图卷积神经网络GCN---空间卷积层代表作
Spatial-based ConvGNN
文章目录
- Spatial-based ConvGNN
- 1 Convolutional networks on graphs for learning molecular fingerprints
- 2 Column Networks for Collective Classification
- 3 Learning Convolutional Neural Networks for Graphs
- 4 Diffusion-Convolutional Neural Networks
- 5 Quantum-Chemical Insights from Deep Tensor Neural Networks
- 6 Interaction Networks for Learning about Objects, Relations and Physics
- 7 Geometric deep learning on graphs and manifolds using mixture model cnns
- 8 Molecular Graph Convolutions: Moving Beyond Fingerprints
- 9 Dynamic Edge-Conditioned Filters in Convolutional Neural Networks on Graphs
- 10 Neural Message Passing for Quantum Chemistry
- 11 Inductive Representation Learning on Large Graphs
- 12 Robust Spatial Filtering With Graph Convolutional Neural Networks
- 13 Large-Scale Learnable Graph Convolutional Networks
- 14 Signed Graph Convolutional Network
- 15 GeniePath: Graph Neural Networks with Adaptive Receptive Paths
- 16 Fast Learning with Graph Convolutional Networks via Importance Sampling
- 17 Stochastic Training of Graph Convolutional Networks with Variance Reduction
- 18 Adaptive Sampling Towards Fast Graph Representation Learning
- 参考文献
1 Convolutional networks on graphs for learning molecular fingerprints
[Duvenaud D, 2015, 1] 是最早对化学上使用图表示分子的文章之一。文章从常见的circular fingerprint作为类比出发,设计了一套类似circular fingerprint的neural graph fingerprint方法,能进行end-to-end学习。

2 Column Networks for Collective Classification
[Pham T, 2017, 2] 考虑了边上的信息:
- contextual features :
顶点 i i i的第 r r r个边:
c ⃗ i , r ( t ) = 1 ∣ N r i ∣ ∑ j ∈ N r i h ⃗ j ( t − 1 ) . (2.1) \vec{c}_{i,r}^{(t)} = \frac{1}{|\mathcal{N}_r{i}|} \sum_{j \in \mathcal{N}_r{i}} \vec{h}_j^{(t-1)}. \tag{2.1} ci,r(t)=∣Nri∣1j∈Nri∑hj(t−1).(2.1)
- 卷积 :
h ⃗ i ( t ) = g ( b ⃗ ( t ) + W ( t ) h ⃗ i ( t − 1 ) + 1 z ∑ r = 1 R V r ( t ) c ⃗ i , r ( t ) ) . (2.2) \vec{h}_i^{(t)} = g \left( \vec{b}^{(t)} + W^{(t)} \vec{h}_i^{(t-1)} + \frac{1}{z} \sum_{r=1}^{R} V_r^{(t)} \vec{c}_{i,r}^{(t)} \right). \tag{2.2} hi(t)=g(b(t)+W(t)hi(t−1)+z1r=1∑RVr(t)ci,r(t)).(2.2)
其中 z z z是超参。在最后的第 T T T步:
P ( y i = l ) = softmax ( b ⃗ l + W l h ⃗ i T ) . (2.3) P(y_i = l) = \text{softmax} \left( \vec{b}_l + W_l \vec{h}_i^T \right). \tag{2.3} P(yi=l)=softmax(bl+WlhiT).(2.3)
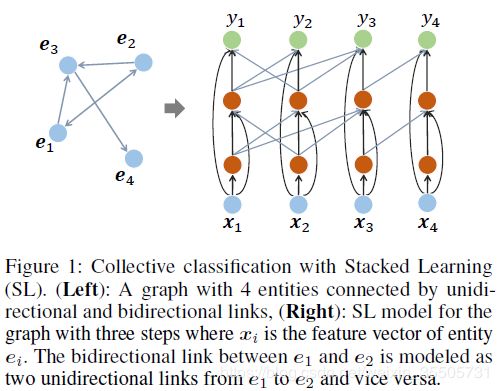
此外,式(2.1)可以加权和:
c ⃗ i , r ( t ) = ∑ j ∈ N r i α j h ⃗ j ( t − 1 ) . ∑ j α j = 1 (2.4) \vec{c}_{i,r}^{(t)} = \sum_{j \in \mathcal{N}_r{i}} \alpha_j \vec{h}_j^{(t-1)}. \qquad \sum_{j} \alpha_j = 1 \tag{2.4} ci,r(t)=j∈Nri∑αjhj(t−1).j∑αj=1(2.4)
原文还给出了跳跃连接:
h ⃗ ( t ) = α ⃗ ⊙ h ⃗ ~ ( t ) + ( 1 ⃗ − α ⃗ ) ⊙ h ⃗ ( t − 1 ) , α ⃗ = σ ( b ⃗ α ( t ) + W α ( t ) h ⃗ i ( t − 1 ) + 1 z ∑ r = 1 R V α r ( t ) c ⃗ i , r ( t ) ) . (2.5) \begin{aligned} \vec{h}^{(t)} &= \vec{\alpha} \odot \tilde{\vec{h}}^{(t)} + (\vec{1} - \vec{\alpha}) \odot \vec{h}^{(t-1)}, \\ \vec{\alpha} &= \sigma \left( \vec{b}_{\alpha}^{(t)} + W_{\alpha}^{(t)} \vec{h}_i^{(t-1)} + \frac{1}{z} \sum_{r=1}^{R} V_{\alpha r}^{(t)} \vec{c}_{i,r}^{(t)} \right). \end{aligned} \tag{2.5} h(t)α=α⊙h~(t)+(1−α)⊙h(t−1),=σ(bα(t)+Wα(t)hi(t−1)+z1r=1∑RVαr(t)ci,r(t)).(2.5)
3 Learning Convolutional Neural Networks for Graphs
[Niepert M, 2016, 3] 提出的PATCHY-SAN在图上使用传统的CNN。为了能用上CNN,对图结构进行了规范化:固定了图顶点的数量,固定了图顶点的邻居顶点的数量:
- 1.根据label排序后,选择固定的 w w w个顶点;
- 2.对于 w w w中的每个顶点,使用BFS算法选择至少 k k k个邻居顶点;
- 3.根据最佳的排序label选择 k k k给邻居顶点进行图规范化。
规范化后,得到顶点、边特征向量长度分别为 a v , a e a_v,a_e av,ae的两个张量 ( w , k , a v ) , ( w , k , k , a e ) (w,k,a_v),(w,k,k,a_e) (w,k,av),(w,k,k,ae)。将它们reshape成 ( w k , a v ) , ( w k 2 , a e ) (wk,a_v),(wk^2,a_e) (wk,av),(wk2,ae),将 a v , a e a_v,a_e av,ae视作通道数,在第一维度上分别做1-D卷积。
最佳的排序label :
最佳的排序label是指,任意两个图的图距离,和由label决定的邻接矩阵距离最小:
l ^ = arg min l E G [ ∣ d A ( A l ( G ) , A l ( G ′ ) ) − d G ( G , G ′ ) ∣ ] . \hat{l} = \arg \min_{l} \mathbb{E}_{\mathcal{G}} \left[ \left| d_A \left( A^l(G), A^l(G^{'})\right) - d_G \left( G, G^{'}\right) \right| \right]. l^=arglminEG[∣∣∣dA(Al(G),Al(G′))−dG(G,G′)∣∣∣].




