运行在Istio之上的Apache Kafka——基准测试
作者:Balint Molnar
编者按
本文是一篇Kafka的基准测试分析报告,作者详细介绍了测试的环境和配置选择,并在单集群、多集群、多云、混合云等各种场景下进行了A/B测试和性能分析,评估了Istio的引入对性能的影响情况。最后对作者所在公司Banzai Cloud的云产品进行了介绍。
我们的容器管理平台Pipeline以及CNCF认证的Kubernetes发行版PKE的一个关键特性是,它们能够在多云和混合云环境中无缝地构建并运行。虽然Pipeline用户的需求因他们采用的是单云方法还是多云方法而有所不同,但通常基于这些关键特性中的一个或多个:
多云应用管理
一个基于Istio的自动化服务网格,用于多云和混合云部署
基于Kubernetes federation v2(集群联邦)的联合资源和应用部署
随着采用基于Istio operator的多集群和多混合云的增加,对运行接入到服务网格中的分布式或去中心化的应用的能力的需求也增加了。我们的客户在Kubernetes上大规模运行的托管应用之一是Apache Kafka。我们认为,在Kubernetes上运行Apache Kafka最简单的方法是使用Banzai Cloud的Kafka spotguide来构建我们的Kafka operator。然而,到目前为止,我们的重点一直是自动化和操作单个集群Kafka部署。
TLDR
我们已经添加了在Istio上运行Kafka所需的支持 (使用Kafka 和 Istio operator,并通过 Pipeline编排).
在Istio上运行Kafka不会增加性能开销 (不同于典型的mTLS,在SSL/TLS上运行Kafka是一样的)。
使用 Pipeline,你可以创建跨多云和混合云环境的Kafka集群。
带有生产者ACK设置为all的3个broker、3个partition和3个replication因子场景的指标预览:
单集群结果
多集群结果

在Istio服务网格上运行Kafka
Kafka社区对如何利用更多的Istio功能非常感兴趣,例如开箱即用的Tracing,穿过协议过滤器的mTLS等。尽管这些功能有不同的需求,如Envoy、Istio和其他各种GitHub repos和讨论板上所反映的那样。大部分的这些特性已经在我们的Pipeline platform的Kafka spotguide中,包括监控、仪表板、安全通信、集中式的日志收集、自动伸缩,Prometheus警报,自动故障恢复等等。我们和客户错过了一个重要的功能:网络故障和多网络拓扑结构的支持。我们之前已经利用Backyards和Istio operator解决过此问题。现在,探索在Istio上运行Kafka的时机已经到来,并在单云多区、多云,特别是混合云环境中自动创建Kafka集群。

让Kafka在Istio上运行并不容易,需要时间以及在Kafka和Istio方面的大量专业知识。经过一番努力和决心,我们完成了要做的事情。然后我们以迭代的方式自动化了整个过程,使其在Pipeline platform上运行的尽可能顺利。对于那些想要通读这篇文章并了解问题所在的人——具体的来龙去脉——我们很快将在另一篇文章中进行深入的技术探讨。同时,请随时查看相关的GitHub代码库。
认知偏差
认知偏差是一个概括性术语,指的是信息的上下文和结构影响个人判断和决策的系统方式。影响个体的认知偏差有很多种,但它们的共同特征是,与人类的个性相一致,它们会导致判断和决策偏离理性的客观。
自从Istio operator发布以来,我们发现自己陷入了一场关于Istio的激烈辩论中。我们已经在Helm(和Helm 3)中目睹了类似的过程,并且很快意识到关于这个主题的许多最激进的观点并不是基于第一手的经验。当我们与对Istio的复杂性有一些疑问的人产生共鸣的时候——这正是我们开源了Istio operator和发布Backyards产品背后的根本原因——我们真的不同意大多数性能相关的争论。是的,Istio有很多“方便”的特性你可能需要也可能不需要,其中一些特性可能会带来额外的延迟,但是问题是和往常一样,这样做是否值得?
注意:是的,在运行一个包含大量微服务、策略实施和原始遥测数据过程的大型Istio集群时,我们已经看到了Mixer性能下降和其他的问题,对此表示关注;Istio社区正在开发一个
mixerless版本——其大部分功能会叠加到Envoy上。
做到客观,测量先行
在我们就是否向客户发布这些特性达成一致之前,我们决定进行一个性能测试。我们使用了几个在基于Istio服务网格上运行Kafka的测试场景来实现这点。你可能注意到,Kafka是一个数据密集型的应用,因此我们希望通过在依赖和不依赖Istio的两种情况下进行测试,以测量其增加的开销。此外,我们对Istio如何处理数据密集型应用很感兴趣,在这些应用程序中保持I/O吞吐量恒定,让所有组件负荷都达到了最大值。
我们使用了新版本的 Kafka operator,它提供了Istio服务网格的原生支持(版本 >=0.5.0)。
基准测试安装设置
为了验证我们的多云设置,我们决定先用各种Kubernetes集群场景测试Kafka:
单机群,3个broker,3个topic分3个partition,复制因子设置为3,关闭TLS
单机群,3个broker,3个topic分3个partition,复制因子设置为3,启用TLS
这些设置对于检查Kafka在选定环境中的实际性能是非常必要的,且没有潜在的Istio开销。
为了对Kafka进行基准测试,我们决定使用两个最流行的云提供商下的Kubernetes解决方案,Amazon EKS和Google GKE。我们希望最小化配置和避免任何潜在的CNI配置不匹配问题,因此决定使用云提供商管理的K8s发行版。
在另一篇文章中,我们将发布混合云Kafka集群的基准测试,其中会使用自己的Kubernetes发行版PKE。
我们想要模拟经常在Pipeline平台上的一个用例,因此部署了跨可用区的节点,Zookeeper和客户端也位于不同的节点中。
下面是使用到的实例类型:
AMAZON EKS

