基于python的贴吧舆情监控助手实战
关于一个设想
wap版贴吧现已重新生效(2020.4.29)!!
贴吧已死,这是现状。据说百度的贴吧组已经没有新人加入,只许出不许进,可以说日薄西山。但是现在仍然作为中文第一社区还是有很大的影响力,同时女朋友的工作性质又与贴吧那么一点点的联系,所以准备这样一个贴吧监控助手项目。
再者就是开始着手舆情分析,大数据挖掘,向前沿靠近。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2bfPyGib-1588146402090)(http://pbnsc9qwg.bkt.clouddn.com/u=3105521460,2871723561&fm=27&gp=0.jpg)]
开始的思考
贴吧的性质与网易云之流还是有很大的差别,所以方向也不同。
前期工作的难度在于判断贴吧的加载是否是ajax形式,研究后发现虽然不是静态加载,早几年的老版贴吧应该是静态加载,然后由匿名发帖爆吧和下掉权限的删吧太猖獗导致如今的ajax形式,这也是大趋势。但是于网易云音乐的不同的分析贴吧请求,虽然没有xhr或者json形式的数据贴子,但是好在贴吧是get形式,没有加密的数据体。
接收到的只是一个页面,估计是经过百度处理过的。至于为什么不是json形式一定的原因是因为防止拿去做第三方客户端吧,毕竟百度自己的贴吧客户端是真的难用。
但是在研究过程中发现web版的贴吧还未关闭,并且不需要登陆即可查询所有相关楼中楼,并且页面代码也更加友好。所以转战用web版贴吧
api地址是:
单个贴吧
http://tieba.baidu.com/mo/q—9CC3CD881B0FE2BA30F4559A6AF8A941%3AFG%3D1-sz%40320_240%2C-1-3-0–2--wapp_1531379582221_177/m?kw=%E6%9E%97%E4%BF%8A%E6%9D%B0&lp=5011&lm=&pn=0
贴吧关键词kw=林俊杰,pn=页数(0,20,40,60…)
api的尝试
首先思考的是能否先造轮子,这样分步进行可以方便对整个项目的拆分以及功能的明确化。所以首先尝试集成贴吧的api,后面的监控通过api来调用。
Get贴吧帖子ID
web端模拟
进行web访问,在多次尝试后发现贴吧web端能够直接访问,而不需要模拟手机。但是我们无法得知会不会在某个时间点被限制,所以对他进行模拟 token。
'User-Agent': 'Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Mobile Safari/537.36'
在集成好headers之后,可以着手开始编写api规则。
约定俗称
我发现好的api他们的形参的设定是特别明确并且巧妙的,这里先开发一个贴吧主页的帖子ID收集,按页来返回。所以,我需要知道调用者他要访问哪一个贴吧,并且想要哪几页的参数。不能无止境的爬取,所以这里给定一个范围。
这里就设定好了三个参数
- key:贴吧关键词
- Start:开始页数
- End:结束页数
key值虽然是贴吧关键词,但是却影响关键词是否错误,该吧是否尚未建立(被封)?这些情况都是要做分析处理的。End需要关心的是,该key是否有这一页,譬如说一个新贴吧,他只有3页帖子,但是我们却要End设置成6显然这是不合适的,所以这里也要处理。Start跟End有相同的问题,但是从实际的角度来将End解决了Start也就解决了。
web端的页数表达与PC端有所区别,以20为一页,所以这里需要做一个转化:
Start = Start*20-20
# 防止出现输入0的情况
if Start == -20:
Start = 0
End = End*20
for i in range(Start,End,20)
在观察以第一页(我们也以第一页为例),我需要的获取到的关键信息则是帖子的标题,作者,时间,以及kz(ID),幸运的是在页面中都是以div的形式存放的。
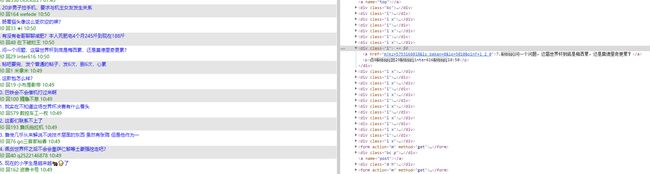
所以这里直接用BeautifulSoup来获取即可:
Soup.select('div.i')
获取到的内容:
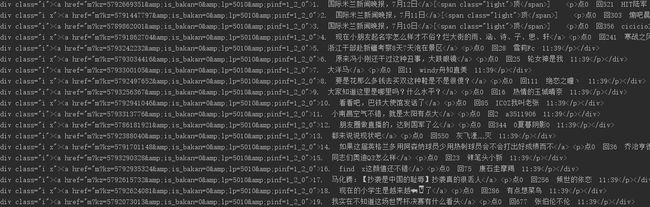
其实这里还可以继续用到BeautifulSoup来处理,但是为了省事直接用re正则表达式来解决。
pattern = re.compile('kz=(.*?)&.*?">(.*?).*?回([0-9]\d*)\s(.*?)\s(.*?)',re.S)

