多元(一元)线性回归&多项式回归
1. 多元线性回归基本假定与表达式
1.1 基本假定
- 回归模型是正确设定的
- 解释变量 x 1 , x 2 , . . , x m x_1,x_2,..,x_m x1,x2,..,xm是非随机的或固定的,且各 x j x_j xj之间不存在严格线性相关性(无完全多重共线性)
- 各解释变量在所抽取的样本中具有变异性,且随着样本容量的无限增加,各解释变量的样本方差趋于一个非零的有限常数。(大样本性质,伪回归问题)
- 随机误差项零均值、同方差、序列不相关
- 解释变量与随机变量不相关(只要4中的零均值假设成立,本条假设一定成立)
- 随机项满足正态分布
1.2 具体值的表达方式
[ y 1 ^ y 2 ^ . . . y n ^ ] = [ x 11 x 12 . . . x 1 m x 21 x 22 . . . x 2 m . . . . . . . . . . . . . x n 1 x n 2 . . . x n m ] ∗ [ ω 1 ω 2 . . . ω m ] + [ b 1 b 2 . . . b m ] + [ ϵ 1 ϵ 2 . . . ϵ m ] \begin{bmatrix} \hat{y_1}\\ \hat{y_2}\\ ...\\ \hat{y_n} \end{bmatrix}= \begin{bmatrix} x_{11}&x_{12}&...&x_{1m}\\ x_{21}&x_{22}&...&x_{2m}\\ ...&...&...&....\\ x_{n1}&x_{n2}&...&x_{nm}\\ \end{bmatrix}* \begin{bmatrix} \omega_1\\ \omega_2\\ ...\\ \omega_m \end{bmatrix}+ \begin{bmatrix} b_1\\ b_2\\ ...\\ b_m \end{bmatrix}+ \begin{bmatrix} \epsilon_1\\ \epsilon_2\\ ...\\ \epsilon_m \end{bmatrix} ⎣⎢⎢⎡y1^y2^...yn^⎦⎥⎥⎤=⎣⎢⎢⎡x11x21...xn1x12x22...xn2............x1mx2m....xnm⎦⎥⎥⎤∗⎣⎢⎢⎡ω1ω2...ωm⎦⎥⎥⎤+⎣⎢⎢⎡b1b2...bm⎦⎥⎥⎤+⎣⎢⎢⎡ϵ1ϵ2...ϵm⎦⎥⎥⎤
其中 x i j x_{ij} xij表示第i个样本第j个变量;
ω i \omega_i ωi为参数;
b i b_i bi为截距项;
因此x的每一行代表一个样本,每一列代表一个特征;y是一个向量;x是一个矩阵; ω \omega ω是一个向量。有时候,为了省略b,会默认x有m+1个随机变量,但x的元素是常数1,形式如下:
[ y 1 ^ y 2 ^ . . . y n ^ ] = [ 1 x 11 x 12 . . . x 1 m 1 x 21 x 22 . . . x 2 m . . . . . . . . . . . . . . . . 1 x n 1 x n 2 . . . x n m ] ∗ [ ω 1 ω 2 . . . ω m ] + [ ϵ 1 ϵ 2 . . . ϵ m ] \begin{bmatrix} \hat{y_1}\\ \hat{y_2}\\ ...\\ \hat{y_n} \end{bmatrix}= \begin{bmatrix} 1&x_{11}&x_{12}&...&x_{1m}\\ 1&x_{21}&x_{22}&...&x_{2m}\\ ...&...&...&...&....\\ 1&x_{n1}&x_{n2}&...&x_{nm}\\ \end{bmatrix}* \begin{bmatrix} \omega_1\\ \omega_2\\ ...\\ \omega_m \end{bmatrix}+ \begin{bmatrix} \epsilon_1\\ \epsilon_2\\ ...\\ \epsilon_m \end{bmatrix} ⎣⎢⎢⎡y1^y2^...yn^⎦⎥⎥⎤=⎣⎢⎢⎡11...1x11x21...xn1x12x22...xn2............x1mx2m....xnm⎦⎥⎥⎤∗⎣⎢⎢⎡ω1ω2...ωm⎦⎥⎥⎤+⎣⎢⎢⎡ϵ1ϵ2...ϵm⎦⎥⎥⎤
在进行推导的过程的一般采用第二种形式,下述表达形式中仍采用含有b的,方便理解。
1.3 向量表达形式
上述说过
y ⃗ = ω 1 x 1 ⃗ + ω 2 x 2 ⃗ + . . . + ω m x m ⃗ + b ⃗ + ϵ ⃗ \vec{y}=\omega_1\vec{x_1}+\omega_2\vec{x_2}+...+\omega_m\vec{x_m}+\vec{b}+\vec{\epsilon} y=ω1x1+ω2x2+...+ωmxm+b+ϵ
1.4 矩阵表达方式
y ⃗ = X ω ⃗ + ϵ ⃗ \vec{y}=X\vec{\omega}+\vec{\epsilon} y=Xω+ϵ
其中, X = ( x 1 ⃗ , x 2 ⃗ , . . . , x m ⃗ ) X=(\vec{x_1},\vec{x_2},...,\vec{x_m}) X=(x1,x2,...,xm)或者 X = ( x 1 ⃗ , x 2 ⃗ , . . . , x m ⃗ ) T X=(\vec{x^1},\vec{x^2},...,\vec{x^m})^T X=(x1,x2,...,xm)T
x ⃗ \vec{x} x下标表示特征,上标表示样本。
2. 多元线性回归求解
2.1 矩阵解
多元回归的解方法有最小二乘估计、极大似然估计、矩估计等,最小二乘估计的参数结果是一种无偏估计(前提是变量y服从正态分布,以及后面的假设检验都是在正态分布的假设下才成立的),因此应用最为广泛。
最小二乘估计即残差和最小,表达式如下:
min ω ∑ i = 1 n = ( y i − y i ^ ) = ( y i − ( x i ) T ) ⋅ ω \min\limits_{\omega}\sum\limits_{i=1}^{n}=(y_i-\hat{y_i})=(y_i-(x^{i})^T)·\omega ωmini=1∑n=(yi−yi^)=(yi−(xi)T)⋅ω
min ω ∣ ∣ y ⃗ − X ω ⃗ ∣ ∣ 2 = min ω ( y ⃗ − X ω ⃗ ) T ( y ⃗ − X ω ⃗ ) \min\limits_{\omega}||\vec{y}-X\vec{\omega}||^2=\min\limits_{\omega}(\vec{y}-X\vec{\omega})^T(\vec{y}-X\vec{\omega}) ωmin∣∣y−Xω∣∣2=ωmin(y−Xω)T(y−Xω)
第二种方式也是范数的表达形式。求解最小值的过程是先求导,再令导数为0。
具体推导过程如下:

注意事项:
- 逆矩阵存在的充分必要条件是特征矩阵不存在多重共线性,即线性代数中的非线性。多重共线性的解决方式见下方(lasso回归和领回归)。但是,当X真存在多重共线性,但又没注意到时,此时的逆就是伪逆(加号逆)。多元回归还涉及异方差性等,可见博客:回归模型概述。
实际中,数据非常大,求解 ( X T X ) − 1 (X^TX)^{-1} (XTX)−1是非常难,因此 X T X X^TX XTX采用奇异值分解的方法(方阵逆和伪逆均适用)。
2.2 代数解


求偏导:



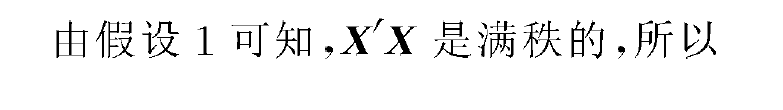

上述截图来自王黎明的应用回归分析
2.3 几何解
2.3.1 线性方程组的几何意义

从行的角度看:
线性方程组的解就是直线a和直线b的交点,如下图左

从上图右可以更全面理解线性方程组,其维度取决于有几个变量x,解得情况取决于每个方程构成的空间图是否存在交点,如果无交点即无解;只有一个交点,有唯一解;相交是一条线或面或超空间的面,有无穷多解。
从列的角度看

