1 容器编排工具概述
k8s扩展docker单个容器的管理功能,实现夸多主机的问题,容器编排要负责网络,存储,安全等问题。
容器编排系统,完成以下功能:
1.为docker提供私有的Registry
2.提供网络功能
3.提供共享存储
4.确保容器间的安全
5.TeleMetry
容器编排的三个主要工具
1.docker的三剑客:docker machine+swarm+compose
docker machine,快速构建docker容器,加入集群。
swarm:把容器加入到集群中来
compose:面向swarm,实现容器的编排
2.mesos+marathon:系统资源调度框架,可以调度hadoop或者容器,不是专门为容器编排设定的
3.kubernetes:把容器归类到一起,最小调度单位是容器集(Pod)
本文主要介绍kubernetes的相关内容
2 k8s整体概述
k8s,可监控系统的资源使用情况,进行容器的自动增加或者收缩,这就是所谓的容器编排
kubernetes:舵手,飞行员,参考谷歌内部的大规模内部容器调度系统Borg实现,使用Go语言开发。代码托管在github上,链接:https://github.com/kubernetes/kubernetes
k8s特性如下:
1.自动装箱,自动容器的部署,不影响可用性
2.自我修复,如容器崩溃后快速重新启动新的容器
3.自动实现水平扩展
4.自动实现服务发现和负载均衡
5.自动发布和回滚
6.支持密钥和配置管理,把应用程序的配置信息通过服务来加载,而不是加载本地的配置。实现配置的统一
7.实现存储编排
8.任务的批处理运行
k8s的集群至少有两个主机组成:master + node ,即为master/node架构,master为集群的控制面板,master主机需要做冗余,一般建议为3台,而node主机不需要,因为node的主要作用是运行pod,贡献计算能力和存储能力,而pod控制器会自动管控pod资源,如果资源少,pod控制器会自动创建pod,即pod控制器会严格按照用户指定的副本来管理pod的数量。客户端的请求下发给master,即把创建和启动容器的请求发给master,master中的调度器分析各node现有的资源状态,把请求调用到对应的node启动容器。
可以理解为k8s把容器抽象为pod来管理1到多个彼此间有非常紧密联系的容器,但是LAMP的容器主机A,M,P只是有关联,不能说是非常紧密联系,因此A,M,P都要运行在三个不同的pod上。
在k8s中,要运行几个pod,是需要定义一个配置文件,在这个配置文件里定义用哪个控制器启动和控制几个pod,在每个pod里要定义那几台容器,k8s通过这个配置文件,去创建一个控制器,由此控制器来管控这些pod,如果这些pod的某几个down掉后,控制器会通过健康监控功能,随时监控pod,发现pod异常后,根据定义的策略进行操作,即可以进行自愈。
k8s内部需要5套证书,手动创建或者自动生成,分别为,etcd内部通信需要一套ca和对应证书,etcd与外部通信也要有一套ca和对应证书。APIserver间通信需要一套证书,apiserver与node间通信需要一套证书,node和pod间通信需要一套ca
目前而言,还不能实现把所有的业务都迁到k8s上,如存储,因为这个是有状态应用,出现错误排查很麻烦,目前而且,k8s主要是运行无状态应用。
所以一般而言,负载均衡器运行在K8s之外,nginx或者tomcat这种无状态的应用运行于k8s集群内部,而数据库,如mysql,zabbix,zoopkeeper,有状态的,一般运行于k8s外部,通过网络连接,实现k8s集群的pod调用这些外部的有状态应用。
k8s集群架构如下

k8s的master和node的详细架构如下
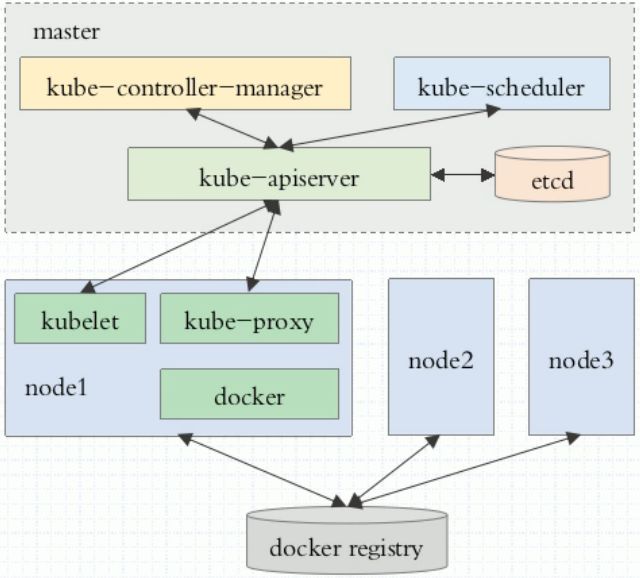
k8s的集群组件如下:
master: apiserver,scheduler,controller-manager,etcd
node:kubelet(agent),kube-proxy,docker(container engine)
Registry:harbor,属于集群外部的