对于存储,我们请求了Amazon提供的
IOPS SSD(io1),在上面列出的实例中,它可以持续的达到437MB/s吞吐量。仅供参考,Amazon在一天剩下的时间里会在30分钟后对小型实例类型磁盘IO进行节流。你可以从 这里读到更多信息。
GOOGLE GKE

KAFKA和加载工具存储方面,我们设置了Google的pd-ssd,根据文档,它可以达到400MB/s。
Kafka方面,我们使用了3个topic,partition 数量和 replication 因子都设置为 3。基于测试的目的我们使用了默认的配置值,除了 broker.rack,min.insync.replicas。
在基准测试中,我们使用自定义构建的Kafka Docker映像banzaicloud/ Kafka:2.12-2.1.1。它使用Java 11、Debian并包含2.1.1版本的Kafka。Kafka容器配置为使用4个CPU内核和12GB内存, Java的堆大小为10GB。
banzaicloud/kafka:2.12-2.1.1 镜像是基于 wurstmeister/kafka:2.12-2.1.1 镜像的, 但为了SSL库的性能提升,我们想用 Java 11 代替 Java 8。
加载工具使用 sangrenel生成,它是一个基于Go语言实现的Kafka性能工具,配置如下:
512 字节的消息尺寸
不压缩
required-acks 设置为 all
worker设置为20个
为了得到准确的结果,我们使用Grafana 仪表板1860的可视化NodeExporter指标监控整个架构。我们不断增加生产者的数量,直到达到架构或Kafka的极限。
为基准测试创建的架构已经超出了这篇文章的范围,但是如果你对重现它感兴趣,我们建议使用Pipeline管道和访问Kafka-operator 的GitHub获取更多细节。
基准测试环境
在讨论Kafka的基准测试结果之前,我们还对环境进行了测试。由于Kafka是一个极端数据密集型的应用,我们特别关注在测试磁盘速度和网络性能;根据经验,这是对Kafka影响最大的指标。网络性能方面,我们使用了一个名为iperf的工具。创建了两个相同的基于Ubuntu的Pod:一个是服务端,另一个是客户端。
在 Amazon EKS 上我们测量到了
3.01 Gbits/sec的吞吐量。在 Google GKE 上我们测量到了
7.60 Gbits/sec的吞吐量。
为了确定磁盘速度,我们在基于容器的Ubuntu系统下使用了一个叫 dd的工具。
在Amazon EKS上我们测量的结果是
437MB/s(这与Amazon为该实例和ssd类型提供的内容完全一致)。在Google GKE上我们测量的结果是
400MB/s(这也与谷歌为其实例和ssd类型提供的内容一致)。
现在我们对环境有了更好的理解,让我们继续讨论部署到Kubernetes的Kafka集群。
单集群
Google GKE
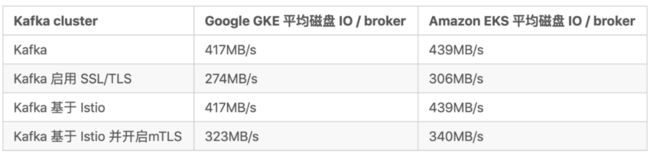
Kafka部署在Kubernetes - 没有Istio
在我们得到关于EKS的结果之后,我们对Kafka在GKE上达到 417MB/s 的磁盘吞吐量并不感到惊讶。该性能受到实例的磁盘IO限制。

