从数据标准到数据库设计:解决基础数据标准落地的最后一公里难题(下)
承接上篇文章:从数据标准到数据库设计:解决基础数据标准落地的最后一公里难题(上)
4. 落标整体方案
无论是原系统数据还是数仓数据,都是不同的开发团队负责,遵循软件开发标准的流程包括设计,开发,测试,上线,维护等环节,因此我们需要在这个过程中,将数据标准这个优良的炮弹,送到最前线,同时,管理团队需要参与这个过程的关键节点中,这需要企业在数据管理上提高管理和执行水平。
鉴于普通银行当前的数据基础水平,数据的落标同样受到人力和财力的制约。所以一个自动化水平非常高的落标方案是非常切合我国普通银行的发展阶段的。因此,本落标方案的关键思想是在开发阶段由模型设计人员进行落标,标准管理和架构管理人员进行评审和核准,同时,自动检测能力来提高执行水平和激励环节的落地。
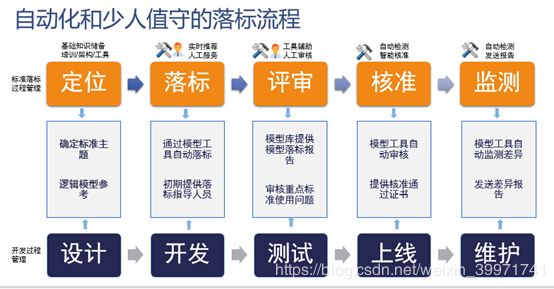
《自动化落标方案》
4.1 标准的定位
这里主要是在系统的需求设计和准备过程中,我们对数据标准需要准备好一些前提条件。
- 标准的技术规范已经准备好:数据标准已经具有详细的技术规范,包括物理数据类型,可以直接应用的物理层上,并已经准备好逻辑数据类型到不同数据库的类型映射。这里数据类型在DDM中是逻辑数据类型,具备自动类型转换能力。
- 标准的主题已经准备好:标准的主题其实是标准的应用范围和检索目录,对于具备条件的银行应该设计出逻辑模型,对数据标准进行业务组织。这样在落标过程中,这是重要的选择依据。
- 标准已经权威发布:标准已经经过讨论,进行了公开发布,具有流程上的正式性和权威性。
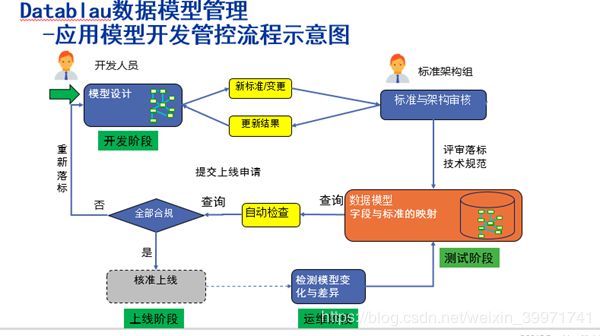
4.2 模型设计中的落标
数据模型是一个更好的数据字典,其向上承接业务语义,向下实现物理数据,它不但包含了数据字典,更重要的是包含了业务的主题,业务主对象,数据关系,以及数据标准的映射。所以模型及其工具的运用不但是企业数据管理是否成熟的重要标志,也是数据标准落标的重要依托。不进行模型设计和管理,落标操作则事倍功半,因为失去了管理的最佳时机。
通过创新一个模型工具,在开发阶段,自动管理数据字典和模型,实现下面三个落标操作。
- 建立标准和数据的映射
- 标准落地的属性继承

一般情况下,数据字段落地标准时要引用标准中上述内容,另还包含数据的标准代码,其中强制性一致的是标准中的技术规范。
- 物理字段的落地衍生
对于一个标准落地的物理字段,如果语义本质是相同的,并且业务规则没有变化,不过满足系统环境,而加上特定限定环境。比如“电话”在供应商的表里叫“供应商电话”,这是一种落地衍生情况,并不需要创建一个新的标准。如前一节所示有一些则需要新的标准或新的子类标准
- 建立代码的标准引用:对字段中的数据类型的引用进行标准化,坚决杜绝Comment里手工写枚举代码的情况。

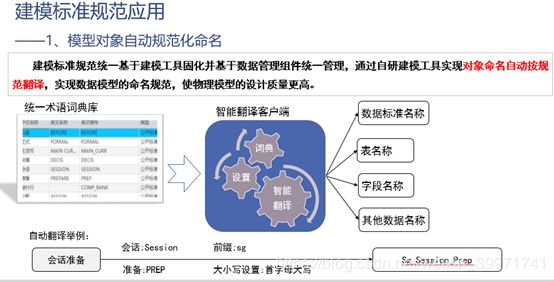
- 标准化命名
4.3 模型的评审
在模型的开发基本完成后,在系统的测试阶段,我们加入模型的评审环节,这个作为系统上线的前奏,避免上线前的修改造成时间紧张等情况。
模型评审前需要创建模型基线,评审包含以下几个内容。
- 标准的落标引用:模型工具应该自动提供报告,重点检查是否有重要的标准没有引用和落地,通过自动化的工具,智能发现落标的潜在问题。

