深度学习 --- 深度卷积神经网络详解(AlexNet 网络详解)
本篇将解释另外一个卷积神经网络,该网络是Hinton率领的谷歌团队(Alex Krizhevsky,Ilya Sutskever,Geoffrey E. Hinton)在2010年的ImageNet大赛获得冠军的一个神经网络,因此本节主要参考的论文也是这次大赛的论文即“ImageNet分类与深卷积神经网络”,大家可以找到这篇论文看看,好,和前面一样,本节主要是介绍网络的架构,同时和LeNet -5-网络进行对比学习,详细介绍本文引入的新概念图像增强,Dropout等技术,下面就开始从ImageNet大赛开始介绍:
ImageNet大赛
ImageNet是一个计算机视觉系统识别项目,是目前丐界上图像识别最大的数据库。是美国斯坦福的计算机科学家,模拟人类的识别系统建立的。能够从图片识别物体.ImageNet LSVRC图像识别大赛素有国际计算机视觉奥林大赛之称。数据集包含大约1000多万张各种图片,被分为1000个分类,参赛者训练分类器,在测试数据上取得最高辨识正确率者为优胜,大家需要数据可以到官网进行下载:ImageNet主页
深度卷积神经网络
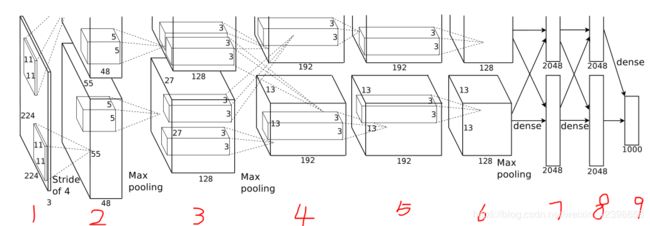
这里的网络和LeNet -5-网络有些许不同,在LeNet-5网络里,卷积层和池化层是分开的即一层卷积层一层池化这样分布的,但是深度卷积神经网络和LeNet -5-网络不同,主要不同在卷积和池化层合为一体了,而且还是分两路设计网络,下面我们都会解说,那么我们下面就针对这个图进行讲解:
输入(1号位置):
本层的输入层如上图1号位置,输入的图片的像素是224x224的且有三层,这三层代表三原色RGB(我们知道所谓的彩色其实就是三原色组合而成的,因此彩色图片也是这样),我们可以简单的看做有三张图片堆叠而成的彩色图片,这三张图片分别对应红色,绿色,蓝色,在LeNet -5-网络只有一层,因为颜色是灰度的。输入层的采样窗口为11×11且也有三层对应图片的三层,那么每采样一次有多少个连接呢?有11x11x3 = 363个,采样窗口的平移步长是4,(在LeNet -5-网络移动步长是1,这里是4,应该很容易理解)为什么步长是4而不是1呢?因为考虑到计算量的问题,如果是1步计算量太大。那么这样的采样窗口在图像上采样后的维度是多少呢?
