【CV06】LeNet,AlexNet,VGG,GoogLeNet,ResNet 简介
文章目录
- CNN的架构设计
- 1. LeNet-5
- 2. AlexNet
- 3. VGG
- 4. Inception and GoogLeNet
- 5. ResNet
CNN的架构设计
卷积神经网络的元素(例如卷积和池化层)相对容易理解。在实践中使用卷积神经网络的挑战性部分是如何设计最能使用这些简单元素的模型架构。
学习如何设计有效的卷积神经网络架构的一种有用方法是研究成功的网络。2012年至2016年间,大规模视觉识别挑战赛(ILSVRC)进行了大量的CNN研究和应用,这一挑战促进了计算机视觉任务的发展,以及卷积神经网络模型的创新。
1. LeNet-5
Yann LeCun等人在1998年题为《基于梯度学习的文档识别(Gradient-Based Learning Applied to Document Recognition)》的论文中最早提出了卷积神经网络LeNet-5。(获取PDF)。
该系统被开发用于手写字符识别问题,并在MNIST标准数据集上实现了大约99.2%的分类精度(0.8%的错误率)。在广泛系统中,该网络为Graph Transformer Networks的核心技术。
这篇论文比较长,最值得关注的部分是第二部分,描述了LeNet-5架构。论文将网络描述为具有7层灰度图像输入,其形状为32×32,即MNIST数据集中的图像大小。
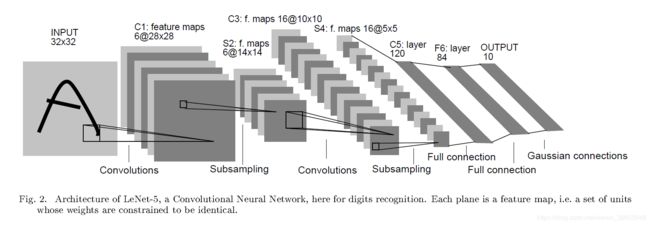
卷积层和池化层重复交叠组合多层,仍然是当今设计和使用卷积神经网络的常见模式。该架构第一层使用少量的filter,有6个5×5的filter。在合并之后(称为子采样层),另一个卷积层有更多的filter,之后的卷积层更小,有16个5×5的filter,再次合并。在这两个卷积和池化层中,趋势是filter数量的增加。
与如今的网络相比,filter的数量很少,但是随着网络深度的增加,filter数量的增长趋势仍然是该技术在现代使用中的一种普遍模式。
如今,通过全连接层对特征图进行展平(flatten)以及对提取的特征进行解释和分类也仍然是常见的模式。在现代术语中,网络模型的最后部分通常被称为分类器,而模型中较早的卷积层和池化层被称为特征提取器。
可以总结出与现代模型相关的架构的关键信息:
- 固定尺寸的输入图像;
- 将卷积层和池层分组为块;
- 架构中卷积层和池化层的交叠重复;
- 随着网络深度的增加,filter的数量也会增加;
- 架构可以设置不同的特征提取器和分类器。
2. AlexNet
Alex Krizhevsky等人在2012年发表的论文ImageNet Classification with Deep Convolutional Neural Networks可以归因于对神经网络的重新激发兴趣以及深度学习在许多计算机视觉应用中的主导地位的开始。该论文表明,无需使用当时流行的无监督预训练技术,就可以开发出深度有效的端到端模型来解决具有挑战性的问题。
AlexNet 在每个卷积层之后都使用整流线性激活函数(ReLU)作为非线性函数,而不是使用S形函数(例如logistic或tanh),直到那个时候才通用。同样,在输出层中使用了softmax激活函数,现在该函数是神经网络进行多类分类的主要条件。