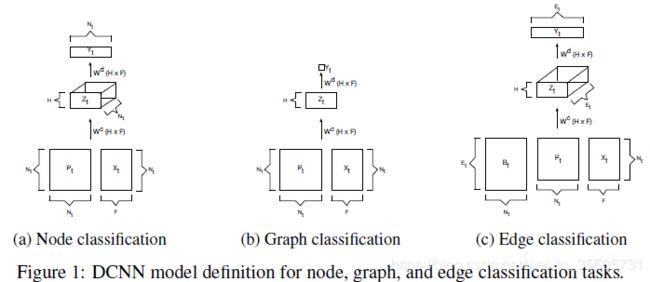
4 Diffusion-Convolutional Neural Networks
[Atwood J, 2016, 4] 根据邻接矩阵 A A A计算度归一化的转换矩阵 P t P_t Pt,它给出了从顶点 i i i跳到顶点 j j j的概率。
P t ∗ P_{t}^{*} Pt∗是 P t ∈ R N t × H × N t P_{t} \in \reals^{N_t \times H \times N_t} Pt∈RNt×H×Nt的幂级数和,对于顶点分类、图分类、边分类分别有 Z ∈ R N t × H × F , R H × F , R M t × H × F Z \in \reals^{N_t \times H \times F}, \reals^{H \times F}, \reals^{M_t \times H \times F} Z∈RNt×H×F,RH×F,RMt×H×F。 X t ∈ R N t × F X_t \in \reals^{N_t \times F} Xt∈RNt×F
- Node Classification :
Z t , i j k = f ( W j k c ∑ l = 1 N t P t , i j l ∗ X t , l k ) , 即: Z t = f ( W c ⊙ P t ∗ X t ) . (4.1) \begin{aligned} Z_{t,ijk} &= f \left( W_{jk}^{c} \sum_{l=1}^{N_t} P_{t,ijl}^{*} X_{t,lk} \right), \\ \text{即:} Z_t &= f \left( W^{c} \odot P_{t}^{*} X_{t} \right). \end{aligned} \tag{4.1} Zt,ijk即:Zt=f(Wjkcl=1∑NtPt,ijl∗Xt,lk),=f(Wc⊙Pt∗Xt).(4.1)
其中 W c ∈ R H × F W^c \in \reals^{H \times F} Wc∈RH×F。
输出:
Y ^ = arg max ( f ( W D ⊙ Z ) ) , P ( Y ∣ X ) = softmax ( f ( W D ⊙ Z ) ) . (4.2) \begin{aligned} \hat{Y} &= \arg \max \left( f(W^D \odot Z)\right), \\ \mathbb{P}(Y | X) &= \text{softmax} \left( f(W^D \odot Z)\right). \end{aligned} \tag{4.2} Y^P(Y∣X)=argmax(f(WD⊙Z)),=softmax(f(WD⊙Z)).(4.2)
- Graph Classification :
Z t = f ( W c ⊙ 1 ⃗ N t T P t ∗ X t N t ) . (4.3) Z_t = f \left( W^c \odot \frac{\vec{1}_{N_t}^T P_{t}^{*} X_{t}}{N_t} \right). \tag{4.3} Zt=f(Wc⊙Nt1NtTPt∗Xt).(4.3)
- Edge Classification and Edge Features :
用
A t ′ = ( A t B t T B t 0 ) (4.4) A_t^{'} = \begin{pmatrix} A_t & B_t^T\\ B_t & 0 \end{pmatrix} \tag{4.4} At′=(AtBtBtT0)(4.4)
计算 P t ′ P_t^{'} Pt′代替 P t P_t Pt做卷积取分类顶点或边。
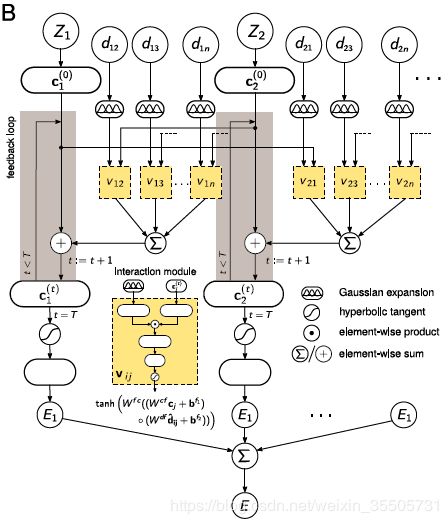
5 Quantum-Chemical Insights from Deep Tensor Neural Networks
[Schutt K T, 2017, 5] 聚合了顶点和边的信息。用高斯核对顶点 V V V构造距离矩阵 D = ( d ⃗ ^ i j ) ∣ V ∣ × ∣ V ∣ D=(\hat{\vec{d}}_{ij})_{|V| \times |V|} D=(d^ij)∣V∣×∣V∣。记每个顶点 v i ∈ V v_i \in V vi∈V的特征向量为 x ⃗ i \vec{x}_i xi,每条 e i j ∈ E e_{ij} \in E eij∈E上的特征向量为 y ⃗ i j \vec{y}_{ij} yij表示顶点 v j v_j vj对 v i v_i vi的作用。
- 顶点特征向量 x ⃗ i \vec{x}_i xi更新:
x ⃗ i ( t + 1 ) = x ⃗ i ( t ) + ∑ j ≠ i y ⃗ i j . (5.1) \vec{x}_i^{(t+1)} = \vec{x}_i^{(t)} + \sum_{j \neq i} \vec{y}_{ij}. \tag{5.1} xi(t+1)=xi(t)+j=i∑yij.(5.1)
- 边特征向量 y ⃗ i j \vec{y}_{ij} yij更新:
y ⃗ i j = tanh [ W f c ( ( W c f x ⃗ j + v ⃗ f 1 ) ⊙ ( W d f d ⃗ ^ i j + v ⃗ f 2 ) ) ] . (5.2) \vec{y}_{ij} = \tanh \left[ W^{fc} \left( \left( W^{cf} \vec{x}_j + \vec{v}^{f_1} \right) \odot \left( W^{df} \hat{\vec{d}}_{ij} + \vec{v}^{f_2} \right) \right) \right]. \tag{5.2} yij=tanh[Wfc((Wcfxj+vf1)⊙(Wdfd^ij+vf2))].(5.2)
6 Interaction Networks for Learning about Objects, Relations and Physics
[Battaglia P W, 2016, 6] 将图网络应用于自然科学中。IN模块为:
I N ( G ) = ϕ O ( a ( G , X , ϕ R ( m ( G ) ) ) ) ; m ( G ) = B = { b k } k = 1 , ⋯ , N R ϕ R ( B ) = E = { e k } k = 1 , ⋯ , N R a ( G , X , E ) = C = { c j } j = 1 , ⋯ , N O ϕ O ( C ) = P = { p j } j = 1 , ⋯ , N O (6.1) \begin{aligned} IN(G) &= \phi_{O} \left( a \left( G, X, \phi_{R} \left( m(G) \right) \right) \right);\\ m(G) &= B = \{b_k\}_{k = 1, \cdots, N_R} \\ \phi_{R}(B) &= E = \{e_k\}_{k = 1, \cdots, N_R} \\ a(G,X,E) &= C = \{c_j\}_{j = 1, \cdots, N_O} \\ \phi_{O}(C) &= P = \{p_j\}_{j = 1, \cdots, N_O} \\ \end{aligned} \tag{6.1} IN(G)m(G)ϕR(B)a(G,X,E)ϕO(C)=ϕO(a(G,X,ϕR(m(G))));=B={bk}k=1,⋯,NR=E={ek}k=1,⋯,NR=C={cj}j=1,⋯,NO=P={pj}j=1,⋯,NO(6.1)
记 N O N_O NO表示顶点的个数, N R N_R NR表示边(关系)的个数, D S , D R D_S,D_R DS,DR分别表示顶点、边的特征向量长度。那么 O ∈ R D S × N O O \in \reals^{D_S \times N_O} O∈RDS×NO表示所有顶点的特征列向量组成的矩阵, R a ∈ R D R × N R R_a \in \reals^{D_R \times N_R} Ra∈RDR×NR表示所有边的特征列向量组成的矩阵。将顶点编号,用0-1表示接受矩阵 R r ∈ R N O × N R R_r \in \reals^{N_O \times N_R} Rr∈RNO×NR和发射矩阵 R s ∈ R N O × N R R_s \in \reals^{N_O \times N_R} Rs∈RNO×NR。
