技术面试问题
CTF
说一个印象深刻的CTF的题目
- Padding Oracle->CBC->密码学(RSA/AES/DSA/SM)
- CRC32
- 反序列化漏洞
sql二次注入
第一次进行数据库插入数据的时候,仅仅只是使用了 addslashes 或者是借助 get_magic_quotes_gpc 对其中的特殊字符进行了转义,在写入数据库的时候还是保留了原来的数据,但是数据本身还是脏数据。 在将数据存入到了数据库中之后,开发者就认为数据是可信的。在下一次进行需要进行查询的时候,直接从数据库中取出了脏数据,没有进行进一步的检验和处理,这样就会造成SQL的二次注入。
交友网站,填写年龄处是一个注入点,页面会显示出与你相同年龄的用户有几个。使用and 1=1确定注入点,用order by探测列数,union select探测输出点是第几列,
- 暴库
group_concat(schema_name) from information_schema.schemata - 暴表
group_concat(table_name) from information_schema.schemata where table_schema='hhh' - 获取数据
concat(flag) from flag
修复:在从数据库或文件中取数据的时候,也要进行转义或者过滤。
Python
爬虫模块、框架、反爬虫机制(IP->代理池、验证码破解、UA)
并发(多线程、线程池、协程、三个程之间的区别)
进程是cpu资源分配的最小单位,线程是cpu调度的最小单位。以前进程既是资源分配也是调度的最小单位,后来为了更合理的使用cpu(实际上是cpu性能越来越好),才将资源分配和调度分开,就有了线程。线程是建立在进程的基础上的一次程序运行单位。
常用的标准库
functools
- itertools 迭代器
- count/cycle/repeat
- chain
- groupby 把迭代器中相邻的重复元素挑出来放在一起
- concurrent.futures
- ThreadPoolExecutor
- hashlib
- md5
- sha1
- sha256
- sha512
- logging
- sys.argv argparse读取命令行参数
- pickle 序列化工具
- re 正则
- collections 多种数据类型
- namedtuple
- OrderedDict
- Counter
- os 系统相关的函数
DJANGO和FLASK区别和使用
ORM
python安全工具编写/源码阅读
证明能力
- python安全工具开发
- python项目,记一下技术细节
密码学
RSA
DES
AES
国内SM系列
风险评估
流程
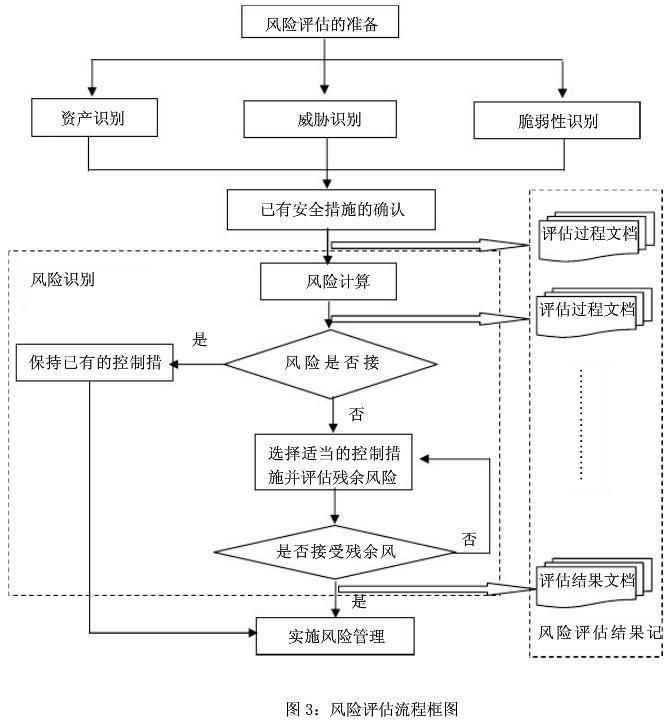
三要素
- 资产:资产价值
- 威胁:威胁主体、影响对象、出现频率、动机等
- 脆弱性:资产弱点的严重程度‘
代码审计
Fority SCA审计JAVA代码
fortify用到什么模块? 过滤器 自定义规则 生成报告
Seay审计PHP代码
源码阅读
应急响应具体流程
模型
https://zhuanlan.zhihu.com/p/26542790
PDCERF模型
- Prepare(准备):准备用来检测的工具和人
- Detection(检测):紧急事件监测:包括防火墙、系统、web服务器、IDS/WAF/SIEM中的日志,不正常或者是执行了越权操作的用户,甚至还有管理员的报告
