[概念]深度学习5种标准化层BN、GN、LN、IN、SN + 谷歌提出新的标准化层:FRN
标准化和归一化的区别?
对图像做数据预处理,最常见的对图像预处理方法有两种,正常白化处理又叫图像标准化处理,另外一种方法叫做归一化处理
而所谓的标准化其实是因为它们都是用标准正太分布的公式如下![[概念]深度学习5种标准化层BN、GN、LN、IN、SN + 谷歌提出新的标准化层:FRN_第1张图片](http://img.e-com-net.com/image/info8/10c1c2f65f844dacbc327def045eeed0.jpg) ,标准化后使得数据分布在均值为0,方差为1上,注意标准化的数据范围并非是[-1,1]之间或者[0,1]之间,通过如下实验可以验证.图像标准化是将数据通过去均值实现中心化的处理,根据凸优化理论与数据概率分布相关知识,数据中心化符合数据分布规律,更容易取得训练之后的泛化效果, 数据标准化是数据预处理的常见方法之一
,标准化后使得数据分布在均值为0,方差为1上,注意标准化的数据范围并非是[-1,1]之间或者[0,1]之间,通过如下实验可以验证.图像标准化是将数据通过去均值实现中心化的处理,根据凸优化理论与数据概率分布相关知识,数据中心化符合数据分布规律,更容易取得训练之后的泛化效果, 数据标准化是数据预处理的常见方法之一
![[概念]深度学习5种标准化层BN、GN、LN、IN、SN + 谷歌提出新的标准化层:FRN_第2张图片](http://img.e-com-net.com/image/info8/0ce504505282419ab0c48ec4d1bdc423.jpg)
而对于归一化:
![[概念]深度学习5种标准化层BN、GN、LN、IN、SN + 谷歌提出新的标准化层:FRN_第3张图片](http://img.e-com-net.com/image/info8/e26ab09e70054e0db78857c636dd4ff0.jpg)
而BN、GN、LN、IN、SN是利用了标准化,英文名叫intermediate normalization layers
为什么要做标准化处理或者归一化处理?
神经网络学习过程的本质就是为了学习数据分布,如果我们没有做归一化处理,那么每一批次训练数据的分布不一样,从大的方向上看,神经网络则需要在这多个分布中找到平衡点,从小的方向上看,由于每层网络输入数据分布在不断变化,这也会导致每层网络在找平衡点,显然,神经网络就很难收敛了。当然,如果我们只是对输入的数据进行归一化处理(比如将输入的图像除以255,将其归到0到1之间),只能保证输入层数据分布是一样的,并不能保证每层网络输入数据分布是一样的,所以也需要在神经网络的中间层加入归一化处理。
常用的5种Normalization
它们分别是Batch Normalization(BN,2015年)、Layer Normalization(LN,2016年)、Instance Normalization(IN,2017年)、Group Normalization(GN,2018年) Switchable Normalization(SN,2019年4月)
论文下载地址:
Batch Normalization
Layer Normalizaiton
Instance Normalization
Group Normalization
Switchable Normalizatio
共同的优点
- 可以使学习快速进行(可以增大学习率)
- 减弱对初始化的强依赖性
- 抑制过拟合
- 保持隐藏层中数值的均值、方差不变,让数值更稳定,为后面网络提供坚实的基础
标准化操作+缩放和平移
它们的计算流程基本一致,主要分为以下几个步骤:
1、对输入数据计算均值
![[概念]深度学习5种标准化层BN、GN、LN、IN、SN + 谷歌提出新的标准化层:FRN_第4张图片](http://img.e-com-net.com/image/info8/d6b3614792954f94893ff76b48a29fab.jpg)
2、计算方差
![[概念]深度学习5种标准化层BN、GN、LN、IN、SN + 谷歌提出新的标准化层:FRN_第5张图片](http://img.e-com-net.com/image/info8/476827b656604646bbe31de7c71f8ab6.jpg)
3、利用均值和方差进行标准化 (![]() 是一个微小常数,为了防止出现除以0的情况)
是一个微小常数,为了防止出现除以0的情况)
4、标准化后,还需要再进行缩放和平移(scale and shift),原因是每一次数据经过标准化后还保留原有学习来的特征,同时又能完成标准化.这两个参数是用来学习的
![[概念]深度学习5种标准化层BN、GN、LN、IN、SN + 谷歌提出新的标准化层:FRN_第7张图片](http://img.e-com-net.com/image/info8/d655556ff4ad4d54a9906e4a1e7ace3f.jpg)
不同点
![[概念]深度学习5种标准化层BN、GN、LN、IN、SN + 谷歌提出新的标准化层:FRN_第8张图片](http://img.e-com-net.com/image/info8/10dae617f57a4829a766b0f91ba4c043.jpg)
上图来自GN那一篇文章,其中N表示batch size的大小(批量),C表示通道数,(H,W)表示特征图的长度和宽度(压缩H,W至一个维度,即图中Instance Norm的蓝色部分既表示一个H,W).通过计算蓝色部分的值求均值和方差,从而进行标准化.
