很明显。通过写入二进制格式数据(即在写入 Kafka 接收器之前将数据序列化为二进制数据)可以降低 CPU 成本。
关于参数numShards——设置接收器并行度。存储在 Kafka 上的状态元数据,使用 sinkGroupId 存储在许多虚拟分区中。一个好的经验法则是将其设置为 Kafka 主题中的分区数。
sinkGroupId——用于在 Kafka 上将少量状态存储为元数据的组 ID。它类似于与 KafkaConsumer 一起使用的使用 groupID。每个作业都应使用唯一的 groupID,以便重新启动 / 更新作业保留状态以确保一次性语义。状态是通过 Kafka 上的接收器事务原子提交的。有关更多信息,请参阅 KafkaProducer.sendOffsetsToTransaction(Map,String)。接收器在初始化期间执行多个健全性检查以捕获常见错误,以便它不会最终使用似乎不是由同一作业写入的状态。
五.Apache Beam Flink 源码剖析FlinkRunner 对 Flink 支持依赖情况Flink 是一个流和批处理的统一的计算框架,Apache Beam 跟 Flink API 做了无缝集成。在 Apache Beam 中对 Flink 的操作主要是 FlinkRunner.java,Apache Beam 支持不同版本的 flink 客户端。我根据不同版本列了一个 Flink 对应客户端支持表如下:

图 5-1 FlinkRunner 与 Flink 依赖关系表
从图 5-1 中可以看出,Apache Beam 对 Flink 的 API 支持的更新速度非常快,从源码可以看到 2.0.0 版本之前的 FlinkRunner 是非常 low 的,并且直接拿 Flink 的实例做为 Beam 的实例,封装的效果也比较差。但是从 2.0.0 版本之后 ,Beam 就像打了鸡血一样 API 更新速度特别快,抛弃了以前的冗余,更好地跟 Flink 集成,让人眼前一亮。
Apache Beam Flink 源码解析因为 Beam 在运行的时候都是显式指定 Runner,在 FlinkRunner 源码中只是成了简单的统一入口,代码非常简单,但是这个入口中有一个比较关键的接口类 FlinkPipelineOptions。
请看代码:
/** Provided options. */
private final FlinkPipelineOptions options;通过这个类我们看一下 Apache Beam 到底封装了哪些 Flink 方法。
首先 FlinkPipelineOptions 是一个接口类,但是它继承了 PipelineOptions、ApplicationNameOptions、StreamingOptions 三个接口类,第一个 PipelineOptions 大家应该很熟悉了,用于基本管道创建;第二个 ApplicationNameOptions 用于设置应用程序名字;第三个用于判断是流式数据还是批数据。源代码如下:
public interface FlinkPipelineOptions extends
PipelineOptions, ApplicationNameOptions, StreamingOptions {
//....
}1) 设置 Flink Master 方法 ,这个方法用于设置 Flink 集群地址的 Master 地址。可以填写 IP 和端口,或者是 hostname 和端口,默认 local 。当然测试也可以是单机的,在 Flink 1.4 利用 start-local.sh 启动,而到了 1.5 以上就去掉了这个脚本,本地直接换成了 start-cluster.sh。大家测试的时候需要注意一下。
/**
* The url of the Flink JobManager on which to execute pipelines. This can either be the the * address of a cluster JobManager, in the form "host:port" or one of the special Strings * "[collection]" will execute the pipeline on Java Collections while "[auto]" will let the system
*/
@Description( "Address of the Flink Master where the Pipeline should be executed. Can"+ "[collection] or [auto].")
void setFlinkMaster(String value);2) 设置 Flink 的并行数,属于 Flink 高级 API 里面的属性。设置合适的 parallelism 能提高运算效率,太多了和太少了都不行。设置 parallelism 有多种方式,优先级为 api>env>p>file。
@Description("The degree of parallelism to be used when distributing operations onto workers.")