Kafka基于Kubernetes 开启TLS - 没有Istio
一旦我们为Kafka打开SSL/TLS,和预期的一样并且已经多次基准测试过,就会出现性能损失。众所周知,Java的SSL/TLS(插件化的)实现性能很差,而且它在Kafka中导致了性能问题。不过在最近的实现版本(9+)中有一些改进,因此我们升级到了Java 11。结果如下:
吞吐量
274MB/s,大约30% 吞吐量损失和没有TLS比较,包速率有大约两倍的提升

Kafka基于Kubernetes - 且有Istio
我们急切地想知道在Istio中部署和使用Kafka时是否会增加开销和有性能损失。结果很有希望:
没有性能损失
CPU方面略有增加
Kafka基于Kubernetes - 有Istio并开启mTLS
接下来,我们在Istio上启用了mTLS,并重用了相同的Kafka部署。结果比基于Kubernetes的Kafka并开启了SSL/TLS的要好。
吞吐量
323MB/s,大约20% 吞吐量损失和没有TLS比较大约有2倍的包速率提升

Amazon EKS
Kafka基于Kubernetes - 没有Istio
在这个配置下我们得到了一个相当可观的写入速度439MB/s,如果消息的尺寸是512字节,那么它就是892928消息/秒。事实上,我们压榨出了AWS r5.4xlarge这种实例的磁盘吞吐量最大的负荷能力。
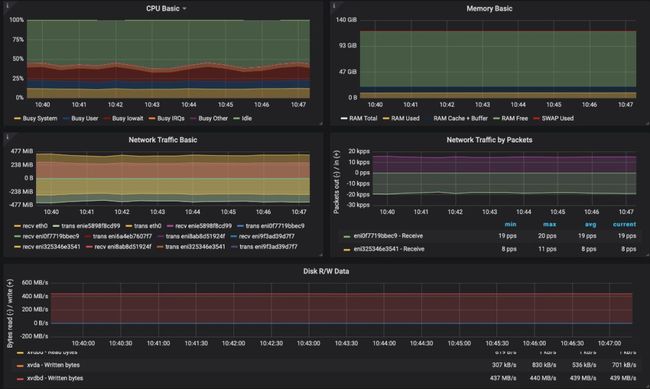
Kafka基于Kubernetes并开启TLS - 没有Istio
一旦我们再次为Kafka打开SSL/TLS,并进行了多次基准测试,就像预期的那样会出现性能损失。Java的SSL/TLS实现性能问题在EKS上和GKE一样存在。不过正如我们之前所说,最近的版本已经有了改进。因此我们将其升级到Java 11,结果如下:
吞吐量
306MB/s,大约30% 吞吐量损失和没有TLS比较,大约2倍包速率提升

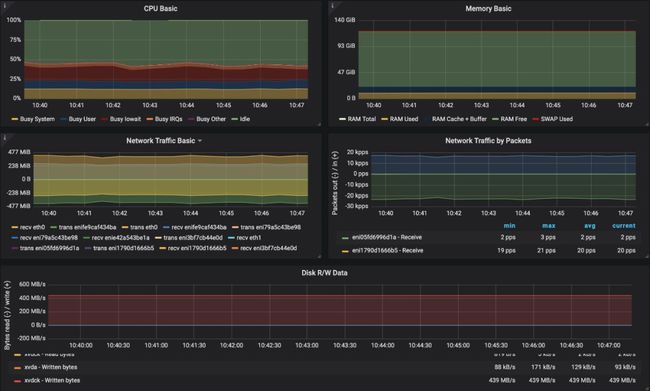
Kafka基于Kubernetes - 有Istio
和以前一样,结果也很好:
没有性能损失
CPU使用方面有轻微增加
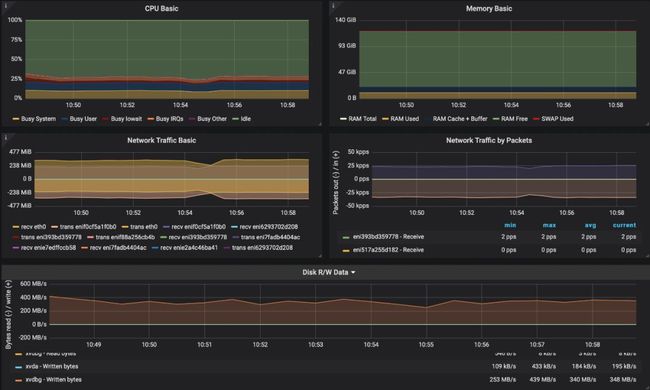
Kafka基于Kubernetes - 有Istio且开启mTLS
接下来,我们在Istio上启用了mTLS,并重用了相同的Kafka部署。同样的,结果比Kafka在Kubernetes上直接使用SSL/TLS要好。
吞吐量
340MB/s,大约20%吞吐量损耗包速率增加了,但低于两倍
额外的尝试 - Kafka基于Linkerd(关闭mTLS)
我们测试了所有可用的情况,所以想用Linkerd再尝试一下。为什么?因为我们可以做到。虽然我们知道Linkerd在可用的功能方面不能满足客户期望,但我们仍然想尝试一下。我们的期望值很高,但得出的数字给了我们一个沉重的教训,也提醒了我们什么是认知偏见。
吞吐量
246MB/s

单集群结论
在继续多集群基准测试之前,让我们评估一下已有的数据。可以看出,在这些环境和场景中,使用没有mTLS的服务网格不会影响Kafka的性能。在到达网络、内存或CPU瓶颈前,底层磁盘的吞吐量限制了Kafka的性能。
无论是使用Istio还是Kafka自己的SSL/TLS库,都会使Kafka的性能降低约20%。它也增加了一点CPU负载,并使通过网络传输的数据包数量增加了一倍。
注意,在使用
iperf进行架构测试期间,仅在网络上启用mTLS就会导致大约20%的性能损耗。
跨“racks”(云区域)topic复制的多集群场景
在这个设置中,我们模拟的内容更接近于生产环境,为了重用测试环境,我们坚持使用相同配置的AWS或Google实例,但是在不同的区域上设置了多个集群(跨云区域的topic复制)。请注意,无论我们跨单个云提供商使用这些集群,还是跨多个云或混合云来使用这些集群,流程都应该是相同的。从Backyards和Istio operator的角度来看没有区别,我们支持3种不同的网络拓扑。
其中一个集群比另一个集群更大,它包含两个broker和两个Zookeeper节点。而另一个集群则各有一个节点。注意,在支持mTLS的单网格多集群环境中是绝对必要的。此外我们还设置min.insync.replicas为3,让生产者应答所有耐用性相关的请求。
网格是全自动的由 Istio operator提供。
Google GKE <-> GKE
在这个场景中,我们创建了一个单网格/单Kakfa集群,它跨越两个Google云区域:eu-west1和eu-west4
吞吐量
211MB/s

Amazon EKS <-> EKS
在这个场景中,我们创建了一个单网格/单Kakfa集群,它横跨两个AWS区域:eu-north1和eu-west1
吞吐量
85MB/s

Google GKE <-> EKS
在这个场景中,我们创建了一个单一的Istio网格,它跨越多个集群和多个云,形成了一个单一的Kafka集群(Google云区域是europe-west-3, AWS的区域是eu-central-1)。正如预期的那样,结果要差得多。
吞吐量
115MB/s

多集群结论
从基准测试来看,我们可以放心地说,在多云单网格环境中使用Kafka是值得的。人们选择在Istio上部署Kafka这种环境的原因各不相同,但像Pipeline这样易于安装,有额外的安全收益,具有可伸缩性和耐用性,基于本地负载均衡和更多特性的工具是一个完美的选择。
正如前面提到的,本系列后续的文章之一是关于基准测试/运维一个自动伸缩的混云Kafka集群,警报和缩放事件基于Prometheus的指标(我们对基于Istio指标的多个应用进行类似的自动伸缩,并通过网格部署和观察它们——阅读这篇之前的文章了解详情:基于自定义Istio指标的Pod水平自动伸缩。)
关于 Backyards
Banzai Cloud的Backyards是一个支持多云和混合云的服务网格平台,用于构建现代应用程序。基于Kubernetes,我们的Istio operator和Pipeline平台支持跨实体数据中心和5个云环境的灵活性、可移植性和一致性。使用简单但功能极其强大的UI和CLI,自己体验自动金丝雀发布、流量转移、路由、安全服务通信、深度的可观察性等特性。
关于 Pipeline
Banzai Cloud的 Pipeline提供了一个平台,允许企业开发、部署和扩展基于容器的应用程序。它利用了最好的云组件比如Kubernetes,为开发人员和运营团队创建了一个高效、灵活的环境。强大的安全评估——多认证后端,细粒度的授权、动态安全管理、使用TLS,漏洞扫描,静态代码分析,CI/CD等特性的组件之间的自动化安全通信,Pipeline是一个0层(tier zero)特性的平台,努力使所有企业实现自动化。
关于 Banzai Cloud
Banzai Cloud 正在改变私有云的构建方式:简化复杂应用程序的开发、部署和扩展,并将Kubernetes和云原生技术的强大功能交到各地的开发人员和企业手中。
推荐阅读
在Play with Kubernetes平台上以测试驱动的方式部署Istio
(译)Istio 1.0 的实战测试
Istio和Linkerd的CPU基准测试报告
第六届 Service Mesh Meetup 广州站
8 月 11 日(本周日),广州见!报名地址:https://tech.antfin.com/community/activities/781

