2019独角兽企业重金招聘Python工程师标准>>> 
逐层构建算法
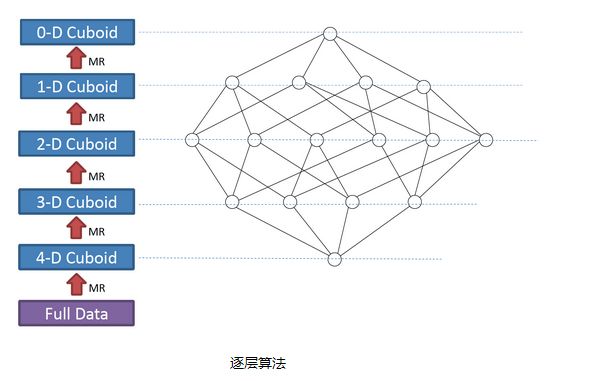
我们知道,一个N维的Cube,是由1个N维子立方体、N个(N-1)维子立方体、N*(N-1)/2个(N-2)维子立方体、......、N个1维子立方体和1个0维子立方体构成,总共有2^N个子立方体组成,在逐层算法中,按维度数逐层减少来计算,每个层级的计算(除了第一层,它是从原始数据聚合而来),是基于它上一层级的结果来计算的。
比如,[Group by A, B]的结果,可以基于[Groupby A, B, C]的结果,通过去掉C后聚合得来的;这样可以减少重复计算;当 0维度Cuboid计算出来的时候,整个Cube的计算也就完成了。
下图为一个四维Cube的构建过程:
此算法的Mapper和Reducer都比较简单。Mapper以上一层Cuboid的结果(Key-Value对)作为输入。由于Key是由各维度值拼接在一起,从其中找出要聚合的维度,去掉它的值成新的Key,然后把新Key和Value输出,进而HadoopMapReduce对所有新Key进行排序、洗牌(shuffle)、再送到Reducer处;Reducer的输入会是一组有相同Key的Value集合,对这些Value做聚合计算,再结合Key输出就完成了一轮计算。
每一轮的计算都是一个MapReduce任务,且串行执行; 一个N维的Cube,至少需要N次MapReduceJob。
问题:
对HDFS的读写操作较多;Cube有比较多维度的时候,所需要的MapReduce任务也相应增加; 该算法的效率较低
快速构建算法(逐块构建算法)
该算法的主要思想是,对Mapper所分配的数据块,将它计算成一个完整的小Cube 段(包含所有Cuboid);每个Mapper将计算完的Cube段输出给Reducer做合并,生成大Cube,也就是最终结果;如下图所示:
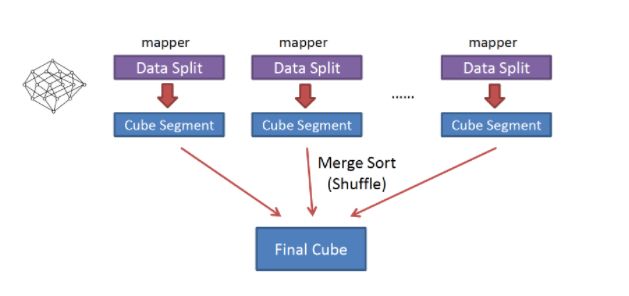
Cube构建流程
为了节省存储资源,Kylin对维度值进行了字典编码。例如城市维度将beijing和shanghai依次编码为0和1。
HBase KV存储:在计算cuboid过程中,会将Hive表的数据转化为HBase的KV形式。Rowkey的具体格式是cuboid id + 具体的维度值(最新的Rowkey中为了并发查询还加入了ShardKey),例如维度组合是(year,city),所以cuboid id就是00000011,cuboid是8位,具体维度值是1994和shanghai,加入维度值对应的字典编码也是11,所以HBase的Rowkey就是0000001111,对应的HBase Value就是sum(priece)的具体值。
所有的cuboid计算完成后,会将cuboid转化为HBase的KeyValue格式生成HBase的HFile,最后将HFile load进cube对应的HBase表中。
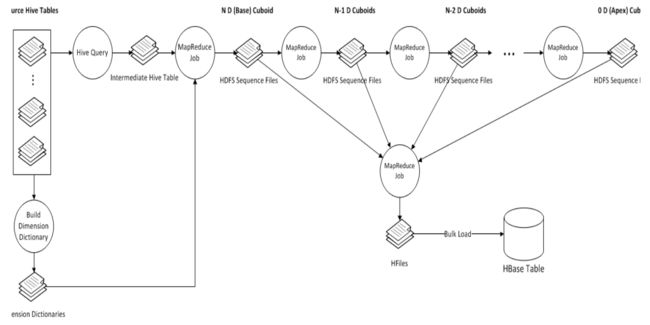
Cube的构建包含如下步骤,由任务引擎来调度执行。
1)创建临时的Hive平表(从Hive读取数据)。
2)计算各维度的不同值,并收集各Cuboid的统计数据。
3)创建并保存字典。
4)保存Cuboid统计信息。
5)创建HTable。
6)计算Cube(一轮或若干轮MapReduce)。
7)将Cube的计算结果转成HFile。
8)加载HFile到HBase。(RowKey为:Cuboid ID + 维度值,Value为度量值)
9)更新Cube元数据。(变更Cube状态)
10)垃圾回收。(删除临时表)