@Default.InstanceFactory(DefaultParallelismFactory.class)
Integer getParallelism();
void setParallelism(Integer value);3) 设置连续检查点之间的间隔时间(即当前的快照)用于容错的管道状态。
@Description("The interval between consecutive checkpoints (i.e. snapshots of the current"
@Default.Long(-1L)
Long getCheckpointingInterval();
void setCheckpointingInterval(Long interval)4) 定义一致性保证的检查点模式,默认为"AT_LEAST_ONCE",在 Beam 的源码中定义了一个枚举类 CheckpointingMode,除了默认的"AT_LEAST_ONCE",还有"EXACTLY_ONCE"。
"AT_LEAST_ONCE":这个模式意思是系统将以一种更简单地方式来对 operator 和 udf 的状态进行快照:在失败后进行恢复时,在 operator 的状态中,一些记录可能会被重放多次。
"EXACTLY_ONCE":这种模式意思是系统将以如下语义对 operator 和 udf(user defined function) 进行快照:在恢复时,每条记录将在 operator 状态中只被重现 / 重放一次。
@Description("The checkpointing mode that defines consistency guarantee.")
@Default.Enum("AT_LEAST_ONCE")
CheckpointingMode getCheckpointingMode();
void setCheckpointingMode(CheckpointingMode mode);5) 设置检查点的最大超时时间,默认为 20*60*1000(毫秒)=20(分钟)。
@Description("The maximum time that a checkpoint may take before being discarded.")
@Default.Long(20 * 60 * 1000)
Long getCheckpointTimeoutMillis();
void setCheckpointTimeoutMillis(Long checkpointTimeoutMillis);6) 设置重新执行失败任务的次数,值为 0 有效地禁用容错,值为 -1 表示使用系统默认值(在配置中定义)。
@Description(
"Sets the number of times that failed tasks are re-executed. "
+ "A value of zero effectively disables fault tolerance. A value of -1 indicates "+ "that the system default value (as defined in the configuration) should be used.")
@Default.Integer(-1)
Integer getNumberOfExecutionRetries();
void setNumberOfExecutionRetries(Integer retries);7) 设置执行之间的延迟,默认值为 -1L。
@Description(
"Sets the delay between executions. A value of {@code -1} "
+ "indicates that the default value should be used.")
@Default.Long(-1L)
Long getExecutionRetryDelay();
void setExecutionRetryDelay(Long delay);8) 设置重用对象的行为。
@Description("Sets the behavior of reusing objects.")
@Default.Boolean(false)
Boolean getObjectReuse();
void setObjectReuse(Boolean reuse);9) 设置状态后端在计算期间存储 Beam 的状态,不设置从配置文件中读取默认值。注意:仅在执行时适用流媒体模式。
@Description("Sets the state backend to use in streaming mode. "
@JsonIgnore
AbstractStateBackend getStateBackend();
void setStateBackend(AbstractStateBackend stateBackend);10) 在 Flink Runner 中启用 / 禁用 Beam 指标。
@Description("Enable/disable Beam metrics in Flink Runner")
@Default.Boolean(true)
BooleangetEnableMetrics();
voidsetEnableMetrics(BooleanenableMetrics);11) 启用或禁用外部检查点,与 CheckpointingInterval 一起使用。
@Description(
"Enables or disables externalized checkpoints."
+"Works in conjunction with CheckpointingInterval")
@Default.Boolean(false)
BooleanisExternalizedCheckpointsEnabled();
voidsetExternalizedCheckpointsEnabled(BooleanexternalCheckpoints);12) 设置当他们的 Wartermark 达到 + Inf 时关闭源,Watermark 在 Flink 中其中一个作用是根据时间戳做单节点排序,Beam 也是支持的。
@Description("If set, shutdown sources when their watermark reaches +Inf.")
