吴恩达机器学习课后习题(一):线性回归
(硬着头皮写完了,但是不理解我写的是什么,为什么要这样写?)
1. 简单的Octave / MATLAB功能
ex1.m的第一部分为您提供Octave / MATLAB语法和作业提交过程。在文件warmUpExercise.m中,您将找到Octave / MATLAB函数的轮廓。通过填写以下代码修改它以返回5 x 5的矩阵:
function A = warmUpExercise()
%WARMUPEXERCISE Example function in octave
% A = WARMUPEXERCISE() is an example function that returns the 5x5 identity matrix
A = [];
% ============= YOUR CODE HERE ==============
% Instructions: Return the 5x5 identity matrix
% In octave, we return values by defining which variables
% represent the return values (at the top of the file)
% and then set them accordingly.
A=eye(5);
% ===========================================
end
完成后,运行ex1.m(假设您位于正确的目录中,在Octave / MATLAB提示符下键入“ ex1”),您应该看到输出类似于以下内容:

现在ex1.m将暂停,直到您按任意键,然后运行代码在下一部分作业中。如果您想退出,请输入ctrl-c在运行过程中停止该程序。
1.1 提交解决方案
完成一部分练习后,您可以提交解决方案通过在Octave / MATLAB命令行中输入Submit进行评分。子任务脚本将提示您输入登录电子邮件和提交令牌并询问您要提交的文件。您可以获取提交网页中用于分配的令牌。
You should now submit your solutions.
您可以多次提交解决方案,我们将采取仅考虑最高分。
2. 单变量线性回归
在本练习的这一部分中,您将使用变量以预测餐车的利润。假设您是某公司的首席执行官餐厅专营权,并正在考虑不同城市开设新餐厅出口。该连锁店在各个城市已经有卡车,并且您有关于城市的利润和人口。
您想使用此数据来帮助您选择要扩展的城市
到下一个。
文件ex1data1.txt包含线性回归问题的数据集。第一列是城市人口,第二列是在那个城市,一辆食品卡车的利润。利润的负值表示失利。
已经设置了ex1.m脚本来为您加载此数据。
2.1 绘制数据
在开始任何任务之前,了解以下信息通常很有用通过可视化它。对于此数据集,您可以使用散点图来可视化数据,因为它只有两个要绘制的属性(利润和人口)。 (许多您在现实生活中会遇到的其他问题是多维的无法在二维绘图上绘制。)
在ex1.m中,数据集从数据文件加载到变量X中和y:
data = load('ex1data1.txt'); % read comma separated data
X = data(:, 1); y = data(:, 2);
m = length(y); % number of training examples
接下来,脚本调用plotData函数来创建散点图数据。您的工作是完成plotData.m绘制图;修改文件并填写以下代码:
function plotData(x, y)
%PLOTDATA Plots the data points x and y into a new figure
% PLOTDATA(x,y) plots the data points and gives the figure axes labels of
% population and profit.
figure; % open a new figure window
% ====================== YOUR CODE HERE ======================
% Instructions: Plot the training data into a figure using the
% "figure" and "plot" commands. Set the axes labels using
% the "xlabel" and "ylabel" commands. Assume the
% population and revenue data have been passed in
% as the x and y arguments of this function.