维度取决于样本个数。如果向量 x 1 = ( 1 , 0 , 0 ) 和 向 量 x 2 = ( 0 , 1 , 0 ) x_1=(1,0,0)和向量x_2=(0,1,0) x1=(1,0,0)和向量x2=(0,1,0)可以通过倍数张成组合成向量 y ⃗ = ( 1 , 1 , 0 ) \vec{y}=(1,1,0) y=(1,1,0)则方程存在解,该例子中 ω 1 = 1 , ω 2 = 1 \omega_1=1,\omega_2=1 ω1=1,ω2=1。即 ω 1 ∗ x 1 ⃗ + ω 2 ∗ x 2 ⃗ = 1 ∗ ( 1 , 0 , 0 ) + 2 ∗ ( 0 , 1 , 0 ) = y ⃗ \omega_1*\vec{x_1}+\omega_2*\vec{x_2}=1*(1,0,0)+2*(0,1,0)=\vec{y} ω1∗x1+ω2∗x2=1∗(1,0,0)+2∗(0,1,0)=y
假如现在是三个样本、三个特征对应的线性方程组,是否有解的几何意义为向量 y ⃗ \vec{y} y是否可以通过 x 1 ⃗ , x 2 ⃗ , x 3 ⃗ \vec{x_1},\vec{x_2},\vec{x_3} x1,x2,x3的线性组合构成。
换句话说向量 y ⃗ \vec{y} y是否在向量 x 1 ⃗ , x 2 ⃗ , x 3 ⃗ \vec{x_1},\vec{x_2},\vec{x_3} x1,x2,x3所构成的平面或者空间中,该平面或空间记做 Ω \Omega Ω。如果不在,则无解,如果在,则可能有无穷多解也可能只有一个解。故无解时, y ⃗ \vec{y} y不在 Ω \Omega Ω中;有解时, y ⃗ \vec{y} y在 Ω \Omega Ω中,但存在唯一解和无穷解两种情况。
2.3.2 最小二乘法
最小二乘法就是解一个无解的线性方程组
以下图为例:

要找到解,就是找到 ω 1 , ω 2 \omega_1,\omega_2 ω1,ω2与向量 x 1 , x 2 x_1,x_2 x1,x2的一个线性组合,使得组合后的向量刚好等于 y ⃗ \vec{y} y。换句话说,要想有解, y ⃗ \vec{y} y必须落在 x 1 , x 2 x_1,x_2 x1,x2所构成的空间 Ω \Omega Ω上。但是向量 y ⃗ \vec{y} y并不在空间 Ω \Omega Ω上。
不能找到解,就寻找一个近似解
找不到完美解,只能找一个最接近的解,所以在空间 Ω \Omega Ω上找一个最接近向量 y ⃗ \vec{y} y的替代向量 y ^ ⃗ \vec{\hat y} y^.
y ^ ⃗ \vec{\hat y} y^就是向量 y ⃗ \vec{y} y到空间 Ω \Omega Ω上的投影。利用投影垂直的性质,可以得到:
( y ⃗ − y ^ ⃗ ) T x 1 = 0... a n d . . . ( y ⃗ − y ^ ⃗ ) T x 2 = 0 (\vec{y}-\vec{\hat y})^Tx_1=0 ...and ...(\vec{y}-\vec{\hat y})^Tx_2=0 (y−y^)Tx1=0...and...(y−y^)Tx2=0
令 X = ( x 1 , x 2 ) X=(x_1,x_2) X=(x1,x2), y ^ ⃗ = ω 1 x 1 + ω 2 x 2 = X ω ⃗ \vec{\hat y}=\omega_1x_1+\omega_2x_2=X\vec{\omega} y^=ω1x1+ω2x2=Xω,扩展到高维转化成矩阵形式:
( y ⃗ − y ^ ⃗ ) T X = 0 → ( y ⃗ − X ω ⃗ ) T X = 0 (\vec{y}-\vec{\hat y})^TX=0\rightarrow (\vec{y}-X\vec{\omega})^TX=0 (y−y^)TX=0→(y−Xω)TX=0。
因此 ω ⃗ = ( X T X ) − 1 X T y ⃗ \vec{\omega}=(X^TX)^{-1}X^T\vec{y} ω=(XTX)−1XTy
所以,最小二乘法的几何意义是高维空间的一个向量(由y数据决定)在低维子空间(由X数据以及多项式的次数决定)的投影。
2.4 正交投影矩阵
结合上述,若存在矩阵P使得 P y ⃗ = y ^ ⃗ P\vec{y} =\vec{\hat y} Py=y^,则称P为正交投影矩阵。推理可得, P = X ( X T X ) − 1 X T P=X(X^TX)^{-1}X^T P=X(XTX)−1XT
3. sklearn中linear model模块简介
3.1 总体概述

