高级网页抓取:如何绕过雷区,抓取成功
介绍
我不会真的考虑网站刮我的爱好或任何东西,但我想我做了很多。看起来我所处理的许多事情都要求我掌握不能以任何其他方式获得的数据。我需要对Intoli的游戏进行静态分析,因此我需要搜索Google Play商店才能找到新游戏并下载游戏。该尖尖的球扩展需要从不同的网站和最简单的方式聚集梦幻足球预测是写一个刮刀。当我想起它时,我可能已经写了大约40-50个刮板。我并不是在向我的家人说谎我囤积了多少TB的数据......但我很接近。
我已经尝试过X光 / cheerio,nokogiri和其他一些,但我总是回到我个人的最爱:scrapy。在我看来,scrapy是一款优秀的软件。我不会轻易地抛出这种明确的赞誉,但它感觉非常直观,并且有很好的学习曲线。
您可以阅读The Scrapy教程并让您的第一个刮板在几分钟内运行。然后,当你需要做一些更复杂的事情时,你很可能会发现有一个内置的和有据可查的方式来做到这一点。有很大的权力建立在但框架的结构使得它保持你的出路,直到你需要它。当你最终确实需要某些默认情况下不存在的内容时,可以使用布隆过滤器进行重复数据删除,因为您访问的URL过多,无法存储到内存中,那么通常就像子类化其中一个组件并进行一些小改动一样简单。一切都感觉如此简单,这在我的书中确实是一个很好的软件设计的标志。
我已经玩了一段时间编写高级scrapy教程的想法。这些东西可以让我有机会展示它的一些可扩展性,同时解决实际中出现的现实挑战。尽管我想这样做,但我无法摆脱这样一个事实,即它似乎是一个决定性的举动,想要发布一些可能会导致某人的服务器受到bot流量攻击的东西。
晚上我可以睡得很好,只要遵循一些基本规则,就可以积极地尝试防止刮擦。也就是说,我保持我的请求率与我手动浏览时的请求率相当,并且我不会对数据做任何事情。这使得运行刮板基本上无法以任何重要的方式手动收集数据。即使我亲自遵守这些规则,对于人们可能真正想要抓取的特定网站,如何做指导仍然是一个过分的步骤。
因此,直到我遇到一个名为Zipru的洪流网站时,它仍然只是一个模糊的想法。它有多种机制,需要先进的抓取技术,但其robots.txt文件允许抓取。此外,没有理由刮掉它。它有一个公共API,可用于获取所有相同的数据。如果您有兴趣获取torrent数据,那么只需使用API; 这很好。
在本文的其余部分中,我将带领您撰写一个可以处理验证码和我们在Zipru网站上遇到的各种其他挑战的刮板。该代码不会完全按照书面方式工作,因为Zipru不是一个真正的网站,但所采用的技术广泛适用于现实世界的抓取并且代码完整。我假设你对python有基本的了解,但是我会尽力让这些对scrapy很少或根本不了解的人来说。如果事情一开始太快,那么花几分钟的时间阅读The Scrapy教程,其中将深入介绍介绍性内容。
设置项目
我们将在一个virtualenv内工作,这让我们可以封装我们的依赖关系。我们先来设置一个virtualenv ~/scrapers/zipru并安装scrapy。
mkdir ~/scrapers/zipru
cd ~/scrapers/zipru
virtualenv env
. env/bin/activate
pip install scrapy
您运行那些终端现在将被配置为使用本地virtualenv。如果你打开另一个终端,那么你需要. ~/scrapers/zipru/env/bin/active再次运行(否则你可能会得到有关命令或模块未被发现的错误)。
您现在可以通过运行创建一个新的项目脚手架
scrapy startproject zipru_scraper
这将创建以下目录结构。
└── zipru_scraper
├── zipru_scraper
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
大多数这些文件默认情况下并未实际使用,他们只是提出了一种理想的方式来构建我们的代码。从现在开始,您应该将其~/scrapers/zipru/zipru_scraper视为项目的顶级目录。这是任何scrapy命令应该运行的地方,也是任何相对路径的根源。
添加一个基本的蜘蛛
我们现在需要添加一个蜘蛛,以便让我们的刮板实际上做任何事情。蜘蛛是scrapy刮板的一部分,它处理解析文档以查找新的URL以提取和提取数据。我将非常依赖默认的Spider实现来最大限度地减少我们必须编写的代码量。这里的东西可能看起来有点自动化,但如果您查看文档,情况会更少。
首先,创建一个名为zipru_scraper/spiders/zipru_spider.py以下内容的文件。
import scrapy
class ZipruSpider(scrapy.Spider):
name = 'zipru'
start_urls = ['http://zipru.to/torrents.php?category=TV']
我们的蜘蛛继承了scrapy.Spider它,提供了一种start_requests()方法,可以通过start_urls它来开始我们的搜索。我们已经在start_urls这些点上提供了一个单独的URL 到电视列表。他们看起来像这样。

在顶部,您可以看到有链接指向其他页面。我们希望我们的刮板遵循这些链接并解析它们。为此,我们首先需要确定链接并找出它们指向的位置。
在这个阶段DOM检查员可以是一个巨大的帮助。如果要右键单击其中一个页面链接并在检查器中查看它,则会看到其他列表页面的链接如下所示