用多层全连接实现 ϕ R , ϕ O \phi_R,\phi_O ϕR,ϕO:
B = m ( G ) = [ O R r ; O R s ; R a ] ∈ R ( 2 D S + D R ) × N R E = ϕ R ( B ) ∈ R D E × N R E ˉ = E R r T ∈ R D E × N O C = a ( G , X , E ) = [ O ; X ; E ˉ ] ∈ R ( D S + D X + D E ) × N O P = ϕ O ( C ) ∈ R D P × N O (6.2) \begin{aligned} B &= m(G) = [OR_r; OR_s; R_a] &\in \reals^{(2D_S + D_R) \times N_R} \\ E &= \phi_R(B) &\in \reals^{D_E \times N_R} \\ \bar{E} &= E R_r^T &\in \reals^{D_E \times N_O} \\ C &= a(G,X,E) = [O; X; \bar{E}] &\in \reals^{(D_S + D_X + D_E) \times N_O} \\ P &= \phi_O(C) &\in \reals^{D_P \times N_O} \\ \end{aligned} \tag{6.2} BEEˉCP=m(G)=[ORr;ORs;Ra]=ϕR(B)=ERrT=a(G,X,E)=[O;X;Eˉ]=ϕO(C)∈R(2DS+DR)×NR∈RDE×NR∈RDE×NO∈R(DS+DX+DE)×NO∈RDP×NO(6.2)
7 Geometric deep learning on graphs and manifolds using mixture model cnns
[F. Monti, 2017, 7] 提出了能再流形和图上混合使用的卷积。对于每个顶点 x x x的邻居点 y ∈ N ( x ) y \in \mathcal{N}(x) y∈N(x)都用伪坐标向量 u ⃗ ( x , y ) \vec{u}(x,y) u(x,y)将它们关联。定义由可学习参数 Θ \Theta Θ决定的权重函数 w ⃗ Θ ( u ⃗ ) = ( w 1 ( u ⃗ ) , ⋯ , w J ( u ⃗ ) ) \vec{w}_{\Theta}(\vec{u}) = (w_1(\vec{u}), \cdots, w_J(\vec{u})) wΘ(u)=(w1(u),⋯,wJ(u)):
D j ( x ) f = ∑ y ∈ N ( x ) w j ( u ⃗ ( x , y ) ) f ( y ) , j = 1 , ⋯ , J . (7.1) D_j(x)f = \sum_{y \in \mathcal{N}(x)} w_j(\vec{u}(x,y)) f(y), j = 1, \cdots, J. \tag{7.1} Dj(x)f=y∈N(x)∑wj(u(x,y))f(y),j=1,⋯,J.(7.1)
其中 J J J代表提取的patch的维数。原文里 w j ( u ⃗ ) w_j(\vec{u}) wj(u)选的是由可学习的 Σ j , μ ⃗ j \Sigma_j,\vec{\mu}_j Σj,μj决定的高斯核:
w j ( u ⃗ ) = exp ( − 1 2 ( u ⃗ − μ ⃗ j ) T Σ j − 1 ( u ⃗ − μ ⃗ j ) ) . (7.2) w_j(\vec{u}) = \exp \left( -\frac{1}{2} \left( \vec{u} - \vec{\mu}_j \right)^T \Sigma_j^{-1} \left( \vec{u} - \vec{\mu}_j \right) \right). \tag{7.2} wj(u)=exp(−21(u−μj)TΣj−1(u−μj)).(7.2)
那么卷积操作为:
( f ⋆ g ) ( x ) = ∑ j = 1 J g j D j ( x ) f . (7.3) \left( f \star g \right)(x) = \sum_{j=1}^{J} g_j D_j(x) f. \tag{7.3} (f⋆g)(x)=j=1∑JgjDj(x)f.(7.3)
8 Molecular Graph Convolutions: Moving Beyond Fingerprints
[Kearnes S, 2017, 8] 提出了图上建模的三个性质:
-
Property 1 (Order invariance). The output of the model should be invariant to the order that the atom and bond information is encoded in the input.
-
Property 2 (Atom and pair permutation invariance). The values of an atom layer and pair permute with the original input layer order. More precisely, if the inputs are permuted with a permutation operator Q Q Q, then for all layers x x x, y y y, A x A^x Ax and P y P^y Py are permuted with operator Q Q Q as well.
-
Property 3 (Pair order invariance). For all pair layers y y y, P ( a , b ) y = P ( b , a ) y P^y_{(a,b)} = P^y_{(b,a)} P(a,b)y=P(b,a)y
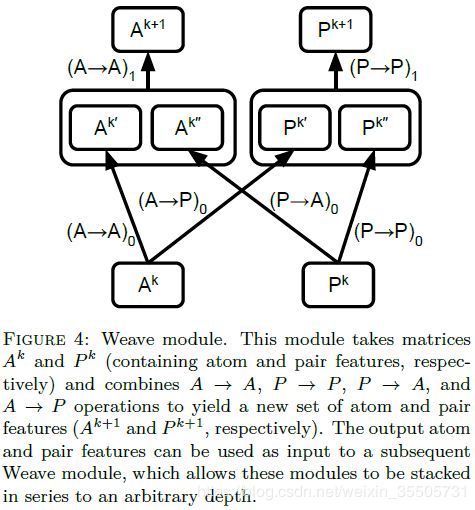
A x , p y A^x,p^y Ax,py分别表示原子层(atom)、键对层(pair)的第 x x x、 y y y层的值。网络由4个主要操作组成:
- ( A → A A \rightarrow A A→A) :
A a y = f ( A a x 1 , A a x 2 , ⋯ , A a x n ) . (8.1) A_a^y = f \left( A_a^{x1}, A_a^{x2}, \cdots, A_a^{xn} \right). \tag{8.1} Aay=f(Aax1,Aax2,⋯,Aaxn).(8.1)
- ( A → P A \rightarrow P A→P) :
P a , b y = g ( f ( A a x , A b x ) , f ( A b x , A a x ) ) . (8.2) P_{a,b}^y = g \left( f \left( A_{a}^{x}, A_{b}^{x} \right), f \left( A_{b}^{x}, A_{a}^{x} \right) \right). \tag{8.2} Pa,by=g(f(Aax,Abx),f(Abx,Aax)).(8.2)
- ( P → A P \rightarrow A P→A) :
A a y = g ( f ( P ( a , b ) x ) , f ( P ( a , c ) x ) , f ( P ( a , d ) x ) , ⋯ ) . (8.3) A_{a}^y = g \left( f \left(P_{(a,b)}^{x}\right), f \left(P_{(a,c)}^{x}\right), f \left(P_{(a,d)}^{x}\right), \cdots \right). \tag{8.3} Aay=g(f(P(a,b)x),f(P(a,c)x),f(P(a,d)x),⋯).(8.3)