MAX pooling层(2号位置):
这一层就是上图的2号位置,那么这里的维度是多少呢?通过11×11的采样和卷积的窗口对224x224的图片进行采样得到55x55的层级地图,那厚度是48的什么意思呢?其实就是对应LeNet -5-网络不同的卷积特征平面,如C1有6个特征平面。因此这里的有48 + 48 = 96个55x55的特征平面,为什么是48 + 48,因为这里计算是通过GPU并行计算的,因此采用两路,合并起来就是LeNet -5-网络的那种形式,这里大家需要结合LeNet -5-网络进行理解。
3号位置:
3号位置的层和2号类似,这里的对2号设置的采样窗口为5×5,得到的3号维度为27x27,总有256个卷积核,在此基础上同理得到4号位置的层,此时的维度为13×13,总共384个卷积核,同理5号,6号也是如此,这里不细讲了。
第6层和第7层是BP形式的全连接,总共有4096个神经元,第7层和第8层也是BP形式的全连接,总共有4096个神经元,最后就是输出1000个输出。
下面系统给出该过程描述:
(1)从上图中可以发现,输入的图像大小为224×224,但是考虑到图像是由RGB组成的三通道,因此输入图像的规则是224×224×3(在AlexNet模型的实际处理过程中会通过预处图像的输人规则是227×227×3)
(2)在AlexNet模型中,一共有96个11×11的卷积核进行特征提取,考虑到图像为RGB图像,则存在三个通道,因此这96个滤波器实际使用过程中也是11×11×3,即原始图像是彩色图像,那么提取的特征也是具有彩色的特质特征图大小的计算方式采用如下公式:其中步幅表示步长,决定了卷积核滑动的大小。因此第一层卷积层生成的特征图大小为(227-11)/ 4 + 1 = 55,因此第一层卷积层得到的特征图一共是(96)AlexNet模型使用RELU函数作为激活函数,使得特征图中特征值取值范围在合理范围。(4)AlexNet模型中是96个,每一个特征图的大小是55x55,且带RGB三通道。使到了 化处理的方式。比如内核是3×3的矩阵,则该过程是对3×3区域的数据进行处理,通过下采样处理可以得到(55-3)/ 2 + 1 = 27,得到96个27x27的特征图,这96个特征图将会作为第二次卷积层操作的输入。第3层卷积层的输入是第2层卷积层输出的96×27×27的特征图,采用的是256个5×5大小的卷积核,利用卷积核对输入的特征图进行处理,处理方式与第2层卷积层的处理方式略有不同。过滤器是对96个特征图中的某几个特征图中相应的区域乘以相应的权值,然后加上偏置之后对所得区域进行卷积,第3层卷积层计算完毕之后,得到的是256个13×13((27 - 3)/ 2 = 13)的特征图。

后续的操作类似,第4层卷积层没有采用下采样操作,得到的是384个13×13的新特征图,第5层依然没有进行下采样操作,因此得到的依然是384个13×13的特征图,第6层得到的是256个6x6的特征图。
对于第7层的全连接层,使用4096个神经元,并对第6层输出的256个6×6的特征图进行全连接:第8层的全连接层与上一层全连接层类似;第9层全连接层采用的是1000个神经元,对第8层的4096个神经元进行全连接,然后通过高斯滤波器,得到各项预测的可能性·
在训练模型过程中,会通过实际值与期望值进行误差计算,求出残差,并通过链式求导法则,将残差通过求解偏导数逐步向上传递,在神经网络的各个层不断修改权值和偏置值和一般的神经网络思想类似。
值得说明的是,局部响应值归一化(局部响应归一化,LRN)是借助神经生物学中的侧抑制思想,即当某个神经元被激活时,抑制相邻的其他神经元。局部响应值归一化的目的是实现局部的抑制,RELU也是一种“侧抑制”方法。这样做的意义在于有利于增强模型的泛化能力.LRN通过模仿神经生物学中的侧抑 局部的神经元实现了竞争机制,使得响应比较大的值相对能够更扩大。
通过计算可得到网络的权值总共大概有6000万个参数,而样本只有1000多万张,因此样本不足,很容易产生过拟合,如何处理?
数据增强:
hintion他们使用的方法是,因为原始处理过的图片的像素是256×256,而我们输入的是224x224,他是怎么增强的呢如下图?
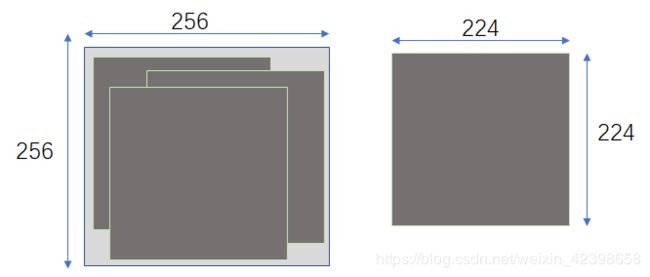
原先是一个256×256,为了得到更多的样本,我们使用一个224x224样板对原图进行截取,如上图,这样每个图片就可以生成很多类似的图片,通过这种方法可以得到充足的样本。这也就解释了为什么输入的224x224的大小了。
数据增强的第二种形式是改变训练图像中RGB通道的强度。具体地说,我们在整幅图中对RGB像素值集执行PCA进行降维,通过改变主要颜色的亮度然后生成更多图片。
Dropout
hintion在那篇论文中还提出使用差进行避免过拟合同时增强神经网络的泛化能力,那什么是Dropout呢?