<a href="/torrents.php?...page=2" title="page 2">2a>
<a href="/torrents.php?...page=3" title="page 3">3a>
<a href="/torrents.php?...page=4" title="page 4">4a>
接下来,我们需要为这些链接构造选择器表达式。有一些类似的搜索看起来更适合于css或xpath选择器,所以我通常倾向于混合并链接它们,有点自由。如果您不知道它,我强烈建议学习xpath,但不幸的是这超出了本教程的范围。我个人认为这对于拼凑,网络用户界面测试,甚至一般的网页开发来说都是不可或缺的。我会坚持使用CSS选择器,因为它们可能对大多数人更为熟悉。
要选择这些页面链接,我们可以使用a[title ~= page]css选择器在标题中查找带有“页面”的标签。如果你按下ctrl-fDOM检查器,那么你会发现你可以使用这个CSS表达式作为搜索查询(这也适用于xpath!)。这样做可以让您循环查看所有比赛。这是检查表达式是否有效的一种好方法,但也不是非常模糊以至于无意中与其他事物相匹配。我们的页面链接选择器满足这两个标准。
为了告诉我们的蜘蛛如何找到这些其他页面,我们将添加一个parse(response)方法来ZipruSpider像这样
def parse(self, response):
# proceed to other pages of the listings
for page_url in response.css('a[title ~= page]::attr(href)').extract():
page_url = response.urljoin(page_url)
yield scrapy.Request(url=page_url, callback=self.parse)
当我们开始抓取时,我们添加的URL start_urls将被自动提取,并将响应反馈到此parse(response)方法中。我们的代码然后找到所有到其他列表页面的链接,并产生附加到同一parse(response)回调的新请求。这些请求将转化为响应对象,然后parse(response)只要URL尚未处理(由于过滤器),就会反馈回来。
我们的刮板已经可以找到并请求所有不同的列表页面,但我们仍然需要提取一些实际数据以使其有用。洪流列表坐在 我们 如果我们只是在拼抢大多数网站,我们现在就会完成。我们可以跑 几分钟后,我们将拥有一个很好的JSON Lines格式的 Drats!我们必须更聪明地获取我们完全可以从公共API获得的数据,并且永远不会真正抓取。 我们的第一个请求会得到一个 Scrapy默认标识为“Scrapy / 1.3.3(+ http://scrapy.org)”,有些服务器可能会阻止此功能,甚至会将有限数量的用户代理列入白名单。您可以在网上找到最常见的用户代理列表,使用其中的一种往往足以绕开基本的防刮擦措施。选择你喜欢的,然后打开 同 您可能会注意到,默认的scrapy设置在那里做了一些刮擦。关于这个问题的意见不同,但我个人认为,如果你的刮板行为像使用普通网络浏览器的人一样,可以将其识别为普通的网络浏览器。所以让我们通过增加一点来减慢响应速度 由于AutoThrottle扩展,这将创建一个有点逼真的浏览模式。我们的刮板也将 现在再次运行刮刀 这是真正的进步!我们有两种 在深入了解我们面临的更大问题之前,了解一下在scrapy中如何处理请求和响应将会很有帮助。当我们创建我们的基本蜘蛛时,我们产生了 下载器中间件继承 当一个请求到达服务器时,它会通过 一个特别简单的中间件是 另一个相当基本的是 如果您惊讶地发现默认情况下启用了这么多的下载器中间件,那么您可能有兴趣查看体系结构概述。这事实上是一种很多其他的东西怎么回事,但同样,约scrapy伟大的事情之一是,你并不需要知道大部分东西。就像您甚至不需要知道下载器中间件存在编写功能性蜘蛛一样,您也不需要知道这些其他部分来编写功能性下载器中间件。 回到我们的刮板,我们发现我们被重定向到一些 在重定向到 查看第一页的源代码显示,有一些JavaScript代码负责构建特殊的重定向URL,并且还负责手动构建浏览器Cookie。如果我们要解决这个问题,那么我们必须处理这两项任务。 那么,当然,我们也必须解决验证码并提交答案。如果我们碰巧遇到了错误,那么我们有时会重定向到另一个验证码页面,而其他时候我们最终会看到像这样的页面 我们需要点击“点击此处”链接开始整个重定向周期。一块蛋糕,对吧? 我们所有的问题都源于最初的 因此,打开 您会注意到我们正在进行子类化, 要启用我们的新中间件,我们需要添加以下内容 这将禁用默认的重定向中间件,并将其插入中间件堆栈中完全相同的位置。我们还必须安装一些我们正在导入但尚未实际使用的附加软件包。 请注意,所有这三个包都具有pip无法处理的外部依赖性。如果遇到错误,那么你可能需要访问dryscrape,枕头和pytesseract安装指南,遵循平台的具体说明。 我们的中间件现在应该可以代替标准的重定向中间件行为; 我们只需要实施 首先,让我们在中间件构造函数中初始化一个dryscrape会话。 您可以将此会话视为一个单独的浏览器选项卡,它执行浏览器通常会执行的所有操作(例如,获取外部资源,执行脚本)。我们可以导航到标签中的新网址,点击东西,将文本输入到输入中,以及各种其他东西。Scrapy支持并发请求和项目处理,但响应处理是单线程的。这意味着我们可以使用这个单独的dryscrape会话,而不必担心线程安全。 