- ( P → P P \rightarrow P P→P) :
P a , b y = f ( P a , b x 1 , P a , b x 2 , ⋯ , P a , b x n ) . (8.4) P_{a,b}^y = f \left( P_{a,b}^{x1}, P_{a,b}^{x2}, \cdots, P_{a,b}^{xn} \right). \tag{8.4} Pa,by=f(Pa,bx1,Pa,bx2,⋯,Pa,bxn).(8.4)
其中 f ( ⋅ ) , g ( ⋅ ) f(\cdot),g(\cdot) f(⋅),g(⋅)表示任意函数和任意的commutative函数。
9 Dynamic Edge-Conditioned Filters in Convolutional Neural Networks on Graphs
[Simonovsky M, 2017, 9] 用边的特征做构造顶点的卷积权重。对于边的特征 L ( j , i ) ∈ R s L(j,i) \in \reals^{s} L(j,i)∈Rs:
Θ j i l = F l ( L ( j , i ) ) ∈ R d l × d l − 1 . (9.1) \Theta_{ji}^{l} = F^l(L(j,i)) \quad \in \reals^{d_l \times d_{l-1}}. \tag{9.1} Θjil=Fl(L(j,i))∈Rdl×dl−1.(9.1)
卷积为:
X l ( i ) = 1 ∣ N ( i ) ∣ ∑ j ∈ N ( i ) F l ( L ( j , i ) ) X l − 1 ( j ) + b l , = 1 ∣ N ( i ) ∣ ∑ j ∈ N ( i ) Θ j i l X l − 1 ( j ) + b l . (9.2) \begin{aligned} X^l(i) &= \frac{1}{|\mathcal{N}(i)|} \sum_{j \in \mathcal{N}(i)} F^l(L(j,i)) X^{l-1}(j) + b^l,\\ &= \frac{1}{|\mathcal{N}(i)|} \sum_{j \in \mathcal{N}(i)} \Theta_{ji}^{l} X^{l-1}(j) + b^l. \end{aligned} \tag{9.2} Xl(i)=∣N(i)∣1j∈N(i)∑Fl(L(j,i))Xl−1(j)+bl,=∣N(i)∣1j∈N(i)∑ΘjilXl−1(j)+bl.(9.2)
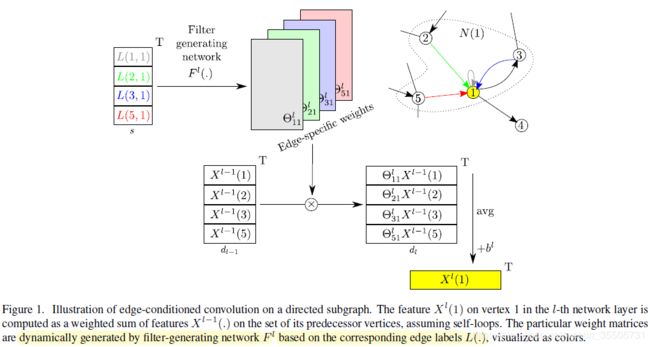
原文提到的池化方法:
- 1.下采样或者合并顶点
- 2.创建新的边缘结构 E ( h ) E^{(h)} E(h)并标记 L ( h ) L^{(h)} L(h)(所谓的约简)
- 3.将原来的顶点映射到新的顶点上 M ( h ) : V ( h − 1 ) → V ( h ) M^{(h)} : V^{(h-1)} \rightarrow V^{(h)} M(h):V(h−1)→V(h)。
10 Neural Message Passing for Quantum Chemistry
[Gilmer J, 2017, 10] 提出的是一个MPNN框架,将GNN分成了两个阶段:消息传播阶段和读出阶段。
- message passing phase :
消息传播阶段又由两部分组成,一是将顶点的邻居顶点和相连边的特征聚合 M t ( ⋅ ) M_t(\cdot) Mt(⋅)(message function),二是对顶点更新 U t ( ⋅ ) U_t(\cdot) Ut(⋅)(vertex update function):
m v ( t + 1 ) = ∑ w ∈ N ( v ) M t ( h v ( t ) , h w ( t ) , e v w ) , h v ( t + 1 ) = U t ( h v ( t ) , m v ( t + 1 ) ) . (10.1) \begin{aligned} m_v^{(t+1)} &= \sum_{w \in \mathcal{N}(v)} M_t \left( h_v^{(t)}, h_w^{(t)}, e_{vw} \right), \\ h_v^{(t+1)} &= U_t \left( h_v^{(t)}, m_v^{(t+1)} \right). \end{aligned} \tag{10.1} mv(t+1)hv(t+1)=w∈N(v)∑Mt(hv(t),hw(t),evw),=Ut(hv(t),mv(t+1)).(10.1)
- readout phase:
对图上每个顶点最后使用读出函数 R ( ⋅ ) R(\cdot) R(⋅):
y ^ = R ( { h v ( T ) ∣ v ∈ V G } ) . (10.2) \hat{y} = R \left( \{ h_v^{(T)} | v \in \mathcal{V}_G \}\right). \tag{10.2} y^=R({hv(T)∣v∈VG}).(10.2)
11 Inductive Representation Learning on Large Graphs
[Hamilton W L, 2017, 11] 提出的方法叫GraphSAGE,可扩展性更强,对于节点分类和链接预测问题的表现也比较突出。同样,GraphSAGE也可以用MPNN框架描述:
- 消息聚合:
h N ( v ) ( k ) ← AGGREGATE k ( h u ( k − 1 ) , ∀ u ∈ N ( v ) ) . (11.1) h_{\mathcal{N}(v)}^{(k)} \leftarrow \text{AGGREGATE}_k \left( h_u^{(k-1)}, \forall u \in \mathcal{N}(v) \right). \tag{11.1} hN(v)(k)←AGGREGATEk(hu(k−1),∀u∈N(v)).(11.1)
- 顶点特征更新:
h v ( k ) ← σ ( W ( k ) ⋅ CONCAT ( h v ( k − 1 ) , h N ( v ) ( k ) ) ) . h v ( k ) ← h v ( k ) ∥ h v ( k ) ∥ 2 , ∀ v ∈ V . (11.2) \begin{aligned} h_v^{(k)} & \leftarrow \sigma \left( W^{(k)} \cdot \text{CONCAT} \left( h_v^{(k-1)}, h_{\mathcal{N}(v)}^{(k)} \right)\right). \\ h_v^{(k)} & \leftarrow \frac{h_v^{(k)}}{\| h_v^{(k)} \|_2}, \quad \forall v \in \mathcal{V}. \end{aligned} \tag{11.2} hv(k)hv(k)←σ(W(k)⋅CONCAT(hv(k−1),hN(v)(k))).←∥hv(k)∥2hv(k),∀v∈V.(11.2)
- 读出函数:
z v ← h v ( K ) , ∀ v ∈ V . (11.3) z_v \leftarrow h_v^{(K)}, \quad \forall v \in \mathcal{V}. \tag{11.3} zv←hv(K),∀v∈V.(11.3)

原文给出了三种聚合函数:
- Mean aggregator:
h v ( k ) ← σ ( W ⋅ MEAN ( { h v ( k − 1 ) } ∪ { h u ( k − 1 ) , ∀ u ∈ N ( v ) } ) ) . (11.4) h_v^{(k)} \leftarrow \sigma \left( W \cdot \text{MEAN} \left( \{ h_v^{(k-1)} \} \cup \{ h_u^{(k-1)}, \forall u \in \mathcal{N}(v) \} \right) \right). \tag{11.4} hv(k)←σ(W⋅MEAN({hv(k−1)}∪{hu(k−1),∀u∈N(v)})).(11.4)
-
LSTM aggregator.