它们主要的区别在于标准化的对象有所不同,下面分别对它们依次进行讲解.
Batch Normalization
![[概念]深度学习5种标准化层BN、GN、LN、IN、SN + 谷歌提出新的标准化层:FRN_第9张图片](http://img.e-com-net.com/image/info8/131278e4b3ad46e1af769684dc8209c0.jpg)
实现步骤
- BN的计算就是把每个通道C的NHW单独拿出来标准化处理+缩放和平移
BN的使用位置:全连接层或卷积层之后,激活层之前
BN的问题:
- BN层已经上成为了标配。但是BN层在训练过程中需要在batch上计算中间统计量,这使得BN层严重依赖batch,如果一堆数据集,每次取得的batch size很小,那么计算出来的均值和方差不足以代表整个数据的分布,往往会恶化性能
- 但是batch size很大的时候,会超过内存容量.
BN的代码实现:
mu = np.mean(x,axis=0)
sigma2 = np.var(x,axis=0)
x_hat = (x-mu)/np.sqrt(sigma2+eps)
out = gamma*x_hat + beta
Layer Normalizatio
![[概念]深度学习5种标准化层BN、GN、LN、IN、SN + 谷歌提出新的标准化层:FRN_第10张图片](http://img.e-com-net.com/image/info8/cad5e80c0beb4126ab7214f199b57743.jpg)
实现步骤
- LN的计算就是把每个CHW单独拿出来标准化处理+缩放和平移
LN的使用位置:它不依赖于batch size和输入sequence的长度,因此可以用于batch size很小的时候和RNN中,LN的效果比较明显.
LN的优点:不受batch size的影响
LN的代码实现
x = x.T # (D, N)
mu = np.mean(x, axis=0) # (N,)
sigma2 = np.var(x, axis=0) # (N,)
x_hat = (x - mu) / np.sqrt(sigma2 + eps)
x_hat = x_hat.T # (N, D)
out = gamma * x_hat + beta
inv_sigma = 1 / np.sqrt(sigma2 + eps)
cache = (x_hat, gamma, mu, inv_sigma)Instance Normalization
![[概念]深度学习5种标准化层BN、GN、LN、IN、SN + 谷歌提出新的标准化层:FRN_第11张图片](http://img.e-com-net.com/image/info8/cf2d75df52a9481d815c7b38cefa1835.jpg)
实现步骤
- IN的计算就是把每个HW单独拿出来标准化处理+缩放和平移
IN的使用位置:保持了每个图像的独立性,最初用于图像的风格化迁移
IN的优点:不受通道和batchsize 的影响
Group Normalization
![[概念]深度学习5种标准化层BN、GN、LN、IN、SN + 谷歌提出新的标准化层:FRN_第12张图片](http://img.e-com-net.com/image/info8/bb88656e20af48bcbe9527813f7e4c03.jpg)
实现步骤
- 把C分成G组,每一组有C/G个通道,各组通道分别标准化+缩放和平移
GN的优点:
- 不受batch size 的影响,batch size很小的时候,GN的效果会比BN好.如下图所示
- GN介于LN和IN之间,当然可以说LN和IN就是GN的特列,比如G的大小为1或者为C
![[概念]深度学习5种标准化层BN、GN、LN、IN、SN + 谷歌提出新的标准化层:FRN_第13张图片](http://img.e-com-net.com/image/info8/e8e921e3a7a84953bede7c78e442b94c.jpg)
GN的缺点:
- 但对于大batch size,GN仍然难以匹敌BN
GN实现代码:
![[概念]深度学习5种标准化层BN、GN、LN、IN、SN + 谷歌提出新的标准化层:FRN_第14张图片](http://img.e-com-net.com/image/info8/c3a7ec49ecad4c56ad55705853478df2.jpg)
Switchable Normalization
实现步骤: 将 BN、LN、IN 结合,赋予不同的权重,让网络自己去学习这些权重