所以现在让我们勾画绕过威胁防御的基本逻辑。 这处理了我们在浏览器中遇到的所有不同情况,并完成了人类在每个情况下都会做的事情。在任何给定点采取的行动只取决于当前页面,所以这种方法有点优雅地处理序列的变化。 谜题的最后一部分是实际解决验证码问题。在那里有验证码解决服务,您可以使用API,但这个验证码很简单,我们可以使用OCR来解决它。使用pytesseract进行OCR,我们可以最终添加我们的 您可以看到,如果由于某种原因,验证码解决失败,则会将此委托给该 这应该足以让我们的刮板工作,但它会陷入无限循环。 它至少看起来像我们的中间件正在成功解决验证码,然后重新发送请求。问题是新的请求再次触发威胁防御。我的第一个想法是,我在解析或附加cookies方面存在一些错误,但是我三重检查了这一点,代码没有问题。这是另一个“唯一可能不同的是标题”的情况。 scrapy和dryscrape的标题显然都绕过了初始过滤器, 所以让我们 请注意,我们明确地在 现在,当我们再次运行我们的刮板时, 我们已经完成了编写可以克服四种不同威胁防御机制的刮板的过程: 我们的目标网站Zipru可能是虚构的,但这些都是真实的网站上遇到的真正的反刮擦技术。希望你会发现我们采取的方法对你自己的拼抢冒险很有用。一起
class="list2at",然后每个单独的列表是在一个与 class="lista2"。这些行中的每一行又包含对应于“类别”,“文件”,“添加”,“大小”,“播种者”,“采集者”,“评论”和“上传者”的8个标签。在代码中查看其他细节可能是最简单的,因此这里是我们更新的 parse(response)方法。
def parse(self, response):
# proceed to other pages of the listings
for page_url in response.xpath('//a[contains(@title, "page ")]/@href').extract():
page_url = response.urljoin(page_url)
yield scrapy.Request(url=page_url, callback=self.parse)
# extract the torrent items
for tr in response.css('table.lista2t tr.lista2'):
tds = tr.css('td')
link = tds[1].css('a')[0]
yield {
'title' : link.css('::attr(title)').extract_first(),
'url' : response.urljoin(link.css('::attr(href)').extract_first()),
'date' : tds[2].css('::text').extract_first(),
'size' : tds[3].css('::text').extract_first(),
'seeders': int(tds[4].css('::text').extract_first()),
'leechers': int(tds[5].css('::text').extract_first()),
'uploader': tds[7].css('::text').extract_first(),
}
parse(response)现在的方法也会生成字典,这些字典会根据类型自动区分请求。每个字典将被解释为一个项目,并作为我们的刮板数据输出的一部分。scrapy crawl zipru -o torrents.jl
torrents.jl文件和我们所有的torrent数据。相反,我们得到这个(还有很多其他的东西)[scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
[scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
[scrapy.core.engine] DEBUG: Crawled (403) 简单的问题
403被忽略的响应,然后所有内容都会关闭,因为我们只通过一个网址对爬网进行播种。即使在没有会话记录的无痕模式下,相同的请求也可以在网络浏览器中正常工作,所以这必须由请求标头中的一些差异引起。我们可以使用tcpdump来比较两个请求的头部,但这里有一个常见的罪魁祸首,我们应该首先检查:用户代理。zipru_scraper/settings.py并更换# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'zipru_scraper (+http://www.yourdomain.com)'
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.95 Safari/537.36'
CONCURRENT_REQUESTS = 1
DOWNLOAD_DELAY = 5
robots.txt默认尊重,所以我们真的在我们最好的行为。scrapy crawl zipru -o torrents.jl应该会产生[scrapy.core.engine] DEBUG: Crawled (200) 200状态,一种302是下载中间件知道如何处理。不幸的是,这表明302我们看起来有些不祥threat_defense.php。不出所料,蜘蛛在那里找不到任何好处,并且爬行终止。下载中间件