-
Pooling aggregator:
AGGREGATE k pool = max ( { σ ( W pool h u i k + b ) , ∀ u i ∈ N ( v ) } ) . (11.5) \text{AGGREGATE}_k^{\text{pool}} = \max \left( \left\{ \sigma \left( W_{\text{pool}} h_{u_i}^k + b \right), \forall u_i \in \mathcal{N}(v) \right\} \right). \tag{11.5} AGGREGATEkpool=max({σ(Wpoolhuik+b),∀ui∈N(v)}).(11.5)
其中 W pool W_{\text{pool}} Wpool是可学习的参数。
12 Robust Spatial Filtering With Graph Convolutional Neural Networks
[Such F P, 2017, 12] 提出的网络能够适用于同质或异质的图数据集。
对于不同的特征可以定义不同的邻接矩阵,将这些邻接矩阵组成 A = ( A 1 , ⋯ , A L ) ∈ R N × N × L \mathcal{A} = (A_1,\cdots, A_L) \in \reals^{N \times N \times L} A=(A1,⋯,AL)∈RN×N×L。
卷积核 H ∈ R N × N × C H \in \reals^{N \times N \times C} H∈RN×N×C为:
H ( c ) ≈ ∑ l = 1 L h l ( c ) A l . (12.1) H^{(c)} \approx \sum_{l=1}^{L} h_l^{(c)} A_l. \tag{12.1} H(c)≈l=1∑Lhl(c)Al.(12.1)
卷积操作为:
V out = ∑ c = 1 C H ( c ) V in ( c ) + b . (12.2) V_{\text{out}} = \sum_{c=1}^{C} H^{(c)} V_{\text{in}}^{(c)} + b. \tag{12.2} Vout=c=1∑CH(c)Vin(c)+b.(12.2)
图嵌入池化过程。为了得到 V e m b ∈ R N × N ′ V_{emb} \in \reals^{N \times N^{'}} Vemb∈RN×N′使用卷积核 H e m b ∈ R N × N × C × N ′ H_{emb} \in \reals^{N \times N \times C \times N^{'}} Hemb∈RN×N×C×N′:
V e m b ( n ′ ) = ∑ c C H e m b ( c , n ′ ) V i n ( c ) + b , V e m b ∗ = σ ( V e m b ) , V o u t = V e m b ∗ T V i n , A o u t = V e m b ∗ T A i n V e m b ∗ (12.3) \begin{aligned} V_{emb}^{(n^{'})} &= \sum_{c}^{C} H_{emb}^{(c,n^{'})} V_{in}^{(c)} + b, \\ V_{emb}^{*} &= \sigma (V_{emb}), \\ V_{out} &= V_{emb}^{*T} V_{in}, \\ A_{out} &= V_{emb}^{*T} A_{in} V_{emb}^{*} \end{aligned} \tag{12.3} Vemb(n′)Vemb∗VoutAout=c∑CHemb(c,n′)Vin(c)+b,=σ(Vemb),=Vemb∗TVin,=Vemb∗TAinVemb∗(12.3)
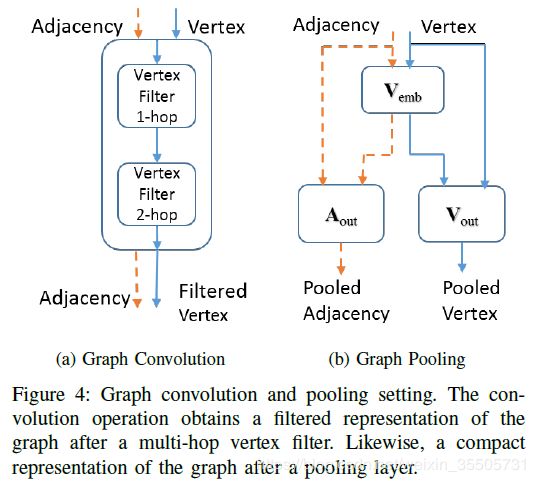
13 Large-Scale Learnable Graph Convolutional Networks
[Gao H, 2018, 13] 同样是在顶点特征向量上使用传统的CNN。
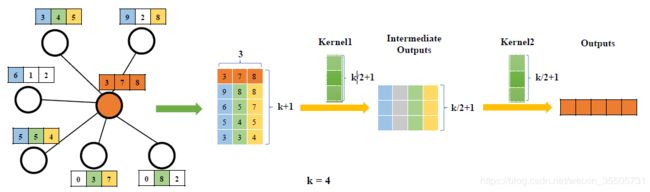
设第 l l l层的图顶点特征向量长度为 F l F_l Fl,每个顶点选择 k k k个邻居点。
卷积过程:
- 将每个顶点的邻居 N \mathcal{N} N的特征向量拼接成张量 R ∣ N ∣ × F l \reals^{|\mathcal{N}| \times F_l } R∣N∣×Fl;
- 将张量 R ∣ N ∣ × F l \reals^{|\mathcal{N}| \times F_l } R∣N∣×Fl的每列从大到小排序,然后截取前 k k k个,得 R k × F l \reals^{k \times F_l } Rk×Fl;
- 再和顶点的特征向量拼接为 R ( k + 1 ) × F l \reals^{ (k+1) \times F_l } R(k+1)×Fl;
- C O N V 1 : R ( k + 1 ) × F l → R ( k 2 + 1 ) × k CONV_1 : \reals^{ (k+1) \times F_l } \rightarrow \reals^{ (\frac{k}{2}+1) \times k } CONV1:R(k+1)×Fl→R(2k+1)×k;
- C O N V 2 : R ( k 2 + 1 ) × k → R 1 × F l + 1 CONV_2 : \reals^{ (\frac{k}{2}+1) \times k } \rightarrow \reals^{ 1 \times F_{l+1} } CONV2:R(2k+1)×k→R1×Fl+1。
14 Signed Graph Convolutional Network
[Derr T, 2018, 14] 提出了在有符号的图数据上建立神经网络。在无符号的图中卷积一般是聚合邻居顶点的信息,但是由于在有符号的图上有正有负,含义不同,需要将图分成平衡路径和非平衡路径。
分解利用了平衡理论,直观的讲就是:1)朋友的朋友,就是我的朋友,2)敌人的朋友就是我的敌人。 平衡的部分包含偶数条负连接,反之,包含奇数条负链接,被认为是不平衡。见下图
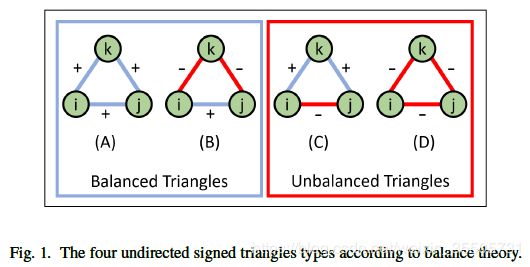
分解后,分别做卷积聚合,平衡部分:
h i B ( l ) = { σ ( W B ( 1 ) [ ∑ j ∈ N i + h j ( 0 ) ∣ N i + ∣ , h i ( 0 ) ] ) l = 1 ; σ ( W B ( l ) [ ∑ j ∈ N i + h j B ( l − 1 ) ∣ N i + ∣ , ∑ k ∈ N i − h k U ( l − 1 ) ∣ N i − ∣ , h i B ( l − 1 ) ] ) l ≠ 1. (14.1) \large h_i^{B(l)} = \begin{cases} \sigma \left( W^{B(1)} \left[ \sum_{j \in \mathcal{N}_{i}^{+}} \frac{h_j^{(0)}}{|\mathcal{N}_{i}^{+}|}, h_i^{(0)} \right] \right) \quad l = 1;\\ \sigma \left( W^{B(l)} \left[ \sum_{j \in \mathcal{N}_{i}^{+}} \frac{h_j^{B(l-1)}}{|\mathcal{N}_{i}^{+}|}, \sum_{k \in \mathcal{N}_{i}^{-}} \frac{h_k^{U(l-1)}}{|\mathcal{N}_{i}^{-}|}, h_i^{B(l-1)} \right] \right) \quad l \neq 1. \end{cases} \tag{14.1} hiB(l)=⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧σ(WB(1)[∑j∈Ni+∣Ni+∣hj(0),hi(0)])l=1;σ(WB(l)[∑j∈Ni+∣Ni+∣hjB(l−1),∑k∈Ni−∣Ni−∣hkU(l−1),hiB(l−1)])l=1.(14.1)
非平衡部分:
h i U ( l ) = { σ ( W U ( 1 ) [ ∑ j ∈ N i − h j ( 0 ) ∣ N i − ∣ , h i ( 0 ) ] ) l = 1 ; σ ( W U ( l ) [ ∑ j ∈ N i + h j U ( l − 1 ) ∣ N i + ∣ , ∑ k ∈ N i − h k B ( l − 1 ) ∣ N i − ∣ , h i U ( l − 1 ) ] ) l ≠ 1. (14.2) \large h_i^{U(l)} = \begin{cases} \sigma \left( W^{U(1)} \left[ \sum_{j \in \mathcal{N}_{i}^{-}} \frac{h_j^{(0)}}{|\mathcal{N}_{i}^{-}|}, h_i^{(0)} \right] \right) \quad l = 1;\\ \sigma \left( W^{U(l)} \left[ \sum_{j \in \mathcal{N}_{i}^{+}} \frac{h_j^{U(l-1)}}{|\mathcal{N}_{i}^{+}|}, \sum_{k \in \mathcal{N}_{i}^{-}} \frac{h_k^{B(l-1)}}{|\mathcal{N}_{i}^{-}|}, h_i^{U(l-1)} \right] \right) \quad l \neq 1. \end{cases} \tag{14.2} hiU(l)=⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧σ(WU(1)[∑j∈Ni−∣Ni−∣hj(0),hi(0)])l=1;σ(WU(l)[∑j∈Ni+∣Ni+∣hjU(l−1),∑k∈Ni−∣Ni−∣hkB(l−1),hiU(l−1)])l=1.(14.2)
读出:
z i ← [ h i B ( L ) , h i U ( L ) ] , ∀ u i ∈ U . (14.3) z_i \leftarrow [h_i^{B(L)}, h_i^{U(L)}], \quad \forall u_i \in \mathcal{U}. \tag{14.3} zi←[hiB(L),hiU(L)],∀ui∈U.(14.3)

15 GeniePath: Graph Neural Networks with Adaptive Receptive Paths
[Liu Z, 2018, 15] 提出了在广度和深度自适应选择顶点经行特征聚合。
- Adaptive Breadth:
基于GAT学习一跳邻居(隐)特征的重要性,决定继续探索的方向:
h i ( tmp ) = tanh ( W ( t ) T ∑ j ∈ N ( i ) ∪ { i } α ( h i ( t ) , h j ( t ) ) ⋅ h j ( t ) ) . (15.1) h_i^{(\text{tmp})} = \tanh \left( {W^{(t)}}^{T} \sum_{j \in \mathcal{N}(i) \cup \{ i \}} \alpha \left( h_i^{(t)}, h_j^{(t)} \right) \cdot h_j^{(t)} \right). \tag{15.1} hi(tmp)=tanh⎝⎛W(t)Tj∈N(i)∪{i}∑α(hi(t),hj(t))⋅hj(t)⎠⎞.(15.1)
其中 α ( h i ( t ) , h j ( t ) ) \alpha \left( h_i^{(t)}, h_j^{(t)} \right) α(hi(t),hj(t))是注意力机制:
α ( x , y ) = softmax y ( v T tanh ( W s T x + W d T y ) ) , softmax y ( ⋅ , y ) = exp f ( ⋅ , y ) ∑ y ′ exp f ( ⋅ , y ′ ) . (15.2) \begin{aligned} \alpha (x,y) &= \text{softmax}_y \left( v^T \tanh \left( W_s^T x + W_d^T y \right) \right), \\ \text{softmax}_y(\cdot, y) &= \frac{\exp f(\cdot,y)}{\sum_{y^{'}} \exp f(\cdot, y^{'})}. \end{aligned} \tag{15.2} α(x,y)softmaxy(⋅,y)=softmaxy(vTtanh(WsTx+WdTy)),=∑y′expf(⋅,y′)expf(⋅,y).(15.2)
- Adaptive Depth:
i i = σ ( W i ( t ) T h i ( tmp ) ) , f i = σ ( W f ( t ) T h i ( tmp ) ) , o i = σ ( W o ( t ) T h i ( tmp ) ) , C ~ = tanh ( W c ( t ) T h i ( tmp ) ) , C i ( t + 1 ) = f i ⊙ C i ( t ) + i i ⊙ C ~ , h t ( t + 1 ) = o i ⊙ tanh ( C i ( t + 1 ) ) . (15.3) \begin{aligned} i_i &= \sigma \left( {W_i^{(t)}}^{T} h_i^{(\text{tmp})} \right), \\ f_i &= \sigma \left( {W_f^{(t)}}^{T} h_i^{(\text{tmp})} \right), \\ o_i &= \sigma \left( {W_o^{(t)}}^{T} h_i^{(\text{tmp})} \right), \\ \widetilde{C} &= \tanh \left( {W_c^{(t)}}^{T} h_i^{(\text{tmp})} \right),\\ C_i^{(t+1)} &= f_i \odot C_i^{(t)} + i_i \odot \widetilde{C}, \\ h_t^{(t+1)} &= o_i \odot \tanh(C_i^{(t+1)}). \end{aligned} \tag{15.3} iifioiC Ci(t+1)ht(t+1)=σ(Wi(t)Thi(tmp)),=σ(Wf(t)Thi(tmp)),=σ(Wo(t)Thi(tmp)),=tanh(Wc(t)Thi(tmp)),=fi⊙Ci(t)+ii⊙C ,=oi⊙tanh(Ci(t+1)).(15.3)
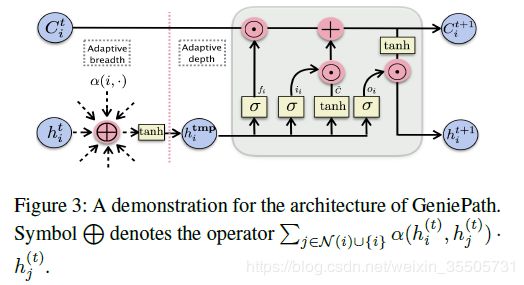
原文给出了一个变体:
μ i ( 0 ) = W x T X i , i i = σ ( W i ( t ) T CONCAT ( h i ( t ) , μ i ( t ) ) ) , f i = σ ( W f ( t ) T CONCAT ( h i ( t ) , μ i ( t ) ) ) , o i = σ ( W o ( t ) T CONCAT ( h i ( t ) , μ i ( t ) ) ) , C ~ = tanh ( W c ( t ) T CONCAT ( h i ( t ) , μ i ( t ) ) ) , C i ( t + 1 ) = f i ⊙ C i ( t ) + i i ⊙ C ~ , μ t ( t + 1 ) = o i ⊙ tanh ( C i ( t + 1 ) ) . \begin{aligned} \mu_i^{(0)} &= W_x^T X_i,\\ i_i &= \sigma \left( {W_i^{(t)}}^{T} \text{CONCAT} \left( h_i^{(t)}, \mu_i^{(t)} \right) \right), \\ f_i &= \sigma \left( {W_f^{(t)}}^{T} \text{CONCAT} \left( h_i^{(t)}, \mu_i^{(t)} \right) \right), \\ o_i &= \sigma \left( {W_o^{(t)}}^{T} \text{CONCAT} \left( h_i^{(t)}, \mu_i^{(t)} \right) \right), \\ \widetilde{C} &= \tanh \left( {W_c^{(t)}}^{T} \text{CONCAT} \left( h_i^{(t)}, \mu_i^{(t)} \right) \right),\\ C_i^{(t+1)} &= f_i \odot C_i^{(t)} + i_i \odot \widetilde{C}, \\ \mu_t^{(t+1)} &= o_i \odot \tanh(C_i^{(t+1)}). \end{aligned} μi(0)iifioiC Ci(t+1)μt(t+1)=WxTXi,=σ(Wi(t)TCONCAT(hi(t),μi(t))),=σ(Wf(t)TCONCAT(hi(t),μi(t))),=σ(Wo(t)TCONCAT(hi(t),μi(t))),=tanh(Wc(t)TCONCAT(hi(t),μi(t))),=fi⊙Ci(t)+ii⊙C ,=oi⊙tanh(Ci(t+1)).