- Containment(抑制):首先先控制受害范围,不要让攻击的影响继续蔓延到其他的IT资产和业务环境,切记不要直接一股脑的投入全部精力到封堵后门。紧接着要做的是去寻找根源原因,彻底解决,封堵攻击源,把业务恢复到更张水平
- Eradication(根除)
- Recover(恢复)
- Follow-Up(跟踪):根据各种监控去确定没有其他的攻击行为和攻击向量,紧接着就是开会反省此次事件,写报告,持续改进工作流程和工作缓解
实例
DDOS
DDOS是什么
分布式拒绝服务攻击(DDoS)是目前黑客经常采用而难以防范的攻击手段。DoS的攻击方式有很多种,最基本的DoS攻击就是利用合理的服务请求来占用过多的服务资源,从而使合法用户无法得到服务的响应。
DDOS攻击手段是在传统的DOS攻击基础之上产生的一类攻击方式。单一的DOS攻击一般是采用一对一方式的,当攻击目标CPU速度低、内存小或者网络带宽小等等各项性能指标不高它的效果是明显的。随着计算机与网络技术的发展,计算机的处理能力迅速增长,内存大大增加,同时也出现了千兆级别的网络,这使得DOS攻击的困难程度加大了——目标对恶意攻击包的“消化能力”加强了不少,例如你的攻击软件每秒钟可以发送3,000个攻击包,但我的主机与网络带宽每秒钟可以处理10,000个攻击包,这样一来攻击就不会产生什么效果这时侯分布式的拒绝服务攻击手段(DDOS)就应运而生了。
如果说计算机与网络的处理能力加大了10倍,用一台攻击机来攻击不再能起作用的话,攻击者使用10台攻击机同时攻击呢?用100台呢?DDOS就是利用更多的傀儡机来发起进攻,以比从前更大的规模来进攻受害者。通常,被攻击的服务器有以下症状:1、被攻击主机上有大量等待的TCP连接;2、网络中充斥着大量的无用的数据包,源地址为假;3、制造高流量无用数据,造成网络拥塞,使受害主机无法正常和外界通讯;4、利用受害主机提供的服务或传输协议上的缺陷,反复高速的发出特定的服务请求,使受害主机无法及时处理所有正常请求;5、严重时会造成系统死机
实例
我司网站www.catroot.cn的IP 223.223.223.223 被人DDOS攻击,流量达9G,并且机房流量清洗无效,所以把223.223.223.223封停,导致网站不能访问,请作出紧急预案。
https://www.zhihu.com/question/19581905
- 网络设备设施
- 拼带宽,加大带宽,但是成本太高
- 使用硬件防火墙
- 选用高性能设备
- 抗D思想和方案
- 负载均衡
- 花钱买流量清洗服务
- CDN:web层,比如cc攻击
- 分布式集群防御
- 高防:防大部分攻击,udp、大型的cc攻击
- 预防为主
- 系统漏洞
- 系统资源优化:
- 过滤不必要的服务和端口
- 限制特定流量:检查访问来源做适当限制
主机被入侵
- 优先提取易消失的数据
- 内存信息
- 系统进程
free -m - 路由信息
tracert
ifconfig查看网卡流量,检查网卡的发送、接收数据情况NetHogs实时监控带宽占用状况- 查看Linux系统日志
/var/log ClamAV杀毒软件
渗透测试流程相关
渗透测试流程
- 项目访谈
- 信息收集:whois、网站源IP、旁站、C段网站、服务器系统版本、容器版本、程序版本、数据库类型、二级域名、防火墙、维护者信息
- 漏洞扫描:Nessus, AWVS
- 手动挖掘:逻辑漏洞
- 验证漏洞
- 修复建议
- (如果有)基线检查/复验漏洞
- 输出报告
- 概述
- 测试基本信息
- 测试范围
- 测试时间
- 测试任务
- 测试过程
- 信息安全风险综合分析
- 整体风险分析
- 风险影响分析
- 系统安全分析
- 安全漏洞列表
- 解决方案建议
- 复测报告
渗透测试项目
