词向量技术原理及应用详解(四)——词向量训练
前文理论介绍完毕,接下来进入实战环节。实践中向量化应用的场景常有不同,但向量文本化的训练和使用方式大同小异。在这里我将采用两种方法:gensim库以及tensorflow来完成词向量实战训练。
一、word2vec之gensim工具包实现
1、gensim工具包中详细参数:
在gensim中,word2vec相关的API都在包gensim.models.word2vec中。和算
法有关的参数都在类gensim.models.word2vec.Word2Vec中。
算法需要注意的参数有:
1) sentences: 我们要分析的语料,可以是一个列表,或者从文件中遍历读出。
2) size: 词向量的维度,默认值是100。这个维度的取值一般与我们的语料的大小相关,如果是不大的语料,比如小于100M的文本语料,则使用默认值一般就可以了。如果是超大的语料,建议增大维度。
3) window:即词向量上下文最大距离,这个参数在我们的算法原理篇中标记为,window越大,则和某一词较远的词也会产生上下文关系。默认值为5。在实际使用中,可以根据实际的需求来动态调整这个window的大小。如果是小语料则这个值可以设的更小。对于一般的语料这个值推荐在[5,10]之间。
4) sg: 即我们的word2vec两个模型的选择了。如果是0,则是CBOW模型,是1则是Skip-Gram模型,默认是0即CBOW模型。
5) hs: 即我们的word2vec两个解法的选择了,如果是0, 则是Negative Sampling,是1的话并且负采样个数negative大于0, 则是Hierarchical Softmax。默认是0即Negative Sampling。
6) negative:即使用Negative Sampling时负采样的个数,默认是5。推荐在[3,10]之间。这个参数在我们的算法原理篇中标记为neg。
7) cbow_mean: 仅用于CBOW在做投影的时候,为0,则算法中的为上下文的词向量之和,为1则为上下文的词向量的平均值。在我们的原理篇中,是按照词向量的平均值来描述的。个人比较喜欢用平均值来表示,默认值也是1,不推荐修改默认值。
8) min_count:需要计算词向量的最小词频。这个值可以去掉一些很生僻的低频词,默认是5。如果是小语料,可以调低这个值。
9) iter: 随机梯度下降法中迭代的最大次数,默认是5。对于大语料,可以增大这个值。
10) alpha: 在随机梯度下降法中迭代的初始步长。算法原理篇中标记为,默认是0.025。
11) min_alpha: 由于算法支持在迭代的过程中逐渐减小步长,min_alpha给出了最小的迭代步长值。随机梯度下降中每轮的迭代步长可以由iter,alpha, min_alpha一起得出。这部分由于不是word2vec算法的核心内容,因此在原理篇我们没有提到。对于大语料,需要对alpha, min_alpha,iter一起调参,来选择合适的三个值。
12)worker:训练词向量使用时使用的线程数,默认为3。
2、Word2vec训练词向量 gensim(从数据库中读取数据)
从pg数据库中读取数据,进行分词,并把分词结果存入txt文档,调用gensim包训练词向量代码
代码如下:
import jieba
import re
from gensim.models import word2vec
import psycopg2读取停用词:
jieba.load_userdict("data\jiebauserdict.txt")
stop_words = []
with open("data\stop_words.txt", "r", encoding="utf-8") as f_reader:
for line in f_reader:
line = line.replace("\r","").replace("\n","").strip()
stop_words.append(line)
print(len(stop_words))
stop_words = set(stop_words)
print(len(stop_words))读取数据库进行分词并保存到txt文档中:
# rules = u"[\u4e00-\u9fa5]+"
# pattern = re.compile(rules)
f_writer = open("data\分词后的文本.txt", "w", encoding="utf-8")
def get_dataset():#读数据库文本详情,并输出切分词数组。
#读取库中数据,mbm case set是表名
conn = psycopg2.connect(database='***',user='***', password='***', host='***', port='***')
cur = conn.cursor()
cur.execute("SQL语句 ")
data = cur.fetchall()#80000
print('length',len(data),type(data))
sentence=[]
for i in range(len(data)):
