python使用Networkx生成人物关系可视化详解
一,先说实现的思路
1,将文本中出现的重要人物名字放入列表中;也可以使用自然语言处理工具将词性标记为‘nr’的词语放入列表中,但一则费时费力二则准确性太差。所以,简单粗暴但高效的做法是直接从搜索引擎中得到主要人物的名称,并将其放入列表中;
2,遍历文本的第一个段落,并检查人物名称是否在此段落中,如果在,将其放入一个空列表中,并使用combination将其转化成人物名称的两两组合;这是很关键的一步,只有得出了人物关系,才可能实现可视化。
3,使用Networkx实现人物关系的可视化,这个操作很简单,但如果想优化节点和线,还是有一些难度的。贴上代码后再详细说明此点。
二,使用到的内置或三方库;
1,set,在遍历文本的每一个段落时,形成的列表中会有多个重复的人物名称,使用set可以去除重复的人名;
2,sorted,为避免形成[A,B]和[B,A]两种本质上相同的关系,使用sorted排序,可以防止出现前述的AB两种关系;
3,itertools库中的combination,[A,B,C]只形成[A,B],[A,C],[B,C]三种关系,符合我们的需求;
4,collections中的Counter,统计每一对关系在列表中出现的次数,形成一个字典;
5,networkx库,使用networkx.draw_circular,让人物以圆的形式排列在图片上。
三,networkx.draw_circular parameter的详细解说:
1,nodelist和node_size,引用g.degree的键值,可通过映射在图表上反映节点的大小,出现越多的节点,在图表上也越大;
2,node_color和cmap,node_color是一个列表,通过colormap与plt.cm.parameter形成映射,在图表上反映为节点的颜色,具体的颜色值可以参考https://matplotlib.org/gallery/color/colormap_reference.html;
3,edge_color和edge_cmap,edge_color也是一个列表,通过edge_cmap与plt.cm.parameter开成映射,在图表上表现为边的颜色;
4,width,width也是一个列表,引用自边的值,即人物关系字典的值;
四,图片比例尺,分辨率和将文本插入到图片中;
1,比例尺,在绘图前使用plt.figure(figsize=(turple))来确定每个像素块的比例尺;
2,分辨率,DPI与比例尺的结合,其中dpi在保存文件的命令savefig中引用,默认值是100;
3,将文本插入图片,x,y指插入的位置,中间为0,0,边上为+/-1。
五,附上两张效果图。
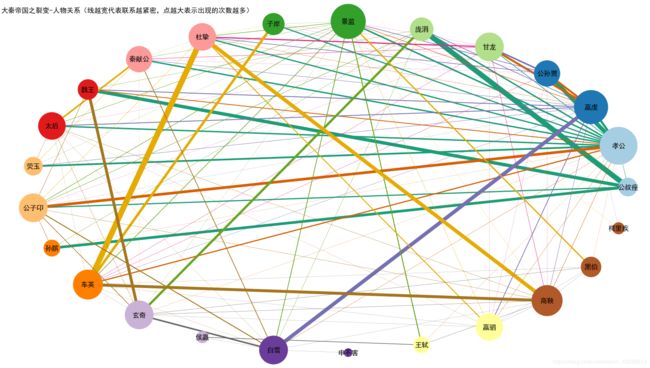
六,附上源代码。
from collections import Counter
from itertools import combinations
import networkx as nx
import matplotlib.pyplot as plt
def getRelationiship(fn):
namelist=['无忌','赵敏','芷若','小昭','殷离','成昆','谢逊','灭绝','翠山','殷素素','纪晓芙','杨逍','杨不悔','范遥','金花婆婆',
'张三丰','殷天正','韦一笑','宋青书','丁敏君','宋远桥','俞岱岩','殷梨亭','殷野王','阳顶天','阳夫人','朱九真','空见大师',
'空智大师','周颠','王保保','黄衫女子','王难姑','俞莲舟','张松溪','莫声谷','鹿杖客','鹤笔翁','渡厄','渡难','渡劫','韩千叶'
,'常遇春','铁冠道人','彭莹玉','说不得','冷谦','鲜于通','何太冲','班淑娴','高老者','矮老者']
fo=open(fn,'r',encoding='utf-8').readlines()
relationlist=[]
for lines in fo:
n=[]
for i in namelist:
for j in namelist[namelist.index(i)+1:]:
if i in lines and j in lines and i!=j:
n.append(i)
relationlist+=combinations(sorted(set(n)),2)
relationDict=Counter(relationlist)
return relationDict,namelist
def createRelationship(fn):
relationDict,namelist=getRelationiship(fn)
edgeWidth=[]
for i in relationDict.values():
edgeWidth.append(i/5)
# print(edgeWidth)
print(len(edgeWidth))
plt.figure(figsize=(16, 9))#图片比例尺,跟dpi合并计算后就是图片的分辨率,注意figure要放在画图开始前
g=nx.MultiGraph()
g.add_edges_from(relationDict.keys())
d=dict(g.degree)
nx.draw_circular(g,nodelist=d.keys(),node_size=[v*200 for v in d.values()],node_color=range(46),cmap=plt.cm.Paired,
with_labels=True,edge_color=range(385),edge_cmap=plt.cm.Dark2,alpha=1.0,width=edgeWidth)
# node_color,要使用报错提醒的数字,edge_color使用len(edgewidth),但直接引用报错。
#nodelist节点名称,node_size节点大小,node_color&cmap节点颜色的映射,edge_color&edge_cmap线颜色的映射,width宽度的值
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.text(-1.05,1.05,'%s-人物关系(线越宽代表联系越紧密,点越大表示出现的次数越多)'%fn[:-4],fontsize=12)#-1,1字体位置
plt.savefig('%s-=人物关系图.png'%fn[:-4],dpi=120)#单个像素的DPI2020年6月16日更新:
因为源代码不在这台电脑上,只针对其中不明确的地方做个说明:
1,46,是人物节点的数量,可以使用len(namelist)代替;
2,385,是边的数量,可以使用len(relationDict)代替;
3,node_size使用的是matplotlib里scatter的规格值,默认是300,到底怎么算出来的,我看了官方文档,也做过计算,都没搞明白。
很抱歉,初学时的代码,有点混乱,但大概能看明白的。
感谢阅读!