scrapy.Request对象,然后它们以某种方式变成scrapy.Response与服务器响应对应的对象。这种“不知何故”的很大一部分是下载中间件。scrapy.downloadermiddlewares.DownloaderMiddleware并实现两者process_request(request, spider)和process_response(request, response, spider)方法。你大概可以猜出那些人的名字。实际上有一大堆这些中间件默认是启用的。这是标准配置的样子(你当然可以禁用东西,添加东西或重新排列东西)。DOWNLOADER_MIDDLEWARES_BASE = {
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100,
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware': 300,
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware': 350,
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware': 400,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 500,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware': 560,
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': 580,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 590,
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 600,
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750,
'scrapy.downloadermiddlewares.stats.DownloaderStats': 850,
'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware': 900,
}
process_request(request, spider)这些中间件的方法来冒泡。这发生在按顺序的数字顺序中,以便RobotsTxtMiddleware首先处理请求和HttpCacheMiddleware处理它的最后处理。然后,一旦产生了响应,它就会通过process_response(request, response, spider)任何启用的中间件的方法回弹。这次以相反的顺序发生,所以数字越高越接近服务器,越低的数字越接近蜘蛛。CookiesMiddleware。它基本上检查Set-Cookie传入响应的头部并保存cookie。然后,当响应正在出来时,它会Cookie适当地设置标题,以便它们包含在传出请求中。这比因过期和东西而复杂一点,但你明白了。RedirectMiddleware处理,等待它... 3XX重定向。这一个让任何非3XX状态代码响应愉快地冒泡,但如果有重定向呢?它能够找出服务器如何响应重定向URL的唯一方法是创建一个新的请求,所以这正是它的功能。当该process_response(request, response, spider)方法返回一个请求对象而不是一个响应时,那么当前的响应将被丢弃,并且所有事情都会从新的请求开始。这就是RedirectMiddleware处理重定向的方式,这是我们即将使用的一项功能。难题(s)
threat_defense.php?defense=1&...URL而不是接收我们正在寻找的页面。当我们在浏览器中访问此页面时,我们会在几秒钟内看到类似的内容
threat_defense.php?defense=2&...更像这样的页面之前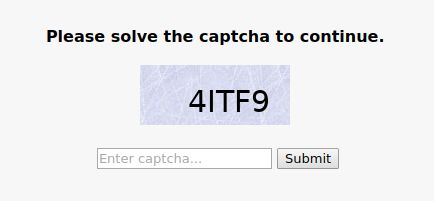

302重定向,因此处理它们的自然地方是在重定向中间件的定制版本中。我们希望我们的中间件像,除了有一个时,在所有情况下的正常重定向中间件302的threat_defense.php页面。当它遇到特殊情况时302,我们希望它绕过所有这些威胁防御措施,将访问cookie附加到会话中,最后重新请求原始页面。如果我们能够解决这个问题,那么我们的蜘蛛并不需要知道任何这种业务,并且请求会“正常工作”。zipru_scraper/middlewares.py并更换内容import os, tempfile, time, sys, logging
logger = logging.getLogger(__name__)
import dryscrape
import pytesseract
from PIL import Image
from scrapy.downloadermiddlewares.redirect import RedirectMiddleware
class ThreatDefenceRedirectMiddleware(RedirectMiddleware):
def _redirect(self, redirected, request, spider, reason):
