图像搜索(三)局部特征SIFT
转载:https://www.cnblogs.com/zhulongchao/p/6444178.html
(这里是Java实现,在用Python实现时我的SIFT报错,解决不了。。。很扎心了,在继续解决中。。)
图像搜索三-局部特征SIFT
基于全局特征的传统特征对图像的精细识别能力都不强,即强调鲁棒性大于区分性,这对我们实际应用,尤其是追求同款的应用非常不利;一般有两种方式来避开全局性特征的不利,一是从局部出发,即点特征,二是采用多个局部来确定整体,即点集。
SIFT介绍
SIFT的出现是图像特征描述子研究领域一项里程碑式的工作,该算法的实质是在不同的尺度空间上查找关键点(特征点),并计算出关键点的方向。SIFT所查找到的关键点是一些十分突出,不会因光照,仿射变换和噪音等因素而变化的点,如角点、边缘点、暗区的亮点及亮区的暗点等,这种点数量丰富,而且具有强大的不变性(如平移、缩放、旋转和光照等),非常适合在拍照情况下进行匹配。
当然,SIFT特征的抽取过程也很复杂,充分体现了由人工定义规则的精美和细致(与非人工/智能相对而言),我们可以简单的划分为如图所示的几个步骤: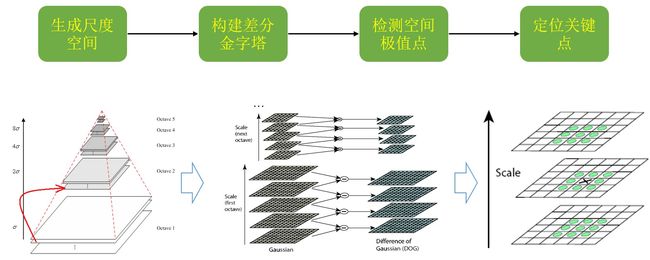
尺度空间理论目的是模拟图像数据的多尺度特征,尺度空间使用高斯金字塔表示。尺度规范化的LoG算子具有真正的尺度不变性,使用LoG能够很好地找到图像中的兴趣点,但是需要大量的计算量,所以Lowe使用DoG图像的极大极小值近似寻找特征点。
极值点的寻找
在实际计算时,使用高斯金字塔每组中相邻上下两层图像相减,得到高斯差分图像,进行极值检测。关键点是由DoG空间的局部极值点组成的,关键点的初步探查是通过同一组内各DoG相邻两层图像之间比较完成的。为了寻找DoG函数的极值点,每一个像素点要和它所有的相邻点比较,看其是否比它的图像域和尺度域的相邻点大或者小。中间的检测点和它同尺度的8个相邻点和上下相邻尺度对应的9×2个点共26个点比较,以确保在尺度空间和二维图像空间都检测到极值点,达到良好的尺度不变性;下图表示了金字塔的建立过程以及差分检测的示意:
以上方法检测到的极值点是离散空间的极值点,需要通过拟合三维二次函数来精确确定关键点的位置和尺度,同时去除低对比度的关键点和不稳定的边缘响应点(因为DoG算子会产生较强的边缘响应,这一步本质上要去掉DoG局部曲率非常不对称的像素),以增强匹配稳定性、提高抗噪声能力。
接下来,要在检测到的关键点基础上得到特征描述子,如下图所示:
极值点的方向性
为了使描述符具有旋转不变性,需要利用图像的局部特征为给每一个关键点分配一个基准方向。使用图像梯度的方法求取局部结构的稳定方向。在完成关键点的梯度计算后,使用直方图统计邻域内像素的梯度和方向。梯度直方图将0~360度的方向范围分为36个柱(bins),其中每柱10度。直方图的峰值方向代表了关键点的主方向,(为简化,图中只画了八个方向的直方图)
通过以上步骤,对于每一个关键点,可以得到三个信息:位置、尺度以及方向。接下来就是为每个关键点建立一个描述符,用一组向量将这个关键点描述出来,使其不随各种变化而改变,比如光照变化、视角变化等等。这个描述子不但包括关键点,也包含关键点周围对其有贡献的像素点,并且描述符应该有较高的独特性,以便于提高特征点正确匹配的概率。
