【深度学习图像识别课程】毕业项目:狗狗种类识别(2)代码实现
本博文涉及以下:Zero/一/二/三/四目录:
Zero:导入数据集
一、检测人脸
二、检测狗狗
三、从头实现CNN实现狗狗分类
四、迁移VGG16实现狗狗分类
五、迁移ResNet_50实现狗狗分类
六、自己实现狗狗分类
Zero:导入数据集
1、导入狗狗数据集
在下方的代码单元(cell)中,我们导入了一个狗图像的数据集。我们使用 scikit-learn 库中的 load_files 函数来获取一些变量:
train_files,valid_files,test_files- 包含图像的文件路径的numpy数组train_targets,valid_targets,test_targets- 包含独热编码分类标签的numpy数组dog_names- 由字符串构成的与标签相对应的狗的种类
from sklearn.datasets import load_files
from keras.utils import np_utils
import numpy as np
from glob import glob
# 定义函数来加载train,test和validation数据集
def load_dataset(path):
data = load_files(path)
dog_files = np.array(data['filenames'])
dog_targets = np_utils.to_categorical(np.array(data['target']), 133)
return dog_files, dog_targets
# 加载train,test和validation数据集
train_files, train_targets = load_dataset('dogImages/train')
valid_files, valid_targets = load_dataset('dogImages/valid')
test_files, test_targets = load_dataset('dogImages/test')
# 加载狗品种列表
dog_names = [item[20:-1] for item in sorted(glob("dogImages/train/*/"))]
# 打印数据统计描述
print('There are %d total dog categories.' % len(dog_names))
print('There are %s total dog images.\n' % len(np.hstack([train_files, valid_files, test_files])))
print('There are %d training dog images.' % len(train_files))
print('There are %d validation dog images.' % len(valid_files))
print('There are %d test dog images.'% len(test_files))
2、导入人脸数据库
import random
random.seed(8675309)
# 加载打乱后的人脸数据集的文件名
human_files = np.array(glob("lfw/*/*"))
random.shuffle(human_files)
# 打印数据集的数据量
print('There are %d total human images.' % len(human_files))![]()
一、检测人脸
我们将使用 OpenCV 中的 Haar feature-based cascade classifiers 来检测图像中的人脸。OpenCV 提供了很多预训练的人脸检测模型,它们以XML文件保存在 github。我们已经下载了其中一个检测模型,并且把它存储在 haarcascades 的目录中。
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
# 提取预训练的人脸检测模型
face_cascade = cv2.CascadeClassifier('haarcascades/haarcascade_frontalface_alt.xml')
# 加载彩色(通道顺序为BGR)图像
img = cv2.imread(human_files[3])
# 将BGR图像进行灰度处理
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 在图像中找出脸
faces = face_cascade.detectMultiScale(gray)
# 打印图像中检测到的脸的个数
print('Number of faces detected:', len(faces))
# 获取每一个所检测到的脸的识别框
for (x,y,w,h) in faces:
# 在人脸图像中绘制出识别框
cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
# 将BGR图像转变为RGB图像以打印
cv_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 展示含有识别框的图像
plt.imshow(cv_rgb)
plt.show()![]()

在使用任何一个检测模型之前,将图像转换为灰度图是常用过程。detectMultiScale 函数使用储存在 face_cascade 中的的数据,对输入的灰度图像进行分类。
在上方的代码中,faces 以 numpy 数组的形式,保存了识别到的面部信息。它其中每一行表示一个被检测到的脸,该数据包括如下四个信息:前两个元素 x、y 代表识别框左上角的 x 和 y 坐标(参照上图,注意 y 坐标的方向和我们默认的方向不同);后两个元素代表识别框在 x 和 y 轴两个方向延伸的长度 w 和 d。
1、写一个人脸识别器
# 如果img_path路径表示的图像检测到了脸,返回"True"
def face_detector(img_path):
img = cv2.imread(img_path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray)
return len(faces) > 0
2、评估人脸检测模型
在下方的代码块中,使用 face_detector 函数,计算:
human_files的前100张图像中,能够检测到人脸的图像占比多少?dog_files的前100张图像中,能够检测到人脸的图像占比多少?