3.2 linear_model.LinearRegression
LinearRegression使用的是矩阵求解的方式,并且没有正则化项

from sklearn import datasets
boston = datasets.load_boston()
X = boston.data
X.shape
y = boston.target
X = X[y < 50]
y = y[y < 50]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 666)
from sklearn.preprocessing import StandardScaler #最大最小值方法用MinMaxScaler
standardScaler = StandardScaler()#创建实例
standardScaler.fit(X_train) #拟合
standardScaler.mean_ #均值
standardScaler.scale_ #描述数据分布范围
X_train = standardScaler.transform(X_train)#此时x_train本身没有改变,故需要一个变量承接
X_test = standardScaler.transform(X_test)
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X_train, y_train)
y_predict = lin_reg.predict(X_test)
lin_reg.intercept_#截距
lin_reg.score(X_test, y_test)
lin_reg.coef_
'''获得均方误差'''
from sklearn.metrics import mean_squared_error
mean_squared_error(y_test, y_predict)
4. 多重共线性
上述中讲到多重共线性,指矩阵X存在线性相关,求解过程中可以理解为 ( X T X ) (X^TX) (XTX)的行列式为0(精确相关关系)或者非常接近于0(高度相关关系)。解决多重共线性的方法有三种:

这三种手段中,第一种相对耗时耗力,需要较多的人工操作,并且会需要混合各种统计学中的知识和检验来进行使 用。在机器学习中,能够使用一种模型解决的问题,我们尽量不用多个模型来解决,如果能够追求结果,我们会尽量 避免进行一系列检验。况且,统计学中的检验往往以“让特征独立”为目标,与机器学习中的”稍微有点相关性也无 妨“不太一致。
第二种手段在现实中应用较多,不过由于理论复杂,效果也不是非常高效,因此向前逐步回归不是机器学习的首选。
机器学习的核心是使用第三种方法:改进线性回归来处理多重共线性。为此,一系列算法,岭回归, Lasso,弹性网就被研究出来了。
5. 岭回归
5.1 原理简介
在线性模型之中,除了线性回归之外,最知名的就是岭回归与Lasso了。这两个算法非常神秘,他们的原理和应用都 不像其他算法那样高调,学习资料也很少。这可能是因为这两个算法不是为了提升模型表现,而是为了修复漏洞而设 计的(实际上,我们使用岭回归或者Lasso,模型的效果往往会下降一些,因为我们删除了一小部分信息),因此在 结果为上的机器学习领域颇有些被冷落的意味。
岭回归在多元线性回归的损失函数上加上了L2正则项,表达如下:
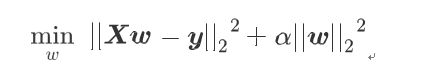
求解过程如下:

一个矩阵存在逆的充要条件为其行列式不等于0,换句话说,将矩阵通过行列变换成上三角矩阵后,对角线元素不含有0元素。假如X存在多重共线性,则 X T X X^TX XTX经过行列变换后的上三角矩阵对角线存在0元素,但是加上 α \alpha α后,就不为0了,因此消除了多重共线性。除非:




岭回归中,当 α > 0 \alpha>0 α>0时, X T X X^TX XTX加上一个数,故矩阵变大,因此逆矩阵减小,所以岭回归有压缩系数的作用,因此,岭回归中 α \alpha α一般取大于0的数(虽然理论上也是可以小于0的)。
5.2 sklearn简介

其他参数,一般不会去设置,可以暂时不做了解。
from sklearn import datasets
boston = datasets.load_boston()
X = boston.data
X.shape
y = boston.target
X = X[y < 50]
y = y[y < 50]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 666)
from sklearn.preprocessing import StandardScaler #最大最小值方法用MinMaxScaler
standardScaler = StandardScaler()#创建实例
standardScaler.fit(X_train) #拟合
standardScaler.mean_ #均值
standardScaler.scale_ #描述数据分布范围
X_train = standardScaler.transform(X_train)#此时x_train本身没有改变,故需要一个变量承接
X_test = standardScaler.transform(X_test)
from sklearn.linear_model import Ridge
Ridge_reg = Ridge()
Ridge_reg.fit(X_train, y_train)
y_predict = Ridge_reg.predict(X_test)
Ridge_reg.intercept_#截距
Ridge_reg.score(X_test, y_test)
Ridge_reg.coef_
'''获得均方误差'''
from sklearn.metrics import mean_squared_error
mean_squared_error(y_test, y_predict)
5.3 选择最佳参数 α \alpha α
5.3.1 岭迹图
既然要选择 α \alpha α的范围,我们就不可避免地要进行最优参数的选择。在各种机器学习教材中,总是教导使用岭迹图来判断正则项参数的最佳取值。传统的岭迹图长这样,形似一个开口的喇叭图(根据横坐标的正负,喇叭有可能朝右或者 朝左):

这一个以正则化参数 α \alpha α为横坐标,线性模型求解的系数 ω \omega ω 为纵坐标的图像,其中每一条彩色的线都是一个系数 ω \omega ω。其目标是建立正则化参数与系数 α \alpha α之间的直接关系,以此来观察正则化参数的变化如何影响了系数 α \alpha α 的拟合。岭迹图认 为,线条交叉越多,则说明特征之间的多重共线性越高。我们应该选择系数较为平稳的喇叭口所对应的 α \alpha α取值作为最佳的正则化参数的取值。绘制岭迹图的方法非常简单,代码如下:
import numpy as np
import matplotlib.pyplot as plt from sklearn import linear_model
#创造10*10的希尔伯特矩阵
X = 1. / (np.arange(1, 11) + np.arange(0, 10)[:, np.newaxis]) y = np.ones(10)
#计算横坐标 n_alphas = 200
alphas = np.logspace(-10, -2, n_alphas)
#建模,获取每一个正则化取值下的系数组合
coefs = []
for a in alphas:
ridge = linear_model.Ridge(alpha=a, fit_intercept=False) ridge.fit(X, y)
coefs.append(ridge.coef_)
#绘图展示结果
ax = plt.gca() ax.plot(alphas, coefs) ax.set_xscale('log')
ax.set_xlim(ax.get_xlim()[::-1]) #将横坐标逆转
plt.xlabel('正则化参数alpha') plt.ylabel('系数w') plt.title('岭回归下的岭迹图') plt.axis('tight')
plt.show()

