2017年ACL的四个NLP深度学习趋势 (二):可解释性和注意力(Interpretability and Attention)...
更多深度文章,请关注:https://yq.aliyun.com/cloud
2017年ACL的四个NLP深度学习趋势 (一):语言结构和词汇嵌入(Linguistic Structure and Word Embeddings)
趋势3:可解释性(Interpretability)
我最近一直在思考可解释性,然而我并不孤单,在深度学习实践者中,神经网络的可怕的“黑匣子”质量使他们难以控制,难以调试。然而,从非研究者的角度来看,有一个更重要的理由要求可解释性:信任。

公众,媒体和一些研究人员如果不能理解AI是否可以信任,反而表示更加担心,虽然这些焦虑是有根据的(见“Facebook聊天发明自己的语言”故事)。例如,如果AI系统吸收了训练数据中存在的不必要的偏差,但是我们无法检查这些偏差,那么我们就有一个灾难的系统。第二,由于人工智能系统不完善,有时会失败,所以我们必须能够检查自己的决策,特别是对于比较复杂的任务。第三,即使AI系统运行良好,人类也许总是需要解释来说服自己。
那么到底什么是可解释性?在研究人员看来“可解释性”也可以有许多定义,对于这些定义的看法,我强烈推荐Zachary Lipton的“模型解释的神话”。特别是,利普顿确定了两种广泛的解释方式:事后解释和透明度。事后解释采取学习模式,并从中吸取一些有用的见解;通常,这些见解仅提供模型的工作原理部分或间接解释。透明度更直接地提出“模式如何工作”,并寻求提供一些方法来了解模型本身的核心机制。
事后解释
在今年的ACL,我看到许多论文提出了各种创造性的方法,以获得神经系统的事后洞察。
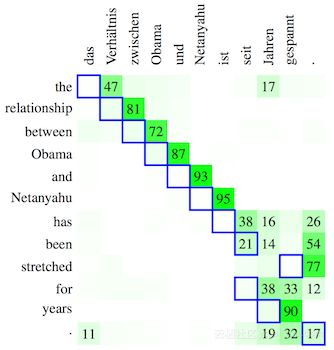
可视化可能是最常见的事后解释类型,特定类型的可视化(如显着图和字预测)成为标准,这些可视化是有用的。在可视化和理解神经机器翻译中,计算相关性分数,量化了特定神经元对另一个神经元的贡献。论文中提供的可视化看起来非常类似于从注意力分布产生的可视化。然而,计算的方法是不同的。相关性分数是直接衡量一个神经元在受训模型中对下游神经元的影响。Ding等人的相关性分数提供了一种有效的替代方法来测量序列到序列模型中的词级相关性。
转移学习是另一种流行的事后解释技术,其中任务A(通常是高级任务)为学习的代表被应用于任务B(通常是较低级别的任务)。任务B的成功程度表明任务A模型已经学到了任务B。
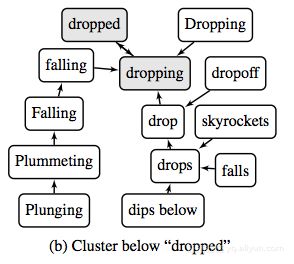
虽然转移学习和注意力可视化可以告诉你“多少”,但他们不会告诉你 “为什么”。为了回答后者,一些研究人员直接研究了表示空间几何的本身。在神经读者的隐藏状态向量中的紧急预测结构中.Wang et al。他提供证据表明,在基于RNN的阅读理解模型中,隐藏的向量空间可以分解为两个正交子空间:一个包含实体的表示,另一个包含关于这些实体的语句(或谓词)的表示。在用于分析连续词嵌入的参数自由分层图形分簇中,Trost和Klakow对字嵌入进行聚类,以获得层次化的树状结构。根据本文提供的示例,层次结构可以提供更可读的方式来探索词嵌入的邻域结构。
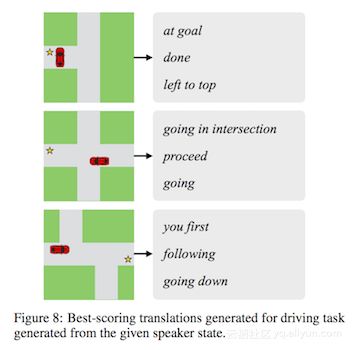
直接进行事后解释的另一种方法是将解释本身视为翻译任务。在翻译神经.Andreas et al。他采取训练进行协作任务的两台机器之间传递的向量信息,并将其转化为自然语言语言。
透明度
尽管从无法解释的神经模型中收集了所有的工作数据,但一些研究者认为盯着神经元只会让我们毫无所获。真正的可解释性要求透明度——构建和训练的模型本身可以解释。
根据定义,语言结构化表示比非结构化表示更容易解释。因此趋势1也可以被看作是向更透明的神经网络模型的转变。神经网络是强大的,因为它们可以学习任意连续的表示。但人类发现离散的信息,比如语言本身,更容易理解。
我们可能担心我们对神经模型的强制性限制会降低其表现力。担心解释性会以有效性为代价。但是,稀疏性诱导正则化可以改善在不损害神经模型的前提下,并且稀疏的词嵌入可以比原始密集法更有效。在多语言序列标签的神经词嵌入的稀疏编码中,Gábor Berend展示了稀疏词嵌入对NER和POS标签的有效性,特别是在有少量训练数据的情况下。

