《数据科学与大数据分析——数据的发现 分析 可视化与表示》一2.8 案例研究:全球创新网络和分析(GINA)...
本节书摘来自异步社区《数据科学与大数据分析——数据的发现 分析 可视化与表示》一书中的第2章,第2.8节,作者【美】EMC Education Services(EMC教育服务团队),更多章节内容可以访问云栖社区“异步社区”公众号查看
2.8 案例研究:全球创新网络和分析(GINA)
EMC全球创新网络和分析(GINA)团队由一群在EMC全球各地卓越中心(COE)工作的高级技术专家构成。这个团队的宗旨是吸引全球卓越中心(COE)员工来从事创新、研究和大学的合作伙伴关系。在2012年,新任职的团队总监想加强这些活动,并建立一个机制来追踪和分析相关信息。此外,GINA团队想要创建更加健壮的机制来记录他们与EMC内部、学术界或者其他组织机构的思想领袖的非正式对话,用来在日后发掘洞见。
GINA团队想要提供一种在全球范围内分享想法,以及在地理上相互远离的GINA成员之间分享知识的手段。它们计划创建一个包含结构化和非结构化数据的存储库,用于实现下面三个主要目标。
- 存储正式和非正式的数据。
- 追踪全球技术专家的研究。
- 挖掘数据模式和洞察力,以提高团队的运营和战略。
GINA的案例研究展示了一个团队如何应用数据分析生命周期在EMC内分析创新数据。创新通常难以评估,该团队想要使用高级分析方法在公司内部识别关键创新者。
2.8.1 第1阶段:发现
在GINA项目的发现阶段,团队开始确定数据源。虽然GINA由一群掌握许多不同技能的技术专家组成,他们对想要探索的领域有一些相关数据和想法,但缺少一个正式的团队来执行这些分析。在咨询了包括巴布森学院(Babson College)的知名分析专家Tom Davenport、麻省理工学院集体智慧专家兼协同创新网络(CoIN,Collaborative Innovation Networks)创始人Peter Gloor等专家后,团队决定在EMC内部寻找志愿者来众包工作。
团队中的各种角色如下所示。
- 业务人员、项目发起人、项目经理:来自于首席技术官办公室的副总裁。
- 商业智能分析师:来自于IT部门的代表。
- 数据工程师和数据库管理员(DBA):来自于IT部门的代表。
- 数据科学家:EMC杰出工程师,他还开发了GINA案例研究中的社交图谱。
项目发起人想要利用社交媒体和博客[26]来加速全球创新和研究数据的收集,并激励世界范围内的数据科学家“志愿者”团队。鉴于项目发起人缺少一个正式的团队,他需要想办法找到既有能力有愿意花时间来解决问题的人。数据科学家们往往热衷于数据,项目发起人依靠这些人才的激情富有创新地完成了工作挑战。
该项目的数据主要分为两大类。第一类是近5年EMC内部创新竞赛,被称为创新线路图(以前称为创新展示),提交的创新想法。创新线路图是一个正式的、有机的创新过程,来自世界各地的员工提交创新想法,然后被审查和评判。最好的想法被选择出来进行孵化。因此,创新线路图的数据是结构化数据和非结构化数据的混合,结构化数据包括创新想法的数量、提交日期和提交者,非结构化数据包括该创新想法的文本描述。
第二类数据包括来自世界各地创新和研究活动的备忘录和笔记。这些数据也包括结构化数据和非结构化数据。结构化数据包括日期、名称、地理位置等属性。非结构化数据包括“谁、何事、何时、何地”等信息,用来表示公司内知识的增长和转移。这种类型的信息通常存在于业务部门,对研究团队几乎不可见。
GINA团队创建的10大初始假设(IH)如下所示。
- IH1:在不同地理区域的创新活动反映了企业的战略方向。
- IH2:当全球知识转移作为想法交付过程的一部分发生时,交付想法所花的时间将减少。
- IH3:参与全球知识转移的创新者能更快地交付想法。
