R_6rh 数据的基本处理
根据书上所学知识对数据进行处理了,由书上的数据可以创建一个数据框,如下所示。
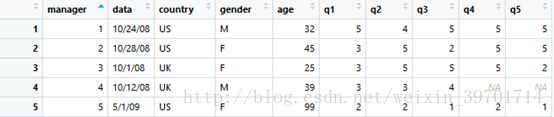
manager <- c (1,2,3,4,5)
data <- c ("10/24/08","10/28/08","10/1/08","10/12/08","5/1/09")
country <- c ("US","US","UK","UK","US")
gender <- c("M","F","F","M","F")
age <- c(32,45,25,39,99)
q1 <- c(5,3,3,3,2)
q2 <- c(4,5,5,3,2)
q3 <- c(5,2,5,4,1)
q4 <- c(5,5,5,NA,2)
q5 <- c(5,5,2,NA,1)
leadership <- data.frame(manager,data,country,gender,age,q1,q2,q3,q4,q5,stringsAsFactors = FALSE)
leadership
manager data country gender age q1 q2 q3 q4 q5
1 1 10/24/08 US M 32 5 4 5 5 5
2 2 10/28/08 US F 45 3 5 2 5 5
3 3 10/1/08 UK F 25 3 5 5 5 2
4 4 10/12/08 UK M 39 3 3 4 NA NA
5 5 5/1/09 US F 99 2 2 1 2 1
1) 创建新的变量
对于每个问题,我们可以得出其q1到q5的sum和平均值,这里说的平均值是比如manage1的横向平均值而不是其纵向平均值。 书上提供了三种方法,transform函数法我觉得很简便,本来可以通过attach函数进行创建,后来发现attach函数只能对两个变量进行编辑。所以我觉得可以用以下方法1:
leadership$sum<- leadership$q1+ leadership$q2+ leadership$q3+ leadership$q4+ leadership$q5
leadership$mean<- leadership$sum/5
或者通过如下方式
方法2
> leadership$sumx <- (q1+q2+q3+4+q5)
> leadership$mean <- leadership$sumx/5
以上方式并不是很科学的,因为它对于的是在创建data框之前已经有了q1到q5的向量,如果直接在data.frame函数中创建向量的话,就不可能会found,而对于方法1又太过于繁琐,所以我们可以通过transform函数来进行编辑与操作:
newleadership <- transform(leadership,sumx = q1+q2+q3+q4+q5, meanx = sumx /5)
> newleadership
manager data country gender age q1 q2 q3 q4 q5 sumx mean meanx
1 1 10/24/08 US M 32 5 4 5 5 5 24 4.6 4.6
2 2 10/28/08 US F 45 3 5 2 5 5 20 3.8 3.8
3 3 10/1/08 UK F 25 3 5 5 5 2 20 3.8 3.8
4 4 10/12/08 UK M 39 3 3 4 NA NA NA NA NA
5 5 5/1/09 US F 99 2 2 1 2 1 8 2.0 2.0
在transform中已经将新的变量保存并可以重新建一个别名的数据框,这样做的好处就是可以使原始数据得到保存。
2) 重新定量的编码
重新编码会涉及到相关的逻辑定义,比如我们定义大于30岁的小于60岁为中年,小于30岁为青少年,大于60岁为老人,
现在可以假设leadership中的数据变量age重新编码为young,middleaged,elder
书中将age=99定义为异常值NA,所以我们应该先将异常值进行重新定义,这里需要使用以下代码:
leadership$age[leadership$age== 99] <- NA
我们可以定义年龄小于40岁的为young,大于40岁小于60岁的为middleaged,大于60岁的为elder。
即可通过同样的变成步骤来进行定义:、
>leadership$age[leadership$age < 40] <- "young"
>leadership$age[leadership$age >= 40 & leadership$age <= 60] <-"middleaged"
>leadership$age[leadership$age > 60] <- "elder"
> leadership
manager data country gender age q1 q2 q3 q4 q5 sum mean
1 1 10/24/08 US M elder 5 4 5 5 5 24 4.8
2 2 10/28/08 US F elder 3 5 2 5 5 20 4.0
3 3 10/1/08 UK F elder 3 5 5 5 2 20 4.0
4 4 10/12/08 UK M elder 3 3 4 NANA NA NA
5 5 5/1/09 US F
所以我们对于特定的异常值可以通过特定的定义让其变为NA
跳回到上一步,也可以重新设定一个变量添加到最后一行 ,即agecat 变量。
leadership$age[leadership$age== 99] <-NA
leadership$agecat[leadership$age>75] <- "elder"