# line = line.replace("\r", "").replace("\n", "").strip()
if data[i][0]!=None:#空字段
if len(data[i][0])>20:#去除无效描述
# print(data[i][0])
text=jieba.lcut(data[i][0])
# print(str(text))
# seg_list = pattern.findall(text)
word_list = []
for word in text:
if word not in stop_words:
word_list.append(word)
if len(word_list) > 0:
sentence.append(word_list)
line = " ".join(word_list)
line = line.replace("\r", "").replace("\n", "").strip()
f_writer.write(line + "\n")
f_writer.flush()
f_writer.close()
# print(sentence[:10])
print('total length is ',len(sentence))
return sentence训练word2vec并保存模型,这里的sentences的实例格式如下,是一个列表里嵌套列表,训练的是词语的向量。如果只是一个列表,如['1','2',...'6'],则是训练字符的向量。
[['中国篮协', '全运', '抵津', '10', '全运村', '姚明', '篮球场', '三座', '开幕式', '入住', '多天', '奔波', '已有', '主席', '之间'], ['天津', '篮球馆', '财大', '地谈', '饶有兴致', '姚明', '全运会', '融入', '亮点', '最有', '看法', '群众', '昨天', '本次', '进来', '能够', '觉得', '地方'], ['天津', '中国篮协', '篮球比赛', '全运会', '非常感谢', '委会', '场馆', '篮球', '方方面面', '运动会', '承办', '大力支持', '委派', '总局', '一员', '市委', '市政府', '比赛', '一项', '各个'], ['城市', '美丽', '津城', '感受', '天津', '全运', '赛得', '多次', '这次', '姚明', '领略到', '之前', '教练员', '文化', '到访', '非常', '浓烈', '体育', '运动员', '这座'], ['群众性', '全运会', '盛会', '体育', '全运', '姚明', '奖牌', '项目', '社会', '一个', '融入', '运动员', '荣誉', '本届', '不该', '引入', '兴趣', '比赛', '做到', '天津'], ['教练员', '段时间', '运动员', '很多', '生活', '篮协', '天津', '官员', '姚明', '全运会', '赞不绝口', '我们', '场馆', '非常', '夸赞', '非常高兴', '发言权', '志愿者', '奔波', '工作'], ['中国篮球', '篮球', '天津', '故乡', '篮球馆', '1891', '漂洋过海', '姚明', '最出色', '毋庸置疑', '文化遗产', '中国', '迄今为止', '作为', '发源地', '上岸', '运动员', '室内', '传入', '诞生'], ['挖掘', '故事', '越来越', '重新', '希望', '未来', '历史', '出来', '工作', '这样', '可以', '我们', '人工智能', '人工智障', '大数据', '马云', '阿里巴巴', '共享单车', '滴滴']]
def train(sentences):
print("开始训练")
model = word2vec.Word2Vec(sentences = sentences, size = 200, window = 5)
model.save("model\word2vec_news.model")
print("训练完成")
if __name__ == '__main__':
content = get_dataset()
train(content)
使用Gensim简单一点,参数可以设置。用了35万训练文本。检测模型训练后的效果,可以根据词的相似度进行判断训练的效果:
import gensim
import pandas as pd
model = gensim.models.Word2Vec.load('model\word2vec_news.model')
result = pd.Series(model.most_similar(u'漏水'))
print(result) 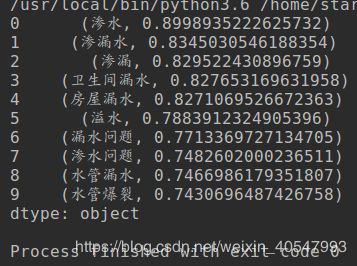
可见,词向量训练的结果还是不错的。这个可以看作是word2vec的求近义词,也可以看成利用word2vec聚类
附:一个在线测试的网站,貌似是一位清华教授做的:http://cikuapi.com/index.php
二、word2vec之tensorflow实现
后期补上