用七八句话概括一下发现、验证漏洞细节、扮演角色、具体工作。 如果技术人员有兴趣会继续问,接着再引导到别处,让自己多说说细节。
渗透测试具体实施
17年OWASP TOP10
- 注入:sql,nosql,ldap,os
- 失效的身份认证:
- 敏感信息泄漏
- XXE XML外部实体
- 失效的访问控制:管理页面仅能管理员权限访问;越权漏洞
- 安全配置错误:页面错误信息,默认密码,使用已知漏洞的应用
- XSS
- 不安全的反序列化:一个PHP论坛使用PHP对象序列化来保存一个cookie,用户修改cookie即可伪造管理员登陆
- 使用含有已知漏洞的组件:比如structs2框架
- 不足的日志记录和监控:代码被删除,无法溯源;记录登陆失败次数;监控问题没被管理员响应
常见的Web安全漏洞
- SQL注入
- XSS
- 文件遍历、文件上传、文件下载
- 垂直越权、水平越权
- 逻辑漏洞
挖过什么逻辑漏洞
订单任意金额修改
相同价格增加订单数量,相同订单数量减少产品价格,订单价格设定为负数。
预防思路:
- 订单需要多重效验

- 订单数值较大的时候需要人工审核
验证码回传
漏洞一般发生在账号密码找回、账号注册、支付订单等。验证码发送途径一般为手机短信、邮箱邮件
预防思路:
- response数据内不包含验证码,验证方式主要采取后端验证,但是缺点是服务器的运算压力也会随之增加
- 如果要进行前端验证的话也可以,但是需要进行加密
未进行登陆凭证验证
有些业务的接口,因为缺少了对用户的登陆凭证的效验或者是验证存在缺陷,导致黑客可以未经授权访问这些敏感信息甚至是越权操作。比如后台页面、订单ID枚举、敏感信息可下载、没验证ID或cookie验证导致越权。
预防思路:
- 对敏感数据存在的接口和页面做cookie,ssid,token或者其它验证
接口无限制枚举
- 某电商登陆接口无验证导致撞库
- 某招聘网验证码无限制枚举
- 某快递公司优惠券枚举
- 某电商会员卡卡号枚举
预防思路:
在输入接口设置验证,如token,验证码等。如果设定验证码,最好不要单纯的采取一个前端验证,最好选择后端验证。如果设定token,请确保每个token只能采用一次,并且对token设定时间参数。
注册界面的接口不要返回太多敏感信息,以防遭到黑客制作枚举字典。
验证码不要用短数字,尽量6位以上,最好是以字母加数字进行组合,并且验证码需要设定时间期限。
优惠券,VIP卡号请尽量不要存在规律性和简短性,并且优惠券最好是以数字加字母进行组合。
cookie设置存在缺陷
- Cookie的效验值过于简单。有些web对于cookie的生成过于单一或者简单,导致黑客可以对cookie的效验值进行一个枚举.
- cookie存在被盗风险,即用户重置密码后使用老cookie依然可以通过验证
- 用户的cookie数据加密应严格使用标准加密算法,并注意密钥管理。不能采取简单的base64等算法
- 越权:平行越权:权限类型不变,权限ID改变;垂直越权:权限ID不变,权限类型改变;交叉越权:即改变ID,也改变权限
预防思路
- cookie中设定多个验证,比如自如APP的cookie中,需要sign和ssid两个参数配对,才能返回数据。
- 用户的cookie数据加密应严格使用标准加密算法,并注意密钥管理。
- 用户的cookie的生成过程中最好带入用户的密码,一旦密码改变,cookie的值也会改变。
- cookie中设定session参数,以防cookie可以长时间生效。
- 根据业务不同还有很多方法
找回密码功能缺陷
- 单纯读取内存值作为用户凭证
- 电商系统加车、下单漏洞
你常用的渗透工具有哪些,最常用的是哪个?
