今天,通过一个例子,一方面熟悉trace在自定义范围内的分析,另一方面golang 在协程调度策略上的浅析。
Show Code
// trace_example.go
package main
import (
"context"
"fmt"
"os"
"runtime"
"runtime/trace"
"sync"
)
func main(){
// 为了看协程抢占,这里设置了一个cpu 跑
runtime.GOMAXPROCS(1)
f, _ := os.Create("trace.dat")
defer f.Close()
_ = trace.Start(f)
defer trace.Stop()
ctx, task := trace.NewTask(context.Background(), "sumTask")
defer task.End()
var wg sync.WaitGroup
wg.Add(10)
for i := 0; i < 10; i ++ {
// 启动10个协程,只是做一个累加运算
go func(region string) {
defer wg.Done()
// 标记region
trace.WithRegion(ctx, region, func() {
var sum, k int64
for ; k < 1000000000; k ++ {
sum += k
}
fmt.Println(region, sum)
})
}(fmt.Sprintf("region_%02d", i))
}
wg.Wait()
}
首先,代码的功能非常简单,只是启动10个协程,每个协程处理的工作都是一样的,即把0 ... 1000000000 做了sum 运算。
其次,代码中,添加了Task 和 Task 的Region,是我们更好的发现我们协程的位置(当然,我这里都捕获了,只是用Region 做了标识),并将记录的 trace 数据写入trace.dat 文件中。
最后,为了更好的看到协程对cpu的抢占,所以把cpu的个数限制为1个。
编译并运行,会得到如下结果:
# go build trace_example.go
# ./trace_example
region_09 499999999500000000
region_00 499999999500000000
region_01 499999999500000000
region_02 499999999500000000
region_03 499999999500000000
region_04 499999999500000000
region_05 499999999500000000
region_06 499999999500000000
region_07 499999999500000000
region_08 499999999500000000
从结果中,我们可以看出,协程执行的顺序不是那么有序。但是真实是怎么执行的呢?我们从 trace.dat 中获取答案。
Trace 分析
执行下面命令,打开trace 的web服务:
# go tool trace trace.dat
2020/04/16 17:34:09 Parsing trace...
2020/04/16 17:34:10 Splitting trace...
2020/04/16 17:34:10 Opening browser. Trace viewer is listening on http://127.0.0.1:53426
我们先从分析整个协程入手, 从这里可以看出,我们的协程其实没有按照时间片轮询的方式跑(毕竟这是一个纯计算性的工作)

而从Task中,我们观察所有自定义的Region 和goroutine.
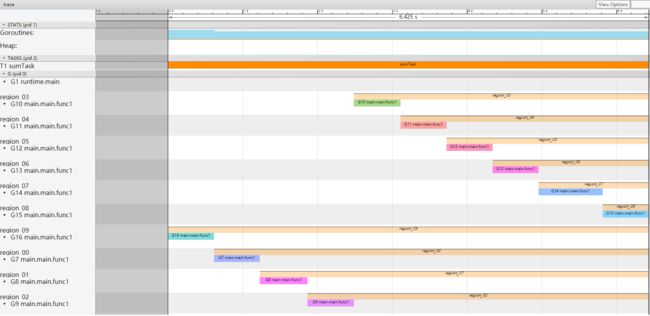
从图中可以看出,task 任务所关注的region 是一个一个跑的,region_09 先执行了,这个也从我们的输出中得到了验证。从图中也可以看到,我们的goroutineid(G1, G10, G12 等, 虽然我们在go编写代码时并不能拿到这个goroutineid).
总结与反思
除了实操了一次 task 和 region 的自定义做trace 分析外,我们还能从这个例子中找到些什么信息。
- goroutine 肯定是存在的
- goroutine 的启动肯定不是有序的, 这一点从task 的图中就可以明显看出来
- goroutine 如果没有阻塞的服务的话,会一直占用cpu的(所以有了 runtime.Gosched() 的存在)
所以,对于一些占用高频cpu的服务(比如说加解密,编解码服务等)如果有别的优先级比较高的goroutine在工作,可以适当的让出CPU, 保证服务正常有序工作。
