Hive -【group by】深刻理解,以及数据倾斜、与distinct区别(去重统计)
目录
1、数据准备
2、实例解读
扩展知识:group by带来的数据倾斜处理、与distinct的区别
环境
- CentOS 7.5
- Hadoop 2.6.5
- MariaDB 5.5.60
- Hive 1.2.2
1、【数据准备】
hive (mydb)> select * from page_view;
OK
page_view.pageid page_view.userid page_view.time
1 111 9:08:01
2 111 09:08:13
1 222 09:08:14
1 333 10:56:00
1 444 12:16:45
hive (mydb)> select * from page_user;
OK
page_user.userid page_user.age page_user.gender
hive (mydb)> select * from page_user;
OK
page_user.userid page_user.age page_user.gender
111 25 female
222 32 male
333 25 male
444 25 female
page_view表:是一个网站 或APP页面访问(或称浏览)表(也可以理解为 页面访问日志)。比如:第一行表示用户(userid)111访问了页面(pageid)1 ,访问时间是9:08:01。page_user表:是访问页面的用户(user)信息,字段有userid、age、gender。
需求:访问每个页面的用户信息(暂时 只需得到用户年龄)
1)创建一个新表用于存储页面id、用户年龄:pv_users
create table pv_users (pageid string,age string);
2)得到新表的数据:
insert overwrite table pv_users
select pv.pageid,pu.age
from page_view pv
join page_user pu
on (pv.userid=pu.userid);
3)查看新表的数据:
hive (mydb)> select * from pv_users;
OK
pv_users.pageid pv_users.age
1 25
2 25
1 32
1 25
1 25
很显然:
- 访问页面1的用户年龄有2个:25、32
- 访问页面2的用户年龄有1个:25
新增一个需求:每个页面上,统计访问的用户年龄。
select pageid,age,count(1) as cnt
from pv_users
group by pageid,age;
OK
pageid age cnt
1 25 3
1 32 1
2 25 1
2、正题:高级查询之 group by
group by:按照某些字段的值进行分组,有相同值的行 放到一起。
解读方式 1:SQL语句执行的逻辑过程
select *
from pv_users
group by pageid,age;
(tok_table_or_col pageid) (tok_table_or_col age)
1 25
1 32
2 25
-------------------------------
select age
from pv_users
group by age;
age
25
32

select age
from pv_users
group by age;
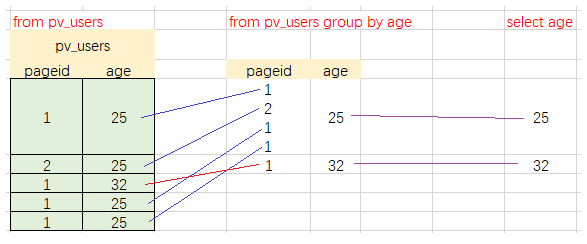
- 1)
from pv_users语句,结果是和pv_users一样的,即原来的表内容; - 2)
from pv_users group by age,以字段age为基准进行分组(group by),age值相同的行【合并】在一起,即分组(group)到一起,为了便于理解,可认为:若还有其他字段(如pageid)写到一个单元格中;- 针对一个单元格中有多个数据的情况,就可以使用【聚合函数】,如
count(age 或* 或1)、sum(字段); - 针对
group by 字段1, 字段2,...,那么就将字段1, 字段2,...看作一个整体。 - 参照下图
- 针对一个单元格中有多个数据的情况,就可以使用【聚合函数】,如
- 3)
select age,对上一步结果执行select语句,即 得到age列的数据。
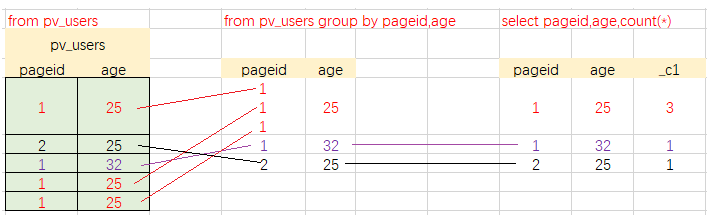
下方SQL语句可以一样的方式去理解,只不过要需要结合实际生产环境的场景来:
select pageid,age
from pv_users
group by pageid,age;
pageid age
1 25
1 32
2 25
-------------------------------
select pageid
from pv_users
group by pageid,age;
pageid
1
1
2
-------------------------------
select pageid,age,count(*)
from pv_users
group by pageid,age;
pageid age _c2
1 25 3
1 32 1
2 25 1
-------------------------------
select age,count(*)
from pv_users
group by pageid,age;
age _c1
25 3
32 1
25 1
-------------------------------
select age
from pv_users
group by pageid;
FAILED: SemanticException [Error 10025]: Line 1:7 Expression not in GROUP BY key 'age'
注意:select后面的非聚合列(即 普通列)必须是出现在group by中的,否则报错如上。【聚合列】,即进行聚合操作的列,比如:count(1),sel_expr(聚合操作)。
解读方式 2:通过MapReudce的执行原理来理解 group by:
select age
from pv_users ---->Map端执行
group by age; ---->Reduce端执行
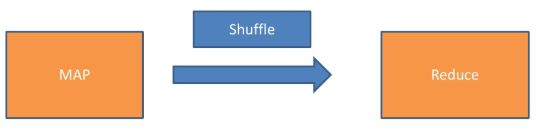
group by的执行会经过reduce操作,必然受限于reduce数量(set mapred.reduce.tasks=n;,不使用默认的话,可自行设置),输出文件个数跟reduce数量相同、文件大小跟reduce处理的数量有关。
explian命令,用于查看查询计划:
hive (mydb)> explain select pageid,age,count(1) as cnt
> from pv_users
> group by pageid,age;
OK
Explain
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: pv_users
Statistics: Num rows: 5 Data size: 20 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: pageid (type: string), age (type: string)
outputColumnNames: pageid, age
Statistics: Num rows: 5 Data size: 20 Basic stats: COMPLETE Column stats: NONE
Group By Operator
aggregations: count(1)
keys: pageid (type: string), age (type: string)
mode: hash
outputColumnNames: _col0, _col1, _col2
Statistics: Num rows: 5 Data size: 20 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: string), _col1 (type: string)
sort order: ++
Map-reduce partition columns: _col0 (type: string), _col1 (type: string)
Statistics: Num rows: 5 Data size: 20 Basic stats: COMPLETE Column stats: NONE
value expressions: _col2 (type: bigint)
Reduce Operator Tree:
Group By Operator
aggregations: count(VALUE._col0)
keys: KEY._col0 (type: string), KEY._col1 (type: string)
mode: mergepartial
outputColumnNames: _col0, _col1, _col2
Statistics: Num rows: 2 Data size: 8 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 2 Data size: 8 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Time taken: 0.078 seconds, Fetched: 48 row(s)
hive (mydb)>
【Hive-Group By(GroupByOperator类) 源码-官方】
【大佬博文-Hive 工作流程源码分析】
扩展知识:
1、问题:由于group by带来的数据倾斜(Skew In Data),导致性能变差
- 1)网络负载过重;
- 2)出现数据倾斜(可以通过
set hive.groupby.skewindata=true;参数来优化数据倾斜的问题,默认为false。但每个参数都是双刃剑),参数设置为true时,会生成的查询计划会有两个MR Job:即设置了这个参数后的MR执行流程- 第一个MR Job:Map的输出结果集 会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果。这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;
- 第二个MR Job:再根据预处理的数据结果按照Group By Key分布到Reduce 中(这个过程可以保证相同的Group By Key被分布到同一个Reduce中),最后完成最终的聚合操作。
2、group by 与distinct区别以及性能比较
distinct,译作:有区别的、不同的
Hive并不惧怕数据量有多大,而是数据倾斜。
数据:pv_users表
pv_users.pageid pv_users.age
1 25
2 25
1 32
1 25
1 25
-------------------------------------
select count(distinct age) as age_cnt
from pv_users;
age_cnt
2
-------------------------------------
select count(t.age) as age_cnt from
(
select age from pv_users group by age
) t;
age_cnt
2
当处理大量数据时(比如 近8亿条记录,总大小108GB。当然这测试时只有5条数据),从MR执行打印中可观察到:
- 使用
distinct(key),会将所有的key都shuffle到一个reducer中,就会发生数据倾斜。 distinct(key)会将key 的所有值都加载到内存中,数据量太大时,容易OOM。即count(distinct key)内存消耗大,但查询快。group by是将key排序,它的空间复杂度小,在时间复杂度允许的情况下,可以发挥他的空间复杂度优势。
因此,数据量太大时,不推荐用distinct,尽管可读性更好。
一条SQL语句中,同时有group by、distinct语句,执行顺序是:先group by,后distinct。