扫描:Nessus,AWVS,Nikto
SQLmap
https://blog.csdn.net/ski_12/article/details/58188331
常用参数
-u 单个URL -m xx.txt 多个URL
-d "mysql://user:[email protected]:3306/dvwa" 作为服务器客户端,直接连接数据库
--data post/get都适用
-p 指定扫描的参数
-r 读取文件
-f 指纹信息
--tamper 混淆脚本,用于应用层过滤
--cookie --user-agent --host等等http头的修改
--threads 并发线程 默认为1
--dbms MySQL<5.0> 指定数据库或版本
–level=LEVEL 执行测试的等级(1-5,默认为 1)
–risk=RISK 执行测试的风险(0-3,默认为 1) Risk升高可造成数据被篡改等风险
–current-db / 获取当前数据库名称
–dbs 枚举数据库管理系统数据库
–tables 枚举 DBMS 数据库中的表
–columns 枚举 DBMS 数据库表列
-D DB 要进行枚举的数据库名
-T TBL 要进行枚举的数据库表
-C COL 要进行枚举的数据库列
-U USER 用来进行枚举的数据库用户
常用的tamper
本地:sqlmap-tamper分类.xlsx
base64encode.py #转为b64编码
charencode.py url编码
chardoubleencode.py 双URL编码
unmagicquotes.py 宽字节
randomcomments.py 用/**/分割SQL关键字
space2plus.py space2comment.py space2xxxx.py 替换空格为xx
Nmap
nmap hostname/ip或者多个ip或者子网192.168.123.*
-iL ip.txt 扫描ip.txt的所有ip
-A 包含了-sV,-O,探测操作系统信息和路由跟踪。一般不用,是激烈扫描
-O 探测操作系统信息
-sV 查找主机服务版本号
-sA 探测该主机是否使用了包过滤器或防火墙
-sS 半开扫描,一般不会记入日志,不过需要root权限。
-sT TCP connect()扫描,这种方式会在目标主机的日志中记录大批的链接请求以及错误信息。
-sP ping扫描,加上这个参数会使用ping扫描,只有主机存活,nmap才会继续扫描,一般最好不加,因为有的主机会禁止ping,却实际存在。
-sN TCP空扫描
-F 快速扫描
-Pn 扫描之前不使用ping,适用于防火墙禁止ping,比较有用。
-p 指定端口/端口范围
-oN 将报告写入文件
-v 详细信息
-T<0-5> 设定速度
Nmap还可以用到爆破等一些脚本
--script all 使用所有脚本
--script=sql.injection.nse sql注入
--script="smb*" 扫smb系列
Metasploit
使用内置模块。HR:常用的模块有哪些? tcp反向链接 msfvenom
Hydra
密码爆破工具,FTP,MSSQL,MYSQL,POP3,SSH,rdp,
hydra IP -l loginname -P pass.txt PROTROCL
hydra 127.0.0.1 -l root -P pass.txt sshkali信息收集工具
- dig
- whois
- host:查询dns服务器
- nslookup
- 域名枚举:fierse -dns
- maltego
- onesixtyone
流量分析WireShark
CTF
描述一个你深入研究过的CVE或POC(ms17-010/最新的CVE)
数据库注入
https://www.zhihu.com/question/22953267
MySQL面试题
MySQL存储引擎?
- InnoDB:主流的存储引擎。支持事务、支持行锁、支持非锁定读、支持外键约束
- 为MySQL提供了具有提交、回滚和崩溃恢复能力的事物安全(ACID兼容)存储引擎。InnoDB锁定在行级并且也在 SELECT语句中提供一个类似Oracle的非锁定读。这些功能增加了多用户部署和性能。在SQL查询中,可以自由地将InnoDB类型的表和其他MySQL的表类型混合起来,甚至在同一个查询中也可以混合
- InnoDB存储引擎为在主内存中缓存数据和索引而维持它自己的缓冲池。InnoDB将它的表和索引在一个逻辑表空间中,表空间可以包含数个文件(或原始磁盘文件)。这与MyISAM表不同,比如在MyISAM表中每个表被存放在分离的文件中。InnoDB表可以是任何尺寸,即使在文 件尺寸被限制为2GB的操作系统上
- InnoDB支持外键完整性约束,存储表中的数据时,每张表的存储都按主键顺序存放,如果没有显示在表定义时指定主键,InnoDB会为每一行生成一个6字节的ROWID,并以此作为主键
- MyISAM:访问速度快,不支持事务,逐渐被淘汰
- MEMORY:BTREE索引或者HASH索引。将表中数据放在内存中,并发性能差。
information_schema用的是该引擎 - MERGE、Archive等等不常用的
什么是事务?