%
% Hint: You can use the 'rx' option with plot to have the markers
% appear as red crosses. Furthermore, you can make the
% markers larger by using plot(..., 'rx', 'MarkerSize', 10);
plot(x,y,'rx','MarkerSize',10);
ylabel('Profit in $10,000s');
xlabel('Population of City in 10,000s');
% ============================================================
end
现在,当您继续运行ex1.m时,我们的最终结果应该像图1,带有相同的红色“ x”标记和轴标签。
要了解有关plot命令的更多信息,可以在Octave / MATLAB命令提示符或在线搜索绘图文件。 (要将标记更改为红色的“ x”,我们使用了“ rx”选项连同plot命令,即plot(…,[此处为您的选项],…,“RX”); )
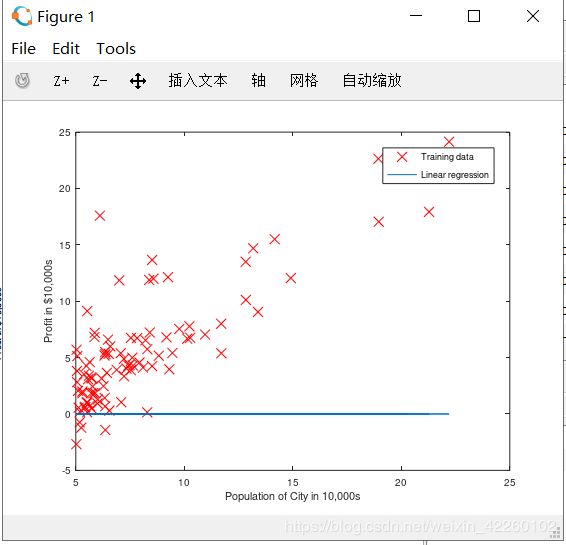
Figure 1: Scatter plot of training data
2.2 梯度下降
在这一部分中,您使用梯度下降将使线性回归参数θ适合我们的数据集。
2.2.1 更新方程式
线性回归的目的是最小化代价函数。
J ( θ ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J(θ) =\frac{1}{2m}\sum_{i=1}^{m}(h_{\theta}(x^{(i)})-y^{(i)})^{2} J(θ)=2m1∑i=1m(hθ(x(i))−y(i))2
假设hθ(x)由线性模型给出
h θ ( x ) = θ T x = θ 0 + θ 1 x 1 h_{\theta}(x)=\theta^{T}x=\theta_{0}+\theta_{1}x_{1} hθ(x)=θTx=θ0+θ1x1
回想一下,模型的参数是θj值。这些是您将调整以最小化成本J(θ)的值。一种方法是使用批次梯度下降算法。在批量梯度下降中,每个迭代执行更新
θ j : = θ j − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) \theta_{j}:=\theta_{j}-\alpha\frac{1}{m}\sum_{i=1}^{m}(h_{\theta}(x^{(i)})-y^{(i)})x_{j}^{(i)} θj:=θj−αm1∑i=1m(hθ(x(i))−y(i))xj(i)(同时更新θj对于所有j)。
随着梯度下降的每一步,您的参数θj都更接近于达到最低成本J(θ)的最佳值。
实施注意:我们将每个示例都存储在X中的一行中Octave/ MATLAB中的矩阵。考虑到截距项(θ0),我们在X上添加了第一列并将其设置为全部。这允许我们将θ0视为另一个“特征”。
2.2.2 实现
在ex1.m中,我们已经设置了用于线性回归的数据。在里面接下来的几行,我们在数据中添加了另一个维度,以适应θ0截距项。我们还将初始参数初始化为0,然后将学习率alpha为0.01。
X = [ones(m, 1), data(:,1)]; % Add a column of ones to x
theta = zeros(2, 1); % initialize fitting parameters
% Some gradient descent settings
iterations = 1500;
alpha = 0.01;
2.2.3 计算代价 J ( θ ) J(\theta) J(θ)
当您执行梯度下降以学习最小化成本函数J(θ)时,通过计算成本来监控收敛是有帮助的。在这部分,您将实现一个计算J(θ)的函数,因此您可以检查梯度下降实现的收敛。
您的下一个任务是完成文件computeCost.m中的代码,该文件是计算J(θ)的函数。在执行此操作时,请记住变量X和y不是标量值,而是代表的矩阵训练集中的例子。
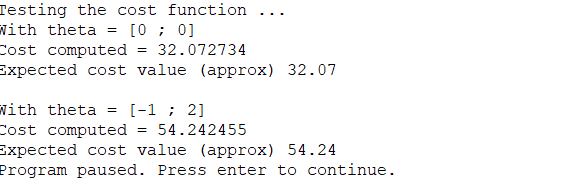
完成功能后,将运行ex1.m中的下一步使用θ初始化为零的computeCost,您将看到成本打印到屏幕上。
您应该会看到成本为32.07。
function J = computeCost(X, y, theta)
%COMPUTECOST Compute cost for linear regression
% J = COMPUTECOST(X, y, theta) computes the cost of using theta as the
% parameter for linear regression to fit the data points in X and y
% Initialize some useful values
m = length(y); % number of training examples
% You need to return the following variables correctly
J = 0;
% ====================== YOUR CODE HERE ======================
% Instructions: Compute the cost of a particular choice of theta
% You should set J to the cost.
