2019独角兽企业重金招聘Python工程师标准>>> 
块设备驱动程序的分层结构
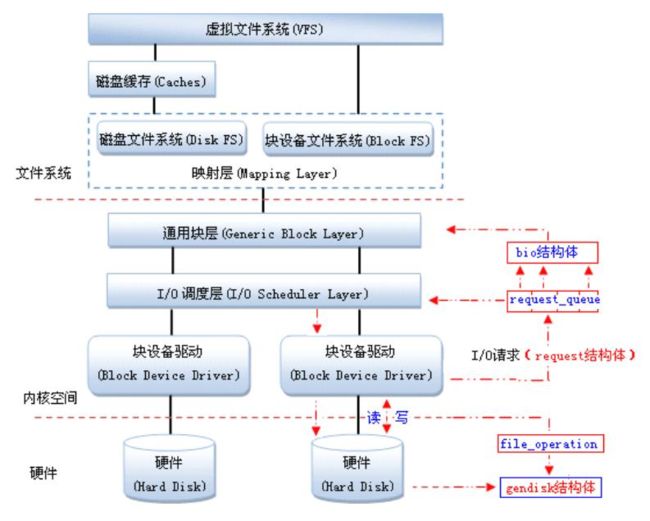
块设备驱动:在Linux中,驱动对块设备的输入或输出(I/O)操作,都会向块设备发出一个请求,在驱动中用request结构体描述。但对于一些磁盘设备而言请求的速度很慢,这时候内核就提供一种队列的机制把这些I/O请求添加到队列中(即:请求队列),在驱动中用request_queue结构体描述。在向块设备提交这些请求前内核会先执行请求的合并和排序预操作,以提高访问的效率,然后再由内核中的I/O调度程序子系统来负责提交 I/O 请求,调度程序将磁盘资源分配给系统中所有挂起的块 I/O 请求,其工作是管理块设备的请求队列,决定队列中的请求的排列顺序以及什么时候派发请求到设备。
通用块层(Generic Block Layer):负责维持一个I/O请求在上层文件系统与底层物理磁盘之间的关系。在通用块层中,通常用一个bio结构体来对应一个I/O请求。
Linux提供了一个gendisk数据结构体,用来表示一个独立的磁盘设备或分区,用于对底层物理磁盘进行访问。在gendisk中有一个类似字符设备中file_operations的硬件操作结构指针,是block_device_operations结构体。
IO调度层:当多个请求提交给块设备时,执行效率依赖于请求的顺序。如果所有的请求是同一个方向(如:写数据),执行效率是最大的。内核在调用块设备驱动程序例程处理请求之前,先收集I/O请求并将请求排序,然后,将连续扇区操作的多个请求进行合并以提高执行效率(内核算法会自己做,不用你管),对I/O请求排序的算法称为电梯算法(elevator algorithm)。电梯算法在I/O调度层完成。内核提供了不同类型的电梯算法,电梯算法有
- noop(实现简单的FIFO,基本的直接合并与排序)
- anticipatory(延迟I/O请求,进行临界区的优化排序)
- Deadline(针对anticipatory缺点进行改善,降低延迟时间)
- Cfq(均匀分配I/O带宽,公平机制)
映射层(Mapping Layer):起映射作用,将文件访问映射为设备的访问。
VFS:对各种文件系统进行统一封装,为用户程序访问文件提供统一的接口,包含ext2,FAT,NFS,设备文件。
磁盘缓存(Caches):将访问频率很高的文件放入其中。
块设备驱动内核数据结构关系图


块设备驱动实例
/*
* Sample disk driver, from the beginning.
*/
#include
#include
#include
#include
#include /* printk() */
#include /* kmalloc() */
#include /* everything... */
#include /* error codes */
#include /* size_t */
#include /* O_ACCMODE */
#include /* HDIO_GETGEO */
#include
#include
#include
#include
#include /* invalidate_bdev */
#include
#ifndef BLK_STS_OK
typedef int blk_status_t;
#define BLK_STS_OK 0
#define OLDER_KERNEL 1
#endif
#ifndef BLK_STS_IOERR
#define BLK_STS_IOERR 10
#endif
#ifndef SECTOR_SHIFT
#define SECTOR_SHIFT 9
#endif
/* FIXME: implement these macros in kernel mainline */
#define size_to_sectors(size) ((size) >> SECTOR_SHIFT)
#define sectors_to_size(size) ((size) << SECTOR_SHIFT)
MODULE_LICENSE("Dual BSD/GPL");
static int sbull_major;
module_param(sbull_major, int, 0);
static int logical_block_size = 512;
module_param(logical_block_size, int, 0);
static char* disk_size = "256M";
module_param(disk_size, charp, 0);
static int ndevices = 1;
module_param(ndevices, int, 0);
static bool debug = false;
module_param(debug, bool, false);
/*
* The different "request modes" we can use.
*/
enum {
RM_SIMPLE = 0, /* The extra-simple request function */
RM_FULL = 1, /* The full-blown version */
RM_NOQUEUE = 2, /* Use make_request */
};
/*
* Minor number and partition management.
*/
#define SBULL_MINORS 16
/*
* We can tweak our hardware sector size, but the kernel talks to us
* in terms of small sectors, always.
*/
#define KERNEL_SECTOR_SIZE 512
/*
* The internal representation of our device.
*/
struct sbull_dev {
int size; /* Device size in sectors */
u8 *data; /* The data array */
spinlock_t lock; /* For mutual exclusion */
struct request_queue *queue; /* The device request queue */
struct gendisk *gd; /* The gendisk structure */
struct blk_mq_tag_set tag_set;
};
static struct sbull_dev *Devices;
/* Handle an I/O request */
static blk_status_t sbull_transfer(struct sbull_dev *dev, unsigned long sector,
unsigned long nsect, char *buffer, int op)
{
unsigned long offset = sectors_to_size(sector);
unsigned long nbytes = sectors_to_size(nsect);
if ((offset + nbytes) > dev->size) {
pr_notice("Beyond-end write (%ld %ld)\n", offset, nbytes);
return BLK_STS_IOERR;
}
if (debug)
pr_info("%s: %s, sector: %ld, nsectors: %ld, offset: %ld,"
" nbytes: %ld",
dev->gd->disk_name,
op == REQ_OP_WRITE ? "WRITE" : "READ", sector, nsect,
offset, nbytes);
/* will be only REQ_OP_READ or REQ_OP_WRITE */
if (op == REQ_OP_WRITE)
memcpy(dev->data + offset, buffer, nbytes);
else
memcpy(buffer, dev->data + offset, nbytes);
return BLK_STS_OK;
}
static blk_status_t sbull_queue_rq(struct blk_mq_hw_ctx *hctx,
const struct blk_mq_queue_data *bd)
{
struct request *req = bd->rq;
struct sbull_dev *dev = req->rq_disk->private_data;
int op = req_op(req);
blk_status_t ret;
blk_mq_start_request(req);
spin_lock(&dev->lock);
if (op != REQ_OP_READ && op != REQ_OP_WRITE) {
pr_notice("Skip non-fs request\n");
blk_mq_end_request(req, BLK_STS_IOERR);
spin_unlock(&dev->lock);
return BLK_STS_IOERR;
}
ret = sbull_transfer(dev, blk_rq_pos(req),
blk_rq_cur_sectors(req),
bio_data(req->bio), op);
blk_mq_end_request(req, ret);
spin_unlock(&dev->lock);
return ret;
}
/*
* The device operations structure.
*/
static const struct block_device_operations sbull_ops = {
.owner = THIS_MODULE,
};
static const struct blk_mq_ops sbull_mq_ops = {
.queue_rq = sbull_queue_rq,
};
static struct request_queue *create_req_queue(struct blk_mq_tag_set *set)
{
struct request_queue *q;
#ifndef OLDER_KERNEL
q = blk_mq_init_sq_queue(set, &sbull_mq_ops,
2, BLK_MQ_F_SHOULD_MERGE | BLK_MQ_F_BLOCKING);
#else
int ret;
memset(set, 0, sizeof(*set));
set->ops = &sbull_mq_ops;
set->nr_hw_queues = 1;
/*set->nr_maps = 1;*/
set->queue_depth = 2;
set->numa_node = NUMA_NO_NODE;
set->flags = BLK_MQ_F_SHOULD_MERGE | BLK_MQ_F_BLOCKING;
ret = blk_mq_alloc_tag_set(set);
if (ret)
return ERR_PTR(ret);
q = blk_mq_init_queue(set);
if (IS_ERR(q)) {
blk_mq_free_tag_set(set);
return q;
}
#endif
return q;
}
/*
* Set up our internal device.
*/
static void setup_device(struct sbull_dev *dev, int which)
{
long long sbull_size = memparse(disk_size, NULL);
memset(dev, 0, sizeof(struct sbull_dev));
dev->size = sbull_size;
dev->data = vzalloc(dev->size);
if (dev->data == NULL) {
pr_notice("vmalloc failure.\n");
return;
}
spin_lock_init(&dev->lock);
dev->queue = create_req_queue(&dev->tag_set);
if (IS_ERR(dev->queue))
goto out_vfree;
blk_queue_logical_block_size(dev->queue, logical_block_size);
dev->queue->queuedata = dev;
/*
* And the gendisk structure.
*/
dev->gd = alloc_disk(SBULL_MINORS);
if (!dev->gd) {
pr_notice("alloc_disk failure\n");
goto out_vfree;
}
dev->gd->major = sbull_major;
dev->gd->first_minor = which*SBULL_MINORS;
dev->gd->fops = &sbull_ops;
dev->gd->queue = dev->queue;
dev->gd->private_data = dev;
snprintf(dev->gd->disk_name, 32, "sbull%c", which + 'a');
set_capacity(dev->gd, size_to_sectors(sbull_size));
add_disk(dev->gd);
return;
out_vfree:
if (dev->data)
vfree(dev->data);
}
static int __init sbull_init(void)
{
int i;
/*
* Get registered.
*/
sbull_major = register_blkdev(sbull_major, "sbull");
if (sbull_major <= 0) {
pr_warn("sbull: unable to get major number\n");
return -EBUSY;
}
/*
* Allocate the device array, and initialize each one.
*/
Devices = kmalloc(ndevices * sizeof(struct sbull_dev), GFP_KERNEL);
if (Devices == NULL)
goto out_unregister;
for (i = 0; i < ndevices; i++)
setup_device(Devices + i, i);
return 0;
out_unregister:
unregister_blkdev(sbull_major, "sbull");
return -ENOMEM;
}
static void sbull_exit(void)
{
int i;
for (i = 0; i < ndevices; i++) {
struct sbull_dev *dev = Devices + i;
if (dev->gd) {
del_gendisk(dev->gd);
put_disk(dev->gd);
}
if (dev->queue)
blk_cleanup_queue(dev->queue);
if (dev->data)
vfree(dev->data);
}
unregister_blkdev(sbull_major, "sbull");
kfree(Devices);
}
module_init(sbull_init);
module_exit(sbull_exit); 可以编写Makefile:
obj-m += sbull.o
CURRENT_PATH:=$(shell pwd)
LINUX_KERNEL:=$(shell uname -r)
LINUX_KERNEL_PATH:=/usr/src/kernels/$(LINUX_KERNEL)
all:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules
clean:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) clean
或者直接使用linux内核中提供的/drivers/block/brd.c
/*
* Ram backed block device driver.
*
* Copyright (C) 2007 Nick Piggin
* Copyright (C) 2007 Novell Inc.
*
* Parts derived from drivers/block/rd.c, and drivers/block/loop.c, copyright
* of their respective owners.
*/
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#define PAGE_SECTORS_SHIFT (PAGE_SHIFT - SECTOR_SHIFT)
#define PAGE_SECTORS (1 << PAGE_SECTORS_SHIFT)
static int ramdisk_major;
/*
* Each block ramdisk device has a radix_tree brd_pages of pages that stores
* the pages containing the block device's contents. A brd page's ->index is
* its offset in PAGE_SIZE units. This is similar to, but in no way connected
* with, the kernel's pagecache or buffer cache (which sit above our block
* device).
*/
struct brd_device {
int brd_number;
struct request_queue *brd_queue;
struct gendisk *brd_disk;
struct list_head brd_list;
/*
* Backing store of pages and lock to protect it. This is the contents
* of the block device.
*/
spinlock_t brd_lock;
struct radix_tree_root brd_pages;
};
/*
* Look up and return a brd's page for a given sector.