事务是一组原子性的SQL语句或者说是一个独立的工作单元,如果数据库引擎能够成功对数据库应用这组SQL语句,那么就执行,如果其中有任何一条语句因为崩溃或其它原因无法执行,那么所有的语句都不会执行。也就是说,事务内的语句,要么全部执行成功,要么全部执行失败。 举个银行应用的典型例子:
假设银行的数据库有两张表:支票表和储蓄表,现在某个客户A要从其支票账户转移2000元到其储蓄账户,那么至少需求三个步骤:
a.检查A的支票账户余额高于2000元;
b.从A的支票账户余额中减去2000元;
c.在A的储蓄账户余额中增加2000元。
这三个步骤必须要打包在一个事务中,任何一个步骤失败,则必须要回滚所有的步骤,否则A作为银行的客户就可能要莫名损失2000元,就出问题了。这就是一个典型的事务,这个事务是不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚,不可能只执行其中一部分,这也是事务的原子性特征。
读锁和写锁
读锁是共享的,即相互不阻塞的,多个客户在同一时刻可以读取同一资源,互不干扰。写锁是排他的,即一个写锁会阻塞其它的写锁和读锁,只有这样,才能确保给定时间内,只有一个用户能执行写入,防止其它用户读取正在写入的同一资源。写锁优先级高于读锁。
MySQL的索引
索引是帮助MySQL高效获取数据的数据结构。MYISAM和InnoDB存储引擎只支持BTree索引;MEMORY和HEAP储存引擎可以支持HASH和BTREE索引。
ORDER BY在注入的运用
GPC是什么?GPC之后怎么绕过?
如果magic_quotes_gpc=On,PHP解析器就会自动为post、get、cookie过来的数据增加转义字符“”,以确保这些数据不会引起程序,特别是数据库语句因为特殊字符(认为是php的字符)引起的污染。
Mysql一个@和两个@什么区别
- @为用户变量,使用
SET @var1=1赋值 - @@ 为系统变量 ,包括全局变量
show global variables \G;和会话变量show session variables \G;
注入/绕过常用的函数
- 基于布尔SQL盲注
left(database(),1)>'s'ascii(substr((select table_name information_schema.tables where tables_schema=database()limit 0,1),1,1))=101 --+ascii(substr((select database()),1,1))=98ORD(MID((SELECT IFNULL(CAST(username AS CHAR),0x20)FROM security.users ORDER BY id LIMIT 0,1),1,1))>98%23regexp正则注入select user() regexp '^[a-z]';select user() like 'ro%'
- 基于报错的SQL盲注
Select 1,count(*),concat(0x3a,0x3a,(select user()),0x3a,0x3a,floor(rand(0)*2))a from information_schema.columns group by a;
MySQL存储过程
各种写shell的问题
- 写shell用什么函数?
select ' into outfile 'D:/shelltest.php'dumpfilefile_put_contents
- outfile不能用了怎么办?
select unhex('udf.dll hex code') into dumpfile 'c:/mysql/mysql server 5.1/lib/plugin/xxoo.dll';可以UDF提权 https://www.cnblogs.com/milantgh/p/5444398.html - dumpfile和outfile有什么不一样?outfile适合导库,在行末尾会写入新行并转义,因此不能写入二进制可执行文件。
- sleep()能不能写shell?
- 写shell的条件?
- 用户权限
- 目录读写权限
- 防止命令执行:
disable_functions,禁止了disable_functions=phpinfo,exec,passthru,shell_exec,system,proc_open,popen,curl_exec,curl_multi_exec,parse_ini_file,show_source,但是可以用dl扩展执行命令或者ImageMagick漏洞 https://www.waitalone.cn/imagemagic-bypass-disable_function.html - open_basedir: 将用户可操作的文件限制在某目录下
注入类型
- 基于报错注入
- 基于布尔的注入,根据返回页面判断条件真假的注入
- 基于时间的盲注,不能根据页面返回内容判断任何信息,用条件语句查看时间延迟语句是否执行(即页面返回时间是否增加)来判断。
- 宽字节注入
- 联合查询,可以使用 union 的情况下的注入。
- 堆查询注入,可以同时执行多条语句的执行时的注入。
SQL注入的原理
通过把SQL命令插入到Web表单提交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令。通常未经检查或者未经充分检查的用户输入数据或代码编写问题,意外变成了代码被执行。
过waf
https://blog.csdn.net/wjy397/article/details/53263281
- 确定waf类型,狗、盾、神、锁、宝、卫士
- 使用注释符号或者特殊符号或者多个特殊符号重复
#
--
-- - //5.6.12特性,需要加空格
--+
//
/**/ //c风格注释