16 Fast Learning with Graph Convolutional Networks via Importance Sampling
[Chen J, 2018, 16] 为了加快训练速度,提出了采样方法,即选取一部分顶点参与训练。
下图算法是随机采样:

下图是论文中提出的采用重要性采样,原文证明能有更小的方差:

其中的采样概率为:
q ( u ) = ∥ A ^ ( : , u ) ∥ 2 ∑ u ′ ∈ V ∥ A ^ ( : , u ′ ) ∥ 2 , u ∈ V . (16.1) q(u) = \frac{\| \hat{A}(:,u) \|^2}{ \sum_{u^{'} \in \mathcal{V}} \| \hat{A}(:,u^{'}) \|^2}, \quad u \in \mathcal{V}. \tag{16.1} q(u)=∑u′∈V∥A^(:,u′)∥2∥A^(:,u)∥2,u∈V.(16.1)
17 Stochastic Training of Graph Convolutional Networks with Variance Reduction
[Chen J, 2018, 17] 证明[Chen J, 2018, 16]的重要性采样方法在实践中并不好,因为有的顶点可能有很多采样点而另一些顶点可能没有采样点。
A ^ = A + I N , D ^ v v = ∑ u A ^ u v , P = D ^ − 1 2 A ^ D ^ − 1 2 \hat{A} = A + I_N, \hat{D}_{vv} = \sum_u \hat{A}_{uv}, P = \hat{D}^{-\frac{1}{2}} \hat{A} \hat{D}^{-\frac{1}{2}} A^=A+IN,D^vv=∑uA^uv,P=D^−21A^D^−21。 P ^ \hat{P} P^是 P P P的无偏估计 P ^ u v ( l ) = ∣ N ( u ) ∣ D ( l ) P u v \hat{P}_{uv}^{(l)} = \frac{|\mathcal{N}(u)|}{D^{(l)}} P_{uv} P^uv(l)=D(l)∣N(u)∣Puv,原文将 h v ( l ) h_v^{(l)} hv(l)分解成 h v ( l ) = Δ h v ( l ) + h ˉ v ( l ) h_v^{(l)} = \Delta h_v^{(l)} + \bar{h}_v^{(l)} hv(l)=Δhv(l)+hˉv(l)。原始的卷积中 h v ( l ) h_v^{(l)} hv(l)的递归计算导致计算量过大,[Chen J, 2018, 17]将每层得到的 h v ( l ) h_v^{(l)} hv(l)计算 h ˉ v ( l ) \bar{h}_v^{(l)} hˉv(l)用于保存做历史的近似。
( P H ( l ) ) u = ∑ v ∈ N ( u ) P u v Δ h v ( l ) + ∑ v ∈ N ( u ) P u v h ˉ v ( l ) , ≈ ∣ N ( u ) ∣ D ( l ) ∑ v ∈ N ^ ( u ) P u v Δ h v ( l ) + ∑ v ∈ N ( u ) P u v h ˉ v ( l ) . \begin{aligned} (PH^{(l)})_u &= \sum_{v \in \mathcal{N}(u)} P_{uv} \Delta h_v^{(l)} + \sum_{v \in \mathcal{N}(u)} P_{uv} \bar{h}_v^{(l)}, \\ &\approx \frac{|\mathcal{N}(u)|}{D^{(l)}} \sum_{v \in \hat{\mathcal{N}}(u)} P_{uv} \Delta h_v^{(l)} + \sum_{v \in \mathcal{N}(u)} P_{uv} \bar{h}_v^{(l)}. \end{aligned} (PH(l))u=v∈N(u)∑PuvΔhv(l)+v∈N(u)∑Puvhˉv(l),≈D(l)∣N(u)∣v∈N^(u)∑PuvΔhv(l)+v∈N(u)∑Puvhˉv(l).
也就是,随机选取近邻节点所得到的项是 Δ h v ( l ) \Delta h_v^{(l)} Δhv(l)。
卷积为:
Z ( l + 1 ) = ( P ^ ( l ) ( H ( l ) − H ˉ ( l ) ) + P H ˉ ( l ) ) W ( l ) (17.1) Z^{(l+1)} = \left( \hat{P}^{(l)} \left( H^{(l)} - \bar{H}^{(l)} \right) + P \bar{H}^{(l)} \right) W^{(l)} \tag{17.1} Z(l+1)=(P^(l)(H(l)−Hˉ(l))+PHˉ(l))W(l)(17.1)
Stochastic GCN:
- 随机选择一个小批量顶点集 V B ∈ V L \mathcal{V}_B \in \mathcal{V}_L VB∈VL;
- 建立一个仅包含当前小批量所需的激活 h v ( l ) h_v^{(l)} hv(l)和 h ˉ v ( l ) \bar{h}_v^{(l)} hˉv(l)的计算图;
- 通过等式(17.1)正向传播获得预测;
- 通过向后传播获取梯度,并通过SGD更新参数;
- 更新历史激活值。
18 Adaptive Sampling Towards Fast Graph Representation Learning
[Huang W, 2018, 18]
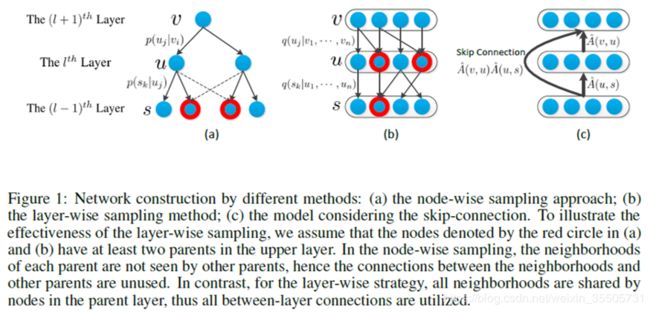
一般的卷积:
h ( l + 1 ) ( v i ) = σ ( ∑ j = 1 N a ^ ( v i , u j ) h ( l ) ( u j ) W ( l ) ) , i = 1 , ⋯ , N . (18.1) h^{(l+1)}(v_i) = \sigma \left( \sum_{j=1}^{N} \hat{a}(v_i,u_j) h^{(l)}(u_j) W^{(l)} \right), \quad i = 1, \cdots, N. \tag{18.1} h(l+1)(vi)=σ(j=1∑Na^(vi,uj)h(l)(uj)W(l)),i=1,⋯,N.(18.1)
- Node-Wise Sampling :
将式(18.1)改写为:
h ( l + 1 ) ( v i ) = σ ( ( ∑ j = 1 N a ^ ( v i , u j ) ) ( ∑ j = 1 N a ^ ( v i , u j ) ∑ j = 1 N a ^ ( v i , u j ) ) h ( l ) ( u j ) W ( l ) ) , , = N ( v i ) : = ∑ j = 1 N a ^ ( v i , u j ) σ ( N ( v i ) ( ∑ j = 1 N a ^ ( v i , u j ) N ( v i ) ) h ( l ) ( u j ) W ( l ) ) , = p ( u j ∣ v i ) : = a ^ ( v i , u j ) N ( v i ) σ ( N ( v i ) ( ∑ j = 1 N p ( u j ∣ v i ) h ( l ) ( u j ) ) W ( l ) ) , = σ ( N ( v i ) E p ( u j ∣ v i ) [ h ( l ) ( u j ) ] W ( l ) ) , i = 1 , ⋯ , N . (18.2) \begin{aligned} h^{(l+1)}(v_i) &= \sigma \left( \left( \sum_{j=1}^{N} \hat{a}(v_i,u_j) \right) \left( \sum_{j=1}^{N} \frac{\hat{a}(v_i,u_j)}{ \sum_{j=1}^{N} \hat{a}(v_i,u_j) } \right) h^{(l)}(u_j) W^{(l)} \right), ,\\ &\overset{N(v_i):= \sum_{j=1}^{N} \hat{a}(v_i,u_j)}{=} \sigma \left( N(v_i) \left( \sum_{j=1}^{N} \frac{\hat{a}(v_i,u_j)}{ N(v_i) } \right) h^{(l)}(u_j) W^{(l)} \right), \\ &\overset{p(u_j | v_i):= \frac{\hat{a}(v_i,u_j)}{ N(v_i) }}{=} \sigma \left( N(v_i) \left( \sum_{j=1}^{N} p(u_j | v_i) h^{(l)}(u_j) \right) W^{(l)} \right), \\ &= \sigma \left( N(v_i) \mathbb{E}_{p(u_j | v_i)} \left[ h^{(l)}(u_j) \right] W^{(l)} \right), \quad i = 1, \cdots, N.\\ \end{aligned} \tag{18.2} h(l+1)(vi)=σ((j=1∑Na^(vi,uj))(j=1∑N∑j=1Na^(vi,uj)a^(vi,uj))h(l)(uj)W(l)),,=N(vi):=∑j=1Na^(vi,uj)σ(N(vi)(j=1∑NN(vi)a^(vi,uj))h(l)(uj)W(l)),=p(uj∣vi):=N(vi)a^(vi,uj)σ(N(vi)(j=1∑Np(uj∣vi)h(l)(uj))W(l)),=σ(N(vi)Ep(uj∣vi)[h(l)(uj)]W(l)),i=1,⋯,N.(18.2)
使用Monte-Carlo sampling, μ p ( v i ) = E p ( u j ∣ v i ) [ h ( l ) ( u j ) ] \mu_p(v_i) = \mathbb{E}_{p(u_j | v_i)} \left[ h^{(l)}(u_j) \right] μp(vi)=Ep(uj∣vi)[h(l)(uj)]:
μ ^ p ( v i ) = 1 n ∑ j = 1 n h ( l ) ( u ^ j ) , u ^ j ∼ p ( u j ∣ v i ) . (18.3) \hat{\mu}_p(v_i) = \frac{1}{n} \sum_{j=1}^{n} h^{(l)} (\hat{u}_j), \quad \hat{u}_j \sim p(u_j | v_i). \tag{18.3} μ^p(vi)=n1j=1∑nh(l)(u^j),u^j∼p(uj∣vi).(18.3)