@Default.Boolean(false)
BooleanisShutdownSourcesOnFinalWatermark();
voidsetShutdownSourcesOnFinalWatermark(BooleanshutdownOnFinalWatermark);剩余两个部分这里不再进行翻译,留给大家去看源码。
六. KafkaIO 和 Flink 实战本节通过解读一个真正的 KafkaIO 和 Flink 实战案例,帮助大家更深入地了解 Apache Beam KafkaIO 和 Flink 的运用。
设计架构图和设计思路解读
Apache Beam 外部数据流程图
设计思路:Kafka 消息生产程序发送 testmsg 到 Kafka 集群,Apache Beam 程序读取 Kafka 的消息,经过简单的业务逻辑,最后发送到 Kafka 集群,然后 Kafka 消费端消费消息。

Apache Beam 内部数据处理流程图
Apache Beam 程序通过 kafkaIO 读取 Kafka 集群的数据,进行数据格式转换。数据统计后,通过 KafkaIO 写操作把消息写入 Kafka 集群。最后把程序运行在 Flink 的计算平台上。
软件环境和版本说明-
系统版本 centos 7
-
Kafka 集群版本: kafka_2.10-0.10.1.1.tgz
-
Flink 版本:flink-1.5.2-bin-hadoop27-scala_2.11.tgz
Kafka 集群和 Flink 单机或集群配置,大家可以去网上搜一下配置文章,操作比较简单,这里就不赘述了。
实践步骤1)新建一个 Maven 项目
2)在 pom 文件中添加 jar 引用
<dependency>
<groupId>org.apache.beamgroupId>
<artifactId>beam-sdks-java-io-kafkaartifactId>
<version>2.4.0version>
dependency>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>0.10.1.1version>
dependency>
<dependency>
<groupId>org.apache.beamgroupId>
<artifactId>beam-runners-core-javaartifactId>
<version>2.4.0version>
dependency>
<dependency>
<groupId>org.apache.beamgroupId>
<artifactId>beam-runners-flink_2.11artifactId>
<version>2.4.0version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-javaartifactId>
<version>1.5.2version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-clients_2.11artifactId>
<version>1.5.2version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-coreartifactId>
<version>1.5.2version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-runtime_2.11artifactId>
<version>1.5.2version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-java_2.11artifactId>
<version>1.5.2version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-metrics-coreartifactId>
<version>1.5.2version>
dependency>3)新建 BeamFlinkKafka.java 类

4)编写以下代码:
public static void main(String[] args) {
// 创建管道工厂
PipelineOptions options = PipelineOptionsFactory.create();
// 显式指定 PipelineRunner:FlinkRunner 必须指定如果不制定则为本地
options.setRunner(FlinkRunner.class);
// 设置相关管道
Pipeline pipeline = Pipeline.create(options);
// 这里 kV 后说明 kafka 中的 key 和 value 均为 String 类型
PCollection> lines =
pipeline.apply(KafkaIO.// 必需设置 kafka 的服务器地址和端口
String>read().withBootstrapServers("192.168.1.110:11092,192.168.1.119:11092,192.168.1.120:11092")
.withTopic("testmsg")// 必需设置要读取的 kafka 的 topic 名称
.withKeyDeserializer(StringDeserializer.class)// 必需序列化 key
.withValueDeserializer(StringDeserializer.class)// 必需序列化 value
.updateConsumerProperties(ImmutableMap.of("auto.offset.reset", "earliest")));// 这个属性 kafka 最常见的.
// 为输出的消息类型。或者进行处理后返回的消息类型
PCollection kafkadata = lines.apply("Remove Kafka Metadata", ParDo.of(new DoFn, String>() {
private static final long serialVersionUID = 1L;
@ProcessElement