*/
static struct page *brd_lookup_page(struct brd_device *brd, sector_t sector)
{
pgoff_t idx;
struct page *page;
/*
* The page lifetime is protected by the fact that we have opened the
* device node -- brd pages will never be deleted under us, so we
* don't need any further locking or refcounting.
*
* This is strictly true for the radix-tree nodes as well (ie. we
* don't actually need the rcu_read_lock()), however that is not a
* documented feature of the radix-tree API so it is better to be
* safe here (we don't have total exclusion from radix tree updates
* here, only deletes).
*/
rcu_read_lock();
idx = sector >> PAGE_SECTORS_SHIFT; /* sector to page index */
page = radix_tree_lookup(&brd->brd_pages, idx);
rcu_read_unlock();
BUG_ON(page && page->index != idx);
return page;
}
/*
* Look up and return a brd's page for a given sector.
* If one does not exist, allocate an empty page, and insert that. Then
* return it.
*/
static struct page *brd_insert_page(struct brd_device *brd, sector_t sector)
{
pgoff_t idx;
struct page *page;
gfp_t gfp_flags;
page = brd_lookup_page(brd, sector);
if (page)
return page;
/*
* Must use NOIO because we don't want to recurse back into the
* block or filesystem layers from page reclaim.
*/
gfp_flags = GFP_NOIO | __GFP_ZERO | __GFP_HIGHMEM;
page = alloc_page(gfp_flags);
if (!page)
return NULL;
if (radix_tree_preload(GFP_NOIO)) {
__free_page(page);
return NULL;
}
spin_lock(&brd->brd_lock);
idx = sector >> PAGE_SECTORS_SHIFT;
page->index = idx;
if (radix_tree_insert(&brd->brd_pages, idx, page)) {
__free_page(page);
page = radix_tree_lookup(&brd->brd_pages, idx);
BUG_ON(!page);
BUG_ON(page->index != idx);
}
spin_unlock(&brd->brd_lock);
radix_tree_preload_end();
return page;
}
/*
* Free all backing store pages and radix tree. This must only be called when
* there are no other users of the device.
*/
#define FREE_BATCH 16
static void brd_free_pages(struct brd_device *brd)
{
unsigned long pos = 0;
struct page *pages[FREE_BATCH];
int nr_pages;
do {
int i;
nr_pages = radix_tree_gang_lookup(&brd->brd_pages,
(void **)pages, pos, FREE_BATCH);
for (i = 0; i < nr_pages; i++) {
void *ret;
BUG_ON(pages[i]->index < pos);
pos = pages[i]->index;
ret = radix_tree_delete(&brd->brd_pages, pos);
BUG_ON(!ret || ret != pages[i]);
__free_page(pages[i]);
}
pos++;
/*
* This assumes radix_tree_gang_lookup always returns as
* many pages as possible. If the radix-tree code changes,
* so will this have to.
*/
} while (nr_pages == FREE_BATCH);
}
/*
* copy_to_brd_setup must be called before copy_to_brd. It may sleep.
*/
static int copy_to_brd_setup(struct brd_device *brd, sector_t sector, size_t n)
{
unsigned int offset = (sector & (PAGE_SECTORS-1)) << SECTOR_SHIFT;
size_t copy;
copy = min_t(size_t, n, PAGE_SIZE - offset);
if (!brd_insert_page(brd, sector))
return -ENOSPC;
if (copy < n) {
sector += copy >> SECTOR_SHIFT;
if (!brd_insert_page(brd, sector))
return -ENOSPC;
}
return 0;
}
/*
* Copy n bytes from src to the brd starting at sector. Does not sleep.
*/
static void copy_to_brd(struct brd_device *brd, const void *src,
sector_t sector, size_t n)
{
struct page *page;
void *dst;
unsigned int offset = (sector & (PAGE_SECTORS-1)) << SECTOR_SHIFT;
size_t copy;
pr_info("copy_to_ramdisk: sector: %d,size: %d\n",(int)sector,(int)n);
copy = min_t(size_t, n, PAGE_SIZE - offset);
page = brd_lookup_page(brd, sector);
BUG_ON(!page);
dst = kmap_atomic(page);
memcpy(dst + offset, src, copy);
kunmap_atomic(dst);
if (copy < n) {
src += copy;
sector += copy >> SECTOR_SHIFT;
copy = n - copy;
page = brd_lookup_page(brd, sector);
BUG_ON(!page);
dst = kmap_atomic(page);
memcpy(dst, src, copy);
kunmap_atomic(dst);
}
}
/*
* Copy n bytes to dst from the brd starting at sector. Does not sleep.
*/
static void copy_from_brd(void *dst, struct brd_device *brd,
sector_t sector, size_t n)
{
struct page *page;
void *src;
unsigned int offset = (sector & (PAGE_SECTORS-1)) << SECTOR_SHIFT;
size_t copy;
pr_info("copy_from_ramdisk: sector: %d,size: %d\n",(int)sector,(int)n);
copy = min_t(size_t, n, PAGE_SIZE - offset);
page = brd_lookup_page(brd, sector);
if (page) {
src = kmap_atomic(page);
memcpy(dst, src + offset, copy);
kunmap_atomic(src);
} else
memset(dst, 0, copy);
if (copy < n) {
dst += copy;
sector += copy >> SECTOR_SHIFT;
copy = n - copy;
page = brd_lookup_page(brd, sector);
if (page) {
src = kmap_atomic(page);
memcpy(dst, src, copy);
kunmap_atomic(src);
} else
memset(dst, 0, copy);
}
}
/*
* Process a single bvec of a bio.
*/
static int brd_do_bvec(struct brd_device *brd, struct page *page,
unsigned int len, unsigned int off, unsigned int op,
sector_t sector)
{
void *mem;
int err = 0;
if (op_is_write(op)) {
err = copy_to_brd_setup(brd, sector, len);
if (err)
goto out;
}
mem = kmap_atomic(page);
if (!op_is_write(op)) {
copy_from_brd(mem + off, brd, sector, len);
flush_dcache_page(page);
} else {
flush_dcache_page(page);
copy_to_brd(brd, mem + off, sector, len);
}
kunmap_atomic(mem);
out:
return err;
}
static blk_qc_t brd_make_request(struct request_queue *q, struct bio *bio)
{
struct brd_device *brd = bio->bi_disk->private_data;
struct bio_vec bvec;
sector_t sector;
struct bvec_iter iter;
sector = bio->bi_iter.bi_sector;
if (bio_end_sector(bio) > get_capacity(bio->bi_disk))
goto io_error;
bio_for_each_segment(bvec, bio, iter) {
unsigned int len = bvec.bv_len;
int err;
err = brd_do_bvec(brd, bvec.bv_page, len, bvec.bv_offset,
bio_op(bio), sector);
if (err)
goto io_error;
sector += len >> SECTOR_SHIFT;
}
bio_endio(bio);
return BLK_QC_T_NONE;
io_error:
bio_io_error(bio);
return BLK_QC_T_NONE;
}
static int brd_rw_page(struct block_device *bdev, sector_t sector,
struct page *page, unsigned int op)
{
struct brd_device *brd = bdev->bd_disk->private_data;
int err;
if (PageTransHuge(page))
return -ENOTSUPP;
err = brd_do_bvec(brd, page, PAGE_SIZE, 0, op, sector);
page_endio(page, op_is_write(op), err);
return err;
}
static const struct block_device_operations brd_fops = {
.owner = THIS_MODULE,
.rw_page = brd_rw_page,
};
/*
* And now the modules code and kernel interface.
*/
static int rd_nr = CONFIG_BLK_DEV_RAM_COUNT;
module_param(rd_nr, int, 0444);
MODULE_PARM_DESC(rd_nr, "Maximum number of brd devices");
unsigned long rd_size = CONFIG_BLK_DEV_RAM_SIZE;
module_param(rd_size, ulong, 0444);
MODULE_PARM_DESC(rd_size, "Size of each RAM disk in kbytes.");
static int max_part = 1;
module_param(max_part, int, 0444);
MODULE_PARM_DESC(max_part, "Num Minors to reserve between devices");
MODULE_LICENSE("GPL");
// MODULE_ALIAS_BLOCKDEV_MAJOR(RAMDISK_MAJOR);
MODULE_ALIAS("cy_ramdisk");
#ifndef MODULE
/* Legacy boot options - nonmodular */
static int __init ramdisk_size(char *str)
{
rd_size = simple_strtol(str, NULL, 0);
return 1;
}
__setup("ramdisk_size=", ramdisk_size);
#endif
/*
* The device scheme is derived from loop.c. Keep them in synch where possible
* (should share code eventually).
*/
static LIST_HEAD(brd_devices);
static DEFINE_MUTEX(brd_devices_mutex);
static struct brd_device *brd_alloc(int i)
{
struct brd_device *brd;
struct gendisk *disk;
brd = kzalloc(sizeof(*brd), GFP_KERNEL);
if (!brd)
goto out;
brd->brd_number = i;
spin_lock_init(&brd->brd_lock);
INIT_RADIX_TREE(&brd->brd_pages, GFP_ATOMIC);
brd->brd_queue = blk_alloc_queue(GFP_KERNEL);
if (!brd->brd_queue)
goto out_free_dev;
blk_queue_make_request(brd->brd_queue, brd_make_request);
blk_queue_max_hw_sectors(brd->brd_queue, 1024);
/* This is so fdisk will align partitions on 4k, because of
* direct_access API needing 4k alignment, returning a PFN
* (This is only a problem on very small devices <= 4M,
* otherwise fdisk will align on 1M. Regardless this call
* is harmless)
*/
blk_queue_physical_block_size(brd->brd_queue, PAGE_SIZE);
disk = brd->brd_disk = alloc_disk(max_part);
if (!disk)
goto out_free_queue;
disk->major = ramdisk_major;
disk->first_minor = i * max_part;
disk->fops = &brd_fops;
disk->private_data = brd;
disk->flags = GENHD_FL_EXT_DEVT;
sprintf(disk->disk_name, "cy_ramdisk%d", i);
set_capacity(disk, rd_size * 2);
brd->brd_queue->backing_dev_info->capabilities |= BDI_CAP_SYNCHRONOUS_IO;
/* Tell the block layer that this is not a rotational device */
blk_queue_flag_set(QUEUE_FLAG_NONROT, brd->brd_queue);
blk_queue_flag_clear(QUEUE_FLAG_ADD_RANDOM, brd->brd_queue);
return brd;
out_free_queue:
blk_cleanup_queue(brd->brd_queue);
out_free_dev:
kfree(brd);
out:
return NULL;
}
static void brd_free(struct brd_device *brd)
{
put_disk(brd->brd_disk);
blk_cleanup_queue(brd->brd_queue);
brd_free_pages(brd);
kfree(brd);
}
static struct brd_device *brd_init_one(int i, bool *new)
{
struct brd_device *brd;
*new = false;
list_for_each_entry(brd, &brd_devices, brd_list) {
if (brd->brd_number == i)
goto out;
}
brd = brd_alloc(i);
if (brd) {
brd->brd_disk->queue = brd->brd_queue;
add_disk(brd->brd_disk);
list_add_tail(&brd->brd_list, &brd_devices);
}
*new = true;
out:
return brd;
}
static void brd_del_one(struct brd_device *brd)
{
list_del(&brd->brd_list);
del_gendisk(brd->brd_disk);
brd_free(brd);
}
static struct kobject *brd_probe(dev_t dev, int *part, void *data)
{
struct brd_device *brd;
struct kobject *kobj;
bool new;
mutex_lock(&brd_devices_mutex);
brd = brd_init_one(MINOR(dev) / max_part, &new);
kobj = brd ? get_disk_and_module(brd->brd_disk) : NULL;
mutex_unlock(&brd_devices_mutex);
if (new)
*part = 0;
return kobj;
}
static int __init brd_init(void)
{
struct brd_device *brd, *next;
int i;
/*
* brd module now has a feature to instantiate underlying device
* structure on-demand, provided that there is an access dev node.
*
* (1) if rd_nr is specified, create that many upfront. else
* it defaults to CONFIG_BLK_DEV_RAM_COUNT
* (2) User can further extend brd devices by create dev node themselves
* and have kernel automatically instantiate actual device
* on-demand. Example:
* mknod /path/devnod_name b 1 X # 1 is the rd major
* fdisk -l /path/devnod_name
* If (X / max_part) was not already created it will be created
* dynamically.