SIFT描述子是关键点邻域高斯图像梯度统计结果的一种表示。通过对关键点周围图像区域分块,计算块内梯度直方图,生成具有独特性的向量,这个向量是该区域图像信息的一种抽象,具有唯一性。
特征向量形成后,为了去除光照变化的影响,需要对它们进行归一化处理,对于图像灰度值整体漂移,图像各点的梯度是邻域像素相减得到,所以也能去除。得到的描述子向量为归一化后的特征向量。同时非线性光照,相机饱和度变化对造成某些方向的梯度值过大,而对方向的影响微弱。因此设置门限值(向量归一化后,一般取0.2)截断较大的梯度值。然后,再进行一次归一化处理,提高特征的鉴别性。
通过以上各步骤后,最终对每个feature形成一个448=128维的描述子,每一维都可以表示4*4个格子中一个的scale/orientation,这个特征就是我们需要使用的神通广大的SIFT特征。
看到上述简化后的步骤,估计不熟悉的诸位,也会头晕脑大;其实这些步骤也是使用统计直方图+最大值等最通用的原理得到,也会遵循Code+pooling的路线。
索引及查询过程
索引及查询过程:基于局部特征的图像搜索系统的整体流程如下图所示,其中左边为离线流程,右边为在线过程.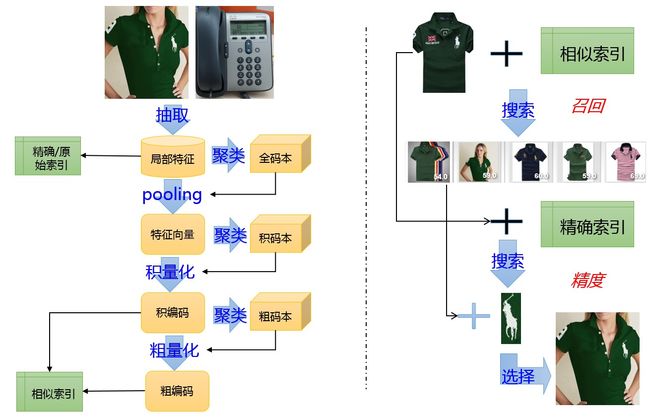
Pooling:这个过程主要是把不定数量的特征向量投影到固定维数的向量空间去,同时保留向量相似度能代表原始图像的相似度,最常用的算法有BOW(Bag of Word),VLAD,SCP以及我们使用的LLC(Locality-constrained Linear Coding)。其过程如下图,其中左边是基于SC的过程,右上是LLC与两者的区别,与VQ相比,引入软件量化,即一对多而不是一对一的量化,减少误差,与SC相比主要体现在引入了locality的约束,即不仅仅是sparse要满足,非零的系数还应该赋值给相近的dictionary terms;
同时,如果码本空间足够大,那么得到的pooling向量就会比较稀疏,而稀疏特征又有很多好处,如
- 已经提到过的重建性能好;
- sparse有助于获取salient patterns of descripors;
- image statistics方面的研究表明image patches都是sparse signals;
- biological visual systems的研究表明信号的稀疏特征有助于学习;
- 稀疏的特征更加线性可分等,所以大家可以看到,以后的高维特征数不胜数,DL等得到的特征也经常是稀疏的。
在Pooling上,LLC选用的是最大值而不是均值,同时作了L2归一,其过程可见右下图(大家是不是很眼熟,这个过程图怎么与CNN这么像啊?事实上正是,各特征提取手段千变万换,其实最基本的过程都有相似性的)。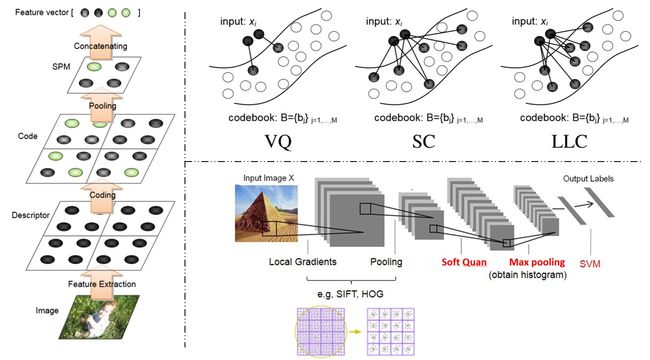
在线精确搜索重排:在通过相似检索(主要为了保证召回)后得到TopK的结果以后,为了更精确的得到结果,需要进行精确匹配并去噪重排,其大致过程有4个步骤:
1.距离匹配