理想情况下,人图像中检测到人脸的概率应当为100%,而狗图像中检测到人脸的概率应该为0%。你会发现我们的算法并非完美,但结果仍然是可以接受的。我们从每个数据集中提取前100个图像的文件路径,并将它们存储在human_files_short和dog_files_short中。
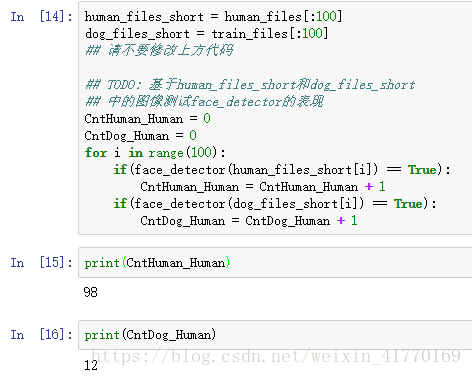
中间查看了一下human_files_short和dog_files_short

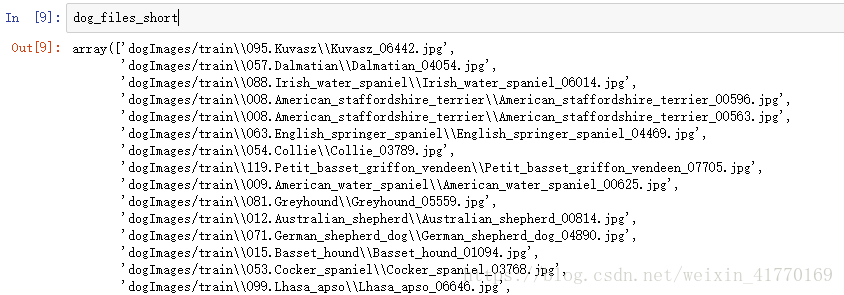
二、检测狗狗
在这个部分中,我们使用预训练的 ResNet-50 模型去检测图像中的狗。下方的第一行代码就是下载了 ResNet-50 模型的网络结构参数,以及基于 ImageNet 数据集的预训练权重。
ImageNet 这目前一个非常流行的数据集,常被用来测试图像分类等计算机视觉任务相关的算法。它包含超过一千万个 URL,每一个都链接到 1000 categories 中所对应的一个物体的图像。任给输入一个图像,该 ResNet-50 模型会返回一个对图像中物体的预测结果。
from keras.applications.resnet50 import ResNet50
# 定义ResNet50模型
ResNet50_model = ResNet50(weights='imagenet')![]()
1、图像预处理
- 在使用 TensorFlow 作为后端的时候,在 Keras 中,CNN 的输入是一个4维数组(也被称作4维张量),它的各维度尺寸为
(nb_samples, rows, columns, channels)。其中nb_samples表示图像(或者样本)的总数,rows,columns, 和channels分别表示图像的行数、列数和通道数。
- 下方的
path_to_tensor函数实现如下将彩色图像的字符串型的文件路径作为输入,返回一个4维张量,作为 Keras CNN 输入。因为我们的输入图像是彩色图像,因此它们具有三个通道(channels为3)。- 该函数首先读取一张图像,然后将其缩放为 224×224 的图像。
- 随后,该图像被调整为具有4个维度的张量。
- 对于任一输入图像,最后返回的张量的维度是:
(1, 224, 224, 3)。
paths_to_tensor函数将图像路径的字符串组成的 numpy 数组作为输入,并返回一个4维张量,各维度尺寸为(nb_samples, 224, 224, 3)。 在这里,nb_samples是提供的图像路径的数据中的样本数量或图像数量。你也可以将nb_samples理解为数据集中3维张量的个数(每个3维张量表示一个不同的图像。
from keras.preprocessing import image
from tqdm import tqdm
def path_to_tensor(img_path):
# 用PIL加载RGB图像为PIL.Image.Image类型
img = image.load_img(img_path, target_size=(224, 224))
# 将PIL.Image.Image类型转化为格式为(224, 224, 3)的3维张量
x = image.img_to_array(img)
# 将3维张量转化为格式为(1, 224, 224, 3)的4维张量并返回
return np.expand_dims(x, axis=0)
def paths_to_tensor(img_paths):
list_of_tensors = [path_to_tensor(img_path) for img_path in tqdm(img_paths)]
return np.vstack(list_of_tensors)
2、基于ResNet50架构进行预测
对于通过上述步骤得到的四维张量,在把它们输入到 ResNet-50 网络、或 Keras 中其他类似的预训练模型之前,还需要进行一些额外的处理:
- 首先,这些图像的通道顺序为 RGB,我们需要重排他们的通道顺序为 BGR。
- 其次,预训练模型的输入都进行了额外的归一化过程。因此我们在这里也要对这些张量进行归一化,即对所有图像所有像素都减去像素均值
[103.939, 116.779, 123.68](以 RGB 模式表示,根据所有的 ImageNet 图像算出)。
导入的 preprocess_input 函数实现了这些功能。如果你对此很感兴趣,可以在 这里 查看 preprocess_input的代码。
在实现了图像处理的部分之后,我们就可以使用模型来进行预测。这一步通过 predict 方法来实现,它返回一个向量,向量的第 i 个元素表示该图像属于第 i 个 ImageNet 类别的概率。这通过如下的 ResNet50_predict_labels 函数实现。
通过对预测出的向量取用 argmax 函数(找到有最大概率值的下标序号),我们可以得到一个整数,即模型预测到的物体的类别。进而根据这个 清单,我们能够知道这具体是哪个品种的狗狗。
from keras.applications.resnet50 import preprocess_input, decode_predictions
def ResNet50_predict_labels(img_path):