*/
ramdisk_major = register_blkdev(ramdisk_major, "cy_ramdisk");
if (ramdisk_major <= 0)
return -EIO;
if (unlikely(!max_part))
max_part = 1;
for (i = 0; i < rd_nr; i++) {
brd = brd_alloc(i);
if (!brd)
goto out_free;
list_add_tail(&brd->brd_list, &brd_devices);
}
/* point of no return */
list_for_each_entry(brd, &brd_devices, brd_list) {
/*
* associate with queue just before adding disk for
* avoiding to mess up failure path
*/
brd->brd_disk->queue = brd->brd_queue;
add_disk(brd->brd_disk);
}
blk_register_region(MKDEV(ramdisk_major, 0), 1UL << MINORBITS,
THIS_MODULE, brd_probe, NULL, NULL);
pr_info("cy_ramdisk: module loaded\n");
return 0;
out_free:
list_for_each_entry_safe(brd, next, &brd_devices, brd_list) {
list_del(&brd->brd_list);
brd_free(brd);
}
unregister_blkdev(ramdisk_major, "cy_ramdisk");
pr_info("cy_ramdisk: module NOT loaded !!!\n");
return -ENOMEM;
}
static void __exit brd_exit(void)
{
struct brd_device *brd, *next;
list_for_each_entry_safe(brd, next, &brd_devices, brd_list)
brd_del_one(brd);
blk_unregister_region(MKDEV(ramdisk_major, 0), 1UL << MINORBITS);
unregister_blkdev(ramdisk_major, "ramdisk");
pr_info("cy_ramdisk: module unloaded\n");
}
module_init(brd_init);
module_exit(brd_exit);
Null block device driver
================================================================================
I. Overview
The null block device (/dev/nullb*) is used for benchmarking the various
block-layer implementations. It emulates a block device of X gigabytes in size.
The following instances are possible:
Single-queue block-layer
- Request-based.
- Single submission queue per device.
- Implements IO scheduling algorithms (CFQ, Deadline, noop).
Multi-queue block-layer
- Request-based.
- Configurable submission queues per device.
No block-layer (Known as bio-based)
- Bio-based. IO requests are submitted directly to the device driver.
- Directly accepts bio data structure and returns them.
All of them have a completion queue for each core in the system.
II. Module parameters applicable for all instances:
queue_mode=[0-2]: Default: 2-Multi-queue
Selects which block-layer the module should instantiate with.
0: Bio-based.
1: Single-queue.
2: Multi-queue.
home_node=[0--nr_nodes]: Default: NUMA_NO_NODE
Selects what CPU node the data structures are allocated from.
gb=[Size in GB]: Default: 250GB
The size of the device reported to the system.
bs=[Block size (in bytes)]: Default: 512 bytes
The block size reported to the system.
nr_devices=[Number of devices]: Default: 1
Number of block devices instantiated. They are instantiated as /dev/nullb0,
etc.
irqmode=[0-2]: Default: 1-Soft-irq
The completion mode used for completing IOs to the block-layer.
0: None.
1: Soft-irq. Uses IPI to complete IOs across CPU nodes. Simulates the overhead
when IOs are issued from another CPU node than the home the device is
connected to.
2: Timer: Waits a specific period (completion_nsec) for each IO before
completion.
completion_nsec=[ns]: Default: 10,000ns
Combined with irqmode=2 (timer). The time each completion event must wait.
submit_queues=[1..nr_cpus]:
The number of submission queues attached to the device driver. If unset, it
defaults to 1. For multi-queue, it is ignored when use_per_node_hctx module
parameter is 1.
hw_queue_depth=[0..qdepth]: Default: 64
The hardware queue depth of the device.
III: Multi-queue specific parameters
use_per_node_hctx=[0/1]: Default: 0
0: The number of submit queues are set to the value of the submit_queues
parameter.
1: The multi-queue block layer is instantiated with a hardware dispatch
queue for each CPU node in the system.
no_sched=[0/1]: Default: 0
0: nullb* use default blk-mq io scheduler.
1: nullb* doesn't use io scheduler.
blocking=[0/1]: Default: 0
0: Register as a non-blocking blk-mq driver device.
1: Register as a blocking blk-mq driver device, null_blk will set
the BLK_MQ_F_BLOCKING flag, indicating that it sometimes/always
needs to block in its ->queue_rq() function.
shared_tags=[0/1]: Default: 0
0: Tag set is not shared.
1: Tag set shared between devices for blk-mq. Only makes sense with
nr_devices > 1, otherwise there's no tag set to share.
zoned=[0/1]: Default: 0
0: Block device is exposed as a random-access block device.
1: Block device is exposed as a host-managed zoned block device. Requires
CONFIG_BLK_DEV_ZONED.
zone_size=[MB]: Default: 256
Per zone size when exposed as a zoned block device. Must be a power of two.
zone_nr_conv=[nr_conv]: Default: 0
The number of conventional zones to create when block device is zoned. If
zone_nr_conv >= nr_zones, it will be reduced to nr_zones - 1./drivers/block/null_blk_main.c
/*
* Add configfs and memory store: Kyungchan Koh and
* Shaohua Li
*/
#include
#include
#include
#include
#include
#include "null_blk.h"
#define PAGE_SECTORS_SHIFT (PAGE_SHIFT - SECTOR_SHIFT)
#define PAGE_SECTORS (1 << PAGE_SECTORS_SHIFT)
#define SECTOR_MASK (PAGE_SECTORS - 1)
#define FREE_BATCH 16
#define TICKS_PER_SEC 50ULL
#define TIMER_INTERVAL (NSEC_PER_SEC / TICKS_PER_SEC)
#ifdef CONFIG_BLK_DEV_NULL_BLK_FAULT_INJECTION
static DECLARE_FAULT_ATTR(null_timeout_attr);
static DECLARE_FAULT_ATTR(null_requeue_attr);
#endif
static inline u64 mb_per_tick(int mbps)
{
return (1 << 20) / TICKS_PER_SEC * ((u64) mbps);
}
/*
* Status flags for nullb_device.
*
* CONFIGURED: Device has been configured and turned on. Cannot reconfigure.
* UP: Device is currently on and visible in userspace.
* THROTTLED: Device is being throttled.
* CACHE: Device is using a write-back cache.
*/
enum nullb_device_flags {
NULLB_DEV_FL_CONFIGURED = 0,
NULLB_DEV_FL_UP = 1,
NULLB_DEV_FL_THROTTLED = 2,
NULLB_DEV_FL_CACHE = 3,
};
#define MAP_SZ ((PAGE_SIZE >> SECTOR_SHIFT) + 2)
/*
* nullb_page is a page in memory for nullb devices.
*
* @page: The page holding the data.
* @bitmap: The bitmap represents which sector in the page has data.
* Each bit represents one block size. For example, sector 8
* will use the 7th bit
* The highest 2 bits of bitmap are for special purpose. LOCK means the cache
* page is being flushing to storage. FREE means the cache page is freed and
* should be skipped from flushing to storage. Please see
* null_make_cache_space
*/
struct nullb_page {
struct page *page;
DECLARE_BITMAP(bitmap, MAP_SZ);
};
#define NULLB_PAGE_LOCK (MAP_SZ - 1)
#define NULLB_PAGE_FREE (MAP_SZ - 2)
static LIST_HEAD(nullb_list);
static struct mutex lock;
static int null_major;
static DEFINE_IDA(nullb_indexes);
static struct blk_mq_tag_set tag_set;
enum {
NULL_IRQ_NONE = 0,
NULL_IRQ_SOFTIRQ = 1,
NULL_IRQ_TIMER = 2,
};
enum {
NULL_Q_BIO = 0,
NULL_Q_RQ = 1,
NULL_Q_MQ = 2,
};
static int g_no_sched;
module_param_named(no_sched, g_no_sched, int, 0444);
MODULE_PARM_DESC(no_sched, "No io scheduler");
static int g_submit_queues = 1;
module_param_named(submit_queues, g_submit_queues, int, 0444);
MODULE_PARM_DESC(submit_queues, "Number of submission queues");
static int g_home_node = NUMA_NO_NODE;
module_param_named(home_node, g_home_node, int, 0444);
MODULE_PARM_DESC(home_node, "Home node for the device");
#ifdef CONFIG_BLK_DEV_NULL_BLK_FAULT_INJECTION
static char g_timeout_str[80];
module_param_string(timeout, g_timeout_str, sizeof(g_timeout_str), 0444);
static char g_requeue_str[80];
module_param_string(requeue, g_requeue_str, sizeof(g_requeue_str), 0444);
#endif
static int g_queue_mode = NULL_Q_MQ;
static int null_param_store_val(const char *str, int *val, int min, int max)
{
int ret, new_val;
ret = kstrtoint(str, 10, &new_val);
if (ret)
return -EINVAL;
if (new_val < min || new_val > max)
return -EINVAL;
*val = new_val;
return 0;
}
static int null_set_queue_mode(const char *str, const struct kernel_param *kp)
{
return null_param_store_val(str, &g_queue_mode, NULL_Q_BIO, NULL_Q_MQ);
}
static const struct kernel_param_ops null_queue_mode_param_ops = {
.set = null_set_queue_mode,
.get = param_get_int,
};
device_param_cb(queue_mode, &null_queue_mode_param_ops, &g_queue_mode, 0444);
MODULE_PARM_DESC(queue_mode, "Block interface to use (0=bio,1=rq,2=multiqueue)");
static int g_gb = 250;
module_param_named(gb, g_gb, int, 0444);
MODULE_PARM_DESC(gb, "Size in GB");
static int g_bs = 512;
module_param_named(bs, g_bs, int, 0444);
MODULE_PARM_DESC(bs, "Block size (in bytes)");
static int nr_devices = 1;
module_param(nr_devices, int, 0444);
MODULE_PARM_DESC(nr_devices, "Number of devices to register");
static bool g_blocking;
module_param_named(blocking, g_blocking, bool, 0444);
MODULE_PARM_DESC(blocking, "Register as a blocking blk-mq driver device");
static bool shared_tags;
module_param(shared_tags, bool, 0444);
MODULE_PARM_DESC(shared_tags, "Share tag set between devices for blk-mq");
static int g_irqmode = NULL_IRQ_SOFTIRQ;
static int null_set_irqmode(const char *str, const struct kernel_param *kp)
{
return null_param_store_val(str, &g_irqmode, NULL_IRQ_NONE,
NULL_IRQ_TIMER);
}
static const struct kernel_param_ops null_irqmode_param_ops = {
.set = null_set_irqmode,
.get = param_get_int,
};
device_param_cb(irqmode, &null_irqmode_param_ops, &g_irqmode, 0444);
MODULE_PARM_DESC(irqmode, "IRQ completion handler. 0-none, 1-softirq, 2-timer");
static unsigned long g_completion_nsec = 10000;
module_param_named(completion_nsec, g_completion_nsec, ulong, 0444);
MODULE_PARM_DESC(completion_nsec, "Time in ns to complete a request in hardware. Default: 10,000ns");
static int g_hw_queue_depth = 64;
module_param_named(hw_queue_depth, g_hw_queue_depth, int, 0444);
MODULE_PARM_DESC(hw_queue_depth, "Queue depth for each hardware queue. Default: 64");
static bool g_use_per_node_hctx;
module_param_named(use_per_node_hctx, g_use_per_node_hctx, bool, 0444);
MODULE_PARM_DESC(use_per_node_hctx, "Use per-node allocation for hardware context queues. Default: false");
static bool g_zoned;
module_param_named(zoned, g_zoned, bool, S_IRUGO);
MODULE_PARM_DESC(zoned, "Make device as a host-managed zoned block device. Default: false");
static unsigned long g_zone_size = 256;
module_param_named(zone_size, g_zone_size, ulong, S_IRUGO);
MODULE_PARM_DESC(zone_size, "Zone size in MB when block device is zoned. Must be power-of-two: Default: 256");