- 自定义标准与词典的评审和转化:DDM模型工具具备自定义数据标准和词典等能力,通过与开发团队评审,提高自定义标准的转化率,完善标准库。
- 元数据的充足率:模型工具应该自动提供报告,列出中文名称没有填写的字段。
- 其他模型质量:比如检查模型主题覆盖率等。
4.4 上线的核准
一般情况下,系统的上线过程需要一个更加标准的流程,提交设计,文档,测试报告,升级步骤等内容,有专业的团队和流程工具来审核。在这个过程中,我们并不主张此环节进行落标的核准,因为此环节已经太晚,我推荐在评审环节完成落标工作,在此环节中,只需要提交落标和模型报告作为过审文档。
模型核准环节包含以下几个工作要做。
- 模型生产库基线与封板:根据评审时建立的模型分支,建立模型的生产库基线,并进行封板操作。
- 模型基线报告:提供模型标准数据字典,标准落标报告,模型质量报告。
4.5 自动监测变化
对于已经发布的模型,随着进入维护期,某些升级的情况下,可能会有徒手修改库表结构的情况发生,为了保证模型与生产库的一致,在自动检测阶段,主要负责定期发现不一致的情况,并发出预警邮件,过程如下。

5. 新增和变更流程
在实际落标过程中,需要新增或修改标准的情况是必然出现的。因此在设计阶段或者模型评审阶段,进行变更流程。
5.1 角色与人力安排
根据银行当前的组织结构,需要有建立“标准和架构组”,至少2人编制,可以是虚拟组织结构和兼职角色。
- 数据架构师(1人),由企业资深(10+年数据开发经验)数据设计人员或管理人员担任,熟悉行业数据模型和企业主流业务逻辑模型,比较熟悉各系统模型情况。主要负责模型管控,落标评审,模型质量等工作。
- 标准管理员(1人),由高级(5+年数据管理经验)数据标准设计和管理人员担任,比较熟悉标准和企业业务逻辑模型。 主要负责标准维护,标准评审,模型质量提高等工作。
5.2 存量数据如何落标
存量系统的落标是很多企业进行标准化第一障碍,前面也进行了痛点分析,那么如何解决落标问题呢?我建议遵循下面方法。
存量系统先管理好数据模型和字典,这作为未来统一数据标准的基础。
摸清模型存量系统不符标准的情况,尤其是那些标准代码,编码规则,存储格式等严重影响数据指标和拉通汇集的情况。
根据非标问题的影响程度,制定未来的落标计划,选择合适的升级版本时机,进行逐项的落标。
未落标前,可以先落标ODS层或API层,这样可以纠正后期应用的标准化问题。
5.3 标准代码的多标准处理
企业里存在多套标准是非常有可能的,比如一个客户类型的代码,原系统一套标准,数仓一套标准,报送EAST模型可能又是一套标准,那么怎么管理这多套标准呢
建议对标准进行有效范围的定义,以明确每套标准的用途,比如原系统的标准作为地方标准,数仓的作为中央标准,EAST模型的标准作为对外标准。
建立标准之间的映射管理,做好数据拉通的依据解决。这样设计标准的维护和变更就可以重点选择哪里进行新增,以及如何进行统一等。
6. 成功案例-中国人寿
我们为中国人寿提供的数据治理整体解决方案的重要组成部分数据标准的落标。中国人寿在全国范围内有26个分支机构,为了保障公司级别系统的一致性和统一性,中国人寿采用Datablau的建模工具基于已有系统提取了基线模型并将标准落在数据模型的字段级别,并将实际的生产元数据跟基线模型绑定,每次系统发版通过比对功能发现生产系统与基线模型的差异,从而快速定位字段级差异并自动发送差异报告通知相关干系人,整个过程无需太多人工干预,治理效果直观有效。
依托建模工具的数据标准的强落地也使得全公司范围的数据标准推广及实施得以顺利进行,各部门的数据标准都汇集到一处,由专人统一管理数据标准的开发,审核,发布以及撤销的全生命周期,各部门只需从数据标准库里面选取对应的标准搭建数据模型。这种强管控的方式也使得数据标准的落地不再是纸上谈兵。
Datablau Data Modeler简介
DDM(Datablau Data Modeler)是国内首创的专业建模工具,是数据治理体系的重要组成部分。数据模型是“所有系统、文档和流程中包含的所有数据的语境。是生数据的知识。”换句话说,如果没有数据模型,组织IT系统中收集和存储的所有数据都会失去意义,也就没有业务价值。
Datablau简介
北京数语科技有限公司(以下简称“数语科技”)成立于2016年,是专注于数据治理领域的国内自主知识产权的专业软件产品提供商,主要业务是数据治理软件产品的研发与销售。数语科技的创始团队全部来自CA erwin,天然具有世界级水准的软件产品开发能力。
创始人兼CEO王琤:曾任职erwin全球研发总监,拥有超过十年以上数据建模和数据管理的从业经验。
CTO朱金宝:曾任职erwin首席架构师,先后服务多家全球知名企业,并曾全程参与中国建设银行数据治理项目,目前全面负责Datablau软件平台的研发工作和关键项目的实施工作。
数语科技根据DAMA理论和中国国情独立研发Datablau新一代数据治理平台,平台由Datablau DDM数据建模产品和Datablau DAM数据资产管理平台两大部分组成,全部拥有软件著作权和知识产权,一站式全面满足中国企业的数据治理需求。其中数据建模产品DDM是Datablau填补国内空白的重量级产品,帮助中国客户摆脱国外产品的垄断现状。2018年,Datablau数据治理平台通过了中国信息通信研究院严格苛刻的产品评测并获得的“最佳大数据产品”奖。
更多渠道了解我们
官网:www.datablau.cn
关注我们,及时了解数据治理干货