# 返回img_path路径的图像的预测向量
img = preprocess_input(path_to_tensor(img_path))
return np.argmax(ResNet50_model.predict(img))
3、完成狗狗检测模型
在研究该 清单 的时候,你会注意到,狗类别对应的序号为151-268。因此,在检查预训练模型判断图像是否包含狗的时候,我们只需要检查如上的 ResNet50_predict_labels 函数是否返回一个介于151和268之间(包含区间端点)的值。
我们通过这些想法来完成下方的 dog_detector 函数,如果从图像中检测到狗就返回 True,否则返回 False。def dog_detector(img_path):
prediction = ResNet50_predict_labels(img_path)
return ((prediction <= 268) & (prediction >= 151))
4、评估狗狗检测模型
在下方的代码块中,使用 dog_detector 函数,计算:
human_files_short中图像检测到狗狗的百分比?dog_files_short中图像检测到狗狗的百分比?

三、从头创建一个CNN来分类狗品种
1、图像预处理
通过对每张图像的像素值/255,实现归一化。
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
# Keras中的数据预处理过程
train_tensors = paths_to_tensor(train_files).astype('float32')/255
valid_tensors = paths_to_tensor(valid_files).astype('float32')/255
test_tensors = paths_to_tensor(test_files).astype('float32')/255
2、构造模型
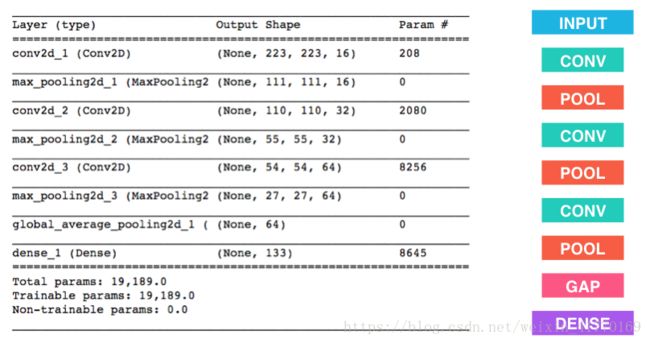
参数变化:
stride=1,kernel_size=2,填充方式为'valid'也就是不填充,则卷积时不会越界
weights bias
208=16(filter_size)*2*2(kernel_size)*3channel + 16(filter_size)
2080 = 32(filter_size)*2*2(kernel_size)*16channel + 32(filter_size)
8256 = 64(filter_size)*2*2(kernel_size)*32channel + 64(filter_size)
8645 = 64(filter_size)*133classes + 133(classes)
一开始图片大小:224*224*3
经历第一次卷积:223*223*16,第一次最大池化:111*111*16
经历第二次卷积:110*110*32,第二次最大池化:55*55*32
经历第三次卷积:54*54*64,第三次最大池化:27*27*64
全局平均池化:64
分类:133类
from keras.layers import Conv2D, MaxPooling2D, GlobalAveragePooling2D
from keras.layers import Dropout, Flatten, Dense
from keras.models import Sequential
model = Sequential()
### TODO: 定义你的网络架构
model.add(Conv2D(filters=16, kernel_size=2, padding='valid', activation='relu', input_shape=(224,224,3)))
model.add(MaxPooling2D(pool_size=2))
model.add(Conv2D(filters=32, kernel_size=2, padding='valid', activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(Conv2D(filters=64, kernel_size=2, padding='valid', activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(GlobalAveragePooling2D(input_shape=(27,27,64)))
model.add(Dense(133, activation='softmax'))
model.summary()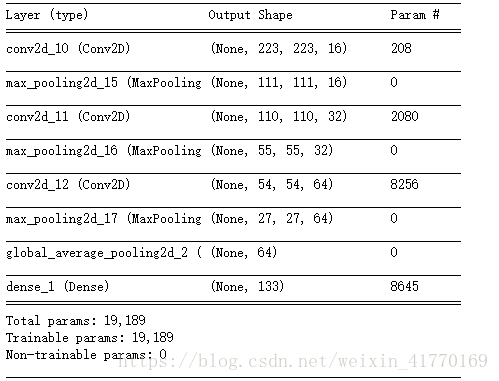
## 编译模型
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
3、训练模型
from keras.callbacks import ModelCheckpoint
### TODO: 设置训练模型的epochs的数量
epochs = 1
### 不要修改下方代码
checkpointer = ModelCheckpoint(filepath='saved_models/weights.best.from_scratch.hdf5',
verbose=1, save_best_only=True)