static unsigned int g_zone_nr_conv;
module_param_named(zone_nr_conv, g_zone_nr_conv, uint, 0444);
MODULE_PARM_DESC(zone_nr_conv, "Number of conventional zones when block device is zoned. Default: 0");
static struct nullb_device *null_alloc_dev(void);
static void null_free_dev(struct nullb_device *dev);
static void null_del_dev(struct nullb *nullb);
static int null_add_dev(struct nullb_device *dev);
static void null_free_device_storage(struct nullb_device *dev, bool is_cache);
static inline struct nullb_device *to_nullb_device(struct config_item *item)
{
return item ? container_of(item, struct nullb_device, item) : NULL;
}
static inline ssize_t nullb_device_uint_attr_show(unsigned int val, char *page)
{
return snprintf(page, PAGE_SIZE, "%u\n", val);
}
static inline ssize_t nullb_device_ulong_attr_show(unsigned long val,
char *page)
{
return snprintf(page, PAGE_SIZE, "%lu\n", val);
}
static inline ssize_t nullb_device_bool_attr_show(bool val, char *page)
{
return snprintf(page, PAGE_SIZE, "%u\n", val);
}
static ssize_t nullb_device_uint_attr_store(unsigned int *val,
const char *page, size_t count)
{
unsigned int tmp;
int result;
result = kstrtouint(page, 0, &tmp);
if (result)
return result;
*val = tmp;
return count;
}
static ssize_t nullb_device_ulong_attr_store(unsigned long *val,
const char *page, size_t count)
{
int result;
unsigned long tmp;
result = kstrtoul(page, 0, &tmp);
if (result)
return result;
*val = tmp;
return count;
}
static ssize_t nullb_device_bool_attr_store(bool *val, const char *page,
size_t count)
{
bool tmp;
int result;
result = kstrtobool(page, &tmp);
if (result)
return result;
*val = tmp;
return count;
}
/* The following macro should only be used with TYPE = {uint, ulong, bool}. */
#define NULLB_DEVICE_ATTR(NAME, TYPE) \
static ssize_t \
nullb_device_##NAME##_show(struct config_item *item, char *page) \
{ \
return nullb_device_##TYPE##_attr_show( \
to_nullb_device(item)->NAME, page); \
} \
static ssize_t \
nullb_device_##NAME##_store(struct config_item *item, const char *page, \
size_t count) \
{ \
if (test_bit(NULLB_DEV_FL_CONFIGURED, &to_nullb_device(item)->flags)) \
return -EBUSY; \
return nullb_device_##TYPE##_attr_store( \
&to_nullb_device(item)->NAME, page, count); \
} \
CONFIGFS_ATTR(nullb_device_, NAME);
NULLB_DEVICE_ATTR(size, ulong);
NULLB_DEVICE_ATTR(completion_nsec, ulong);
NULLB_DEVICE_ATTR(submit_queues, uint);
NULLB_DEVICE_ATTR(home_node, uint);
NULLB_DEVICE_ATTR(queue_mode, uint);
NULLB_DEVICE_ATTR(blocksize, uint);
NULLB_DEVICE_ATTR(irqmode, uint);
NULLB_DEVICE_ATTR(hw_queue_depth, uint);
NULLB_DEVICE_ATTR(index, uint);
NULLB_DEVICE_ATTR(blocking, bool);
NULLB_DEVICE_ATTR(use_per_node_hctx, bool);
NULLB_DEVICE_ATTR(memory_backed, bool);
NULLB_DEVICE_ATTR(discard, bool);
NULLB_DEVICE_ATTR(mbps, uint);
NULLB_DEVICE_ATTR(cache_size, ulong);
NULLB_DEVICE_ATTR(zoned, bool);
NULLB_DEVICE_ATTR(zone_size, ulong);
NULLB_DEVICE_ATTR(zone_nr_conv, uint);
static ssize_t nullb_device_power_show(struct config_item *item, char *page)
{
return nullb_device_bool_attr_show(to_nullb_device(item)->power, page);
}
static ssize_t nullb_device_power_store(struct config_item *item,
const char *page, size_t count)
{
struct nullb_device *dev = to_nullb_device(item);
bool newp = false;
ssize_t ret;
ret = nullb_device_bool_attr_store(&newp, page, count);
if (ret < 0)
return ret;
if (!dev->power && newp) {
if (test_and_set_bit(NULLB_DEV_FL_UP, &dev->flags))
return count;
if (null_add_dev(dev)) {
clear_bit(NULLB_DEV_FL_UP, &dev->flags);
return -ENOMEM;
}
set_bit(NULLB_DEV_FL_CONFIGURED, &dev->flags);
dev->power = newp;
} else if (dev->power && !newp) {
mutex_lock(&lock);
dev->power = newp;
null_del_dev(dev->nullb);
mutex_unlock(&lock);
clear_bit(NULLB_DEV_FL_UP, &dev->flags);
clear_bit(NULLB_DEV_FL_CONFIGURED, &dev->flags);
}
return count;
}
CONFIGFS_ATTR(nullb_device_, power);
static ssize_t nullb_device_badblocks_show(struct config_item *item, char *page)
{
struct nullb_device *t_dev = to_nullb_device(item);
return badblocks_show(&t_dev->badblocks, page, 0);
}
static ssize_t nullb_device_badblocks_store(struct config_item *item,
const char *page, size_t count)
{
struct nullb_device *t_dev = to_nullb_device(item);
char *orig, *buf, *tmp;
u64 start, end;
int ret;
orig = kstrndup(page, count, GFP_KERNEL);
if (!orig)
return -ENOMEM;
buf = strstrip(orig);
ret = -EINVAL;
if (buf[0] != '+' && buf[0] != '-')
goto out;
tmp = strchr(&buf[1], '-');
if (!tmp)
goto out;
*tmp = '\0';
ret = kstrtoull(buf + 1, 0, &start);
if (ret)
goto out;
ret = kstrtoull(tmp + 1, 0, &end);
if (ret)
goto out;
ret = -EINVAL;
if (start > end)
goto out;
/* enable badblocks */
cmpxchg(&t_dev->badblocks.shift, -1, 0);
if (buf[0] == '+')
ret = badblocks_set(&t_dev->badblocks, start,
end - start + 1, 1);
else
ret = badblocks_clear(&t_dev->badblocks, start,
end - start + 1);
if (ret == 0)
ret = count;
out:
kfree(orig);
return ret;
}
CONFIGFS_ATTR(nullb_device_, badblocks);
static struct configfs_attribute *nullb_device_attrs[] = {
&nullb_device_attr_size,
&nullb_device_attr_completion_nsec,
&nullb_device_attr_submit_queues,
&nullb_device_attr_home_node,
&nullb_device_attr_queue_mode,
&nullb_device_attr_blocksize,
&nullb_device_attr_irqmode,
&nullb_device_attr_hw_queue_depth,
&nullb_device_attr_index,
&nullb_device_attr_blocking,
&nullb_device_attr_use_per_node_hctx,
&nullb_device_attr_power,
&nullb_device_attr_memory_backed,
&nullb_device_attr_discard,
&nullb_device_attr_mbps,
&nullb_device_attr_cache_size,
&nullb_device_attr_badblocks,
&nullb_device_attr_zoned,
&nullb_device_attr_zone_size,
&nullb_device_attr_zone_nr_conv,
NULL,
};
static void nullb_device_release(struct config_item *item)
{
struct nullb_device *dev = to_nullb_device(item);
null_free_device_storage(dev, false);
null_free_dev(dev);
}
static struct configfs_item_operations nullb_device_ops = {
.release = nullb_device_release,
};
static const struct config_item_type nullb_device_type = {
.ct_item_ops = &nullb_device_ops,
.ct_attrs = nullb_device_attrs,
.ct_owner = THIS_MODULE,
};
static struct
config_item *nullb_group_make_item(struct config_group *group, const char *name)
{
struct nullb_device *dev;
dev = null_alloc_dev();
if (!dev)
return ERR_PTR(-ENOMEM);
config_item_init_type_name(&dev->item, name, &nullb_device_type);
return &dev->item;
}
static void
nullb_group_drop_item(struct config_group *group, struct config_item *item)
{
struct nullb_device *dev = to_nullb_device(item);
if (test_and_clear_bit(NULLB_DEV_FL_UP, &dev->flags)) {
mutex_lock(&lock);
dev->power = false;
null_del_dev(dev->nullb);
mutex_unlock(&lock);
}
config_item_put(item);
}
static ssize_t memb_group_features_show(struct config_item *item, char *page)
{
return snprintf(page, PAGE_SIZE, "memory_backed,discard,bandwidth,cache,badblocks,zoned,zone_size\n");
}
CONFIGFS_ATTR_RO(memb_group_, features);
static struct configfs_attribute *nullb_group_attrs[] = {
&memb_group_attr_features,
NULL,
};
static struct configfs_group_operations nullb_group_ops = {
.make_item = nullb_group_make_item,
.drop_item = nullb_group_drop_item,
};
static const struct config_item_type nullb_group_type = {
.ct_group_ops = &nullb_group_ops,
.ct_attrs = nullb_group_attrs,
.ct_owner = THIS_MODULE,
};
static struct configfs_subsystem nullb_subsys = {
.su_group = {
.cg_item = {
.ci_namebuf = "nullb",
.ci_type = &nullb_group_type,
},
},
};
static inline int null_cache_active(struct nullb *nullb)
{
return test_bit(NULLB_DEV_FL_CACHE, &nullb->dev->flags);
}
static struct nullb_device *null_alloc_dev(void)
{
struct nullb_device *dev;
dev = kzalloc(sizeof(*dev), GFP_KERNEL);
if (!dev)
return NULL;
INIT_RADIX_TREE(&dev->data, GFP_ATOMIC);
INIT_RADIX_TREE(&dev->cache, GFP_ATOMIC);
if (badblocks_init(&dev->badblocks, 0)) {
kfree(dev);
return NULL;
}
dev->size = g_gb * 1024;
dev->completion_nsec = g_completion_nsec;
dev->submit_queues = g_submit_queues;
dev->home_node = g_home_node;
dev->queue_mode = g_queue_mode;
dev->blocksize = g_bs;
dev->irqmode = g_irqmode;
dev->hw_queue_depth = g_hw_queue_depth;
dev->blocking = g_blocking;
dev->use_per_node_hctx = g_use_per_node_hctx;
dev->zoned = g_zoned;
dev->zone_size = g_zone_size;
dev->zone_nr_conv = g_zone_nr_conv;
return dev;
}
static void null_free_dev(struct nullb_device *dev)
{
if (!dev)
return;
null_zone_exit(dev);
badblocks_exit(&dev->badblocks);
kfree(dev);
}
static void put_tag(struct nullb_queue *nq, unsigned int tag)
{
clear_bit_unlock(tag, nq->tag_map);
if (waitqueue_active(&nq->wait))
wake_up(&nq->wait);
}
static unsigned int get_tag(struct nullb_queue *nq)
{
unsigned int tag;
do {
tag = find_first_zero_bit(nq->tag_map, nq->queue_depth);
if (tag >= nq->queue_depth)
return -1U;
} while (test_and_set_bit_lock(tag, nq->tag_map));
return tag;
}
static void free_cmd(struct nullb_cmd *cmd)
{
put_tag(cmd->nq, cmd->tag);
}
static enum hrtimer_restart null_cmd_timer_expired(struct hrtimer *timer);
static struct nullb_cmd *__alloc_cmd(struct nullb_queue *nq)
{
struct nullb_cmd *cmd;
unsigned int tag;
tag = get_tag(nq);
if (tag != -1U) {
cmd = &nq->cmds[tag];
cmd->tag = tag;
cmd->nq = nq;
if (nq->dev->irqmode == NULL_IRQ_TIMER) {
hrtimer_init(&cmd->timer, CLOCK_MONOTONIC,
HRTIMER_MODE_REL);
cmd->timer.function = null_cmd_timer_expired;
}
return cmd;
}
return NULL;
}
static struct nullb_cmd *alloc_cmd(struct nullb_queue *nq, int can_wait)
{
struct nullb_cmd *cmd;
DEFINE_WAIT(wait);
cmd = __alloc_cmd(nq);
if (cmd || !can_wait)
return cmd;
do {
prepare_to_wait(&nq->wait, &wait, TASK_UNINTERRUPTIBLE);
cmd = __alloc_cmd(nq);
if (cmd)
break;
io_schedule();
} while (1);
finish_wait(&nq->wait, &wait);
return cmd;
}
static void end_cmd(struct nullb_cmd *cmd)
{
int queue_mode = cmd->nq->dev->queue_mode;
switch (queue_mode) {
case NULL_Q_MQ:
blk_mq_end_request(cmd->rq, cmd->error);
return;
case NULL_Q_BIO:
cmd->bio->bi_status = cmd->error;
bio_endio(cmd->bio);
break;
}
free_cmd(cmd);
}
static enum hrtimer_restart null_cmd_timer_expired(struct hrtimer *timer)
{
end_cmd(container_of(timer, struct nullb_cmd, timer));
return HRTIMER_NORESTART;