Dropout可以作为训练深度神经网络的一种选择。在每个训练批次中,通过忽略一半的特征检测器(让一半的隐层节点值为0),可以明显地减少过拟合现象。这种方式可以减少特征检测器(隐层节点)间的相互作用,检测器相互作用是指某些检测器依赖其他检测器才能发挥作用.Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征,如下图所示
Dropout具体工作流程如下:
假如我们的神经网络是这样的,在本节中其实就是最后两层的全连接层,下面给出Dropout的过程:
输入是X输出是Y,正常的流程是:我们首先把X通过网络前向传播,然后把误差反向传播以决定如何更新参数让网络进行学习使用Dropout之后,过程变成如下:
(1)首先随机(临时)删掉网络中一半的隐藏神经元,输入输出神经元保持不变(图下图虚线为部分临时被删除的神经元)
(2)然后把输入X通过修改后的网络前向传播,然后把得到的损失结果通过修改的网络反向传播。一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数(W,b)。
(3)然后继续重复这一过程:
恢复被删掉的神经元(此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新)。从隐藏层神经元中随机选择一个一半大小的子集临时删除掉(备份被删除神经元的参数)。对一小批训训练本,先向前传播然后反向传播损失并根据随机梯度下降法更新参数(W,b)(没有被删除的那一部分参数得到更新,删除的神经元参数保持被删除前的结果)。不断重复这一过程。
Dropout为什么可以解决过拟合?
(1)取平均的作用:先回到标准的模型即没有丢失,我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们可以采用“5个结果取均值“或者 '多数取胜的投票策略' 去决定最终结果。例如3个网络判断结果为数字9,那么很有可能真正的结果就是数字9,其它两个网络给出了错误结果。”综合起来取平均”的策略通常可以有效防止过拟合问题。因为不同的网络可能产生不同的过拟合,取平均则有可能让一些 '相反的' 拟合互相抵消.dropout掉不同的隐藏神经元就类似在训练不同的网络,随机删掉一半隐藏神经元导致网络结构已经不同,整个。Dropout过程就相当于对很多个不同的神经网络取平均而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。
(2)减少神经元之间复杂的共适应关系:因为Dropout程序导致两个神经元不一定每次都在一个压差网络中出现这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其他特定特征特征下才有效果的情况。迫使网络去学习更加鲁棒的特征,这些特征在其它的神经元的随机子集中也存在。换句话说假如我们的神经网络是在做出某种预测,它不应该对一些特定的线索片段太过敏感,即使丢失特定的线索,它也应该可以从众多其它线索中学习一些共同的特征。从这个角度看Dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高。
(3)Dropout类似于性别在生物进化中的角色:物种为了生存往往会倾向于适应这种环境,环境突变则会导致物种难以做出及时反应,性别的出现可以繁衍出适应新环境的变种,有效的阻止过拟合,即避免环境改变时物种可能面临的灭绝。
至于学习算法,hintion这篇论文没说,论文的主要内容就这些,其他的就是数据了,这里就不贴了,有兴趣的查看原文看看就可以了,估计应该和LeNet -5-网络差不多,因为他们都是基于BP的,因此大家应该把我的上一篇博客好好看一下,本节到此结束,下一节我们将看看卷积神经网络的一些优化,或者说真的大多数网络的优化更合适吧,好本节到此结束。
(这里的单词差,我在编辑时老是被浏览器自动翻译了,无语了)