天池-工业预测总结-XGBoost
比赛网址 https://tianchi.aliyun.com/competition/entrance/231693/information
赛题分析 https://www.jianshu.com/p/f15e01d377ef?utm_campaign=haruki 文中选用了一些主流的机器学习模型测试预测结果,最终选择随机森林。
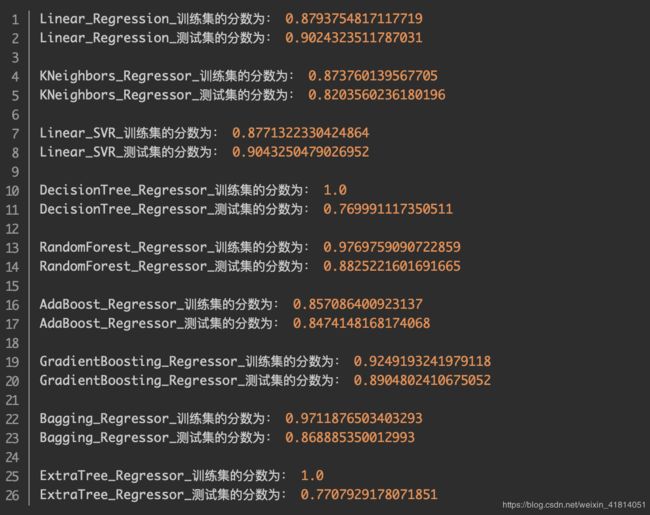
参考了他的模型结果,随机森林是多颗独立的树,在改进的时候选用了这两年比赛中效果比较显著的XGBoost。
xgboost通俗理解,以xgboost回归为例
单个决策树很难保障准确率,假设单个决策树预测为y’,真实值为y,于是产生了一个误差y-y',
xgboost针对这个误差又建立了一棵决策树,分析误差产生的原因,从而弥补这个误差,新的决策树又会产生一个误差,那么继续建立一棵决策树,如此迭代下去,这就是xgboost的大致过程。
这个过程好比我们写代码,先大致写个框架,运行一下,看看哪不对,改一下,再运行一下,看看哪不对,再改一下,如此迭代,直至完全正确。注意我们写代码时很少一下从头写到尾,因为这样很不方便调试,如果错误太多,还不如重新写,对应到决策树就是树太深,过拟合,可能需要重新训练,所以xgboost每一棵树不能太深。
xgboost原理及数学推导,可以参考以下两篇博客
https://blog.csdn.net/lukeyyanghang/article/details/87914428
https://www.cnblogs.com/zongfa/p/9324684.html
应用的XGBoost核心代码如下,特征工程部分不再分析。

模型参数训练后结果

关于XGBoost中参数意义及训练方法 可以参考此篇 https://blog.csdn.net/u010665216/article/details/78532619
特别作者提到 “不要幻想仅仅通过参数调优或者换一个稍微更好的模型使得最终结果有巨大的飞跃。要想最后的结果有巨大的提升,可以通过特征工程、模型集成来实现。” 深以为然。
另外模型中涉及到的sklearn交叉验证,这篇博客有比较系统的说明供参考https://blog.csdn.net/luanpeng825485697/article/details/79836262
这里也顺便补充一下另一个大杀器lightgbm吧
传统的boosting算法(如GBDT和XGBoost)已经有相当好的效率,但是在如今的大样本和高维度的环境下,传统的boosting似乎在效率和可扩展性上不能满足现在的需求了,主要的原因就是传统的boosting算法需要对每一个特征都要扫描所有的样本点来选择最好的切分点,这是非常的耗时。为了解决这种在大样本高纬度数据的环境下耗时的问题,Lightgbm使用了如下两种解决办法:一是GOSS(Gradient-based One-Side Sampling, 基于梯度的单边采样),不是使用所用的样本点来计算梯度,而是对样本进行采样来计算梯度;二是EFB(Exclusive Feature Bundling, 互斥特征捆绑) ,这里不是使用所有的特征来进行扫描获得最佳的切分点,而是将某些特征进行捆绑在一起来降低特征的维度,是寻找最佳切分点的消耗减少。这样大大的降低的处理样本的时间复杂度,但在精度上,通过大量的实验证明,在某些数据集上使用Lightgbm并不损失精度,甚至有时还会提升精度。
详细原理:https://blog.csdn.net/qq_24519677/article/details/82811215
主要关注应用,调参原理
1 针对 Leaf-wise(Best-first)树的参数优化
(1)num_leaves这是控制树模型复杂度的主要参数。理论上, 借鉴 depth-wise 树, 我们可以设置 num_leaves= 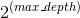
(2)min_data_in_leaf. 这是处理 leaf-wise 树的过拟合问题中一个非常重要的参数. 它的值取决于训练数据的样本个树和 num_leaves. 将其设置的较大可以避免生成一个过深的树, 但有可能导致欠拟合. 实际应用中, 对于大数据集, 设置其为几百或几千就足够了。
(3)max_depth(默认不限制,一般设置该值为5—10即可) 你也可以利用 max_depth 来显式地限制树的深度。
2 针对更快的训练速度
(1)通过设置 bagging_fraction 和 bagging_freq 参数来使用 bagging 方法;
(2)通过设置 feature_fraction 参数来使用特征的子抽样;
(3)使用较小的 max_bin;
(4)使用 save_binary 在以后的学习过程对数据进行加速加载。
3 针对更好的准确率
(1)使用较大的 max_bin (学习速度可能变慢);
(2)使用较小的 learning_rate 和较大的 num_iterations;
(3)使用较大的 num_leaves (可能导致过拟合);
(4)使用更大的训练数据;
(5)尝试 dart(一种在多元Additive回归树种使用dropouts的算法).
4 处理过拟合
(1)使用较小的 max_bin(默认为255)
(2)使用较小的 num_leaves(默认为31)
(3)使用 min_data_in_leaf(默认为20) 和 min_sum_hessian_in_leaf(默认为)
(4)通过设置 bagging_fraction (默认为1.0)和 bagging_freq (默认为0,意味着禁用bagging,k表示每k次迭代执行一个bagging)来使用 bagging
(5)通过设置 feature_fraction(默认为1.0) 来使用特征子抽样
(6)使用更大的训练数据
(7)使用 lambda_l1(默认为0), lambda_l2 (默认为0)和 min_split_gain(默认为0,表示执行切分的最小增益) 来使用正则
(8)尝试 max_depth 来避免生成过深的树