}
static void null_cmd_end_timer(struct nullb_cmd *cmd)
{
ktime_t kt = cmd->nq->dev->completion_nsec;
hrtimer_start(&cmd->timer, kt, HRTIMER_MODE_REL);
}
static void null_complete_rq(struct request *rq)
{
end_cmd(blk_mq_rq_to_pdu(rq));
}
static struct nullb_page *null_alloc_page(gfp_t gfp_flags)
{
struct nullb_page *t_page;
t_page = kmalloc(sizeof(struct nullb_page), gfp_flags);
if (!t_page)
goto out;
t_page->page = alloc_pages(gfp_flags, 0);
if (!t_page->page)
goto out_freepage;
memset(t_page->bitmap, 0, sizeof(t_page->bitmap));
return t_page;
out_freepage:
kfree(t_page);
out:
return NULL;
}
static void null_free_page(struct nullb_page *t_page)
{
__set_bit(NULLB_PAGE_FREE, t_page->bitmap);
if (test_bit(NULLB_PAGE_LOCK, t_page->bitmap))
return;
__free_page(t_page->page);
kfree(t_page);
}
static bool null_page_empty(struct nullb_page *page)
{
int size = MAP_SZ - 2;
return find_first_bit(page->bitmap, size) == size;
}
static void null_free_sector(struct nullb *nullb, sector_t sector,
bool is_cache)
{
unsigned int sector_bit;
u64 idx;
struct nullb_page *t_page, *ret;
struct radix_tree_root *root;
root = is_cache ? &nullb->dev->cache : &nullb->dev->data;
idx = sector >> PAGE_SECTORS_SHIFT;
sector_bit = (sector & SECTOR_MASK);
t_page = radix_tree_lookup(root, idx);
if (t_page) {
__clear_bit(sector_bit, t_page->bitmap);
if (null_page_empty(t_page)) {
ret = radix_tree_delete_item(root, idx, t_page);
WARN_ON(ret != t_page);
null_free_page(ret);
if (is_cache)
nullb->dev->curr_cache -= PAGE_SIZE;
}
}
}
static struct nullb_page *null_radix_tree_insert(struct nullb *nullb, u64 idx,
struct nullb_page *t_page, bool is_cache)
{
struct radix_tree_root *root;
root = is_cache ? &nullb->dev->cache : &nullb->dev->data;
if (radix_tree_insert(root, idx, t_page)) {
null_free_page(t_page);
t_page = radix_tree_lookup(root, idx);
WARN_ON(!t_page || t_page->page->index != idx);
} else if (is_cache)
nullb->dev->curr_cache += PAGE_SIZE;
return t_page;
}
static void null_free_device_storage(struct nullb_device *dev, bool is_cache)
{
unsigned long pos = 0;
int nr_pages;
struct nullb_page *ret, *t_pages[FREE_BATCH];
struct radix_tree_root *root;
root = is_cache ? &dev->cache : &dev->data;
do {
int i;
nr_pages = radix_tree_gang_lookup(root,
(void **)t_pages, pos, FREE_BATCH);
for (i = 0; i < nr_pages; i++) {
pos = t_pages[i]->page->index;
ret = radix_tree_delete_item(root, pos, t_pages[i]);
WARN_ON(ret != t_pages[i]);
null_free_page(ret);
}
pos++;
} while (nr_pages == FREE_BATCH);
if (is_cache)
dev->curr_cache = 0;
}
static struct nullb_page *__null_lookup_page(struct nullb *nullb,
sector_t sector, bool for_write, bool is_cache)
{
unsigned int sector_bit;
u64 idx;
struct nullb_page *t_page;
struct radix_tree_root *root;
idx = sector >> PAGE_SECTORS_SHIFT;
sector_bit = (sector & SECTOR_MASK);
root = is_cache ? &nullb->dev->cache : &nullb->dev->data;
t_page = radix_tree_lookup(root, idx);
WARN_ON(t_page && t_page->page->index != idx);
if (t_page && (for_write || test_bit(sector_bit, t_page->bitmap)))
return t_page;
return NULL;
}
static struct nullb_page *null_lookup_page(struct nullb *nullb,
sector_t sector, bool for_write, bool ignore_cache)
{
struct nullb_page *page = NULL;
if (!ignore_cache)
page = __null_lookup_page(nullb, sector, for_write, true);
if (page)
return page;
return __null_lookup_page(nullb, sector, for_write, false);
}
static struct nullb_page *null_insert_page(struct nullb *nullb,
sector_t sector, bool ignore_cache)
__releases(&nullb->lock)
__acquires(&nullb->lock)
{
u64 idx;
struct nullb_page *t_page;
t_page = null_lookup_page(nullb, sector, true, ignore_cache);
if (t_page)
return t_page;
spin_unlock_irq(&nullb->lock);
t_page = null_alloc_page(GFP_NOIO);
if (!t_page)
goto out_lock;
if (radix_tree_preload(GFP_NOIO))
goto out_freepage;
spin_lock_irq(&nullb->lock);
idx = sector >> PAGE_SECTORS_SHIFT;
t_page->page->index = idx;
t_page = null_radix_tree_insert(nullb, idx, t_page, !ignore_cache);
radix_tree_preload_end();
return t_page;
out_freepage:
null_free_page(t_page);
out_lock:
spin_lock_irq(&nullb->lock);
return null_lookup_page(nullb, sector, true, ignore_cache);
}
static int null_flush_cache_page(struct nullb *nullb, struct nullb_page *c_page)
{
int i;
unsigned int offset;
u64 idx;
struct nullb_page *t_page, *ret;
void *dst, *src;
idx = c_page->page->index;
t_page = null_insert_page(nullb, idx << PAGE_SECTORS_SHIFT, true);
__clear_bit(NULLB_PAGE_LOCK, c_page->bitmap);
if (test_bit(NULLB_PAGE_FREE, c_page->bitmap)) {
null_free_page(c_page);
if (t_page && null_page_empty(t_page)) {
ret = radix_tree_delete_item(&nullb->dev->data,
idx, t_page);
null_free_page(t_page);
}
return 0;
}
if (!t_page)
return -ENOMEM;
src = kmap_atomic(c_page->page);
dst = kmap_atomic(t_page->page);
for (i = 0; i < PAGE_SECTORS;
i += (nullb->dev->blocksize >> SECTOR_SHIFT)) {
if (test_bit(i, c_page->bitmap)) {
offset = (i << SECTOR_SHIFT);
memcpy(dst + offset, src + offset,
nullb->dev->blocksize);
__set_bit(i, t_page->bitmap);
}
}
kunmap_atomic(dst);
kunmap_atomic(src);
ret = radix_tree_delete_item(&nullb->dev->cache, idx, c_page);
null_free_page(ret);
nullb->dev->curr_cache -= PAGE_SIZE;
return 0;
}
static int null_make_cache_space(struct nullb *nullb, unsigned long n)
{
int i, err, nr_pages;
struct nullb_page *c_pages[FREE_BATCH];
unsigned long flushed = 0, one_round;
again:
if ((nullb->dev->cache_size * 1024 * 1024) >
nullb->dev->curr_cache + n || nullb->dev->curr_cache == 0)
return 0;
nr_pages = radix_tree_gang_lookup(&nullb->dev->cache,
(void **)c_pages, nullb->cache_flush_pos, FREE_BATCH);
/*
* nullb_flush_cache_page could unlock before using the c_pages. To
* avoid race, we don't allow page free
*/
for (i = 0; i < nr_pages; i++) {
nullb->cache_flush_pos = c_pages[i]->page->index;
/*
* We found the page which is being flushed to disk by other
* threads
*/
if (test_bit(NULLB_PAGE_LOCK, c_pages[i]->bitmap))
c_pages[i] = NULL;
else
__set_bit(NULLB_PAGE_LOCK, c_pages[i]->bitmap);
}
one_round = 0;
for (i = 0; i < nr_pages; i++) {
if (c_pages[i] == NULL)
continue;
err = null_flush_cache_page(nullb, c_pages[i]);
if (err)
return err;
one_round++;
}
flushed += one_round << PAGE_SHIFT;
if (n > flushed) {
if (nr_pages == 0)
nullb->cache_flush_pos = 0;
if (one_round == 0) {
/* give other threads a chance */
spin_unlock_irq(&nullb->lock);
spin_lock_irq(&nullb->lock);
}
goto again;
}
return 0;
}
static int copy_to_nullb(struct nullb *nullb, struct page *source,
unsigned int off, sector_t sector, size_t n, bool is_fua)
{
size_t temp, count = 0;
unsigned int offset;
struct nullb_page *t_page;
void *dst, *src;
while (count < n) {
temp = min_t(size_t, nullb->dev->blocksize, n - count);
if (null_cache_active(nullb) && !is_fua)
null_make_cache_space(nullb, PAGE_SIZE);
offset = (sector & SECTOR_MASK) << SECTOR_SHIFT;
t_page = null_insert_page(nullb, sector,
!null_cache_active(nullb) || is_fua);
if (!t_page)
return -ENOSPC;
src = kmap_atomic(source);
dst = kmap_atomic(t_page->page);
memcpy(dst + offset, src + off + count, temp);
kunmap_atomic(dst);
kunmap_atomic(src);
__set_bit(sector & SECTOR_MASK, t_page->bitmap);
if (is_fua)
null_free_sector(nullb, sector, true);
count += temp;
sector += temp >> SECTOR_SHIFT;
}
return 0;
}
static int copy_from_nullb(struct nullb *nullb, struct page *dest,
unsigned int off, sector_t sector, size_t n)
{
size_t temp, count = 0;
unsigned int offset;
struct nullb_page *t_page;
void *dst, *src;
while (count < n) {
temp = min_t(size_t, nullb->dev->blocksize, n - count);
offset = (sector & SECTOR_MASK) << SECTOR_SHIFT;
t_page = null_lookup_page(nullb, sector, false,
!null_cache_active(nullb));
dst = kmap_atomic(dest);
if (!t_page) {
memset(dst + off + count, 0, temp);
goto next;
}
src = kmap_atomic(t_page->page);
memcpy(dst + off + count, src + offset, temp);
kunmap_atomic(src);
next:
kunmap_atomic(dst);
count += temp;
sector += temp >> SECTOR_SHIFT;
}
return 0;
}
static void null_handle_discard(struct nullb *nullb, sector_t sector, size_t n)
{
size_t temp;
spin_lock_irq(&nullb->lock);
while (n > 0) {
temp = min_t(size_t, n, nullb->dev->blocksize);
null_free_sector(nullb, sector, false);
if (null_cache_active(nullb))
null_free_sector(nullb, sector, true);
sector += temp >> SECTOR_SHIFT;
n -= temp;
}
spin_unlock_irq(&nullb->lock);
}
static int null_handle_flush(struct nullb *nullb)
{
int err;
if (!null_cache_active(nullb))
return 0;
spin_lock_irq(&nullb->lock);
while (true) {
err = null_make_cache_space(nullb,
nullb->dev->cache_size * 1024 * 1024);
if (err || nullb->dev->curr_cache == 0)
break;
}
WARN_ON(!radix_tree_empty(&nullb->dev->cache));
spin_unlock_irq(&nullb->lock);
return err;
}
static int null_transfer(struct nullb *nullb, struct page *page,
unsigned int len, unsigned int off, bool is_write, sector_t sector,
bool is_fua)
{
int err = 0;
if (!is_write) {
err = copy_from_nullb(nullb, page, off, sector, len);
flush_dcache_page(page);
} else {
flush_dcache_page(page);
err = copy_to_nullb(nullb, page, off, sector, len, is_fua);
}
return err;
}
static int null_handle_rq(struct nullb_cmd *cmd)
{
struct request *rq = cmd->rq;
struct nullb *nullb = cmd->nq->dev->nullb;
int err;
unsigned int len;
sector_t sector;
struct req_iterator iter;
struct bio_vec bvec;
sector = blk_rq_pos(rq);
if (req_op(rq) == REQ_OP_DISCARD) {
null_handle_discard(nullb, sector, blk_rq_bytes(rq));
return 0;
}
spin_lock_irq(&nullb->lock);
rq_for_each_segment(bvec, rq, iter) {
len = bvec.bv_len;
err = null_transfer(nullb, bvec.bv_page, len, bvec.bv_offset,
op_is_write(req_op(rq)), sector,
req_op(rq) & REQ_FUA);
if (err) {
spin_unlock_irq(&nullb->lock);
return err;
}
sector += len >> SECTOR_SHIFT;
}
spin_unlock_irq(&nullb->lock);
return 0;
}
static int null_handle_bio(struct nullb_cmd *cmd)
{
struct bio *bio = cmd->bio;
struct nullb *nullb = cmd->nq->dev->nullb;
int err;
unsigned int len;
sector_t sector;
struct bio_vec bvec;
struct bvec_iter iter;
sector = bio->bi_iter.bi_sector;
if (bio_op(bio) == REQ_OP_DISCARD) {
null_handle_discard(nullb, sector,
bio_sectors(bio) << SECTOR_SHIFT);
return 0;
}
spin_lock_irq(&nullb->lock);