- IH4:对提交的创新想法可以进行分析和评估,确定资助的可能性。
- IH5:某一特定主题的知识发现和增长可以跨区域进行评估和对比。
- IH6:知识转移活动可以确定在不同地区的特定研究的边界人员。
-IH7:企业战略与地理区域相对应。 - IH8:频繁的知识扩张和转移活动缩短了从想法到企业产出所花费的时间。
- IH9:谱系图可以揭示什么时候知识扩展和转移(还)没有导致企业产出。
- IH10:新兴研究课题可以按照特定的思想者、创新者、边界人员和资产进行分类。
GINA的初始假设可以被划分为2大类。
描述性分析,对当前正在发生的能进一步激发创造力、合作和资产生成的事件进行描述。
预测性分析,建议管理层未来投资的方向和领域。
2.8.2 第2阶段:数据准备
团队与IT部门合作建立了一个新的分析沙箱用于存储和实验数据。在数据探索期间,数据科学家和数据工程师开始注意到某些数据需要治理和规范化。此外,团队意识到某些缺失的数据集对于检验一些分析假设非常关键。
当团队探索数据时,他们很快就意识到,如果数据的质量不够好或者没有足够的高质量数据,就无法执行生命周期过程中的后续步骤。因此,确定项目需要什么级别的数据质量和清洁度非常重要。在GINA案例中,团队发现许多研究者和大学人员的名字被拼错,或者在数据存储中的首尾有空格。这些看似数据中的小问题都必须在本阶段解决,以便在随后阶段更好地分析和聚合数据。
2.8.3 第3阶段:模型规划
在GINA项目中,对于大部分数据集来说,似乎可以使用社交网络分析技术来研究EMC的创新者网络。在其他情况下,由于数据的缺乏很难恰当地检验假设。针对IH9,团队决定发起一个纵向研究来跟踪知识产权产出随时间的变化。这种数据收集将使团队可以检验以下两种初始假设。
- IH8:频繁的知识扩张和转移活动缩短了从想法到企业产出所花费的时间。
- IH9:谱系图可以揭示什么时候知识扩展和转移(还)没有导致企业产出。
对于提出的纵向研究,团队需要建立研究的目标标准。具体来说,团队需要确定遍历了整个过程的成功创意的最终目标。针对研究范围要考虑以下注意事项。
确定实现目标所要经历的里程碑。
追踪人们如何从每个里程碑出发进化创意。
追踪失败的创意和达成了目标的创意,对比两种创意的不同历程。
取决于数据如何收集和封装,使用不同的方法比较时间和结果。这可能会像t检验(t-test)那样简单,也可能会涉及不同的分类算法。
2.8.4 第4阶段:模型建立
在第4阶段,GINA团队采用了若干种分析方法。其中包括数据科学家使用自然语言处理(NLP)技术来处理创新线路图的创新想法的文本描述。此外,数据科学家使用R和RStudio进行社交网络分析,然后使用R的ggplot2包创建社交图谱和创新网络的可视化。这项工作的示例如图2.10和图2.11所示。
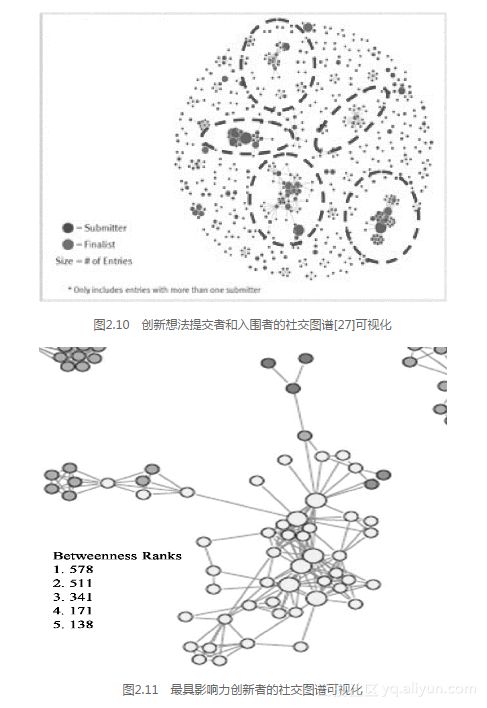
图2.10中的社交图谱描述了GINA中创新想法提交者之间的关系。每一种颜色代表来自不同国家的创新者。带红圈的点是中心(hub),代表一个具有较高的连通性和较高的“中间型(betweenness)”分数的创新者。图2.11中的聚类包含地理的多样性,这在证明地理边界人员的假设时至关重要。该图中有一个研究科学家比图中其他人的分数高很多。数据科学家识别出了这个人,并在分析沙箱中对其运行了分析,生成了关于他的如下信息,证明他在公司中很有影响力。
2011年,他参加了ACM SIGMOD会议,这是一个大规模数据管理和数据库方面的顶级会议。
他拜访了EMC Documentum内容管理团队位于法国的业务部门(现在IIG部门的一部分)。
在一个虚拟午餐会议上,他向3名俄罗斯员工、1名开罗员工、1名爱尔兰员工、1名印度员工、3名美国员工和1名以色列员工介绍了参加SIGMOD会议的感想。
2012年,他参加了在加州召开的SDM 2012会议。