# act normally if this isn't a threat defense redirect
if not self.is_threat_defense_url(redirected.url):
return super()._redirect(redirected, request, spider, reason)
logger.debug(f'Zipru threat defense triggered for {request.url}')
request.cookies = self.bypass_threat_defense(redirected.url)
request.dont_filter = True # prevents the original link being marked a dupe
return request
def is_threat_defense_url(self, url):
return '://zipru.to/threat_defense.php' in url
RedirectMiddleware而不是DownloaderMiddleware直接进行。这使我们能够重用大部分内置的重定向处理,并插入我们的代码_redirect(redirected, request, spider, reason),只有process_response(request, response, spider)在构建重定向请求时才会调用该代码。我们只是在这里推行标准重定向的超级类实现,但特殊威胁防御重定向的处理方式不同。我们还没有实施bypass_threat_defense(url),但我们可以看到它应该返回将附加到原始请求的访问cookie,并且原始请求将被重新处理。zipru_scraper/settings.py。DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': None,
'zipru_scraper.middlewares.ThreatDefenceRedirectMiddleware': 600,
}
pip install dryscrape # headless webkit
pip install Pillow # image processing
pip install pytesseract # OCR
bypass_thread_defense(url)。我们可以解析javascript以获取我们需要的变量,并在python中重新创建逻辑,但这看起来很脆弱并且有很多工作。让我们来看一下使用无头webkit实例的更简单但也许更笨重的方法。有几个不同的选项,但我个人喜欢dryscrape(我们已经安装)。 def __init__(self, settings):
super().__init__(settings)
# start xvfb to support headless scraping
if 'linux' in sys.platform:
dryscrape.start_xvfb()
self.dryscrape_session = dryscrape.Session(base_url='http://zipru.to')
def bypass_threat_defense(self, url=None):
# only navigate if any explicit url is provided
if url:
self.dryscrape_session.visit(url)
# solve the captcha if there is one
captcha_images = self.dryscrape_session.css('img[src *= captcha]')
if len(captcha_images) > 0:
return self.solve_captcha(captcha_images[0])
# click on any explicit retry links
retry_links = self.dryscrape_session.css('a[href *= threat_defense]')
if len(retry_links) > 0:
return self.bypass_threat_defense(retry_links[0].get_attr('href'))
# otherwise, we're on a redirect page so wait for the redirect and try again
self.wait_for_redirect()
return self.bypass_threat_defense()
def wait_for_redirect(self, url = None, wait = 0.1, timeout=10):
url = url or self.dryscrape_session.url()
for i in range(int(timeout//wait)):
time.sleep(wait)
if self.dryscrape_session.url() != url:
return self.dryscrape_session.url()
logger.error(f'Maybe {self.dryscrape_session.url()} isn\'t a redirect URL?')