J=sum((X*theta-y).^2)/(2*m);
% =========================================================================
end
2.2.4 梯度下降
接下来,您将在gradientDescent.m文件中实现梯度下降。已经为您编写了循环结构,您只需要提供每次迭代中对θ的更新。
在编程时,请确保您了解要优化的内容和正在更新的内容。请记住,成本J(θ)由向量θ而不是X和y来参数化。也就是说,我们将J(θ)的值最小化通过改变矢量θ的值,而不是通过改变X或y。如果不确定,可以在本讲义和视频讲座中找到方程式。
验证梯度下降是否正常工作的一种好方法是查看取J(θ)的值,并检查其每步是否减小。该每次迭代时,gradientDescent.m的启动程序代码都会调用computeCost并打印成本。假设您实施了梯度下降,正确地计算成本,您的J(θ)值永远不会增加,并且应该在算法结束时收敛到稳定值。
完成后,ex1.m将使用最终参数来绘制线性拟合。结果应类似于图2:
您最终的θ值也将用于预测35,000和70,000人。请注意以下各行的方式ex1.m使用矩阵乘法而不是显式求和或循环来计算预测。这是代码中的向量化示例在Octave/ MATLAB。
function [theta, J_history] = gradientDescent(X, y, theta, alpha, num_iters)
%GRADIENTDESCENT Performs gradient descent to learn theta
% theta = GRADIENTDESCENT(X, y, theta, alpha, num_iters) updates theta by
% taking num_iters gradient steps with learning rate alpha
% Initialize some useful values
m = length(y); % number of training examples
J_history = zeros(num_iters, 1);
for iter = 1:num_iters
% ====================== YOUR CODE HERE ======================
% Instructions: Perform a single gradient step on the parameter vector
% theta.
%
% Hint: While debugging, it can be useful to print out the values
% of the cost function (computeCost) and gradient here.
%
temp0=theta(1,1)-alpha*sum(X*theta-y)/m;
temp1=theta(2,1)-alpha*sum((X*theta-y).*X(:,2))/m;
theta(1,1)=temp0;
theta(2,1)=temp1;
% ============================================================
% Save the cost J in every iteration
J_history(iter) = computeCost(X, y, theta);
end
end

2.3 调试
实施梯度下降时,请注意以下几点:
- Octave / MATLAB数组索引从1开始,而不是零。如果将θ0和θ1存储在称为theta的向量中,则值将为theta(1)和theta(2)。
- 如果在运行时看到许多错误,请检查矩阵操作以确保您要添加和乘以兼容尺寸的矩阵。用大小打印变量的尺寸命令将帮助您调试。
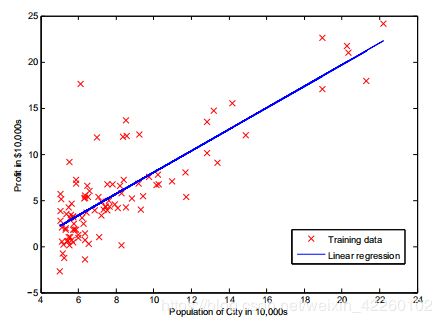
Figure 2: Training data with linear regression fit - 默认情况下,Octave / MATLAB将数学运算符解释为矩阵运营商。这是大小不兼容错误的常见原因。如果你不需要矩阵乘法,您需要添加“点”符号将此指定为Octave / MATLAB。例如,A * B做一个矩阵乘,而A. * B进行逐元素乘法。
2.4 可视化 J ( θ ) J(\theta) J(θ)
为了更好地了解成本函数J(θ),现在将成本绘制在θ0和θ1值的二维网格。您无需编写任何代码,这部分是新的,但您应该了解所编写的代码已经在创建这些图像。
在ex1.m的下一步中,使用您编写的computeCost函数来计算a上J(θ)的值网格。
% Grid over which we will calculate J