model.fit(train_tensors, train_targets,
validation_data=(valid_tensors, valid_targets),
epochs=epochs, batch_size=20, callbacks=[checkpointer], verbose=1)

## 加载具有最好验证loss的模型
model.load_weights('saved_models/weights.best.from_scratch.hdf5')
4、测试模型
# 获取测试数据集中每一个图像所预测的狗品种的index
dog_breed_predictions = [np.argmax(model.predict(np.expand_dims(tensor, axis=0))) for tensor in test_tensors]
# 报告测试准确率
test_accuracy = 100*np.sum(np.array(dog_breed_predictions)==np.argmax(test_targets, axis=1))/len(dog_breed_predictions)
print('Test accuracy: %.4f%%' % test_accuracy)![]()
四、使用VGG_16来区分狗的品种
使用 迁移学习(Transfer Learning)的方法,能帮助我们在不损失准确率的情况下大大减少训练时间。在以下步骤中,你可以尝试使用迁移学习来训练你自己的CNN。
1、得到从图像提取的特征向量
bottleneck_features = np.load('bottleneck_features/DogVGG16Data.npz')
train_VGG16 = bottleneck_features['train']
valid_VGG16 = bottleneck_features['valid']
test_VGG16 = bottleneck_features['test']
2、Vgg16模型架构
该模型使用预训练的 VGG-16 模型作为固定的图像特征提取器,其中 VGG-16 最后一层卷积层的输出被直接输入到我们的模型。我们只需要添加一个全局平均池化层以及一个全连接层,其中全连接层使用 softmax 激活函数,对每一个狗的种类都包含一个节点。
VGG16_model = Sequential()
VGG16_model.add(GlobalAveragePooling2D(input_shape=train_VGG16.shape[1:]))
VGG16_model.add(Dense(133, activation='softmax'))
VGG16_model.summary()
3、模型编译
## 编译模型
VGG16_model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
4、模型训练
## 训练模型
checkpointer = ModelCheckpoint(filepath='saved_models/weights.best.VGG16.hdf5',
verbose=1, save_best_only=True)
VGG16_model.fit(train_VGG16, train_targets,
validation_data=(valid_VGG16, valid_targets),
epochs=20, batch_size=20, callbacks=[checkpointer], verbose=1)
## 加载具有最好验证loss的模型
VGG16_model.load_weights('saved_models/weights.best.VGG16.hdf5')
5、模型测试
现在,我们可以测试此CNN在狗图像测试数据集中识别品种的效果如何。我们在下方打印出测试准确率。
# 获取测试数据集中每一个图像所预测的狗品种的index
VGG16_predictions = [np.argmax(VGG16_model.predict(np.expand_dims(feature, axis=0))) for feature in test_VGG16]
# 报告测试准确率
test_accuracy = 100*np.sum(np.array(VGG16_predictions)==np.argmax(test_targets, axis=1))/len(VGG16_predictions)
print('Test accuracy: %.4f%%' % test_accuracy)![]()
6、使用模型预测狗的品种
from extract_bottleneck_features import *
def VGG16_predict_breed(img_path):
# 提取bottleneck特征
bottleneck_feature = extract_VGG16(path_to_tensor(img_path))
# 获取预测向量
predicted_vector = VGG16_model.predict(bottleneck_feature)
# 返回此模型预测的狗的品种
return dog_names[np.argmax(predicted_vector)]可视化测试了两张:
