对某一天的商品成交量的区域分布进行分析
成果:
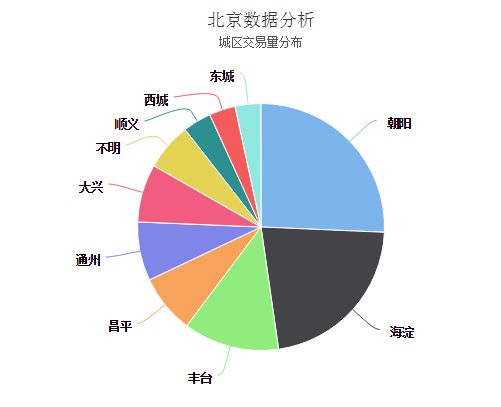
最终结果图
代码:
这个是惯例不解释了
import charts
from pymongo import MongoClient
from random import randint
client = MongoClient()
ceshi = client['ganji']
item_info = ceshi['info_details']
首先对自己的数据库做了一些改动,以备后面使用
# 因为没有time,所以就自己插入time,随机的,无非就是用一下数据库嘛
for i in item_info.find():
nums = randint(0,2)
# 其中update的行为是:如果元素存在则更新,如果不存在则新建
# nums是次数
item_info.update_one({'_id':i['_id']}, {'$set': {'nums': nums}})
# 有些place只有一个元素,这样调整一下变为'不明'
for i in item_info.find():
place = ['北京', '不明']
if i['place'][1] == '':
print(i['place'])
item_info.update_one({'_id':i['_id']}, {'$set': {'place': place}})
接下来就都是套路了,取数据塞进charts
def data_gen(data, nums):
pipeline = [
{'$match': {'$and':[{'time':{'$in':data}},{'nums':1}]}},
{'$group': {'_id':{'$slice':['$place', 1,1]},'counts':{'$sum':1}}},
{'$sort' : {'counts':-1}},
{'$limit': 10}
]
for i in item_info.aggregate(pipeline):
yield [i['_id'][0], i['counts']]
options = {
'chart' : {'zoomType':'xy'},
'title' : {'text': '北京数据分析'},
'subtitle': {'text': '城区交易量分布'},
}
series = [{
'type': 'pie',
'name': 'pie charts',
'data':[i for i in data_gen(['2016-08-08', '2016-08-14'],1)]
}]
charts.plot(series,options=options,show='inline')
新技能GET:
aggregate方法
这是mongodb的方法,只是在Python使用。
- 管道的概念
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
在这里我们用pipeline处理完要的信息,
pipeline = [
{'$match': {'$and':[{'time':{'$in':data}},{'nums':1}]}},
{'$group': {'_id':{'$slice':['$place', 1,1]},'counts':{'$sum':1}}},
{'$sort' : {'counts':-1}},
{'$limit': 10}
]
然后通过for i in item_info.aggregate(pipeline):把数据迭代出来
- 常用的几个命令
- '$match' --查询,需要同find()一样的参数
{'$match': {'$and':[{'time':{'$in':['2016-08-08', '2016-08-14']}},{'nums':1}]}}这个$and表示‘与’的作用,匹配多个条件,跟find({‘nums’:1, 'time':##},{})差不多的作用,但是后者不能选时间期限,记得前面有遇到没法选一段时间,$in就很好的解决了这个问题。match中第一个大括号内是匹配,第二个括号内是显示与否的选择:1为显示,0为不显示。但是这个管道有个行为:如果默认为空,则全部都显示;如果输入一个值为1的,则'_id'显示,其他信息不显示(如果想显示就设置为1) - '$group' --按照给定表达式组合结果
{'$group': {'_id':{'$slice':['$place', 1,1]},'counts':{'$sum':1}}},以place中的第一个元素为id,然后counts次数为1的个数

看图会比较直观
- '$sort' --按照给定的字段排序结果
{'$sort' : {'counts':-1}},以counts为排列依据,-1是降序排列,1是升序排列 - '$limit' --限制结果数量
{'$limit': 10}就是只显示10个结果 - 其他的筛选可以看上面的链接
整体思路:
1.知道要做什么图,然后需要什么数据,这里是需要什么样的数据,然后去组织这些数据
2.难点是怎么去筛选这些数据,所以努力的方向就是熟练使用管道,话说这些管道比find()好用多了
遇到的坑:
1.insert_one是给collection里面加入document,而不是更新document中的元素,当时想在document中加入‘nums’,已经手打出来,item_info.inset_one({'nums':num}),就差点击运行了。否则处理将是多麻烦的事情
2.其他倒是没有了,一句话:套路熟练就行了