theta0_vals = linspace(-10, 10, 100);
theta1_vals = linspace(-1, 4, 100);
% initialize J_vals to a matrix of 0's
J_vals = zeros(length(theta0_vals), length(theta1_vals));
% Fill out J_vals
for i = 1:length(theta0_vals)
for j = 1:length(theta1_vals)
t = [theta0_vals(i); theta1_vals(j)];
J_vals(i,j) = computeCost(X, y, t);
end
end
执行完这些行后,您将拥有J(θ)值的二维数组。然后,脚本ex1.m将使用这些值来生成曲面和轮廓,使用surf和contour命令绘制J(θ)曲线。情节应该看起来如图3所示:
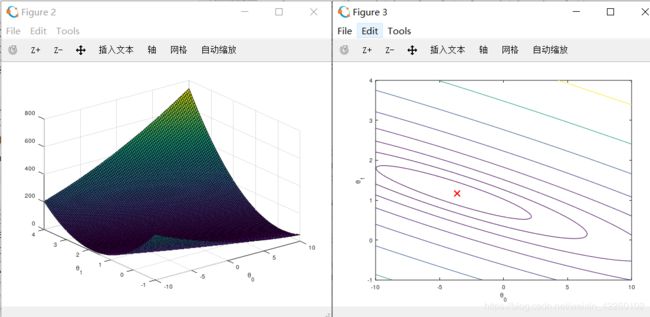
Figure 3: Cost function J(θ)
这些图的目的是向您展示J(θ)如何随θ0和θ1改变的。成本函数J(θ)是碗形的并且具有全局的最小值。 (在轮廓图中比在3D曲面中更容易看到情节)。这个最小值是θ0和θ1的最佳点,并且每个步长梯度下降更接近此点。
可选练习
3 多元线性回归
在这一部分中,您将使用多个变量来实现线性回归预测房屋价格。假设您正在出售房屋,而您想知道什么是好的市场价格。一种方法是首先收集有关最近出售房屋的信息,并建立房屋价格模型。
文件ex1data2.txt包含俄勒冈州波特兰市的房屋价格培训集。第一列是房屋的大小(以平方英尺为单位),第二列是卧室数,第三列是这所房子的价格。
已设置ex1 multi.m脚本来帮助您逐步完成此操作。
3.1 特征归一化
ex1_multi.m脚本将从这个数据集加载和显示一些值开始。通过查看这些值,注意到房子的大小大约是卧室数量的1000倍。当特征相差数量级时,首先进行特征缩放可以使梯度下降收敛的快得多。
您的任务是完成featureNormalize.m中的代码以
- 从数据集中减去每个特征的平均值。
- 减去平均值后,额外缩放(除以)特征值根据各自的“标准偏差”。
标准偏差是在特定要素的值范围内一种衡量存在多少变化的方法(大多数数据点将位于平均值的±2标准偏差);这是替代范围值的最大值(最大值-最小值)。
在Octave / MATLAB中,您可以使用“ std”函数计算标准偏差。例如,在featureNormalize.m中,数组X(:,1)包含训练集中x1的所有值(房屋大小),因此std(X(:,1))计算房屋尺寸的标准偏差。
在调用featureNormalize.m时,附加的1尚未将与x0 = 1对应的值添加到X中(有关详细信息,请参见ex1 multi.m细节)。
您将对所有的特性都这样做并且您的代码应该和所有大小的数据集(任意数量的特性/示例)都能工作。注意,每个矩阵X的列对应一个特征。
function [X_norm, mu, sigma] = featureNormalize(X)
%FEATURENORMALIZE Normalizes the features in X
% FEATURENORMALIZE(X) returns a normalized version of X where
% the mean value of each feature is 0 and the standard deviation
% is 1. This is often a good preprocessing step to do when
% working with learning algorithms.
% You need to set these values correctly
X_norm = X;
mu = zeros(1, size(X, 2));
sigma = zeros(1, size(X, 2));
% ====================== YOUR CODE HERE ======================
% Instructions: First, for each feature dimension, compute the mean
% of the feature and subtract it from the dataset,
% storing the mean value in mu. Next, compute the
% standard deviation of each feature and divide
% each feature by it's standard deviation, storing
% the standard deviation in sigma.