![[概念]深度学习5种标准化层BN、GN、LN、IN、SN + 谷歌提出新的标准化层:FRN_第15张图片](http://img.e-com-net.com/image/info8/eb4ba480cfa84c4fb9edade24218bcb2.jpg)
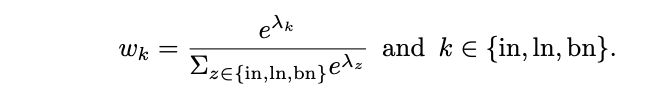
缺点:训练复杂
谷歌新推出的标准化: Filter Response Normalization
FRN论文下载:连接 (2019年11月)
FRN的优点:
- FRN层不仅消除了模型训练过程中对batch的依赖,而且当batch size较大时性能优于BN。
谷歌的提出的FRN层包括归一化层FRN(Filter Response Normalization)和激活层TLU(Thresholded Linear Unit),如图所示
![[概念]深度学习5种标准化层BN、GN、LN、IN、SN + 谷歌提出新的标准化层:FRN_第16张图片](http://img.e-com-net.com/image/info8/36b29949852a47d1a6cfa43001d4c52d.jpg)
![[概念]深度学习5种标准化层BN、GN、LN、IN、SN + 谷歌提出新的标准化层:FRN_第17张图片](http://img.e-com-net.com/image/info8/cd44897782dd406e9c71fc858322c1bf.jpg)
![[概念]深度学习5种标准化层BN、GN、LN、IN、SN + 谷歌提出新的标准化层:FRN_第18张图片](http://img.e-com-net.com/image/info8/64479fef0ea8444f9da6d9358a903624.jpg)
标准化之后同样需要进行缩放和平移变换.
FRN缺少去均值的操作,这可能使得标准化的结果任意地偏移0,如果FRN之后是ReLU激活层,可能产生很多0值,这对于模型训练和性能是不利的。为了解决这个问题,FRN之后采用的阈值化的ReLU,即TLU:
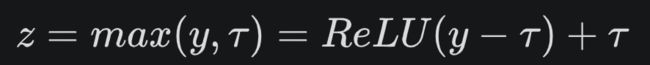
这里的参数 是一个可学习的参数。论文中发现FRN之后采用TLU对于提升性能是至关重要的.
是一个可学习的参数。论文中发现FRN之后采用TLU对于提升性能是至关重要的.
FRN实现的代码:(TensorFlow)
def FRNLayer(x, tau, beta, gamma, eps=1e-6):
# x: Input tensor of shape [BxHxWxC].
# alpha, beta, gamma: Variables of shape [1, 1, 1, C].
# eps: A scalar constant or learnable variable.
# Compute the mean norm of activations per channel.
nu2 = tf.reduce_mean(tf.square(x), axis=[1, 2],
keepdims=True)
# Perform FRN.
x = x * tf.rsqrt(nu2 + tf.abs(eps))
# Return after applying the Offset-ReLU non-linearity.
return tf.maximum(gamma * x + beta, tau)FRN层的效果也是极好的,下图给出了FRN与BN和GN的效果对比:
![[概念]深度学习5种标准化层BN、GN、LN、IN、SN + 谷歌提出新的标准化层:FRN_第19张图片](http://img.e-com-net.com/image/info8/480a8cfdb5fe48a78293d500ea64027f.jpg)
可以看到FRN是不受batch size的影响,而且效果是超越BN的。论文中还有更多的对比试验证明FRN的优越性。
BN目前依然是最常用的标准化方法,GN虽然不会受batch size的影响,但是目前还没大范围采用,不知道FRN的提出会不会替代BN,这需要时间的检验。
reference
1、http://www.360doc.com/content/19/0928/22/32196507_863780595.shtml
2、https://blog.csdn.net/u013289254/article/details/99690730
3、https://blog.csdn.net/hao1994121/article/details/85171610
4、FRN:https://zhuanlan.zhihu.com/p/98688349