在参加SDM会议后,他拜访了EMC、Pivotal和VMware的创新者和研究员。
随后,他在一个内部技术会议上,向数十名公司创新和研究人员介绍了他的二位研究人员。
这一发现表明,至少部分初级假设是正确的,即数据可以识别跨越不同地域和业务部门的创新者。团队使用了Tableau软件进行数据可视化和探索,使用了Pivotal GreenPlum数据库作为主数据仓库和分析引擎。
2.8.5 第5阶段:沟通结果
在第5阶段中,团队发现了若干种方法来过滤分析结果和识别最有影响和最相关的发现。这个项目在识别边界人员和隐藏的创新者方面是成功的。因此,首席技术官办公室发起了纵向研究,开始收集更长时间跨度上的创新数据。GINA项目促进公司内外跨区域的创新和研究相关的知识分享。GINA也使得EMC创造了更多的知识产权和生成了更多的研究主题,并促进了与大学的科研合作关系,以便在数据科学和大数据方面进行联合学术研究。此外,由于有杰出工程师和数据科学家作为志愿者参与了该项目,因此该项目在预算有限的情况下顺利完成。
该项目中的一个重要发现是,在爱尔兰的科克市有相当多的创新者。EMC在每年举办一次创新竞赛,让员工提出可以为公司带来新价值的创新理念。回顾2011年的相关数据,15%的入围者和15%的获奖者都来自爱尔兰。考虑到爱尔兰科克市的COE相对较小的规模,这些数字就异常惊人了。进一步研究后发现,科克COE员工接受了来自外部顾问关于创新的集中培训,这被证明是非常有效的。因此科克的COE想出了更多、更好的创新点子,为EMC的创新做出了巨大的贡献。传统的或者“八卦式”的口口相传的方法将很难识别这个创新者群体。团队运用社交网络分析发现了在EMC中谁做了巨大的贡献。这些研究结果通过演示和会议在内部分享,并通过社交媒体和博客进行了推广。
2.8.6 第6阶段:实施
在一个装载了创新者笔记、备忘录和演示报告的沙箱中运行分析产生了对EMC创新文化的深刻见解。来自该项目的关键发现包括以下这些。
首席技术官办公室和GINA在将来需要更多的包括营销计划在内的数据,以解读EMC全球的创新和研究活动。
有些数据非常敏感,团队需要考虑数据的安全性和私密性,比如谁可以运行模型并看到结果。
除了运行模型,还需要改进基本的商业智能,比如仪表盘、报告和全球研究活动的查询。
在部署模型后,需要有一套机制来持续不断地评估模型。评估模型的好处也是这一阶段的主要目标之一,并需要定义一个过程来按需重新训练模型。
除了上述的行为和发现,团队还演示了如何在项目中通过分析发现新的见解,而这些见解在传统上是很难进行评估和量化的。这个项目促使首席技术官办公室对大学研究项目进行资助,也发现了隐藏的、高价值的创新者。此外,首席技术官办公室还开发了工具来帮助创新想法提交者使用新的融合了主题建模技术的推荐系统来寻找类似的想法,改进自己的想法和完善新知识产权的提案。
表2.3列出了GINA案例中的分析计划。尽管这个项目只展示了3个发现,但实际上有许多。例如,这个项目最大的综合性结果也许就是它以具体的方式展示了分析可以从关于像创新这样难于评估的主题的项目中发现新的见解。

每个公司都想要加强创新,但却很难评估创新或确定增加创新的方法。本项目从这样一个角度来探索这个问题,即通过评价非正式社交网络来识别创新子网络内的边界人员和有影响力的人。本质上,这个项目应用了高级的分析方法,基于客观事实梳理出了一个看似模糊的问题的答案。
这个项目的另一个结论是,需要为商业智能报表建立一个单独的数据存储来搜索创新和研究举措。除了支持决策,这也能提供一种知晓全球范围内不同区域的团队成员之间的讨论和研究的机制。这个项目同时强调了通过数据和分析可以获得的价值。因此,应该启动正式的营销计划,以说服人们在全球社区提交或者告知他们的创新/研究活动。知识共享是关键,否则GINA也将无法执行分析并识别隐藏在公司内部的创新者。