我们需要以输入Query图的特征点去匹配相似搜索的结果(比如Top1K),这个过程运算量其实也非常大(比方说Query图有200个点,目标图有1000 * 200个点,每个点维度为128【未优化】,使用欧氏距离来匹配,运算量可以估计出来);我们在三方面进行了优化,一是如先所说特征本身的优化(包括维度、点数、数值范围等),二是距离计算采用指令优化,三是可以使用量化算法来降低匹配数据量,如下图
在上图的左边,根据全量化码本,我们在离线处理中为每个图都建立一个微型量化索引;在在线的时候,首先为Query中的每一个特征点与码本进行一次比较,得到排序的码本中心,然后根据这个序列,对每张候选图中的点从近到远进行比较,当比较点数量达到总点数量的一定比例(如10%)时,停止比较,得到最近的点即为有效点。通过这种方法可以将距离运算量降低一个数量级,同时召回在0.93以上。
要注意的是,距离最近的点对必须是相互的才有效,即你离我最近,同时我离你也最近;
2.匹配对选取
并不是所有的匹配对都是真正有效的对,虽然你离我是最近,但这个最近也非常远,则需要抛弃掉;比较实际的方法是,将最近的和最远的距离值取出来作为基准空间,然后选取离最近一定范围内的比例作为候选点集;
3. 去噪
以上方法得到匹配集,大部分都是噪声匹配,因为该匹配没有考虑空间位置,因此会存在误匹配。
去噪的算法也有好几种,其中比较经典的是RANSAC算法,但是该算法使用全局迭代的逻辑,效率很难达到要求,一对图需要秒级的消耗,在实际中难以应用,因此为了提高匹配的精度,我们通过另一种快速的方式,即空间校验的方法来去除误匹配。该空间匹配算法利用SIFT特征的位置,角度和尺度信息来滤除不兼容的匹配点。对待查询图像和目标图像的每一对匹配点,将图像坐标归一化到各自特征对应的角度和尺度,然后对空间进行划分来滤除不匹配的点。下图表示以点2的特征为基准的坐标归一化,其中红色箭头表示特征的角度,红色圆表示特征的尺度。如下图,由于点5的相对坐标位置在两幅图中发生了变化,其会被滤除。
待查询图像 目标图像
4.相似分计算
最后剩下的匹配点对,才可以参与相似分的计算,这个分采用倒数开方相加的方法得到。
SIFT一经提出,就迅速成为局部特征描述的主流,在部分拷贝图像检索、刚体检索中发挥了巨大的作用,并在此基础上扩展了各种其它描述子,如SURF、Color-SIFT、Affine-SIFT、Dense-SIFT、PCA-SIFT、Kaze等,各有优缺点,大家可以搜索之。
但局部特征也有不少缺点:
- 速度相对比较慢,对空间要求大,在线和离线压力大;
- 对非常模糊、光滑的物体抽取不出特征,或特征量过少;
- 变形过大(如褶子非常多的衣服),背景噪声过多,抽取的特征本身也是噪声点的概率大;
- 局部特征本身是从底向上的特征,反应的是图像局部的信息,对上层抽象、图像全局能力描述不够(如我们想搜一种“短袖、圆领的T恤”这种概念无法做到)
知识储备
角点
尺度规范化的LoG算子
Lowe使用DoG图像
高斯差分图像
拟合三维二次函数
图像灰度
归一化处理
非线性光照
相机饱和度
coding+pooling线路
BOW(Bag of Word),VLAD,SCP以及我们使用的LLC(Locality-constrained Linear Coding)
sparse
匹配与选取
RANSAC
相似分计算
SURF、Color-SIFT、Affine-SIFT、Dense-SIFT、PCA-SIFT、Kaze