raise Exception('Timed out on the zipru redirect page.')
solve_captcha(img)方法并完成bypass_threat_defense()功能。 def solve_captcha(self, img, width=1280, height=800):
# take a screenshot of the page
self.dryscrape_session.set_viewport_size(width, height)
filename = tempfile.mktemp('.png')
self.dryscrape_session.render(filename, width, height)
# inject javascript to find the bounds of the captcha
js = 'document.querySelector("img[src *= captcha]").getBoundingClientRect()'
rect = self.dryscrape_session.eval_script(js)
box = (int(rect['left']), int(rect['top']), int(rect['right']), int(rect['bottom']))
# solve the captcha in the screenshot
image = Image.open(filename)
os.unlink(filename)
captcha_image = image.crop(box)
captcha = pytesseract.image_to_string(captcha_image)
logger.debug(f'Solved the Zipru captcha: "{captcha}"')
# submit the captcha
input = self.dryscrape_session.xpath('//input[@id = "solve_string"]')[0]
input.set(captcha)
button = self.dryscrape_session.xpath('//button[@id = "button_submit"]')[0]
url = self.dryscrape_session.url()
button.click()
# try again if it we redirect to a threat defense URL
if self.is_threat_defense_url(self.wait_for_redirect(url)):
return self.bypass_threat_defense()
# otherwise return the cookies as a dict
cookies = {}
for cookie_string in self.dryscrape_session.cookies():
if 'domain=zipru.to' in cookie_string:
key, value = cookie_string.split(';')[0].split('=')
cookies[key] = value
return cookies
bypass_threat_defense()方法。这在必要时授予我们多次验证码尝试,因为我们可以始终在验证过程中不断弹跳,直到我们获得一个权限。[scrapy.core.engine] DEBUG: Crawled (200) 403因为我们没有收到任何403回应,所以会触发响应。这肯定是由于它们的标题不同而引起的。我的猜测是,其中一个加密访问cookie包含完整标题的散列,并且如果请求不匹配,请求将触发威胁防御。这里的目的可能是帮助防止有人将浏览器中的cookies复制到刮板上,但它也只是增加了一些你需要解决的问题。zipru_scraper/settings.py像这样明确地指定我们的头文件。DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'User-Agent': USER_AGENT,
'Connection': 'Keep-Alive',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'en-US,*',
}
User-Agent此处添加了USER_AGENT我们之前定义的标题。这已经由用户代理中间件自动添加,但将所有这些内容放在一个位置可以更容易地在dryscrape中复制标题。我们可以通过修改我们的ThreatDefenceRedirectMiddleware初始化程序来做到这一点。def __init__(self, settings):
super().__init__(settings)
# start xvfb to support headless scraping
if 'linux' in sys.platform:
dryscrape.start_xvfb()
self.dryscrape_session = dryscrape.Session(base_url='http://zipru.to')
for key, value in settings['DEFAULT_REQUEST_HEADERS'].items():
# seems to be a bug with how webkit-server handles accept-encoding
if key.lower() != 'accept-encoding':
self.dryscrape_session.set_header(key, value)
scrapy crawl zipru -o torrents.jl我们看到了不断刮掉的物品,我们的torrents.jl文件记录了这一切。我们已经成功解决了所有的威胁防御机制!包起来
你可能感兴趣的:(高级网页抓取:如何绕过雷区,抓取成功)