LeNet-5中使用的平均池化替换为最大池化,在这种情况下,发现重叠池化的性能优于当今常用的非重叠池(即池操作的步幅与池操作的大小相同 ,例如2 x 2像素)。为了解决过拟合问题,在模型的分类器部分的全连接层之间使用了新提出的Dropout方法,以改善泛化误差。
AlexNet的体系结构很深,并扩展了LeNet-5建立的某些模式。在这种情况下,分为两个并行部分以在当时的GPU硬件上进行训练。

该模型在特征提取部分有5个卷积层,分类器部分有3层全连接层。输入图像通过三个颜色通道的尺寸固定为224×224。在每个卷积层中使用的过滤器数量方面,在LeNet中看到的过滤器数量随着深度的增加而增加的模式在大多数情况下都遵循,即大小为96、256、384、384、256。 filter的尺寸随深度减小,尺寸从11×11减小到5×5,在较深的层减小到3×3。现在通常使用较小尺寸的filter,例如5×5和3×3。
使用数据增强对模型进行了训练,从而人为地增加了训练数据集的大小,并为模型提供了更多的机会来学习不同方向的相同特征。
可以总结出与现代模型相关的架构的关键信息:
- 卷积层使用ReLU激活函数,输出使用softmax函数;
- 使用最大池化代替平均池化;
- 在全连接的层之间使用Dropout正则化;
- 卷积层的特征图直接馈送到另一个卷积层;
- 使用数据增强。
3. VGG
牛津大学的Visual Geometry Group提出了称为VGG的网络模型(论文原文),与先前两种网络模型的第一个重要区别是使用了大量的尺寸较小的filter。具体而言,使用步幅为1尺寸为3×3和1×1的filter,不同于LeNet-5中大尺寸的filter,以及步幅很大,尺寸相对较大的filter的AlexNet。
在从AlexNet中大多数(不是全部)卷积层之后使用了最大池化层,但是所有池化都以2×2的大小和相同的步幅执行,这也已成为常用的标准。具体而言,VGG网络在最大池化层之前堆叠多层卷积层。基本原理是,具有较小filter的堆叠卷积层近似具有较大filter的单层卷积层的效果,例如,具有3×3filter的三层堆叠卷积层与具有7×7filter的单层卷积层类似。
另一个重要的区别是使用了大量的filter。filter的数量随模型深度的增加而增加,从相对较大的64个开始,在模型的特征提取部分结束时增加到128、256、512个。
开发和评估了该网络结构的多种变体,在性能和深度方面最常提及两种。它们以层数命名:分别是VGG-16和VGG-19。下表中,最右边的两列表示该架构的VGG-16和VGG-19版本中配置的filter的数量。

可以总结出与现代模型相关的架构的关键方面,如下所示:
- 使用非常小的卷积滤波器,例如3×3和1×1,步幅为1;
- 使用大小为2×2且跨度相同的最大池;
- 池化层之前,使用多层卷积层堆叠;
- 卷积层池化层的重复交叠配置;
- 开发非常深的(16和19层)模型。
4. Inception and GoogLeNet
Christian Szegedy等人在2015年的论文Going Deeper with Convolutions中提出了使用卷积层的重要创新。作者提出了Inception v1的网络架构,以及一个名为GoogLeNet的特定模型,该模型在2014年ILSVRC中取得了最佳成绩。