public void processElement(ProcessContext ctx) {
System.out.print("输出的分区为 ----:" + ctx.element().getKV());
ctx.output(ctx.element().getKV().getValue());// 其实我们这里是把"张海 涛在发送消息 ***"进行返回操作
}
}));
PCollection windowedEvents = kafkadata.apply(Window.into(FixedWindows.of(Duration.standardSeconds(5))));
PCollection> wordcount = windowedEvents.apply(Count.perElement()); // 统计每一个 kafka 消息的 Count
PCollection wordtj = wordcount.apply("ConcatResultKVs", MapElements.via( // 拼接最后的格式化输出(Key 为 Word,Value 为 Count)
new SimpleFunction, String>() {
private static final long serialVersionUID = 1L;
@Override
public String apply(KV input) {
System.out.print("进行统计:" + input.getKey() + ": " + input.getValue());
return input.getKey() + ": " + input.getValue();
}
}));
wordtj.apply(KafkaIO.write() .withBootstrapServers("192.168.1.110:11092,192.168.1.119:11092,192.168.1.120:11092")// 设置写会 kafka 的集群配置地址
.withTopic("senkafkamsg")// 设置返回 kafka 的消息主题
// .withKeySerializer(StringSerializer.class)// 这里不用设置了,因为上面 Void
.withValueSerializer(StringSerializer.class)
// Dataflow runner and Spark 兼容, Flink 对 kafka0.11 才支持。我的版本是 0.10 不兼容
//.withEOS(20, "eos-sink-group-id")
.values() // 只需要在此写入默认的 key 就行了,默认为 null 值
); // 输出结果
pipeline.run().waitUntilFinish();
} 5)打包 jar,本示例是简单的实战,并没有用 Docker,Apache Beam 新版本是支持 Docker 的。


6)通过 Apache Flink Dashboard 提交 job


7)查看结果

程序接收的日志如下:
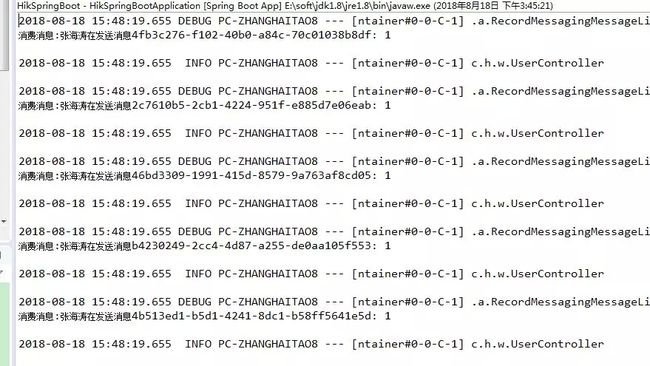
本次实战在源码分析中已经做过详细解析,在这里不做过多的描述,只选择部分问题再重点解释一下。此外,如果还没有入门,甚至连管道和 Runner 等概念都还不清楚,建议先阅读本系列的第一篇文章 《Apache Beam 实战指南之基础入门》。
1.FlinkRunner 在实战中是显式指定的,如果想设置参数怎么使用呢?其实还有另外一种写法,例如以下代码:
//FlinkPipelineOptions options =PipelineOptionsFactory.as(FlinkPipelineOptions.class);
//options.setStreaming(true);
//options.setAppName("app_test");
//options.setJobName("flinkjob");
//options.setFlinkMaster("localhost:6123");
//options.setParallelism(10);// 设置 flink 的并行度
// 显式指定 PipelineRunner:FlinkRunner,必须指定,如果不指定则为本地
options.setRunner(FlinkRunner.class);2.Kafka 有三种数据读取类型,分别是 “earliest ”,“latest ”,“none ”,分别的意思代表是:
-
earliest
当各分区下有已提交的 offset 时,从提交的 offset 开始消费;无提交的 offset 时,从头开始消费 。
-
latest
当各分区下有已提交的 offset 时,从提交的 offset 开始消费;无提交的 offset 时,消费新产生的该分区下的数据 。
-
none
topic 各分区都存在已提交的 offset 时,从 offset 后开始消费;只要有一个分区不存在已提交的 offset,则抛出异常。
.updateConsumerProperties(ImmutableMap.<String,Object>of("auto.offset.reset", "earliest")));3. 实战中我自己想把 Kafka 的数据写入,key 不想写入,所以出现了 Kafka 的 key 项为空,而 values 才是真正发送的数据。所以开始和结尾要设置个.values(),如果不加上就会报错。
KafkaIO.write()
.values() // 只需要在此写入默认的 key 就行了,默认为 null 值 随着 AI 和 loT 的时代的到来,各个公司不同结构、不同类型、不同来源的数据进行整合的成本越来越高。Apache Beam 技术的统一模型和大数据计算平台特性优雅地解决了这一问题,相信在 loT 万亿市场中,Apache Beam 将会发挥越来越重要的角色。
作者介绍张海涛,目前就职于海康威视云基础平台,负责云计算大数据的基础架构设计和中间件的开发,专注云计算大数据方向。Apache Beam 中文社区发起人之一,如果想进一步了解最新 Apache Beam 动态和技术研究成果,请加微信 cyrjkj 入群共同研究和运用。
传送门:系列文章第一篇《Apache Beam 实战指南之基础入门》