leadership$agecat[leadership$age>= 55&leadership$age <= 55] <- "middle"
leadership$agecat[leadership$age<55] <- "young"
第一行先定义99岁为NA,后面对于其定义的各个年龄都可以通过逻辑判断归入相应的字符中,即可得到以下:
manager data country gender age q1 q2 q3 q4 q5 agecat
1 1 10/24/08 US M 32 5 4 5 5 5 young
2 2 10/28/08 US F 45 3 5 2 5 5 young
3 3 10/1/08 UK F 25 3 5 5 5 2 young
4 4 10/12/08 UK M 39 3 3 4 NA NA young
5 5 5/1/09 US F NA 2 2 1 2 1
书中指出也可以通过within()函数进行编辑:
leadership <-within(leadership,{agecat <- NA
agecat[age >75] <-"elder"
agecat[age>=55&age<=75] <- "middle aged"
agecat[age <55] <-"young"})
这里花括号内每行不需要用,隔开,而且需要注意的是对于with和within(),with和within区别在于with只能进行检索,而within可以进行编辑,
关于with的函数有以下摘抄:
可以使用:
with(mtcars,
list(sum.mpg =summary(mpg),
sum.dis= summary(disp),
sum.wt= summary(wt)
)
)
结果是
$sum.mpg
Min. 1st Qu. Median Mean 3rdQu. Max.
10.40 15.42 19.20 20.09 22.80 33.90
$sum.dis
Min. 1st Qu. Median Mean 3rdQu. Max.
71.1 120.8 196.3 230.7 326.0472.0
$sum.wt
Min. 1st Qu. Median Mean 3rdQu. Max.
1.513 2.581 3.325 3.217 3.610 5.424
如果你想在with()外生成新的目标对象,你可以使用特殊的赋值函数<<-,这样在调用with()函数时它将把该目标保存为全局变量。例如
> with(mtcars, {
nokeepstats <- summary(mpg)
keepstats <<- summary(mpg)
})
> nokeepstats
Error: object ‘nokeepstats’ not found
> keepstats
Min. 1st Qu. Median Mean 3rd Qu. Max.
10.40 15.43 19.20 20.09 22.80 33.90
以上的例子中,对于已经定义好的 age[99]<- NA,才可以使用within函数进行重新编码。
3) 变量重命名
方法1 :
可以使用fix()进行交互式重命名
> fix(leadership)
可以看出我们不仅可以对变量进行重命名,还可以修改变量以得到我们想要的结果。
补充 : 这里所需要说明的是如果你不小心在空白处添加了一个数字,再次删除数字也不会消失而是变成NA,此时会有以下:
> leadership
manager data country gender age q1 q2 q3 q4 q5
1 1 10/24/08 US M 32 5 4 5 5 5
2 2 10/28/08 US F 45 3 5 2 5 5
3 3 10/1/08 UK F 25 3 5 5 5 2
4 4 10/12/08 UK M 39 3 3 4 NA NA
5 5 5/1/09 US F 99 2 2 1 2 1
6 NA NA NA NA NA NA NA
此时如果需要删除对应的行则需要使用检索功能将第六行设定为负值:
> leadership <- leadership[-6,]
> leadership
manager data country gender age q1 q2 q3 q4 q5
1 1 10/24/08 US M 32 5 4 5 5 5
2 2 10/28/08 US F 45 3 5 2 5 5
3 3 10/1/08 UK F 25 3 5 5 5 2
4 4 10/12/08 UK M 39 3 3 4 NA NA
5 5 5/1/09 US F 99 2 2 1 2 1
方法2 :使用编程进行命名
使用names函数可以对变量进行重命名;
> names(leadership)
[1] "manager" "data" "country" "gender" "age" "q1" "q2" "q3" "q4" "q5"
> names(leadership)[1] <- "mananer ID"
> leadership
mananer ID data country gender age q1 q2 q3 q4 q5 agecat
1 1 10/24/08 US M 32 5 4 5 5 5 young
2 2 10/28/08 US F 45 3 5 2 5 5 young
3 3 10/1/08 UK F 25 3 5 5 5 2 young
4 4 10/12/08 UK M 39 3 3 4 NA NA young
5 5 5/1/09 US F NA 2 2 1 2 1
以类似的方式可以对每行进行逐一命名:
names(leadership)[6:10] <- c("item1" , "item2", "item3", "item4","item5")