然而,并不建议使用岭迹图来作为寻找最佳参数的标准。 有这样的两个理由:
- 岭迹图的很多细节,很难以解释。比如为什么多重共线性存在会使得线与线之间有很多交点?当 很大了之后看 上去所有的系数都很接近于0,难道不是那时候线之间的交点最多吗?
-
岭迹图的评判标准,非常模糊。哪里才是最佳的喇叭口?哪里才是所谓的系数开始变得”平稳“的时候?一千个读 者一千个哈姆雷特的画像?未免也太不严谨了。
5.3.2 RidgeCV
在现实中,真正应用来选择正则化系数的技术是交叉验证,并且选择的标准非常明。sklern中使用RindgeCV

from sklearn import datasets
boston = datasets.load_boston()
X = boston.data
X.shape
y = boston.target
X = X[y < 50]
y = y[y < 50]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 666)
from sklearn.preprocessing import StandardScaler #最大最小值方法用MinMaxScaler
standardScaler = StandardScaler()#创建实例
standardScaler.fit(X_train) #拟合
standardScaler.mean_ #均值
standardScaler.scale_ #描述数据分布范围
X_train = standardScaler.transform(X_train)#此时x_train本身没有改变,故需要一个变量承接
X_test = standardScaler.transform(X_test)
from sklearn.linear_model import RidgeCV
RidgeCV_reg = RidgeCV(alphas = (0.1, 0.01, 0.001),cv = 5)
RidgeCV.fit(X_train, y_train)
y_predict = RidgeCV_reg.predict(X_test)
RidgeCV.intercept_#截距
RidgeCV.score(X_test, y_test)
RidgeCV.coef_
6. Lasso回归
6.1 原理简介
Lasso全称最小绝对收缩和选择算子(least absolute shrinkage and selection operator),由于这个名字过于复杂所以简称为Lasso。和岭回归一样,Lasso是被创造来作用于多重共线性问题的算法,不过Lasso使用的是系数的L1范式(L1范式则是系数的绝对值)乘以正则化系数 ,所以 Lasso的损失函数表达式为:
min ω ∣ ∣ X ω − y ∣ ∣ 2 2 + α ∣ ∣ ω ∣ ∣ 1 \min\limits_{\omega}||X\omega-y||_2^2+\alpha||\omega||_1 ωmin∣∣Xω−y∣∣22+α∣∣ω∣∣1
有些教材说,Lasso与岭回归非常相似,都是利用正则项来对原本的损失函数形成一个惩罚,以此来防止多重共线性。这种说法不是非常严谨。当我们使用最小二乘法来求解Lasso中 的参数 ,我们依然对损失函数进行求导:
现在问题又回到了 X T X X^TX XTX的逆是否存在。在岭回归中,通过正则化系数 ,能够向方阵 X T X X^TX XTX加上一个单位矩阵,以此来防止方阵 X T X X^TX XTX的行列式为0,而现在L1范式所带的正则项 在求导之后并不带有 这个项,因此它无法对 X T X X^TX XTX造成任何影响。也就是说,Lasso无法解决特征之间”精确相关“的问题。当使用最小二乘法求解线性回归时,如果线性回归无解或者报出零错误,换Lasso不能解决任何问题。
岭回归可以解决特征间的精确相关关系导致的最小二乘法无法使用的问题,而Lasso不行。幸运的是,在现实中我们其实会比较少遇到“精确相关”的多重共线性问题,大部分多重共线性问题应该是“高度相关“,假设方阵 X T X X^TX XTX的逆是一定存在,那么:

通过增大 α \alpha α,可以为 ω \omega ω的计算增加一个负项,从而限制参数估计中 ω \omega ω的大小,而防止多重共线性引起的参数 ω \omega ω估计过大导致模型失准的问题。Lasso不是从根本上解决多重共线性问题,而是限制多重共线性带来的影响。何况,这还是在假设所有的系数都为正的情况下,假设系数 ω \omega ω无法为正,则很有可能需要将正则项参数 α \alpha α设定 为负,因此 α \alpha α可以取负数,并且负数越大,对共线性的限制也越大。
岭回归和Lasso回归都会压缩系数的大小,对标签贡献更少的特征的系数会更小,也会更容易被压缩。不过,L2正则化只会将系数压缩到尽量接近0,但L1正则化主导稀疏性,因此会将系数压缩到0。这个性质, 让Lasso成为了线性模型中的特征选择工具首选。
6.2 特征选择
import numpy as np import pandas as pd
from sklearn.linear_model import Ridge, LinearRegression, Lasso from sklearn.model_selection import train_test_split as TTS
from sklearn.datasets import fetch_california_housing as fch import matplotlib.pyplot as plt
housevalue = fch()
X = pd.DataFrame(housevalue.data) y = housevalue.target
X.columns = ["住户收入中位数","房屋使用年代中位数","平均房间数目"
,"平均卧室数目","街区人口","平均入住率","街区的纬度","街区的经度"]
X.head()
Xtrain,Xtest,Ytrain,Ytest = TTS(X,y,test_size=0.3,random_state=420)
#恢复索引
for i in [Xtrain,Xtest]: i.index = range(i.shape[0])
#岭回归进行拟合
Ridge_ = Ridge(alpha=0.01).fit(Xtrain,Ytrain) (Ridge_.coef_*100).tolist()
#Lasso进行拟合
lasso_ = Lasso(alpha=0.01).fit(Xtrain,Ytrain) (lasso_.coef_*100).tolist()
6.3选择最佳的正则化参数
使用交叉验证的Lasso类参数与岭回归略有不同,这是由于Lasso对于alpha的取值更加敏感,因此往往让 α \alpha α在很小的空间中变动。这个小空间小到超乎人们的想象(不是0.01到0.02之间这样的空间,这个空间对lasso而言还是太大了),因此设定了一个重要概念**“正则化路径”(regularization path)**:假设特征矩阵中有n个特征,则就有特征向量 x 1 , x 2 , . . . , x n x_1,x_2,...,x_n x1,x2,...,xn。对于每一个 α \alpha α的取值,都可以得出一组对应这个特征向量的参数向量,其中包含了n+1个参数(包含截距项)。这些参数可以被看作是一个n+1维空间中的一个点。对于不同的 α \alpha α取 值,我们就将得到许多个在n+1维空间中的点,所有的这些点形成的序列,就被称之为是正则化路径。
把形成这个正则化路径的 α \alpha α的最小值除以 α \alpha α的最大值得到的量 α m i n α m a x \frac{\alpha_{min}}{\alpha_{max}} αmaxαmin称为正则化路径的长度(length of the path)。在sklearn中,可以通过规定正则化路径的长度(即限制 α \alpha α的最小值和最大值之间的比例),以及路径中 α \alpha α的个数,来让sklearn自动生成 α \alpha α的取值,避免了自己手动生成 α \alpha α列表。
和岭回归的交叉验证类相似,除了进行交叉验证之外,LassoCV也会单独建立模型。它会先找出最佳的正则化参数, 然后在这个参数下按照模型评估指标进行建模。需要注意的是,LassoCV的模型评估指标选用的是均方误差,而岭回归的模型评估指标是可以自己设定的,并且默认是 R 2 R^2 R2 。