对于回答复杂问题的AI系统,如果人类信任答案,透明度尤为重要。这些系统应该理想地产生答案的证明或推导过程。对于解决数学问题的系统,证明应该是一个逐步的自然语言派生的最终答案。这正是Ling等人提供的基于生成原理的程序导入:学习解决和解释代数词问题。他们的系统不是直接和毫无瑕疵地产生最终答案,而是共同学习产生数学转换的基本序列。

期待
我不确定事后可解释性或透明度是正确的道路。事后可解释性倾向于给出有限的解释,虽然迷人,但通常是隐藏的本身。我认为更灵活的解释技术,是基于翻译的方法。虽然他们提出了关于信任的问题。另一方面,透明度是有吸引力的,因为可解释性应该是一个设计选择,而不是事后的想法。虽然我们还没有建立透明的端到端的神经系统,但是使系统的一小部分透明化也非常有用。请注意,注意机制作为一个健全检查和调试工具有助于开发系统。
趋势4:注意力(Attention)
注意机制正在迅速成为最流行的技术,它可以用于绕过信息流中的瓶颈,它能够实现无法通过前馈层实现的键值查找功能,并提供了一些非常需要的解释性。注意力机制在今年的ACL上有所增加,论文一共有十五篇,比上年的九个有所增加。
无处不在的更多注意力机制
注意机制是序列到序列框架中最可操作的一部分。因此,研究人员通过设计越来越复杂的注意力模型来寻求成功,目标是解决特定的特定任务问题。
有三篇论文提出了问题回答的模式,在这些模型(注意注意力,交叉注意力和门控注意力)中,第三种模型引入了多跳注意力,这使得模型在得到答案之前可以迭代地遍历不同的部分。本文的附录包含几个演示了多跳推理的必要性和有效性的例子。

注意力也已经成为衡量和综合来自多个潜在的多模态信息源的标准方法。Libovicky等人 Lin等人考虑同时通过文本和图像来翻译标题。在这些情况下,注意力很方便,因为它提供了从任意数量的源获取固定大小的表示的一般方法。
其他人发现,在多个维度上应用注意力对某些任务很有用。例如,语法错误纠正需要嵌套注意力:字级注意检测字顺序错误,以及字符级注意检测拼写错误。
所以你需要注意吗?
注意力机制的热情似乎可以证实最近大胆的声称:注意力是你需要的。然而,在ACL,我注意到一些研究人员提供关于潜在的陷阱或注意力错误的警告信息。
例如,有些情况下,我们可能希望注意力不起作用·Tan et al。他认为对于抽象文献总结,注意力分布不能有效地模拟源句子的显著性。相反,他们通过使用深度学习的提取摘要算法(基于PageRank的句子排名),从而获得更大的成功。这个结果作为一个重要的提醒:我们不应该丢弃过去几十年的积累的NLP知识,虽然不时尚,但这些技术可能提供改善我们神经系统的关键。
另外可能在一些情况下,注意力是多余的。Bollman等人 发现当他们引入多任务学习的辅助任务时,增加注意力机制就变得有害而不是有用。作为解释,他们提供了证据表明辅助任务中增加注意力机制是多余的。虽然我不完全理解注意力和多任务学习之间的这种互动,但我们应该注意这一现象,因为它对未来系统的发展构成潜在的陷阱。

期待
虽然注意力最初被认为是解决对序列到序列NMT的瓶颈问题,但事实证明它是一个更为基础和通用的技术。通过考虑为什么关注如此受欢迎,我们可能会了解到当前深度学习社区的需求。例如需要解释性,长距离依赖性以及动态结构。我认为注意力机制只是实现这些事情的第一步。
结论
虽然这只是我参加过的第二个ACL,但我对今年的组委会印象深刻,他们通过透明度,听取社群的意见,并且积极处理这些问题。在这个非常依靠经验驱动的时代,我们认为我们应该追求并做好可以复制和重现的假设驱动的科学。
在深度学习高速发展的这几年,NLP社区有理由感到兴奋和焦虑。但我对社区有信心,随着时代的变化而保持其集体智慧。所以,不需要炒作也不要害怕。深度学习既不是NLP的终极解决方案也不是死亡。
本文由北邮@爱可可-爱生活老师推荐,阿里云云栖社区组织翻译。
文章原标题《machine-learning-vs-statistics》,
作者:abigail Chris Manning教授的博士生
个人网站:http://www.abigailsee.com
译者:袁虎 审阅:主题曲哥哥
文章为简译,更为详细的内容,请查看原文