opencv中的双目标定
主要是对opencv例程中stereo_calib代码的阅读。
opencv采用的模型公式
针孔相机模型
![]()
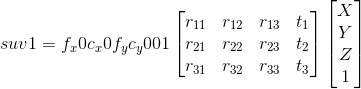
其中,X,Y,Z是世界系中的3D坐标;u,v是像素坐标系下的坐标;A是相机矩阵,包含相机内参;cx,cy是图像系的原点,通常位于图像中心;fx,fy是焦距,单位为像素单元。所以如果图像的尺度发生了变化,所有的这些参数都应当随之变化。
以上公式也可以写为:
![]()
![]()
![]()
![]()
考虑到畸变,通常指径向畸变和轻微的切向畸变:
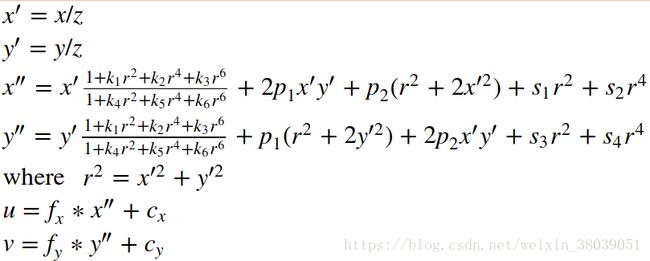
其中,k1, k2, k3, k4, k5, k6是径向畸变系数,主要由光学曲率的变化引起;p1, p2是切向畸变系数,主要由人工装配时光轴不共线引起;s1, s2, s3, s4是薄棱镜畸变系数,主要由光学镜头制造误差和成像敏感阵列的制造误差引起。
鱼眼相机模型
X是世界系下点的三维坐标,其在相机系下的坐标是
Xc = R X + T
R是旋转矩阵。鱼眼畸变:

畸变后的点的坐标:
![]() 其中,
其中, 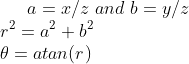
转换为像素坐标:
![]()
双目标定算法
图像会被分为多个尺度,分别在多个尺度之下检测角点,以增强准确程度和鲁棒性。
vector
vector
for( i = 0; i < nimages; i++ )
{
for( j = 0; j < boardSize.height; j++ )
for( k = 0; k < boardSize.width; k++ )
objectPoints[i].push_back(Point3f(k*squareSize, j*squareSize, 0));
}
之后利用findChessboardCorners函数对图像进行角点检测,若有符合boardSize的角点,将其存入对应的imagePoints中,其中涉及到的几种flag可以是一种或几种图像处理方式的组合,包括利用equalizeHist对图像gamma进行归一化、自适应阈值法二值化图像、棋盘角点的快速检测以及附加准则过滤错误quads(角点?)。具体使用方式自行查看calib3d进行了解。
之后利用cornerSubPix对检测出的角点精度进行改善,使之达到亚像素级别,cornerSubPix函数的原理可以查看博客。
有了目标点的空间初始三维坐标以及对应的亚像素级别的二维点之后,利用initCameraMatrix2D函数进行标定初始化,找到一个相机矩阵的初值,用来在后面迭代优化。
利用stereoCalibrate函数进行迭代优化,函数输出两个相机的相机矩阵、对应的畸变参数、镜头之间的旋转(由1相机到2相机)、平移矩阵、本质矩阵、基础矩阵、均方根误差RMS。也提供了若干flag进行算法细节的选择,有固定焦距、固定相机阵等等。注意,该函数是迭代优化函数,所以终止条件需要输入函数中。
利用标定出来的各项系数,undistortPoints用来恢复未畸变的点;computeCorrespondEpilines计算点对应的极线,可以利用极线计算极线误差。
//-----------------------------------------------------补充--------------------------------------------------------------//
欠的债总是要还的...没搞明白的地方终究还会卡住你,下面推导以下opencv中双目标定的函数涉及的公式:
先分别对双目相机标定内参,标定出的结果是:


![]()
单目标定的重投影误差在0.04像素左右。
之后利用标定好的单目内参去标定双目,利用stereoCalibrate函数,加上CALIB_FIX_INTRINSIC, 可得双目标定的结果有旋转矩阵![]() (从右目旋转到左目),平移矩阵(右目到左目),相应的本质矩阵(E_rl)、基础矩阵(F_rl)
(从右目旋转到左目),平移矩阵(右目到左目),相应的本质矩阵(E_rl)、基础矩阵(F_rl)
(标定结果中,平移矩阵的x值为 -baseline,猜测作者将右目设为参考系,据此推导得出的本质矩阵E_rl恰与标定结果反号,是因为P_r^T * E_rl * P_l = 0,所以正负号不影响吗?本质矩阵与理论偏差较大,是因为标定结果中的本质矩阵考虑了畸变等参数吗?求大神解惑!!)