%
% Note that X is a matrix where each column is a
% feature and each row is an example. You need
% to perform the normalization separately for
% each feature.
%
% Hint: You might find the 'mean' and 'std' functions useful.
%
mu=mean(X);
sigma=std(X);
mu_t=repmat(mu,size(X,1),1);
sigma_t=repmat(sigma,size(X,1),1);
X_norm=(X-mu_t)./sigma_t
% ============================================================
end
3.2 梯度下降
之前,您对单变量回归问题实现了梯度下降。现在唯一的区别是,在矩阵x中还有一个特征,假设函数和批量梯度下降更新规则保持不变。
您应该在computeCostMulti.m和gradientDescentMulti.m中完成代码,实现多变量线性回归的成本函数和梯度下降。如果前一部分(单变量)中的代码已经支持多个变量,您也可以在这里使用它。
确保您的代码支持任意数量的特性,并且是良好的矢量化的。您可以使用“size(X, 2)”来找出数据集中有多少特性。
实现注意:在多元情况下,cost函数也可以写成如下矢量化形式:
J ( θ ) = 1 2 m ( X θ − y ˉ ) T ( X θ − y ˉ ) J(\theta)=\frac{1}{2m}(X\theta-\bar{y})^{T}(X\theta-\bar{y}) J(θ)=2m1(Xθ−yˉ)T(Xθ−yˉ)
where
X = [ − ( x ( 1 ) ) T − − ( x ( 2 ) ) T − . . . − ( x ( m ) ) T − ] , y ˉ = [ y ( 1 ) y ( 2 ) . . . y ( m ) ] X=\begin{bmatrix} -(x^{(1)})^{T}-\\ -(x^{(2)})^{T}-\\ ...\\ -(x^{(m)})^{T}- \end{bmatrix},\bar{y}=\begin{bmatrix} y^{(1)}\\ y^{(2)}\\ ...\\ y^{(m)} \end{bmatrix} X=⎣⎢⎢⎡−(x(1))T−−(x(2))T−...−(x(m))T−⎦⎥⎥⎤,yˉ=⎣⎢⎢⎡y(1)y(2)...y(m)⎦⎥⎥⎤
当您使用诸如Octave/MATLAB之类的数值计算工具时,矢量化版本非常有效。如果你是矩阵运算的专家,你可以证明这两种形式是等价的。
3.2.1 可选(未分级)练习:选择学习率
在练习的这一部分中,您将尝试不同的数据集学习率,并找到一个收敛速度很快的学习率。您可以通过修改ex1.multi来改变学习速度。并改变代码中设置学习速度的部分。
下一阶段在ex1 multi.m将会调用你的gradientDescent.m函数并且以所选的学习速度进行约50次的梯度下降迭代。函数应该返回J(θ)的历史值在一个向量J .在最后一次迭代之后, ex1 multi.m脚本根据迭代次数绘制J值。
如果您选择了一个良好范围内的学习率,您的图如图4所示。如果你的图看起来很不同的,尤其是如果你的价值的J(θ)增加甚至炸毁,调整学习速率,再试一次。我们推荐的学习速率值α在对数尺度,在乘法步骤的前一个值(即3倍左右。, 0.3, 0.1, 0.03, 0.01等等)。您还可能需要调整正在运行的迭代次数,如果这样可以帮助您看到曲线中的总体趋势。
function [theta, J_history] = gradientDescentMulti(X, y, theta, alpha, num_iters)
%GRADIENTDESCENTMULTI Performs gradient descent to learn theta
% theta = GRADIENTDESCENTMULTI(x, y, theta, alpha, num_iters) updates theta by
% taking num_iters gradient steps with learning rate alpha
% Initialize some useful values
m = length(y); % number of training examples
J_history = zeros(num_iters, 1);
n=length(theta);
theta_t=theta;
for iter = 1:num_iters
% ====================== YOUR CODE HERE ======================
% Instructions: Perform a single gradient step on the parameter vector
% theta.
%
% Hint: While debugging, it can be useful to print out the values
% of the cost function (computeCostMulti) and gradient here.