/**//**/ //多个注释
/*letmetest*/
;
# 科学记数法
id=0e1union select
# 空白字符
SQLite3 0A 0D 0C 09 20
MySQL5 09 0A 0B 0C 0D A0 20
PosgresSQL 0A 0D 0C 09 20
Oracle 11g 00 0A 0D 0C 09 20
MSSQL 01,02,03,04,05,06,07,08,09,0A,0B,0C,0D,0E,0F,10,11,12,13,14,15,16,17,18,19,1A,1B,1C,1D,1E,1F,20
- 使用sql内置函数或者关键字
报错注入 https://blog.csdn.net/like98k/article/details/79646512
# 常用
extractvalue
updatexml 报错注入
UPDATEXML (XML_document, XPath_string, new_value);
or updatexml(1, concat(0x7e, (version()), 0x7e), 0);
> select * from users where id = 1 and updatexml(1, concat(0x7e, (version()), 0x7e), 0);
> version() database() (SELECT concat(column_name) FROM information_schema.columns WHERE table_name='users' limit 0,1
floor()
ceil()
Mid(version(),1,1)
Substr(version(),1,1)
Substring(version(),1,1)
concat(version(),'|',user());
concat_ws('|',1,2,3)
Char(49)
Hex('a')
Unhex(61)
过滤了逗号
(1)limit处的逗号:
limit 1 offset 0
(2)字符串截取处的逗号
mid处的逗号:
mid(version() from 1 for 1)
- 利用容器特性,比如iis+asp的环境可能会吞掉%(f%rom->from)造成注入,或者iis支持unicode解析,当我们请求的url存在unicode字符串的话iis会自动将其转换,但waf可能不会拦截造成注入
- 畸形协议/请求。asp/asp.net在解析请求的时候,允许application/x-www-form-urlencoded的数据提交方式;php+apache解析协议除了get/post外随便定义协议也可能过
- %0a换行
- 多次URL编码,waf的一根筋过滤
unlencode
base64
json
binary
querystring
htmlencode
unicode
php serialize
- http参数污染,
id=1&id=2&id=3id=1,2,3
如何进行SQL注入的防御
关闭应用的错误提示
加waf
对输入进行过滤
限制输入长度
限制好数据库权限,drop/create/truncate等权限谨慎grant
预编译好sql语句,python和Php中一般使用?作为占位符。这种方法是从编程框架方面解决利用占位符参数的sql注入,只能说一定程度上防止注入。还有缓存溢出、终止字符等。
数据库信息加密安全(引导到密码学方面)。不采用md5因为有彩虹表,一般是一次md5后加盐再md5
清晰的编程规范,结对/自动化代码 review ,加大量现成的解决方案(PreparedStatement,ActiveRecord,歧义字符过滤, 只可访问存储过程 balabala)已经让 SQL 注入的风险变得非常低了。
具体的语言如何进行防注入,采用什么安全框架
作者:没啥意思 链接:https://www.zhihu.com/question/22953267/answer/23222069 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
SQL注入问题既不能“靠用户(开发者也是用户)的自觉去避免”,也不能完全脱离用户(开发者也是用户)而指望数据库层面去避免。对于那些不了解SQL注入漏洞细节或不关心SQL注入漏洞或没精力去关心SQL注入漏洞的工程师,你要给他们一条尽可能简单可行透明的方案来避免SQL注入漏洞,告诉他这样写就可以了,这就是安全框架;然后告诉他或者让他的老大告诉他你必须这样写,这就是安全编码规范;然后你有手段在他没有这样写的时候能够检查出来(这比检查出漏洞要容易)并推动他改正,这就是白盒检查。
我们现在的互联网产品SQL注入漏洞仍然层出不穷,并不是这套思路有问题,相反恰恰是这套思路没有完善。一方面是框架方案本身不完善,以SQL注入漏洞为例,参数化是防SQL注入框架级方案的重要部分,但仅靠参数化没法很好满足开发过程中一些常见需求,如逗号分割的id列表问题、排序标记的问题等等(其实这些问题真要用参数化的方案解决也可以),使得开发更愿意在这些地方使用非参数化或伪参数化的方法(比如拼接SQL片段后再把整个片段当作参数扔进去exec)。这些问题在参数化的基础上,再加以改进,仍然守着拼接SQL片段时进行强类型转换的思路,仍然是能很好解决的,也就是继续完善参数化方案的问题,而不是看上去那样“参数化解决不了问题”。另一方面,安全编码规范的制定、培训、流程建设和实施保证上也做得远远不到位,开发leader们更希望后面的数据库或者前面的安全防御上能有手段去解决SQL注入问题,对于安全工程师来说,设置并维护几个特征串、语法分析场景也远比做那些安全框架、编码规范、白盒扫描来得要轻松实在,彼此在心照不宣中度过今天,自然不能指望明天能彻底踏实。
mysql的网站注入,5.0以上和5.0以下有什么区别?