- Layer-Wise Sampling :
同样地:
h ( l + 1 ) ( v i ) = σ ( N ( v i ) E q ( u j ∣ v 1 , ⋯ , v n ) [ p ( u j ∣ v i ) q ( u j ∣ v 1 , ⋯ , v n ) h ( l ) ( u j ) ] W ( l ) ) , i = 1 , ⋯ , N . (18.4) h^{(l+1)}(v_i) = \sigma \left( N(v_i) \mathbb{E}_{q(u_j | v_1,\cdots,v_n)} \left[ \frac{p(u_j | v_i)}{q(u_j | v_1,\cdots,v_n)} h^{(l)}(u_j) \right] W^{(l)} \right), \quad i = 1, \cdots, N. \tag{18.4} h(l+1)(vi)=σ(N(vi)Eq(uj∣v1,⋯,vn)[q(uj∣v1,⋯,vn)p(uj∣vi)h(l)(uj)]W(l)),i=1,⋯,N.(18.4)
同样Monte-Carlo sampling, μ q ( v i ) = E q ( u j ∣ v 1 , ⋯ , v n ) [ p ( u j ∣ v i ) q ( u j ∣ v 1 , ⋯ , v n ) h ( l ) ( u j ) ] \mu_q(v_i) = \mathbb{E}_{q(u_j | v_1,\cdots,v_n)} \left[ \frac{p(u_j | v_i)}{q(u_j | v_1,\cdots,v_n)} h^{(l)}(u_j) \right] μq(vi)=Eq(uj∣v1,⋯,vn)[q(uj∣v1,⋯,vn)p(uj∣vi)h(l)(uj)]:
μ ^ q ( v i ) = 1 n ∑ j = 1 n p ( u ^ j ∣ v i ) q ( u ^ j ∣ v 1 , ⋯ , v n ) h ( l ) ( u ^ j ) , μ ^ j ∼ q ( u ^ j ∣ v 1 , ⋯ , v n ) . (18.5) \hat{\mu}_q(v_i) = \frac{1}{n} \sum_{j=1}^{n} \frac{p(\hat{u}_j | v_i)}{q(\hat{u}_j | v_1,\cdots,v_n)} h^{(l)} (\hat{u}_j), \quad \hat{\mu}_j \sim q(\hat{u}_j | v_1,\cdots,v_n). \tag{18.5} μ^q(vi)=n1j=1∑nq(u^j∣v1,⋯,vn)p(u^j∣vi)h(l)(u^j),μ^j∼q(u^j∣v1,⋯,vn).(18.5)
原文给了 q ( u j ) q(u_j) q(uj)最佳取法:
q ∗ ( u j ) = ∑ i = 1 n p ( u j ∣ v i ) ∣ g ( x ( u j ) ) ∣ ∑ j = 1 N ∑ i = 1 n p ( u j ∣ v i ) ∣ g ( x ( u j ) ) ∣ . (18.6) q^{*}(u_j) = \frac{ \sum_{i=1}^{n} p(u_j | v_i) | g(x(u_j)) | }{ \sum_{j=1}^{N} \sum_{i=1}^{n} p(u_j | v_i) | g(x(u_j)) | }. \tag{18.6} q∗(uj)=∑j=1N∑i=1np(uj∣vi)∣g(x(uj))∣∑i=1np(uj∣vi)∣g(x(uj))∣.(18.6)
其中 g ( ⋅ ) g(\cdot) g(⋅)是线性行数。
参考文献
-
1 Duvenaud D, Maclaurin D, Aguileraiparraguirre J, et al. Convolutional networks on graphs for learning molecular fingerprints[C]. neural information processing systems, 2015: 2224-2232.
-
2 Pham T, Tran T, Phung D, et al. Column Networks for Collective Classification[C]. national conference on artificial intelligence, 2017: 2485-2491.
-
3 Niepert M, Ahmed M H, Kutzkov K, et al. Learning Convolutional Neural Networks for Graphs[J]. arXiv: Learning, 2016.
-
4 Atwood J, Towsley D. Diffusion-Convolutional Neural Networks[C]. neural information processing systems, 2016: 1993-2001.
-
5 Schutt K T, Arbabzadah F, Chmiela S, et al. Quantum-chemical insights from deep tensor neural networks[J]. Nature Communications, 2017, 8(1): 13890-13890.
-
6 Battaglia P W, Pascanu R, Lai M, et al. Interaction networks for learning about objects, relations and physics[C]. neural information processing systems, 2016: 4509-4517.
-
7 F. Monti, D. Boscaini, J. Masci, E. Rodola, J. Svoboda, and M. M.Bronstein, “Geometric deep learning on graphs and manifolds using mixture model cnns,” in Proc. of CVPR, 2017, pp. 5115–5124.
-
8 Kearnes S, Mccloskey K, Berndl M, et al. Molecular graph convolutions: moving beyond fingerprints[J]. Journal of Computer-aided Molecular Design, 2016, 30(8): 595-608.
-
9 Simonovsky M, Komodakis N. Dynamic Edge-Conditioned Filters in Convolutional Neural Networks on Graphs[C]. computer vision and pattern recognition, 2017: 29-38.
-
10 Gilmer J, Schoenholz S S, Riley P, et al. Neural Message Passing for Quantum Chemistry[C]. international conference on machine learning, 2017: 1263-1272.
-
11 Hamilton W L, Ying Z, Leskovec J, et al. Inductive Representation Learning on Large Graphs[C]. neural information processing systems, 2017: 1024-1034.
-
12 Such F P, Sah S, Dominguez M, et al. Robust Spatial Filtering With Graph Convolutional Neural Networks[J]. IEEE Journal of Selected Topics in Signal Processing, 2017, 11(6): 884-896.
-
13 Gao H, Wang Z, Ji S, et al. Large-Scale Learnable Graph Convolutional Networks[C]. knowledge discovery and data mining, 2018: 1416-1424.
-
14 Derr T, Ma Y, Tang J, et al. Signed Graph Convolutional Network.[J]. arXiv: Social and Information Networks, 2018.
-
15 Liu Z, Chen C, Li L, et al. GeniePath: Graph Neural Networks with Adaptive Receptive Paths.[J]. arXiv: Learning, 2018.
-
16 Chen J, Ma T, Xiao C, et al. FastGCN: Fast Learning with Graph Convolutional Networks via Importance Sampling[C]. international conference on learning representations, 2018.
-
17 Chen J, Zhu J, Song L, et al. Stochastic Training of Graph Convolutional Networks with Variance Reduction[C]. international conference on machine learning, 2018: 941-949.
-
18 Huang W, Zhang T, Rong Y, et al. Adaptive Sampling Towards Fast Graph Representation Learning[C]. neural information processing systems, 2018: 4558-4567.