使用keras搭建网络
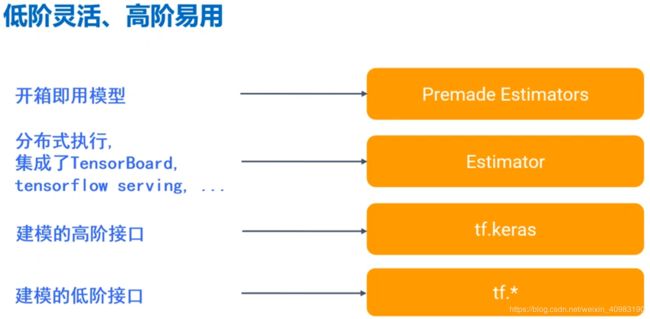
Keras是更高阶的Tensorflow的接口应用。Tensorflow框架已经不需要再引入第三方的keras包了,可以直接应用keras高阶接口。让神经网络的搭建门槛降低,更加利于科研人员使用神经网络。在此之上还有更加集成化的应用和模型,他们的关系基本可以用下图来表示,越低阶的开发门槛越高,使用越灵活,越高阶的越友好。可以根据开发人员的实际情况来决定使用那一层级的API
 Keras的模型搭建过程。
Keras的模型搭建过程。
1、 序列化建模model = tf.keras.models.Sequential()
2、 添加模型的隐藏层model.add(tf.keras.layers.Dense(…)
3、 模型设置,就是定义优化器,损失函数和监控的度量model.compile(…)
4、 模型训练train_history = model.fit(…)
5、 模型评估evaluate_results = model.evaluate(…)
6、 使用模型预测predict_result = model.predict(…)
7、 从ckpt恢复模型model.load_weights(…)
以titanic人员数据为例,使用keras搭建神经网络的代码,供参考
#数据准备
##下载旅客数据
import urllib.request
import os
data_url = "http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.xls"
data_file_path = "data/titanic3.xls"
if not os.path.isfile(data_file_path):
result = urllib.request.urlretrieve(data_url,data_file_path)
print("downloaded:",result)
else:
print(data_file_path," data file already exists.")
#读取数据
import numpy
import pandas as pd
df_data = pd.read_excel(data_file_path)
#筛选数据字段
selected_cols = ['survived','name','pclass','sex','age','sibsp','parch','fare','embarked']
selected_df_data = df_data[selected_cols]
from sklearn import preprocessing
#定义数据预处理函数
def prepare_data(df_data):
df = df_data.drop(['name'],axis = 1)
age_mean = df['age'].mean()
df['age']=df['age'].fillna(age_mean)
fare_mean = df['fare'].mean()
df['fare']=df['fare'].fillna(fare_mean)
df['sex']=df['sex'].map({'female':0,'male':1}).astype(int)
df['embarked'] = df['embarked'].fillna('S')
df['embarked'] = df['embarked'].map({'C':0,'Q':1,'S':2}).astype(int)
ndarray_data = df.values
features = ndarray_data[:,1:]
label = ndarray_data[:,0]
minmax_scale = preprocessing.MinMaxScaler(feature_range=(0,1))
norm_features = minmax_scale.fit_transform(features)
return norm_features,label
#shuffle打乱数据为后续数据做准备
shuffled_df_data = selected_df_data.sample(frac=1)
#对数据做预处理
x_data,y_data = prepare_data(shuffled_df_data)
#划分为训练集合测试集
train_size = int(len(x_data)*0.8)
x_train = x_data[:train_size]
y_train = y_data[:train_size]
x_test = x_data[train_size:]
y_test = y_data[train_size:]
#Keras建模
import tensorflow as tf
#使用Keras序列化建立模型
model = tf.keras.models.Sequential()
#加入第一层,64个神经元,输入数据维数为7,KERNEL_INITIALIZER是指权重初始化的方式
model.add(tf.keras.layers.Dense(units = 64,
input_dim = 7,
use_bias = True,
kernel_initializer ='uniform',
bias_initializer ='zero',
activation = 'relu'))
#增加sigmoid层,第二层的输入维数可以不用指定了,默认等于第一层的维数
model.add(tf.keras.layers.Dense(units=32,activation='sigmoid'))
#指定输出层,输出层的units就等于需要分类的种类
model.add(tf.keras.layers.Dense(units=1,activation='sigmoid'))
#显示模型参数
model.summary()
#使用keras设置模型,就是定义优化器,损失函数和监控的度量值
model.compile(optimizer = tf.keras.optimizers.Adam(0.003),
loss='binary_crossentropy',
metrics = ['accuracy'])
#sigmoid作为激活函数,一般损失函数用binary_crossentropy
#softmax作为激活函数,一般损失函数选用categorical_crossentropy(分类交叉熵)
#具体的设置可以查阅相关API文档 比如
#https://www.tensorflow.org/versions/r1.10/api_docs/python/tf/keras/Model
#keras中训练模型,fit的返回值是字典类型的数据
train_history = model.fit(x=x_train,
y=y_train,
validation_split = 0.2, #将训练集数据分成两部分,20%用作验证集
epochs =100,
batch_size = 40,
verbose=2 #显示参数 0/1/2 0不显示;1显示进度条;2表示显示最多细节
)
#定义训练过程的可视化函数
import matplotlib.pyplot as plt
def visu_train_history(train_history,train_metrics,validation_metric):
plt.plot(train_history.history[train_metrics])
plt.plot(train_history.history[validation_metric])
plt.title('Train_History')
plt.ylabel('train_metrics')
plt.xlabel('epoch')
plt.legend(['train','validatio'],loc='upper left')
plt.show()
#显示准确率
visu_train_history(train_history,'acc','val_acc')
#显示损失函数
visu_train_history(train_history,'loss','val_loss')
#评估模型
evaluate_results = model.evaluate(x=x_test, y = y_test)
#model.metrics_names保存了结果返回值的标签
#keras模型应用
#制作数据
#Jack:3等舱,男性,票价5,年龄23
#Rose:头等舱,女性,票价100,年龄20
Jack_info=[0,'Jack',3,'male',23,1,0,5.0,'S']
Rose_info = [1,'Rose',1,'female',20,1,0,100.0,'S']
#创建新的旅客信息
#columns=selected_cols表示旅客信息的列就是前面选取出来的特征列
new_passager_pd = pd.DataFrame([Jack_info,Rose_info],columns=selected_cols)
#在老的DataFrame中加入新的旅客信息
all_passager_pd = selected_df_data.append(new_passager_pd)
#在此执行数据的预处理
x_features,y_label = prepare_data(all_passager_pd)
#利用模型计算旅客生存率
surv_probability = model.predict(x_features)
#查看最后两位旅客的生存概率
print(surv_probability[-2:])