bio_for_each_segment(bvec, bio, iter) {
len = bvec.bv_len;
err = null_transfer(nullb, bvec.bv_page, len, bvec.bv_offset,
op_is_write(bio_op(bio)), sector,
bio->bi_opf & REQ_FUA);
if (err) {
spin_unlock_irq(&nullb->lock);
return err;
}
sector += len >> SECTOR_SHIFT;
}
spin_unlock_irq(&nullb->lock);
return 0;
}
static void null_stop_queue(struct nullb *nullb)
{
struct request_queue *q = nullb->q;
if (nullb->dev->queue_mode == NULL_Q_MQ)
blk_mq_stop_hw_queues(q);
}
static void null_restart_queue_async(struct nullb *nullb)
{
struct request_queue *q = nullb->q;
if (nullb->dev->queue_mode == NULL_Q_MQ)
blk_mq_start_stopped_hw_queues(q, true);
}
static blk_status_t null_handle_cmd(struct nullb_cmd *cmd)
{
struct nullb_device *dev = cmd->nq->dev;
struct nullb *nullb = dev->nullb;
int err = 0;
if (test_bit(NULLB_DEV_FL_THROTTLED, &dev->flags)) {
struct request *rq = cmd->rq;
if (!hrtimer_active(&nullb->bw_timer))
hrtimer_restart(&nullb->bw_timer);
if (atomic_long_sub_return(blk_rq_bytes(rq),
&nullb->cur_bytes) < 0) {
null_stop_queue(nullb);
/* race with timer */
if (atomic_long_read(&nullb->cur_bytes) > 0)
null_restart_queue_async(nullb);
/* requeue request */
return BLK_STS_DEV_RESOURCE;
}
}
if (nullb->dev->badblocks.shift != -1) {
int bad_sectors;
sector_t sector, size, first_bad;
bool is_flush = true;
if (dev->queue_mode == NULL_Q_BIO &&
bio_op(cmd->bio) != REQ_OP_FLUSH) {
is_flush = false;
sector = cmd->bio->bi_iter.bi_sector;
size = bio_sectors(cmd->bio);
}
if (dev->queue_mode != NULL_Q_BIO &&
req_op(cmd->rq) != REQ_OP_FLUSH) {
is_flush = false;
sector = blk_rq_pos(cmd->rq);
size = blk_rq_sectors(cmd->rq);
}
if (!is_flush && badblocks_check(&nullb->dev->badblocks, sector,
size, &first_bad, &bad_sectors)) {
cmd->error = BLK_STS_IOERR;
goto out;
}
}
if (dev->memory_backed) {
if (dev->queue_mode == NULL_Q_BIO) {
if (bio_op(cmd->bio) == REQ_OP_FLUSH)
err = null_handle_flush(nullb);
else
err = null_handle_bio(cmd);
} else {
if (req_op(cmd->rq) == REQ_OP_FLUSH)
err = null_handle_flush(nullb);
else
err = null_handle_rq(cmd);
}
}
cmd->error = errno_to_blk_status(err);
if (!cmd->error && dev->zoned) {
sector_t sector;
unsigned int nr_sectors;
int op;
if (dev->queue_mode == NULL_Q_BIO) {
op = bio_op(cmd->bio);
sector = cmd->bio->bi_iter.bi_sector;
nr_sectors = cmd->bio->bi_iter.bi_size >> 9;
} else {
op = req_op(cmd->rq);
sector = blk_rq_pos(cmd->rq);
nr_sectors = blk_rq_sectors(cmd->rq);
}
if (op == REQ_OP_WRITE)
null_zone_write(cmd, sector, nr_sectors);
else if (op == REQ_OP_ZONE_RESET)
null_zone_reset(cmd, sector);
}
out:
/* Complete IO by inline, softirq or timer */
switch (dev->irqmode) {
case NULL_IRQ_SOFTIRQ:
switch (dev->queue_mode) {
case NULL_Q_MQ:
blk_mq_complete_request(cmd->rq);
break;
case NULL_Q_BIO:
/*
* XXX: no proper submitting cpu information available.
*/
end_cmd(cmd);
break;
}
break;
case NULL_IRQ_NONE:
end_cmd(cmd);
break;
case NULL_IRQ_TIMER:
null_cmd_end_timer(cmd);
break;
}
return BLK_STS_OK;
}
static enum hrtimer_restart nullb_bwtimer_fn(struct hrtimer *timer)
{
struct nullb *nullb = container_of(timer, struct nullb, bw_timer);
ktime_t timer_interval = ktime_set(0, TIMER_INTERVAL);
unsigned int mbps = nullb->dev->mbps;
if (atomic_long_read(&nullb->cur_bytes) == mb_per_tick(mbps))
return HRTIMER_NORESTART;
atomic_long_set(&nullb->cur_bytes, mb_per_tick(mbps));
null_restart_queue_async(nullb);
hrtimer_forward_now(&nullb->bw_timer, timer_interval);
return HRTIMER_RESTART;
}
static void nullb_setup_bwtimer(struct nullb *nullb)
{
ktime_t timer_interval = ktime_set(0, TIMER_INTERVAL);
hrtimer_init(&nullb->bw_timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL);
nullb->bw_timer.function = nullb_bwtimer_fn;
atomic_long_set(&nullb->cur_bytes, mb_per_tick(nullb->dev->mbps));
hrtimer_start(&nullb->bw_timer, timer_interval, HRTIMER_MODE_REL);
}
static struct nullb_queue *nullb_to_queue(struct nullb *nullb)
{
int index = 0;
if (nullb->nr_queues != 1)
index = raw_smp_processor_id() / ((nr_cpu_ids + nullb->nr_queues - 1) / nullb->nr_queues);
return &nullb->queues[index];
}
static blk_qc_t null_queue_bio(struct request_queue *q, struct bio *bio)
{
struct nullb *nullb = q->queuedata;
struct nullb_queue *nq = nullb_to_queue(nullb);
struct nullb_cmd *cmd;
cmd = alloc_cmd(nq, 1);
cmd->bio = bio;
null_handle_cmd(cmd);
return BLK_QC_T_NONE;
}
static bool should_timeout_request(struct request *rq)
{
#ifdef CONFIG_BLK_DEV_NULL_BLK_FAULT_INJECTION
if (g_timeout_str[0])
return should_fail(&null_timeout_attr, 1);
#endif
return false;
}
static bool should_requeue_request(struct request *rq)
{
#ifdef CONFIG_BLK_DEV_NULL_BLK_FAULT_INJECTION
if (g_requeue_str[0])
return should_fail(&null_requeue_attr, 1);
#endif
return false;
}
static enum blk_eh_timer_return null_timeout_rq(struct request *rq, bool res)
{
pr_info("null: rq %p timed out\n", rq);
blk_mq_complete_request(rq);
return BLK_EH_DONE;
}
static blk_status_t null_queue_rq(struct blk_mq_hw_ctx *hctx,
const struct blk_mq_queue_data *bd)
{
struct nullb_cmd *cmd = blk_mq_rq_to_pdu(bd->rq);
struct nullb_queue *nq = hctx->driver_data;
might_sleep_if(hctx->flags & BLK_MQ_F_BLOCKING);
if (nq->dev->irqmode == NULL_IRQ_TIMER) {
hrtimer_init(&cmd->timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL);
cmd->timer.function = null_cmd_timer_expired;
}
cmd->rq = bd->rq;
cmd->nq = nq;
blk_mq_start_request(bd->rq);
if (should_requeue_request(bd->rq)) {
/*
* Alternate between hitting the core BUSY path, and the
* driver driven requeue path
*/
nq->requeue_selection++;
if (nq->requeue_selection & 1)
return BLK_STS_RESOURCE;
else {
blk_mq_requeue_request(bd->rq, true);
return BLK_STS_OK;
}
}
if (should_timeout_request(bd->rq))
return BLK_STS_OK;
return null_handle_cmd(cmd);
}
static const struct blk_mq_ops null_mq_ops = {
.queue_rq = null_queue_rq,
.complete = null_complete_rq,
.timeout = null_timeout_rq,
};
static void cleanup_queue(struct nullb_queue *nq)
{
kfree(nq->tag_map);
kfree(nq->cmds);
}
static void cleanup_queues(struct nullb *nullb)
{
int i;
for (i = 0; i < nullb->nr_queues; i++)
cleanup_queue(&nullb->queues[i]);
kfree(nullb->queues);
}
static void null_del_dev(struct nullb *nullb)
{
struct nullb_device *dev = nullb->dev;
ida_simple_remove(&nullb_indexes, nullb->index);
list_del_init(&nullb->list);
del_gendisk(nullb->disk);
if (test_bit(NULLB_DEV_FL_THROTTLED, &nullb->dev->flags)) {
hrtimer_cancel(&nullb->bw_timer);
atomic_long_set(&nullb->cur_bytes, LONG_MAX);
null_restart_queue_async(nullb);
}
blk_cleanup_queue(nullb->q);
if (dev->queue_mode == NULL_Q_MQ &&
nullb->tag_set == &nullb->__tag_set)
blk_mq_free_tag_set(nullb->tag_set);
put_disk(nullb->disk);
cleanup_queues(nullb);
if (null_cache_active(nullb))
null_free_device_storage(nullb->dev, true);
kfree(nullb);
dev->nullb = NULL;
}
static void null_config_discard(struct nullb *nullb)
{
if (nullb->dev->discard == false)
return;
nullb->q->limits.discard_granularity = nullb->dev->blocksize;
nullb->q->limits.discard_alignment = nullb->dev->blocksize;
blk_queue_max_discard_sectors(nullb->q, UINT_MAX >> 9);
blk_queue_flag_set(QUEUE_FLAG_DISCARD, nullb->q);
}
static int null_open(struct block_device *bdev, fmode_t mode)
{
return 0;
}
static void null_release(struct gendisk *disk, fmode_t mode)
{
}
static const struct block_device_operations null_fops = {
.owner = THIS_MODULE,
.open = null_open,
.release = null_release,
.report_zones = null_zone_report,
};
static void null_init_queue(struct nullb *nullb, struct nullb_queue *nq)
{
BUG_ON(!nullb);
BUG_ON(!nq);
init_waitqueue_head(&nq->wait);
nq->queue_depth = nullb->queue_depth;
nq->dev = nullb->dev;
}
static void null_init_queues(struct nullb *nullb)
{
struct request_queue *q = nullb->q;
struct blk_mq_hw_ctx *hctx;
struct nullb_queue *nq;
int i;
queue_for_each_hw_ctx(q, hctx, i) {
if (!hctx->nr_ctx || !hctx->tags)
continue;
nq = &nullb->queues[i];
hctx->driver_data = nq;
null_init_queue(nullb, nq);
nullb->nr_queues++;
}
}
static int setup_commands(struct nullb_queue *nq)
{
struct nullb_cmd *cmd;
int i, tag_size;
nq->cmds = kcalloc(nq->queue_depth, sizeof(*cmd), GFP_KERNEL);
if (!nq->cmds)
return -ENOMEM;
tag_size = ALIGN(nq->queue_depth, BITS_PER_LONG) / BITS_PER_LONG;
nq->tag_map = kcalloc(tag_size, sizeof(unsigned long), GFP_KERNEL);
if (!nq->tag_map) {
kfree(nq->cmds);
return -ENOMEM;
}
for (i = 0; i < nq->queue_depth; i++) {
cmd = &nq->cmds[i];
INIT_LIST_HEAD(&cmd->list);
cmd->ll_list.next = NULL;
cmd->tag = -1U;
}
return 0;
}
static int setup_queues(struct nullb *nullb)
{
nullb->queues = kcalloc(nullb->dev->submit_queues,
sizeof(struct nullb_queue),
GFP_KERNEL);
if (!nullb->queues)
return -ENOMEM;
nullb->nr_queues = 0;
nullb->queue_depth = nullb->dev->hw_queue_depth;
return 0;
}
static int init_driver_queues(struct nullb *nullb)
{
struct nullb_queue *nq;
int i, ret = 0;
for (i = 0; i < nullb->dev->submit_queues; i++) {
nq = &nullb->queues[i];
null_init_queue(nullb, nq);
ret = setup_commands(nq);
if (ret)
return ret;
nullb->nr_queues++;
}
return 0;
}
static int null_gendisk_register(struct nullb *nullb)
{
struct gendisk *disk;
sector_t size;
disk = nullb->disk = alloc_disk_node(1, nullb->dev->home_node);
if (!disk)
return -ENOMEM;
size = (sector_t)nullb->dev->size * 1024 * 1024ULL;
set_capacity(disk, size >> 9);
disk->flags |= GENHD_FL_EXT_DEVT | GENHD_FL_SUPPRESS_PARTITION_INFO;
disk->major = null_major;
disk->first_minor = nullb->index;
disk->fops = &null_fops;
disk->private_data = nullb;
disk->queue = nullb->q;
strncpy(disk->disk_name, nullb->disk_name, DISK_NAME_LEN);
if (nullb->dev->zoned) {
int ret = blk_revalidate_disk_zones(disk);
if (ret != 0)
return ret;
}
add_disk(disk);
return 0;
}
static int null_init_tag_set(struct nullb *nullb, struct blk_mq_tag_set *set)
{
set->ops = &null_mq_ops;
set->nr_hw_queues = nullb ? nullb->dev->submit_queues :
g_submit_queues;
set->queue_depth = nullb ? nullb->dev->hw_queue_depth :
g_hw_queue_depth;
set->numa_node = nullb ? nullb->dev->home_node : g_home_node;
set->cmd_size = sizeof(struct nullb_cmd);
set->flags = BLK_MQ_F_SHOULD_MERGE;
if (g_no_sched)
set->flags |= BLK_MQ_F_NO_SCHED;