使用names函数可以先查看对应的data所对应的编号,即可进行修改。
4) NA的处理
我们可以通过is.na来观测缺失值
> is.na(leadership[,6:10])
item1 item2 item3 item4 item5
1 FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE
3 FALSE FALSE FALSE FALSE FALSE
4 FALSE FALSE FALSE TRUE TRUE
5 FALSE FALSE FALSE FALSE FALSE
leadership[,6:10]即可检索第6列到第10列。
我们可以通过上例来对特定的变量进行NA 处理
leadership$age[leadership$age== 99] <-NA
在分析中排除缺失值:
现在已经知道我们所需要对年龄进行sum和mean的统计
> age
[1] 32 45 25 39 99
> age[5]
[1] 99
> age[5] <- NA
> age
[1] 32 45 25 39 NA
>
> sum(age)
[1] NA
> sum(age,na.rm = T)
[1] 141
对于age,我们如果不排除NA,则无法进行计算, 这时可以通过na.rm =TRUE 将NA排除掉再进行计算。
对于数据框,我们可以通过na.omit函数进行移除所有含有缺失值行的数据
na.omit(leadership)
mananer ID data country gender age item1 item2 item3 item4 item5 agecat
1 1 10/24/08 US M 32 5 4 5 5 5 young
2 2 10/28/08 US F 45 3 5 2 5 5 young
3 3 10/1/08 UK F 25 3 5 5 5 2 young
5) 时间值
1 字符型转换为日期
函数as.Date()可以用于执行转换, as.Date(x,”input_format),其中x表示需要转换的字符型数据,“input_format”表示用于读入日期的格式
| 格式 |
意义 |
| %d |
月份中当的天数 |
| %m |
月份,以数字形式表示 |
| %b |
月份,缩写 |
| %B |
月份,完整的月份名,指英文 |
| %y |
年份,以二位数字表示 |
|
%Y %a %A |
年份,以四位数字表示 缩写的星期名 非缩写的星期名 |
比如:
> mydates <- as.Date(c("2007-06-22"))
> mydates
[1] "2007-06-22"
>
> strdates <- c("01/05/1965","08/16/1975")
> dates <- as.Date(strdates,"%m/%d/%Y")
> dates
[1] "1965-01-05" "1975-08-16"
这里input内的含义即告诉R关于x的读取方法,比如在leadership中:
> leadership$data <- as.Date(leadership$data,myformat)
> leadership
manager data country gender age q1 q2 q3 q4 q5
1 1 2008-10-24 US M 32 5 4 5 5 5
2 2 2008-10-28 US F 45 3 5 2 5 5
3 3 2008-10-01 UK F 25 3 5 5 5 2
4 4 2008-10-12 UK M 39 3 3 4 NA NA
5 5 2009-05-01 US F 99 2 2 1 2 1
data从24/10/08 变为日期格式。
也就是给一个可读取的模板(%m/%d/%y)来套用在24/10/08上读取相应的数。
日期的格式一般有yyyy-mm-dd (默认)和mm/dd/yy
2. Sys.Date()显示当天的日期
date()返回当前日期和时间
> Sys.Date()
[1]"2018-02-02"
> date()
[1] "Fri Feb02 23:42:03 2018"
可以使用format(x,format = “output_format”)来输出指定的格式和日期。并且可以提取日期值的某些部分。
> today <- Sys.Date()
> format(today,format = "%B %d %Y")
[1] "二月 02 2018"
> format(today,format= "%A")
[1] "星期五"
同时也可以计算天数,比如
> startsday <- as.Date("2014-09-21")
> todays <- as.Date("2018-02-02")
> durations <- todays - startsday
> durations
Time difference of 1230 days
同样我们可以使用difftime()函数来进行时间间隔的计算,units可以控制其星期,天,时,分,秒等
> difftime(todays,startsday,units = "hours")
Time difference of 29520 hours
作者在最后留了一个小测验,问其生日是周几
> format(as.Date("1956-10-12"),"%A")
[1] "星期五"
最后是将日期转换为字符型, as.character()
> todays
[1] "2018-02-02"
> class(todays)
[1] "Date"
> as.character(todays)
[1] "2018-02-02"
> class(as.character(todays))
[1] "character"