在实际操作中,往往将左右图像进行调整,使左右两幅图像调整到理想位置,使极线水平,这样在极线搜索时仅搜索对应的行就好了,大大简化了程序的复杂程度。
利用stereoRectify函数,接口如下:
CV_EXPORTS_W void stereoRectify( InputArray cameraMatrix1, InputArray distCoeffs1,
InputArray cameraMatrix2, InputArray distCoeffs2,
Size imageSize, InputArray R, InputArray T,
OutputArray R1, OutputArray R2,
OutputArray P1, OutputArray P2,
OutputArray Q, int flags = CALIB_ZERO_DISPARITY,
double alpha = -1, Size newImageSize = Size(),
CV_OUT Rect* validPixROI1 = 0, CV_OUT Rect* validPixROI2 = 0 );
将双目标定得到的相机矩阵、畸变矩阵、双目之间的旋转、平移关系作为输入,函数输出P1, P2, R1, R2, Q以及对应的ROI区域。
其中P1、P2是经过校正后的相机矩阵,R1, R2是原图像到新图像的转换(旋转)矩阵,R1代表左目,R2为右目。Q矩阵用于将图像点反投影到世界3D坐标系中,这个函数中的flag只能为0或CALIB_ZERO_DISPARITY,若为0,函数会最大化公共场景,否则,函数会将左右两目的主点统一固定,使之在调整后的图像中具有相同的图像坐标;alpha 为0,则在调整后只保存有效ROI中的像素,若为1,不丢失任何原图像像素信息,但是会出现黑边。具体表达式如下:
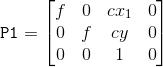
之后,利用initUndistortRectifyMap函数对原始图像进行投影,函数接口如下:
CV_EXPORTS_W void initUndistortRectifyMap( InputArray cameraMatrix, InputArray distCoeffs,
InputArray R, InputArray newCameraMatrix,
Size size, int m1type, OutputArray map1, OutputArray map2 );该函数利用之前得到的原始相机矩阵、畸变矩阵以及上一步得到的R,设定校正后的相机矩阵为理想的相机矩阵,从而得到两个转换矩阵。将其与原图像输入remap函数,得到转换后的图像,如下:
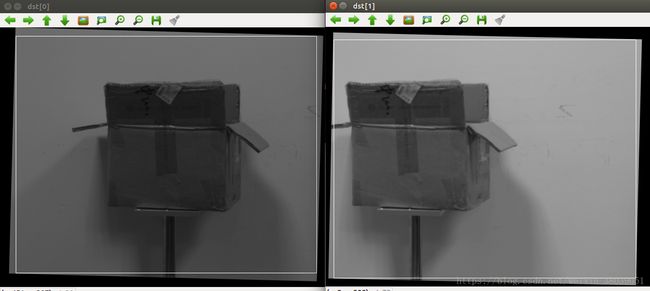
其中,白色框为对应的ROI区域,注意ROI位置、尺寸并不相等,将其截取出来操作的话需要再次计算对应的相机矩阵。否则,建议将ROI区域保存下来,在之后的运算中,仅对ROI区域中的像素点进行操作即可。