风格迁移0-03:stylegan-数据制作及训练
以下链接是个人关于stylegan所有见解,如有错误欢迎大家指出,我会第一时间纠正,如有兴趣可以加微信:a944284742相互讨论技术。若是帮助到了你什么,一定要记得点赞奥!因为这是对我最大的鼓励。
风格迁移0-00:stylegan-目录-史上最全:https://blog.csdn.net/weixin_43013761/article/details/100895333
数据制作
如果你通过之前的博客,已经下载好了数据,可以知道FFHQ数据集是十分大的,估计是60G左右,里面都是分辨率很高的图片,这么多的图片,全部都加载训练,其实是一件比较麻烦的事情,这里为了大家简单快速的了解整个训练的流程,我们解压其中的一个压缩包当作我们训练的数据,解压之后我们可以看到类似如下的图片:

每张的分辨率都是1024*1024。
下面我们就要制作数据了,制作数据的流程很简单,执行如下(源码根目录):
python datasetool.py create_from_images <输出目录> <图片目录>
其主要是依赖datasetool.py源码中的:
p = add_command( 'create_from_images', 'Create dataset from a directory full of images.',
'create_from_images datasets/mydataset myimagedir')
p.add_argument( 'tfrecord_dir', help='New dataset directory to be created')
p.add_argument( 'image_dir', help='Directory containing the images')
p.add_argument( '--shuffle', help='Randomize image order (default: 1)', type=int, default=1)
执行之后,我们可以再输出目录下看到如下文件:
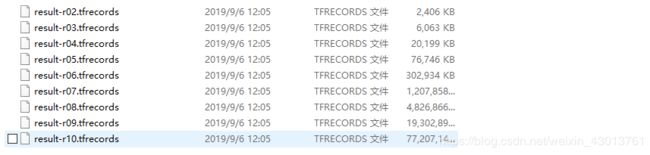
其中的数据代表的是2的多少次方的分辨率,如:
result-r04.tfrecords
其代表的是,生成tfrecords文件中,图片的分辨率为 2 4 2^4 24=16,即该数据中,其图片的分辨率为16*16。每个分辨率的数据,再训练的过程都是会被使用到的。
这样我们就生成了训练的数据。
模型训练
模型的训练是十分简单的,我们需要配置的东西也不多,主要配置的文件为源码根目录下的config.py,其中内容如下:
result_dir = 'results'
data_dir = 'E:/1.PaidOn/3.FaceFusion/2.stylegan/dataset/test/'
cache_dir = 'cache'
run_dir_ignore = ['results', 'datasets', 'cache']
result_dir表示结果输出的目录 ,data_dir表示训练数据输入的目录,即前面的包含多个tfrecords的目录,cache_dir表示模型缓存的目录。run_dir_ignore代表的是忽略的目录,那么什么叫做忽略的目录,这里是忽略拷贝的意思,因为再训练的过程中,其会创建一个子项目,该项目的所有文件,几乎都是从根目录拷贝生成,为了避免拷贝一些没有必要的文件到子项目中,所以通过这里进行设置,选择不需要拷贝的目录。
大家看了之后,可能会比较难以理解,不过没有关系,再接下来训练的过程中,就能知道为什么了。
直接执行:
python train.py
很可惜,由于本人电脑的配置不够,其实也已经8G显存了,然后没有办法运行,故此,为了让代码运转起来,迫不得已修改了源码train.py:
desc += '-1gpu'; submit_config.num_gpus = 1; sched.minibatch_base = 1; sched.minibatch_dict = {4: 32, 8: 32, 16: 32, 32: 16, 64: 8, 128: 4, 256: 2, 512: 1}
#desc += '-1gpu'; submit_config.num_gpus = 1; sched.minibatch_base = 4; sched.minibatch_dict = {4: 128, 8: 128, 16: 128, 32: 64, 64: 32, 128: 16, 256: 8, 512: 4}
注释掉的是源码中的,本人把训练时,每个分辨率的batch_size都除以了4,这样我的机器就可以运行了。
运行之后,可以看到在根目录的results下面生成新的目录,类似于:

可以发现该谢目录中,存在很多根目录的代码,其实每个如上图的文件夹,都是独立的子项目工程。
预训练模型加载
在训练的过程中,其保存的模型在子项目的根目录下,如下:

下面是子项目的结构:
E:.
│ config.txt
│ fakes000000.png
│ log.txt
│ reals.png
│ run.py
│ run.txt
│ submit_config.1pkl
│ submit_config.txt
│ tree.txt
│
└─src
│ config.py
│ dataset_tool.py
│ generate_figures.py
│ LICENSE.txt
│ pretrained_example.py
│ README.md
│ run_metrics.py
│ stylegan-teaser.png
│ train.py
│ tree.txt
│
├─1pkl
│ inception_v3_features.pkl
│
├─dnnlib
│ │ util.py
│ │ __init__.py
│ │
│ ├─submission
│ │ │ run_context.py
│ │ │ submit.py
│ │ │ __init__.py
│ │ │
│ │ └─_internal
│ │ run.py
│ │
│ └─tflib
│ autosummary.py
│ network.py
│ optimizer.py
│ tfutil.py
│ __init__.py
│
├─metrics
│ frechet_inception_distance.py
│ linear_separability.py
│ metric_base.py
│ perceptual_path_length.py
│ __init__.py
│
└─training
dataset.py
loss.py
misc.py
networks_progan.py
networks_stylegan.py
training_loop.py
__init__.py
其与我们主项目的目录是十分相似的,其中的submit_config.txt代表的是子项目的配置信息,在训练的过程中,我们可能或被中断,那么下一次我们运行的时候,只需要运行子项目就可以了,即子项目根目录下的run.py文件,在运行该项目的时候,需要指定一些参数:
run_dir = str(sys.argv[1])
task_name = str(sys.argv[2])
host_name = str(sys.argv[3])
本人运行的命令如下:
python run.py ./ 00002-sgan-result-1gpu localhost
其中的00002-sgan-result-1gpu创建与子项目根目录下的results目录下,类似如下:
创建完成之后,再运行上面的代码。
如果我们要接着上一次的训练,我们还需要再源码中添加:
submit_config.task_name = task_name
submit_config.host_name = host_name
+ submit_config.run_func_kwargs['resume_run_id'] = 2
+ submit_config.run_func_kwargs['resume_kimg'] = 4160
其中带+好的两行都是本人添加,resume_run_id代表的是子项目resilt目录下的类似:

文件的编号,resume_kimg表示的是你上一次训练数据的张数,如果不对该变量进行设置,其默认会从4X4的分辨率开始训练。子项目训练的结果都会保存再子项目的result目录下。其中类似上图的目录中,保存的都是训练的一些信息,如log,图片等。
小结
到目前为止,我们已经知道训练以及测试的整个流程,下面我们就正式的开始对代码的原理以及论文相关的知识点进行讲解。