set->driver_data = NULL;
if ((nullb && nullb->dev->blocking) || g_blocking)
set->flags |= BLK_MQ_F_BLOCKING;
return blk_mq_alloc_tag_set(set);
}
static void null_validate_conf(struct nullb_device *dev)
{
dev->blocksize = round_down(dev->blocksize, 512);
dev->blocksize = clamp_t(unsigned int, dev->blocksize, 512, 4096);
if (dev->queue_mode == NULL_Q_MQ && dev->use_per_node_hctx) {
if (dev->submit_queues != nr_online_nodes)
dev->submit_queues = nr_online_nodes;
} else if (dev->submit_queues > nr_cpu_ids)
dev->submit_queues = nr_cpu_ids;
else if (dev->submit_queues == 0)
dev->submit_queues = 1;
dev->queue_mode = min_t(unsigned int, dev->queue_mode, NULL_Q_MQ);
dev->irqmode = min_t(unsigned int, dev->irqmode, NULL_IRQ_TIMER);
/* Do memory allocation, so set blocking */
if (dev->memory_backed)
dev->blocking = true;
else /* cache is meaningless */
dev->cache_size = 0;
dev->cache_size = min_t(unsigned long, ULONG_MAX / 1024 / 1024,
dev->cache_size);
dev->mbps = min_t(unsigned int, 1024 * 40, dev->mbps);
/* can not stop a queue */
if (dev->queue_mode == NULL_Q_BIO)
dev->mbps = 0;
}
#ifdef CONFIG_BLK_DEV_NULL_BLK_FAULT_INJECTION
static bool __null_setup_fault(struct fault_attr *attr, char *str)
{
if (!str[0])
return true;
if (!setup_fault_attr(attr, str))
return false;
attr->verbose = 0;
return true;
}
#endif
static bool null_setup_fault(void)
{
#ifdef CONFIG_BLK_DEV_NULL_BLK_FAULT_INJECTION
if (!__null_setup_fault(&null_timeout_attr, g_timeout_str))
return false;
if (!__null_setup_fault(&null_requeue_attr, g_requeue_str))
return false;
#endif
return true;
}
static int null_add_dev(struct nullb_device *dev)
{
struct nullb *nullb;
int rv;
null_validate_conf(dev);
nullb = kzalloc_node(sizeof(*nullb), GFP_KERNEL, dev->home_node);
if (!nullb) {
rv = -ENOMEM;
goto out;
}
nullb->dev = dev;
dev->nullb = nullb;
spin_lock_init(&nullb->lock);
rv = setup_queues(nullb);
if (rv)
goto out_free_nullb;
if (dev->queue_mode == NULL_Q_MQ) {
if (shared_tags) {
nullb->tag_set = &tag_set;
rv = 0;
} else {
nullb->tag_set = &nullb->__tag_set;
rv = null_init_tag_set(nullb, nullb->tag_set);
}
if (rv)
goto out_cleanup_queues;
if (!null_setup_fault())
goto out_cleanup_queues;
nullb->tag_set->timeout = 5 * HZ;
nullb->q = blk_mq_init_queue(nullb->tag_set);
if (IS_ERR(nullb->q)) {
rv = -ENOMEM;
goto out_cleanup_tags;
}
null_init_queues(nullb);
} else if (dev->queue_mode == NULL_Q_BIO) {
nullb->q = blk_alloc_queue_node(GFP_KERNEL, dev->home_node);
if (!nullb->q) {
rv = -ENOMEM;
goto out_cleanup_queues;
}
blk_queue_make_request(nullb->q, null_queue_bio);
rv = init_driver_queues(nullb);
if (rv)
goto out_cleanup_blk_queue;
}
if (dev->mbps) {
set_bit(NULLB_DEV_FL_THROTTLED, &dev->flags);
nullb_setup_bwtimer(nullb);
}
if (dev->cache_size > 0) {
set_bit(NULLB_DEV_FL_CACHE, &nullb->dev->flags);
blk_queue_write_cache(nullb->q, true, true);
}
if (dev->zoned) {
rv = null_zone_init(dev);
if (rv)
goto out_cleanup_blk_queue;
blk_queue_chunk_sectors(nullb->q, dev->zone_size_sects);
nullb->q->limits.zoned = BLK_ZONED_HM;
}
nullb->q->queuedata = nullb;
blk_queue_flag_set(QUEUE_FLAG_NONROT, nullb->q);
blk_queue_flag_clear(QUEUE_FLAG_ADD_RANDOM, nullb->q);
mutex_lock(&lock);
nullb->index = ida_simple_get(&nullb_indexes, 0, 0, GFP_KERNEL);
dev->index = nullb->index;
mutex_unlock(&lock);
blk_queue_logical_block_size(nullb->q, dev->blocksize);
blk_queue_physical_block_size(nullb->q, dev->blocksize);
null_config_discard(nullb);
sprintf(nullb->disk_name, "nullb%d", nullb->index);
rv = null_gendisk_register(nullb);
if (rv)
goto out_cleanup_zone;
mutex_lock(&lock);
list_add_tail(&nullb->list, &nullb_list);
mutex_unlock(&lock);
return 0;
out_cleanup_zone:
if (dev->zoned)
null_zone_exit(dev);
out_cleanup_blk_queue:
blk_cleanup_queue(nullb->q);
out_cleanup_tags:
if (dev->queue_mode == NULL_Q_MQ && nullb->tag_set == &nullb->__tag_set)
blk_mq_free_tag_set(nullb->tag_set);
out_cleanup_queues:
cleanup_queues(nullb);
out_free_nullb:
kfree(nullb);
out:
return rv;
}
static int __init null_init(void)
{
int ret = 0;
unsigned int i;
struct nullb *nullb;
struct nullb_device *dev;
if (g_bs > PAGE_SIZE) {
pr_warn("null_blk: invalid block size\n");
pr_warn("null_blk: defaults block size to %lu\n", PAGE_SIZE);
g_bs = PAGE_SIZE;
}
if (!is_power_of_2(g_zone_size)) {
pr_err("null_blk: zone_size must be power-of-two\n");
return -EINVAL;
}
if (g_home_node != NUMA_NO_NODE && g_home_node >= nr_online_nodes) {
pr_err("null_blk: invalid home_node value\n");
g_home_node = NUMA_NO_NODE;
}
if (g_queue_mode == NULL_Q_RQ) {
pr_err("null_blk: legacy IO path no longer available\n");
return -EINVAL;
}
if (g_queue_mode == NULL_Q_MQ && g_use_per_node_hctx) {
if (g_submit_queues != nr_online_nodes) {
pr_warn("null_blk: submit_queues param is set to %u.\n",
nr_online_nodes);
g_submit_queues = nr_online_nodes;
}
} else if (g_submit_queues > nr_cpu_ids)
g_submit_queues = nr_cpu_ids;
else if (g_submit_queues <= 0)
g_submit_queues = 1;
if (g_queue_mode == NULL_Q_MQ && shared_tags) {
ret = null_init_tag_set(NULL, &tag_set);
if (ret)
return ret;
}
config_group_init(&nullb_subsys.su_group);
mutex_init(&nullb_subsys.su_mutex);
ret = configfs_register_subsystem(&nullb_subsys);
if (ret)
goto err_tagset;
mutex_init(&lock);
null_major = register_blkdev(0, "nullb");
if (null_major < 0) {
ret = null_major;
goto err_conf;
}
for (i = 0; i < nr_devices; i++) {
dev = null_alloc_dev();
if (!dev) {
ret = -ENOMEM;
goto err_dev;
}
ret = null_add_dev(dev);
if (ret) {
null_free_dev(dev);
goto err_dev;
}
}
pr_info("null: module loaded\n");
return 0;
err_dev:
while (!list_empty(&nullb_list)) {
nullb = list_entry(nullb_list.next, struct nullb, list);
dev = nullb->dev;
null_del_dev(nullb);
null_free_dev(dev);
}
unregister_blkdev(null_major, "nullb");
err_conf:
configfs_unregister_subsystem(&nullb_subsys);
err_tagset:
if (g_queue_mode == NULL_Q_MQ && shared_tags)
blk_mq_free_tag_set(&tag_set);
return ret;
}
static void __exit null_exit(void)
{
struct nullb *nullb;
configfs_unregister_subsystem(&nullb_subsys);
unregister_blkdev(null_major, "nullb");
mutex_lock(&lock);
while (!list_empty(&nullb_list)) {
struct nullb_device *dev;
nullb = list_entry(nullb_list.next, struct nullb, list);
dev = nullb->dev;
null_del_dev(nullb);
null_free_dev(dev);
}
mutex_unlock(&lock);
if (g_queue_mode == NULL_Q_MQ && shared_tags)
blk_mq_free_tag_set(&tag_set);
}
module_init(null_init);
module_exit(null_exit);
MODULE_AUTHOR("Jens Axboe ");
MODULE_LICENSE("GPL"); /drivers/block/null_blk.h
/* SPDX-License-Identifier: GPL-2.0 */
#ifndef __BLK_NULL_BLK_H
#define __BLK_NULL_BLK_H
#include
#include
#include
#include
#include
#include
#include
struct nullb_cmd {
struct list_head list;
struct llist_node ll_list;
struct __call_single_data csd;
struct request *rq;
struct bio *bio;
unsigned int tag;
blk_status_t error;
struct nullb_queue *nq;
struct hrtimer timer;
};
struct nullb_queue {
unsigned long *tag_map;
wait_queue_head_t wait;
unsigned int queue_depth;
struct nullb_device *dev;
unsigned int requeue_selection;
struct nullb_cmd *cmds;
};
struct nullb_device {
struct nullb *nullb;
struct config_item item;
struct radix_tree_root data; /* data stored in the disk */
struct radix_tree_root cache; /* disk cache data */
unsigned long flags; /* device flags */
unsigned int curr_cache;
struct badblocks badblocks;
unsigned int nr_zones;
struct blk_zone *zones;
sector_t zone_size_sects;
unsigned long size; /* device size in MB */
unsigned long completion_nsec; /* time in ns to complete a request */
unsigned long cache_size; /* disk cache size in MB */
unsigned long zone_size; /* zone size in MB if device is zoned */
unsigned int zone_nr_conv; /* number of conventional zones */
unsigned int submit_queues; /* number of submission queues */
unsigned int home_node; /* home node for the device */
unsigned int queue_mode; /* block interface */
unsigned int blocksize; /* block size */
unsigned int irqmode; /* IRQ completion handler */
unsigned int hw_queue_depth; /* queue depth */
unsigned int index; /* index of the disk, only valid with a disk */
unsigned int mbps; /* Bandwidth throttle cap (in MB/s) */
bool blocking; /* blocking blk-mq device */
bool use_per_node_hctx; /* use per-node allocation for hardware context */
bool power; /* power on/off the device */
bool memory_backed; /* if data is stored in memory */
bool discard; /* if support discard */
bool zoned; /* if device is zoned */
};
struct nullb {
struct nullb_device *dev;
struct list_head list;
unsigned int index;
struct request_queue *q;
struct gendisk *disk;
struct blk_mq_tag_set *tag_set;
struct blk_mq_tag_set __tag_set;
unsigned int queue_depth;
atomic_long_t cur_bytes;
struct hrtimer bw_timer;
unsigned long cache_flush_pos;
spinlock_t lock;
struct nullb_queue *queues;
unsigned int nr_queues;
char disk_name[DISK_NAME_LEN];
};
#ifdef CONFIG_BLK_DEV_ZONED
int null_zone_init(struct nullb_device *dev);
void null_zone_exit(struct nullb_device *dev);
int null_zone_report(struct gendisk *disk, sector_t sector,
struct blk_zone *zones, unsigned int *nr_zones,
gfp_t gfp_mask);
void null_zone_write(struct nullb_cmd *cmd, sector_t sector,
unsigned int nr_sectors);
void null_zone_reset(struct nullb_cmd *cmd, sector_t sector);
#else
static inline int null_zone_init(struct nullb_device *dev)
{
pr_err("null_blk: CONFIG_BLK_DEV_ZONED not enabled\n");
return -EINVAL;
}
static inline void null_zone_exit(struct nullb_device *dev) {}
static inline int null_zone_report(struct gendisk *disk, sector_t sector,
struct blk_zone *zones,
unsigned int *nr_zones, gfp_t gfp_mask)
{
return -EOPNOTSUPP;
}
static inline void null_zone_write(struct nullb_cmd *cmd, sector_t sector,
unsigned int nr_sectors)
{
}
static inline void null_zone_reset(struct nullb_cmd *cmd, sector_t sector) {}
#endif /* CONFIG_BLK_DEV_ZONED */
#endif /* __NULL_BLK_H */
#include
#include
#include
#include
#include
#include
#include
#include
#include //for struct hd_geometry
#include //for CDROM_GET_CAPABILITY
#ifndef SUCCESS
#define SUCCESS 0
#endif
//This defines are available in blkdev.h from kernel 4.17 (vanilla).