差不多已经整理完了,只是需要对标题进行修该,移除掉其中的“11.\xa0”这样的html上的代码。
接下来为了能够做第三方客户端(友好),这里需要做做一个分页处理。
Page = {
str(int((i + 20) / 20)): SouList
}
Son = {
'Id':items[0][0],
'Title':Title,
'Reply':items[0][2],
'Author':items[0][3],
'Time':items[0][4]
}
SouList.append(Son)
最后将这个SouList转化为json
Result = json.dumps(ReturnJson,ensure_ascii=False)
唯一需要注意的是,在做赋值的过程中,python的原理好像是引入型。在代码注释中我也提到过,所以要引入copy包
SuperList.append(copy.deepcopy(Page))
这样基本上就做好一个api接口了,返回是以json形式。
返回的结果:

校验的结果:

Get 帖子内容
在获取到帖子基本数据后,就要获取页面内容。帖子在web的内容是很简洁的,并且没有广告。

最重要的是,相对于网页端,web端的楼中楼是不受登陆限制的,可以没有任何条件的获取到我们想要的任何一个楼中楼的信息,唯一需要注意的是,每一个楼中楼的层数是不确定的,所以这里要做判断不能根据页数,这里我是试验后果才明白。

所以思来想去发现当楼中楼达到最后一页,没有内容之后是没有“下一页”提示,所以就以“下一页”为关键词来筛别。
这里ID作为唯一的参数,这一部分大体上与获取ID基本一致,这里需要注意的是一楼跟其他楼是有所区别的,所以需要对re做分情况处理:
if count == 1 and page == 0:
pattern = re.compile('class="i">1楼.\s(.*?).*?(.*?).*?class="b">(.*?)\d*楼.\s(.*?).*?(.*?).*?class="b">(.*?).*?href="(.*?)">回复(.*?)', re.S)
items = re.findall(pattern, str(OneContent))
Text = items[0][0]
Author = items[0][1]
Time = items[0][2]
Floor = items[0][4][1:-1]
# print(items)
FloorInFloor = []
if not (Floor == '' or Floor == None):
# print(items[0][2])
FloorInFloor = GetFloorInFloor(url=items[0][3])
SonDict['Text'] = Text
SonDict['Author'] = items[0][1]
SonDict['Time'] = Time
SonDict['FloorInFloor'] = FloorInFloor
FatherList.append(copy.deepcopy(SonDict))
FloorInFloor.clear()
SonDict.clear()
以及对于楼中楼的内容获取,都是基于获取到单个回复之后再来获取这个回复的楼中楼,类似一只虫这样子。
所以在做完与以上相同的处理之后:

Sentiment
关于关键词以及舆情
Sentiment部分从无到有经历了三个步骤,也是三个部分。
-
从需要收集的贴吧开始,获取相关的贴子内容,这里API的两个重要方法全部运用到了,这里可以称作收集阶段。
-
从需要分析的关键词开始,分析第一部分获得信息,进行分类和处理,总体而言第二部分是核心。
-
从获得与关键词相关联的内容开始,进行加工,怎么更加直观的将内容呈现给需求方,这里很考验一种经验和想法。
配置配置
相较于小程序,这里需要配置文件开始初始化参数。所以通过API以及刚提到的第一部分,我归列了这些参数。
- tb:需要监控的贴吧名
- Essential:监控关键词
- Start:开始页数
- End:结束页数
- Sleep:运转周期
有些监控是不需要实时反馈的,所以这里用Sleep来做休息,休息一个周期后在来重新监控收集。
显然,我们监控的贴吧以及关键词都不是单个,所以运用configparser库读取配置文件,将两者都转化为list,方便程序初始化运转。
config = configparser.ConfigParser()
# 编码要设置成utf-8-sig而并不是utf-8
config.read('TiebaSetting.conf', encoding='utf-8-sig')
key = config.get("Setting", "tb")
keyList = key.split(',')
Essential = config.get("Customize", "Essential")
EssentialList = Essential.split(',')
# 休息周期
X = config.getint("Setting", "Sleep")
# 开始页数
Start = config.getint("Setting", "Start")
# 结束页数
End = config.getint("Setting", "End")
这里,我将用api中的GetID获取到的ID全部存取,这里只需要ID,在装载成list之后再用API的GetTiebaOne()方法获取到帖子内容。在得到想要的内容后,就要开始进行处理。
关键词分析
关键词分析在第二部分由为重要,上面提到在做关键词存放在list,这里遍历对所有的内容进行遍历。这里其实有一个很重要的Tips就是,在第一部分内容处理的时候就可以进行判断,而不用子啊做好存取之后在继而分开做处理,难免降低效率。
def OneToOne(Text):
for i in EssentialList:
if i in Text:
return True
当然,如果是做舆情导向类似于这样的方案也就是不一样的想法了。如果做热点分析,这里可以用分词来处理,解析处理掉几个常用的高频词,最后呈现的就是近来热点。
这只是一个抛砖引玉的想法,还有更多很好的想法需要发掘…
呈现
其实表达部分是修改最多的,修修补补。这里要有更新和比较,因为这里周期性的本质就是用作对比相邻周期的不同。
def ComparisonDict():
for x in Save:
for i,y in zip(OldSave,range(1,len(OldSave)+1)):
if x == i:
# 值相同
if not Save[x] == OldSave[i]:
NewList.append(str(i))
break
if y == len(OldSave) and x != i:
NewList.append(str(x))
OldSave.clear()
OldSave.update(copy.deepcopy(Save))
Save.clear()
这一段要小心很多陷阱。
其中需要删减掉很多不需要要的信息,一些html的代码。再是可以对内容进行一个不同的呈现。
在是可以动态修改我们需求的配置内容,因为相关在变化。
然后呈现的就是给需求方:

微信控制
微信是我一开始就像用作控制器和显示方式,所以需要加入itchat包。
首先加入的是图灵机器人,因为想找一个陪聊机,然后在加入tieba的舆情监控。
图灵需要接入图灵的官方API,只需要注册一个图灵,申请一个免费的key即可。
图灵官网
然后加入监控,需要多线程,单纯的示例程序以及单线程是无法完成的,虽然如果只是手动给予命令可以完成,但是效率很低,并且在面对大贴吧的时候无法做到即输即到,所以加入线程,设定周期。只需在前期配置好配置文件即可,其他的就让它自己运作就可,获得数据之后自动发送。
所以这里线程需要多开一个,开启监控以及修改配置:
def Main():
global T
while 1:
C = tieba.Main()
print('This is myitchat: '+ str(C) )
print(T)
if C == None or C == [] or C == ' ':
continue
if T == 1:
T = 0
if T ==0:
itchat.send_msg('监控到更新的数据 \n \n'+str(C),toUserName=id)
tieba.ini()
tie = threading.Thread(target=Main(), )
tie.start()
监控设置:
if msg['Text'] == '开启监控' and (id == '' or id ==None ):
# 引用全局变量
id = msg['FromUserName']
itchat.send_msg('已经开启监控~', toUserName=id)
itchat.send_msg(tieba.setting(), toUserName=id)
return
if msg['Text'] == '修改配置' and id == msg['FromUserName']:
Setting = tieba.GetSetting()
a = {
'监控贴吧列表':Setting[0],
'监控关键词':Setting[1],
'监控周期(S)':Setting[2],
'开始页数':Setting[3],
'结束页数': Setting[4]
}
itchat.send_msg('修改以下列信息,并且将修改后的信息复制发送', toUserName=id)
itchat.send_msg(str(a), toUserName=id)
return
完成
开启监控:
修改配置:
监控内容:
Github
项目完整程序在我的Github上:
TieBa-API-Sentiment
一些思考
这个项目拉了很长的战线,来来回回耗时了半个月,其实一个星期就可以完成的一个小demo被拖了这么久,有很多原因需要思考,不光光是程序外的原因,程序背身的设计和思路在设定时就没有很认真的思考,而是修修补补出现问题再来改正。
这样难免很耗时耗力。
但这项目算法涉及很少,虽然可以用到某些算法,但是在设计过程中还是想以简单为主,这是其一。再是在某些技巧以及方法上使用还是不够熟练,没有明白该方法的设计思想和原理,虽然期间学到了很多,但是仍然不够。
现在基本上可以做很多事情了,但是还是要继续学习很多专业相关,譬如前端的一些原理以及http的原理。