Addons(附件):kube-dns,UI(如 dashboard)等等。在集群运行正常后,在集群上运行pod实现。
k8s部署集群整体环境架构
注意,下图的ip可根据实际环境调整

3 master主机
master 有三个最关键的组件,apiserver,scheduler,controller-manager,运行为三个守护进程:
apiserver:负责接入请求的入口,解析请求,处理请求,即网关,任何到达请求必须经过apiserver
scheduler:请求到达后,由scheduler计算后端node的相关资源,如cpu或者内存使用情况后,负责调度到合适的node,并启动pod,即选定某一节点后,有节点的kubelet负责节点上的操作如启动pod,即scheduler会先做预选,选择满足条件的node,然后再做优选,最合适的node,启动pod
controller-manager:控制器管理器,统一管控不同类型的资源,监控master上每个控制器的健康性,可以在每个master集群上做冗余高可用。其中,控制器用于确保已创建的容器处于健康状态。
controller:控制器,自动创建pod资源(容器启动),根据用户的需求启动和创建pod,可以在m个节点上运行n个容器,控制器根据label来识别pod。,使得pod能够按照指定的数量运行。
controller 通过 label selector 来关联 pod (lable),注意controller只是用来管理pod的健康性,不能进行pod流量导向,即管理pod,确保pod副本数量严格符合用户的定义。
每一组pod都需要独立的控制器来运行,实现跨节点自愈,管控pod的生命周期。控制器也是通过便签和便签选择器来实现感知自己管控组内的pod
在k8s环境中,推荐使用控制器管理的pod,控制器有如下几种:
ReplicationController。严格控制容器的副本数和滚动更新pod,在更新过程临时超出副本数。也支持滚动回滚操作。
RelicaSet:声明更新控制器
Deployment:负责无状态应用pod控制,支持二级控制器(HPA,HorizontalPodAutoscaler水平pod自动控制器)。
StatefulSet:负责有状态应用pod控制
DeamonSet:守护进程集,作用是在集群中每一个node上都启用一个pod副本,如果pod down了,DeamonSet会自动重启这个pod,如果新增node,会自动添加。即自动下载镜像,在这个node上启用这个pod。
Job,Ctonjob:周期性pod控制,如临时任务的job。
不同的控制器,满足客户不同类型的pod资源运行。
master 主机其他组件:
label selector ;标签选择器,根据标签来选择符合条件的资源对象的机制,不仅仅用于pod资源,所有的对象都可以打上标签。k/v格式的数据。service和controller都是根据标签和标签控制器来识别pod资源。
etcd:分布式的高性能的键值存储的数据库系统,保存集群的对象状态信息,如apiserver对所有主机的操作结果,如创建pod,删除pod,调度pod的结果状态信息都保存在etcd中,如果这个插件异常,则整个集群运行都将异常,因为etcd异常后,整个集群的状态协议都将不能正常工作。因此etcd需要做高可用,防止单点故障。专门的组件,另外一个主机上安装的组件,建议至少三个节点,为restfull风格的集群。为https协议。
master示意图如下
注意,API,UI,CLI都想API Server发送请求

4 node主机
node节点上主要有三个主键,kubelet,kube-proxy,container engine(这里用docker),介绍如下
kubelet:相当于k8s的节点级的agent,执行当地任务,如当前节点的启动和当前节点的状态状态监测,和apiserver进行交互。
kube-proxy:为当前节点的pod生成iptables或者ipvs规则,实现了将用户请求调度到后端pod,为service组件服务,负责与apiserver随时保持通信,一旦发现某一service后的pod发生改变,需要将改变保存在apiserver中,而apiserver内容发生改变后,会生成通知事件,使得所有关联apiserver的组件都能收到,而 kube-proxy可以收到这个通知事件,一旦发现某一service背后的pod信息发生改变,kube-proxy就会把改变反应在本地的iptables或者ipvs规则上,实现动态的变化。kube-proxy有三个模型,userspace(名称空间,和docker的名称空间有区别,),iptables,ipvs,负责实现service的定义
container engine:作用是负责启动或者运行有kubelete启动的容器,如docker
此外,node节点上还有addons(附件),如dns,可以动态变动dns解析内容,如service的名称改了,会自动触发dns的记录进行更改。
node示意图如下

5 逻辑组件介绍
除了master和node上的关键组件,还有逻辑组件介绍如下
service:
service 通过 label selector 来关联 pod (lable) ,提供一个固定端点,使得用户的请求流量导向后端的pod,service为pod中的应用的客户端提供一个固定的访问端点,即clusterIP:ServicePort实现、另外通过DNS Addons实现服务把主机名和clusterIP做解析,使得访问能够通过主机名和端口来实现
service是在应用前面加一个代理层,这个代理层的主机名对应的ip不变,手动创建,比如nginx要配置后端的tomcat,那么配置文件上写入的后端tomcat的ip应该是代理层上(service)的主机名(因为ip也可能变化),防止tomcat重建后ip变化。代理层上通过service的后端pod的label来感知后端pod,所以,无论pod的ip地址怎么变化,只要label不变,service通过便签选择器(label selector)来动态关联后端的pod。同理,由于应用可能被删掉重新创建,因此,在所有的应用前,都需要有service,相当于是提供其他应用统一访问的入口。实际上,service,提供稳定的访问入口和调度功能,根据label来调度,只要pod的label不变,那么即使pod的ip和端口变化了,都能被service识别,因为service根据label来识别pod对象。可以跨主机实现的,service相当于是由kube-proxy创建的iptables的dnat规则或者ipvs规则。k8s1.11版本中,已经把规则调整为ipvs规则。当一个请求到达service后,service会调度到对应的node上。如果service被误删了,那么ip地址可能会变化,为了防止这种情况发生,k8s有一个附件,dns服务,完成服务发现,动态按需完成资源的迁移和改变,如每次创建一个service,就会把service对应的名称和ip关系,放入到这个dns的解析库中,那么当service被删掉时,对应解析记录就会被删掉,当service重建后,就会在这个解析库中新建对应的解析记录。因此只要前端应用配置的是service的主机名,那么即使service重建,ip变更也不影响请求的调度。如果没有了service,那么前后端应用的衔接就不能固定,服务异常。
当客户端发起请求,请求都先到servcie,service收到请求后,通过本地的iptables或者ipvs规则调度到后端的pod,如果pod不在同一node上,那么存在一个跨主机调度问题。使用叠加网络(overlay)解决不同主机上网络问题,所有的pod都在同一网段,service才能实现正常调度。当宿主机把请求送出去后,报文封装了两个ip,容器ip和宿主机网卡的ip,这样,容器才能实现跨主机间的网络访问。即k8s要求所有的pod在同一网段,而且可以使用这个网络直接通信。注意,service的ip和pod的ip不在同一网段,而且service的ip不是真的ip,即不配在某一个网卡上,仅仅是iptables上的某一个符号。因此service的ip是不能被ping通,service的ip被称为cluster ip, pod的ip称为 pod ip。
service作为k8s的对象有service的名称,service的名称,相当于是服务的名称,而名称可以被dns解析。service有两种类型,一种是只能pod内部访问,一种是可以供k8s外部访问。