#ifndef SECTOR_SHIFT
#define SECTOR_SHIFT 9
#endif
#ifndef SECTOR_SIZE
#define SECTOR_SIZE (1 << SECTOR_SHIFT)
#endif
// constants - instead defines
static const char* _sblkdev_name = "sblkdev";
static const size_t _sblkdev_buffer_size = 16 * PAGE_SIZE;
// types
typedef struct sblkdev_cmd_s
{
//nothing
} sblkdev_cmd_t;
// The internal representation of our device
typedef struct sblkdev_device_s
{
sector_t capacity; // Device size in bytes
u8* data; // The data aray. u8 - 8 bytes
atomic_t open_counter; // How many openers
struct blk_mq_tag_set tag_set;
struct request_queue *queue; // For mutual exclusion
struct gendisk *disk; // The gendisk structure
} sblkdev_device_t;
// global variables
static int _sblkdev_major = 0;
static sblkdev_device_t* _sblkdev_device = NULL;
// functions
static int sblkdev_allocate_buffer(sblkdev_device_t* dev)
{
dev->capacity = _sblkdev_buffer_size >> SECTOR_SHIFT;
dev->data = kmalloc(dev->capacity << SECTOR_SHIFT, GFP_KERNEL); //
if (dev->data == NULL) {
printk(KERN_WARNING "sblkdev: vmalloc failure.\n");
return -ENOMEM;
}
return SUCCESS;
}
static void sblkdev_free_buffer(sblkdev_device_t* dev)
{
if (dev->data) {
kfree(dev->data);
dev->data = NULL;
dev->capacity = 0;
}
}
static void sblkdev_remove_device(void)
{
sblkdev_device_t* dev = _sblkdev_device;
if (dev == NULL)
return;
if (dev->disk)
del_gendisk(dev->disk);
if (dev->queue) {
blk_cleanup_queue(dev->queue);
dev->queue = NULL;
}
if (dev->tag_set.tags)
blk_mq_free_tag_set(&dev->tag_set);
if (dev->disk) {
put_disk(dev->disk);
dev->disk = NULL;
}
sblkdev_free_buffer(dev);
kfree(dev);
_sblkdev_device = NULL;
printk(KERN_WARNING "sblkdev: simple block device was removed\n");
}
static int do_simple_request(struct request *rq, unsigned int *nr_bytes)
{
int ret = SUCCESS;
struct bio_vec bvec;
struct req_iterator iter;
sblkdev_device_t *dev = rq->q->queuedata;
loff_t pos = blk_rq_pos(rq) << SECTOR_SHIFT;
loff_t dev_size = (loff_t)(dev->capacity << SECTOR_SHIFT);
printk(KERN_WARNING "sblkdev: request start from sector %ld \n", blk_rq_pos(rq));
rq_for_each_segment(bvec, rq, iter)
{
unsigned long b_len = bvec.bv_len;
void* b_buf = page_address(bvec.bv_page) + bvec.bv_offset;
if ((pos + b_len) > dev_size)
b_len = (unsigned long)(dev_size - pos);
if (rq_data_dir(rq))//WRITE
memcpy(dev->data + pos, b_buf, b_len);
else//READ
memcpy(b_buf, dev->data + pos, b_len);
pos += b_len;
*nr_bytes += b_len;
}
return ret;
}
static blk_status_t _queue_rq(struct blk_mq_hw_ctx *hctx, const struct blk_mq_queue_data* bd)
{
unsigned int nr_bytes = 0;
blk_status_t status = BLK_STS_OK;
struct request *rq = bd->rq;
//we cannot use any locks that make the thread sleep
blk_mq_start_request(rq);
if (do_simple_request(rq, &nr_bytes) != SUCCESS)
status = BLK_STS_IOERR;
printk(KERN_WARNING "sblkdev: request process %d bytes\n", nr_bytes);
#if 0 //simply and can be called from proprietary module
blk_mq_end_request(rq, status);
#else //can set real processed bytes count
if (blk_update_request(rq, status, nr_bytes)) //GPL-only symbol
BUG();
__blk_mq_end_request(rq, status);
#endif
return BLK_STS_OK;//always return ok
}
static struct blk_mq_ops _mq_ops = {
.queue_rq = _queue_rq,
};
static int _open(struct block_device *bdev, fmode_t mode)
{
sblkdev_device_t* dev = bdev->bd_disk->private_data;
if (dev == NULL) {
printk(KERN_WARNING "sblkdev: invalid disk private_data\n");
return -ENXIO;
}
atomic_inc(&dev->open_counter);
printk(KERN_WARNING "sblkdev: device was opened\n");
return SUCCESS;
}
static void _release(struct gendisk *disk, fmode_t mode)
{
sblkdev_device_t* dev = disk->private_data;
if (dev) {
atomic_dec(&dev->open_counter);
printk(KERN_WARNING "sblkdev: device was closed\n");
}
else
printk(KERN_WARNING "sblkdev: invalid disk private_data\n");
}
static int _getgeo(sblkdev_device_t* dev, struct hd_geometry* geo)
{
sector_t quotient;
geo->start = 0;
if (dev->capacity > 63) {
geo->sectors = 63;
quotient = (dev->capacity + (63 - 1)) / 63;
if (quotient > 255) {
geo->heads = 255;
geo->cylinders = (unsigned short)((quotient + (255 - 1)) / 255);
}
else {
geo->heads = (unsigned char)quotient;
geo->cylinders = 1;
}
}
else {
geo->sectors = (unsigned char)dev->capacity;
geo->cylinders = 1;
geo->heads = 1;
}
return SUCCESS;
}
static int _ioctl(struct block_device *bdev, fmode_t mode, unsigned int cmd, unsigned long arg)
{
int ret = -ENOTTY;
sblkdev_device_t* dev = bdev->bd_disk->private_data;
printk(KERN_WARNING "sblkdev: ioctl %x received\n", cmd);
switch (cmd) {
case HDIO_GETGEO:
{
struct hd_geometry geo;
ret = _getgeo(dev, &geo );
if (copy_to_user((void *)arg, &geo, sizeof(struct hd_geometry)))
ret = -EFAULT;
else
ret = SUCCESS;
break;
}
case CDROM_GET_CAPABILITY: //0x5331 / * get capabilities * /
{
struct gendisk *disk = bdev->bd_disk;
if (bdev->bd_disk && (disk->flags & GENHD_FL_CD))
ret = SUCCESS;
else
ret = -EINVAL;
break;
}
}
return ret;
}
#ifdef CONFIG_COMPAT
static int _compat_ioctl(struct block_device *bdev, fmode_t mode, unsigned int cmd, unsigned long arg)
{
// CONFIG_COMPAT is to allow running 32-bit userspace code on a 64-bit kernel
return -ENOTTY; // not supported
}
#endif
static const struct block_device_operations _fops = {
.owner = THIS_MODULE,
.open = _open,
.release = _release,
.ioctl = _ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = _compat_ioctl,
#endif
};
//
static int sblkdev_add_device(void)
{
int ret = SUCCESS;
sblkdev_device_t* dev = kzalloc(sizeof(sblkdev_device_t), GFP_KERNEL);
if (dev == NULL) {
printk(KERN_WARNING "sblkdev: unable to allocate %ld bytes\n", sizeof(sblkdev_device_t));
return -ENOMEM;
}
_sblkdev_device = dev;
do{
ret = sblkdev_allocate_buffer(dev);
if(ret)
break;
#if 0 //simply variant with helper function blk_mq_init_sq_queue. It`s available from kernel 4.20 (vanilla).
{//configure tag_set
struct request_queue *queue;
dev->tag_set.cmd_size = sizeof(sblkdev_cmd_t);
dev->tag_set.driver_data = dev;
queue = blk_mq_init_sq_queue(&dev->tag_set, &_mq_ops, 128, BLK_MQ_F_SHOULD_MERGE | BLK_MQ_F_SG_MERGE);
if (IS_ERR(queue)) {
ret = PTR_ERR(queue);
printk(KERN_WARNING "sblkdev: unable to allocate and initialize tag set\n");
break;
}
dev->queue = queue;
}
#else // more flexible variant
{//configure tag_set
dev->tag_set.ops = &_mq_ops;
dev->tag_set.nr_hw_queues = 1;
dev->tag_set.queue_depth = 128;
dev->tag_set.numa_node = NUMA_NO_NODE;
dev->tag_set.cmd_size = sizeof(sblkdev_cmd_t);
dev->tag_set.flags = BLK_MQ_F_SHOULD_MERGE | BLK_MQ_F_SG_MERGE;
dev->tag_set.driver_data = dev;
ret = blk_mq_alloc_tag_set(&dev->tag_set);
if (ret) {
printk(KERN_WARNING "sblkdev: unable to allocate tag set\n");
break;
}
}
{//configure queue
struct request_queue *queue = blk_mq_init_queue(&dev->tag_set);
if (IS_ERR(queue)) {
ret = PTR_ERR(queue);
printk(KERN_WARNING "sblkdev: Failed to allocate queue\n");
break;
}
dev->queue = queue;
}
#endif
dev->queue->queuedata = dev;
{// configure disk
struct gendisk *disk = alloc_disk(1); //only one partition
if (disk == NULL) {
printk(KERN_WARNING "sblkdev: Failed to allocate disk\n");
ret = -ENOMEM;
break;
}
disk->flags |= GENHD_FL_NO_PART_SCAN; //only one partition
//disk->flags |= GENHD_FL_EXT_DEVT;
disk->flags |= GENHD_FL_REMOVABLE;
disk->major = _sblkdev_major;
disk->first_minor = 0;
disk->fops = &_fops;
disk->private_data = dev;
disk->queue = dev->queue;
sprintf(disk->disk_name, "sblkdev%d", 0);
set_capacity(disk, dev->capacity);
dev->disk = disk;
add_disk(disk);
}
printk(KERN_WARNING "sblkdev: simple block device was created\n");
}while(false);
if (ret){
sblkdev_remove_device();
printk(KERN_WARNING "sblkdev: Failed add block device\n");
}
return ret;
}
static int __init sblkdev_init(void)
{
int ret = SUCCESS;
_sblkdev_major = register_blkdev(_sblkdev_major, _sblkdev_name);
if (_sblkdev_major <= 0){
printk(KERN_WARNING "sblkdev: unable to get major number\n");
return -EBUSY;
}
ret = sblkdev_add_device();
if (ret)
unregister_blkdev(_sblkdev_major, _sblkdev_name);
return ret;
}
static void __exit sblkdev_exit(void)
{
sblkdev_remove_device();
if (_sblkdev_major > 0)
unregister_blkdev(_sblkdev_major, _sblkdev_name);
}
module_init(sblkdev_init);
module_exit(sblkdev_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Code Imp");