菜哥学知识图谱(通过“基于医疗知识图谱的问答系统”)(三)(代码分析)
上接菜哥学知识图谱(通过“基于医疗知识图谱的问答系统”)(二)
目录
- 代码分析
代码分析
这是项目内的文件结构。从基于医疗知识图谱的问答系统源码详解借一张图,按照新内容修改了一下。
├── QASystemOnMedicalKG
├── data
├── medical.json # 知识数据
├── dict
├── check.txt # 诊断检查项目实体库
├── deny.txt # 否定词库
├── department.txt # 医疗科目实体库
├── disease.txt # 疾病实体库
├── drug.txt # 药品实体库
├── food.txt # 食物实体库
├── producer.txt # 在售药品库
├── symptom.txt # 疾病症状实体库
├── document # 文档
├── img # 图片
├── prepare_data
├── build_data.py # 数据库操作脚本
├── data_spider.py # 数据采集脚本
├── max_cut.py # 基于词典的最大前向/后向匹配
├── answer_search.py # 问题查询及返回
├── build_medicalgraph.py # 将结构化json数据导入neo4j
├── chatbot_graph.py # 问答程序脚本
├── question_classifier.py # 问句类型分类脚本
├── question_parser.py # 问句解析脚本
一个文件一个文件的分析。
1.data\medical.json
这里面是已经存储好的疾病知识数据,打开看一下。新建一个openjson.py文件,输入以下内容:
with open(r'C:\QASystemOnMedicalKG\data\medical.json', 'r', encoding='utf8') as js:
for js_data in js:
print(js_data)
执行,可以看到,json文件里面的数据是这样的:
{ "_id" : { "$oid" : "5bb57901831b973a137e614d" },
"name" : "病毒性肠炎",
"desc" : "病毒性肠炎(viralgastroenteritis)又称病毒性腹泻......。",
"category" : [ "疾病百科", "内科", "消化内科" ],
"prevent" : "及早发现和隔离病人......。",
"cause" : "......但多数肠粘膜细胞尚正常。肠绒毛上皮细胞内空泡变性,内质网中有多量轮状病毒颗粒。",
"symptom" : [ "恶心与呕吐", "驻站医", "发烧", "腹泻", "腹痛", "慢性腹痛" ],
"yibao_status" : "否",
"get_prob" : "0.001%",
"easy_get" : "无特定人群",
"get_way" : "无传染性",
"acompany" : [ "缺铁性贫血" ],
"cure_department" : [ "内科", "消化内科" ],
"cure_way" : [ "药物治疗", "康复治疗" ],
"cure_lasttime" : "7-14天",
"cured_prob" : "85%-95%",
"common_drug" : [ "盐酸左氧氟沙星胶囊", "依托红霉素片" ],
"cost_money" : "根据不同医院,收费标准不一致,市三甲医院约(1000——5000元)",
"check" : [ "便常规", "纤维肠镜", "小肠镜检查", "红细胞计数(RBC)", "细菌学检验", "粪酸碱度", "血常规", "粪细菌培养", "血小板计数(PLT)" ],
"do_eat" : [ "鸭蛋", "鸡蛋", "鸡肉", "芝麻" ],
"not_eat" : [ "杏仁", "腐竹", "白扁豆", "沙丁鱼" ],
"recommand_eat" : [ "冬瓜粒杂锦汤", "土豆肉末粥", "丁香酸梅汤" ],
"recommand_drug" : [ "司帕沙星片", "清泻丸", "复方黄连素片", "枯草杆菌二联活菌肠溶胶囊", "盐酸左氧氟沙星胶囊", "司帕沙星分散片",..... "SP", "依托红霉素片", "苦木注射液", "氧氟沙星片" ],
"drug_detail" : [ "联邦左福康盐酸左氧氟沙星胶(盐酸左氧氟沙星胶囊)", "广东华南依托红霉素片(依托红霉素片)", "桂林三金复方红根草片(复方红根草片)", ........"万年青苦木注射液(苦木注射液)", "惠州九惠炎宁颗粒(炎宁颗粒)", "浙江得恩德氧氟沙星片(氧氟沙星片)", "吉林跨海生化止痢宁片(止痢宁片)" ] }
{......}
{......}
可以猜测,每一种疾病是一条字典类型数据。每条数据里面有24个键值对。每个键值对的含义能猜出来。
2.dict文件夹内的各个文本文档,是各类实体库,可以挨个打开看一下。
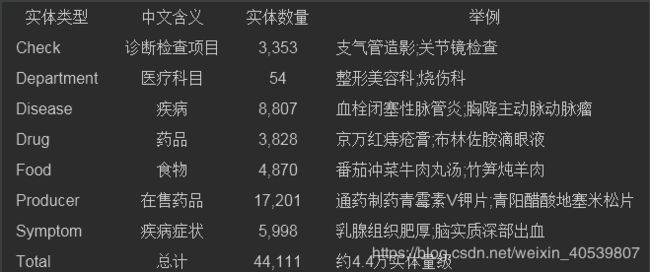
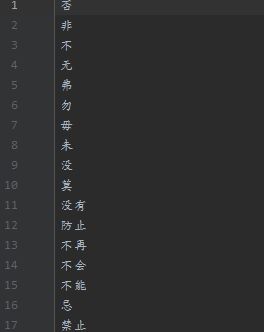
和一个否定词库deny.txt。
3.prepare_data\data_spider.py 数据采集脚本。spider_main()方法把爬取的疾病相关信息放到数据库’medical’里。inspect_crawl()方法把检查项目的网页地址和源码放到了数据库’jc’里。
可以看对源码我的注释:
#!/usr/bin/env python3
# coding: utf-8
# File: data_spider.py
# Author: lhy4.prepare_data\max_cut.py 基于词典的最大前向/后向匹配。
看原文注释就可以,重新注释的意义不大。
5.prepare_data\build_data.py 数据库操作脚本。collect_medical()方法把key换成英文了,内容变化不大;执行后,数据应该在data\medical.json里面,格式内容是一样的。
注释一下
#!/usr/bin/env python3
# coding: utf-8
# File: build_data.py
# Author: lhy未完待续:
菜哥学知识图谱(通过“基于医疗知识图谱的问答系统”)(四)(代码分析2)