inception模型的关键创新称为 inception module。这是具有不同大小的filter(例如1×1、3×3、5×5)的并行卷积层和3×3的最大池化层的block,然后将其结果合并在一起。下面是一个示例。
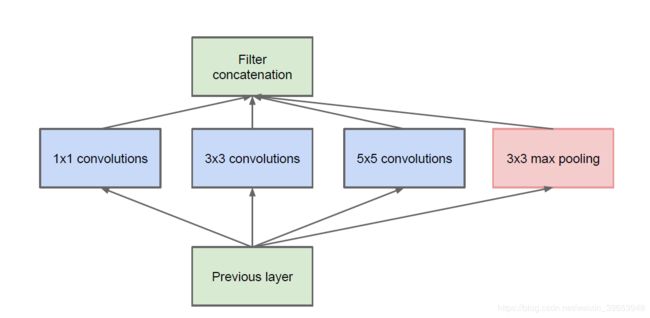
初始模型的一个问题是filter(深度或通道)的数量开始快速增加,尤其是在堆叠初始block时。在数量较多的filter上,使用较大尺寸的filter(例如3和5)进行卷积在计算上很昂贵。为了解决这个问题,使用1×1卷积层来减少初始模型中的filter数量。特别是在3×3和5×5卷积层之前和池化层之后。下图取自论文,显示了对初始模块的更改。

初始模型中的第二个重要设计决策是将输出连接到模型中的不同节点。这是通过从主网络创建经过训练以进行预测的小型支路输出网络来实现的。目的是在深度模型的不同点上提供来自分类任务的附加误差信号,以解决梯度消失问题。然后在训练后将这些小型输出网络删除。
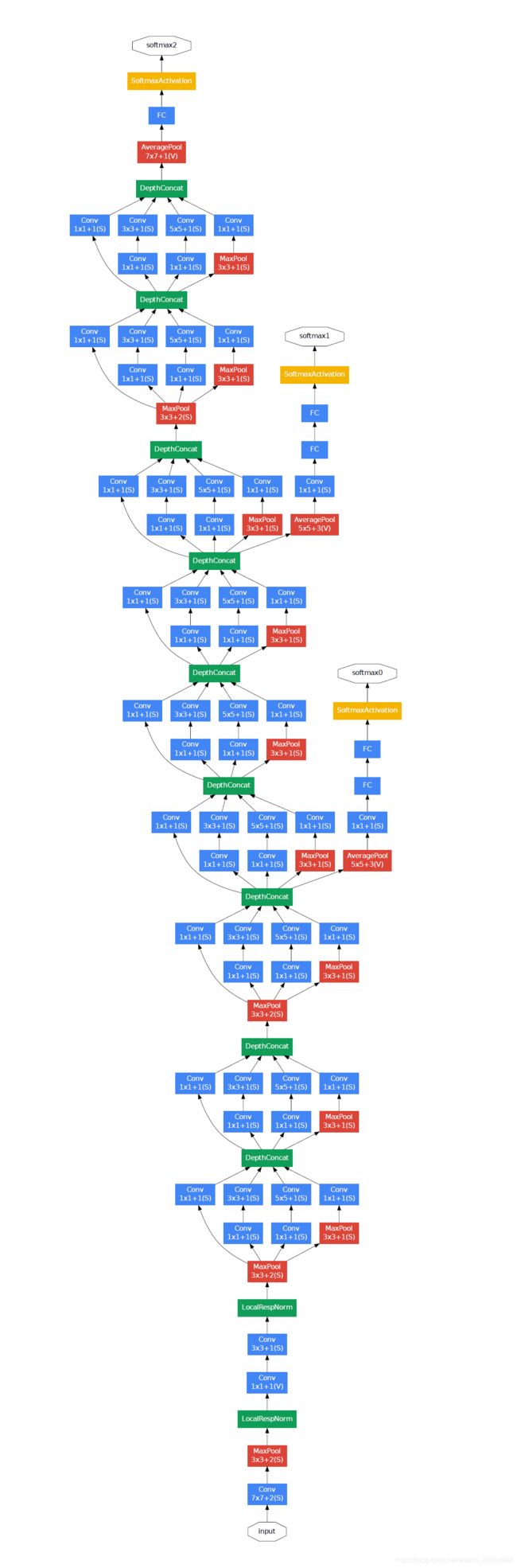
在模型的分类器部分之前,在模型的特征提取部分的末尾使用了重叠的最大池化,并使用了较大的平均池化操作。
以总结出与现代模型相关的架构的关键信息:
- 开发和重复Inception模块;
- 大量使用1×1卷积以减少通道数;
- 在网络中的多个点使用错误反馈;
- 开发非常深的(22层)模型;
- 使用全局平均池化作为模型的输出。
5. ResNet
Kaiming He等人在论文Deep Residual Learning for Image Recognition提出了一个非常深的模型,称为残差网络,简称ResNet。模型具有152层,模型设计的关键是利用快捷连接(shortcut connections)的残差块(residual blocks)的概念,这些只是网络结构中的连接,其中输入保持原样(不加权)并传递到更深的层,例如,跳过下一层。
残差块(residual blocks)是具有ReLU激活的两个卷积层的模式,其中,块的输出与块的输入(例如,快捷连接)组合在一起。如果到块的输入的形状与块的输出不同,则使用1×1卷积。与未加权或identity快捷连接相比,这些称为投影快捷连接(projected shortcut connections)。
该网络受VGG启发,使用较小尺寸的filter(3×3),成组的卷积层堆叠,且没有池化层,全连接层之前使用平均池化,该模型的检测器部分在完全连接输出之前使用softmax激活函数。
通过添加快捷连接以定义残留块,将普通网络修改为残留网络。通常,快捷连接的输入形状与残差块的输出大小相同。
下图取自本文,从左至右比较了VGG模型,普通卷积模型和带有残差模块的普通卷积模型(称为残差网络)的网络结构。

可以总结出与现代模型相关的架构的关键方面,如下所示:
- 使用快捷连接;
- 残差块的扩展和重复;
- 开发非常深的(152层)模型。
参考:
https://machinelearningmastery.com/review-of-architectural-innovations-for-convolutional-neural-networks-for-image-classification/