10年前就出了5.0,现在都到5.7了,没啥意义的问题
- 5.0以下没有information_schema这个系统表,无法列表名等,只能暴力跑表名。
- 5.0以下是多用户单操作,5.0以上是多用户多操做。
SQL和NoSQL的区别
SQL关系型数据库,NoSQL(Not only SQL)非关系型数据库
SQL优点
关系型数据库是指用关系数学模型来表示的数据,其中是以二维表的形式描述数据。
- 结构稳定,不易修改,常用联表查询
- 查询能力高,可以操作很复杂的查询
- 一致性高,处理数据会使用封锁保证数据不被改变
- 表具有逻辑性,易于理解
SQL缺点
- 不适用高并发读写
- 不适用海量数据高效读写
- 层次多,扩展性低
- 维护一致性开销大
- 涉及联表查询,复杂,慢
NoSQL优点
采用键值对存储数据
- 由于数据之间没有关系,所以易扩展,也易于查询
- 数据结构灵活,每个数据都可以有不同的结构
- 由于降低了一致性的要求,所以查询速度更快
比较
非关系型数据库的产生是因为随着网站的进化,并发性增加,扩展性高,一致性要求降低。这样关系型数据库最重要的一致性维护就显得有点多余,并且消耗着性能。因此有了非关系型数据库,它可以算是关系型数据库的一种弱化的结果,在海量数据存储和查询上更胜一筹。
两种数据库没有好坏之分,只是使用的环境不一样。关系型数据库可以说是更严谨的,可靠性更强的数据库,在对于数据精度要求高的环境,比如说银行系统这样自然是像mysql这样的数据库适合。非关系型数据库胜在处理大数据的速度,但是对于数据的准确度没有那么高,对于操作量大的环境比如当前大部分web2.0的网站更加适用一些。
MongoDB注入方式
利用正则:找到y开头的name db.items.find({name: {$regex: "^y"}})
一些payload
?login[$regex]=^&password[$regex]=^?login[$not][$type]=1&password[$not][$type]=1
XSS CSRF XXE
CSRF 和 XSS 和 XXE 有什么区别,以及修复方式?
xss学习 https://www.secpulse.com/?s=+%E9%82%A3%E4%BA%9B%E5%B9%B4%E6%88%91%E4%BB%AC%E4%B8%80%E8%B5%B7%E5%AD%A6XSS+
XSS是跨站脚本攻击,用户提交的数据中可以构造代码来执行,从而实现窃取用户信息等攻击。修复方式:对字符实体进行转义、使用HTTP Only来禁止JavaScript读取Cookie值、输入时校验、浏览器与Web应用端采用相同的字符编码。
CSRF是跨站请求伪造攻击,XSS是实现CSRF的诸多手段中的一种,是由于没有在关键操作执行时进行是否由用户自愿发起的确认。修复方式:筛选出需要防范CSRF的页面然后嵌入Token、再次输入密码、检验Referer.
XXE是XML外部实体注入攻击,XML中可以通过调用实体来请求本地或者远程内容,和远程文件保护类似,会引发相关安全问题,例如敏感文件读取。修复方式:XML解析库在调用时严格禁止对外部实体的解析。
CSRF、SSRF和重放攻击有什么区别?
- CSRF是跨站请求伪造攻击,由客户端发起
- SSRF是服务器端请求伪造,由服务器发起
- 重放攻击是将截获的数据包进行重放,达到身份认证等目的
啥是同源策略,跨域有几种方式?
http://www.ruanyifeng.com/blog/2016/04/same-origin-policy.html
浏览器安全的基石是"同源政策",目的是为了保证用户的信息安全,防止恶意网站窃取数据,避免cookie共享。同源含义是协议、域名、端口相同的两个网页才可以共用cookie。目前如果非同源,有三种行为收到限制: - Cookie、LocalStorage 和 IndexDB 无法读取。 - DOM 无法获得。 - AJAX 请求不能发送
如何规避同源策略?
JSONP
向服务器请求json数据回调,一般请求URL会加上&callback=xx
foo({
"ip": "8.8.8.8"
});由于