每个应用的pod都要有专用的service进行调度。
存储卷,pod级别的卷,pod间存在卷的问题,因此,数据建议使用外部的专用卷,而不要使用挂载的本地容器的卷。当容器重建时,需要加载相同的卷。存储卷有四级概念,pv(持久卷),pvc(持久卷申请),volume(存储卷),volume mount(存储卷挂载)。
pod:
Pod指容器集,原子调度单元,一个Pod的所有容器运行于同一节点。k8s调度的目标是pod,,pod可以理解为容器的外壳,pod是k8s最小的调度单元。一个pod可以包含多个容器。一组联系非常紧密的容器组成pod,同一组pod共享networks,uts,storage,volumes,通过ipc机制进行通讯,跨pod的容器,需要借助于外部网络插件进行通讯,每一个pod有一个podIP。一个pod相当于是传统意义上的虚拟机。存储卷属于pod。一般而言,一个pod仅放一个容器。一个pod内的所有容器只能运行于同一node上。
k8s的最核心功能就是为了运行pod,其他组件是为了pod能够正常运行而执行的。
pod可以分为两类:
1.自主式pod,
2.控制器管理的pod
一个pod上有两类元数据,label 和 annotation
label:标签,对数据类型和程度要求严格,
annotation:注解,用于存储自己定义的复杂元数据,用来描述pod的属性
外部请求访问内部的pod,有三级转发,第一级,先到nodeip(宿主机ip)对应的端口,然后被转为cluster ip的service 端口,然后转换为PodIP的containerPort。
注意,在k8s集群外部还有一个调度器(load blance),这个调度器跟k8s没有关系,需要手动管理。这个调度器可借助keepalive实现高可用。
k8s的运行空间需要分区,即分成逻辑区域,如用于区分不同项目,每个逻辑区域为一个名词空间(usersapce),这里的名称空间为k8s特有的名称空间,和docker的名称空间有区别。用于隔离pod。实现了网络边界的隔离。提供了管理的边界。网络策略可以实现不同名称空间是否可以实现网络访问。默认情况下,不需要创建namespace。
6 k8s通信
service地址和pod地址在不同网段,service地址为虚拟地址,不配在pod上或主机上,外部访问时,先到节点网络,再打service网络,最后代理给pod网络。
同一pod内的多个容器通过lo通信
各pod间的通信,pod通过overlay network的隧道转发实现跨主机间报文转发,实现直接通信。
其中,叠加网络
1.一个数据包(或帧)封装在另一个数据包内;被封装的包转发到隧道端点后再被拆装。
2.叠加网络就是使用这种所谓“包内之包”的技术安全地将一个网络隐藏在另一个 网络中,然后将网络区段进行迁移。
pod和service间的通信,
CNI:容器网络集接口,网络解决方案,有三种不同ip,ip地址解释如下
node ip,节点网络,宿主机物理ip
cluster ip,集群ip,为service 网络,为固定的接入端口,即service组件的ip地址,不会配置在任何网络接口上,clusterIP定义在iptables或ipvs规则中。k8s集群自己管控和提供
pod ip ,属于pod网络,为pod提供ip地址,使得pod间直接通信,但是,集群间pod通信要借助于 cluster ip,pod和集群外通信,还要借助于node ip。pod网络要通过CNI规范借助于外部的虚拟化网络模型实现,为pod配置ip地址,使得pod间能够通信。
其中,虚拟化网络解决方案有如下几种较为著名的插件:
flannel:简单易用,不支持网络策略,配置本地网络协议栈,从而为运行在这个主机上的pod提供ip,但是,不能提供网络策略的功能。
project calico:支持网络策略和网络配置,默认基于BGP构建网络,实现直接通讯,三层隧道网络,目前生产主要使用这个模型
Canel:是flannel+calico的结合,用flannel提供网络,calico实现策略配置
kube-rote
weave network
k8s的网络模型如下