%
for j=1 : n
theta_t(j,1)=theta(j,1)-alpha*sum((X*theta-y).*X(:,j))/m
end
theta=theta_t;
% ============================================================
% Save the cost J in every iteration
J_history(iter) = computeCostMulti(X, y, theta);
end
end
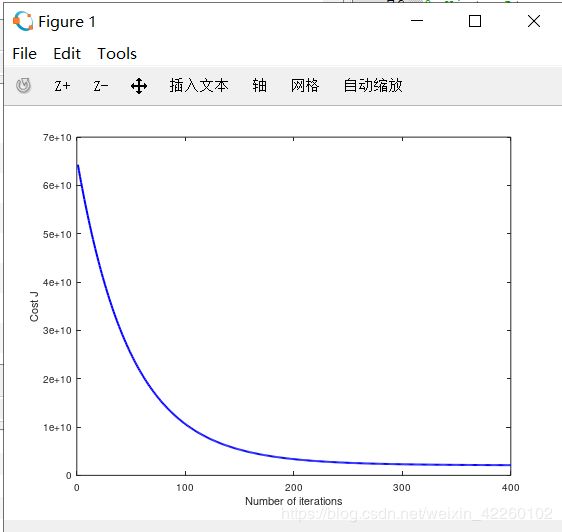
Figure 4: Convergence of gradient descent with an appropriate learning rate
实施注意:如果您的学习率太大,则J(θ)会发散并“爆炸”,从而导致值太大,无法进行计算机计算。 在这种情况下,Octave / MATLAB将倾向于返回NaN。 NaN代表“非数字”,通常是由涉及-∞和+∞的未定义运算引起的。
Octave/ MATLAB提示:为了比较不同的学习速率对收敛的影响,在同一图上绘制多个学习速率的J会很有帮助。 在Octave / MATLAB中,可以通过在图之间使用“保持”命令多次执行梯度下降来完成。 具体来说,如果您尝试了三个不同的alpha值(可能应该尝试更多的值)并将成本存储在J1,J2和J3中,则可以使用以下命令将它们绘制在同一图上:
plot(1:50,J1(1:50),'b');
hold on;
plot(1:50,J2(1:50),'r');
plot(1:50,J3(1:50),'k');
最后的参数“ b”,“ r”和“ k”为图表指定了不同的颜色。
注意随着学习率的变化收敛曲线的变化。学习率较小时,您会发现梯度下降需要很长时间才能收敛到最佳值。 相反,在学习率较高的情况下,梯度下降可能不会收敛,甚至可能发散!
使用找到的最佳学习率,运行ex1_multi.m脚本运行梯度下降直至收敛,以找到θ的最终值。 接下来,使用此θ值来预测1650平方英尺和3卧室的房屋的价格。 稍后将使用value来检查法线方程的实现。 进行此预测时,请不要忘记归一化您的特征!
您无需针对这些可选(未分级)提交任何解决方案练习。
3.3 正态方程
在讲座视频中,您了解到线性回归的闭式解是
θ = ( X T X ) − 1 X T y ˉ \theta=(X^{T}X)^{-1}X^{T}\bar{y} θ=(XTX)−1XTyˉ
使用此公式不需要任何特征缩放,并且您将在一个计算中获得确切的解决方案:没有像梯度下降这样的“直到收敛的循环”。
完成normalEqn.m中的代码以使用上面的公式计算θ。 请记住,虽然您不需要缩放要素,但我们仍然需要在X矩阵中添加一列1以具有截距项(θ0)。
ex1.m中的代码将为您添加1的列。
function [theta] = normalEqn(X, y)
%NORMALEQN Computes the closed-form solution to linear regression
% NORMALEQN(X,y) computes the closed-form solution to linear
% regression using the normal equations.
theta = zeros(size(X, 2), 1);
% ====================== YOUR CODE HERE ======================
% Instructions: Complete the code to compute the closed form solution
% to linear regression and put the result in theta.
%
theta=pinv(X'*X)*X'*y;
% ---------------------- Sample Solution ----------------------
% -------------------------------------------------------------
% ============================================================
end