from sklearn.linear_model import LassoCV
#自己建立Lasso进行alpha选择的范围
alpharange = np.logspace(-10, -2, 200,base=10)
#其实是形成10为底的指数函数
#10**(-10)到10**(-2)次方 alpharange.shape
Xtrain.head()
lasso_ = LassoCV(alphas=alpharange #自行输入的alpha的取值范围
,cv=5 #交叉验证的折数
).fit(Xtrain, Ytrain)
#查看被选择出来的最佳正则化系数 lasso_.alpha_
#调用所有交叉验证的结果 lasso_.mse_path_
lasso_.mse_path_.shape #返回每个alpha下的五折交叉验证结果 lasso_.mse_path_.mean(axis=1) #有注意到在岭回归中我们的轴向是axis=0吗?
#在岭回归当中,我们是留一验证,因此我们的交叉验证结果返回的是,每一个样本在每个alpha下的交叉验证结果
#因此我们要求每个alpha下的交叉验证均值,就是axis=0,跨行求均值
#而在这里,我们返回的是,每一个alpha取值下,每一折交叉验证的结果
#因此我们要求每个alpha下的交叉验证均值,就是axis=1,跨列求均值
#最佳正则化系数下获得的模型的系数结果 lasso_.coef_
lasso_.score(Xtest,Ytest)
#与线性回归相比如何?
reg = LinearRegression().fit(Xtrain,Ytrain) reg.score(Xtest,Ytest)
#使用lassoCV自带的正则化路径长度和路径中的alpha个数来自动建立alpha选择的范围 ls_ = LassoCV(eps=0.00001
,n_alphas=300
,cv=5
).fit(Xtrain, Ytrain)
ls_.alpha_
ls_.alphas_ #查看所有自动生成的alpha取值 ls_.alphas_.shape ls_.score(Xtest,Ytest)
ls_.coef_
7.普通线性回归、岭回归、lasso回归几何意义
7.1 岭回归与普通线性回归
上面讲到,岭回归是在普通线性回归上加了一个参数的L2范数,也被称为目标函数的惩罚函数。它可以确保岭回归系数值不会变的很大,起到收缩的作用,这个收缩力度就可以通过 α \alpha α来平衡。岭回归模型的参数求解依赖于一个目标函数,该目标函数还可以表示为(通过数学证明可以得到上述所写岭回归表达式与下面这两个是一致的):
ω ^ = a r g min ω ∣ ∣ X ω − y ∣ ∣ 2 2 \hat{\omega}=arg \min\limits_{\omega}||X\omega-y||_2^2 ω^=argωmin∣∣Xω−y∣∣22
附 加 约 束 条 件 : ∑ i = 1 p ω i 2 ≤ t 附加约束条件:\sum\limits_{i=1}^{p}\omega_i^2\le t 附加约束条件:i=1∑pωi2≤t
为什么要添加这个岭回归系数平方和的约束呢?上面讲到岭回归模型可以解决多重共线性的问题,正是因为多重共线性的原因,才需要添加这个约束。比如一个家庭可支配收入(y)的因素有收入(x1)和支出(x2),可以根据自变量和因变量的关系构造线性模型 y = ω 0 + ω 1 x 1 + ω 2 x 2 y=\omega_0+\omega_1x_1+\omega_2x_2 y=ω0+ω1x1+ω2x2。假如收入(x1)和支出(x2)之间存在高度多重共线性,则两个变量的回归系数之间定会存在相互抵消的作用。即把 ω 1 \omega_1 ω1调整为很大的正数,把 ω 2 \omega_2 ω2调整为很小的负数时,预测出来的y将不会有较大的变化。所以为了压缩 ω 1 \omega_1 ω1和 ω 2 \omega_2 ω2的范围,就需要一个平方和的约束。
如果把上面的等价目标函数展示到几何图形中的话,将会是(这里以两个变量的回归系数为例,且不含截距项):
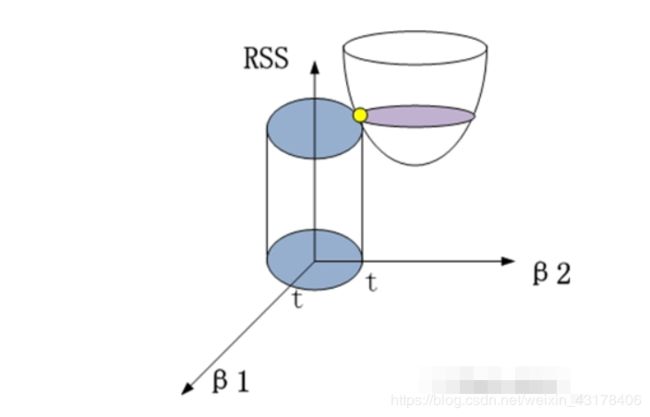
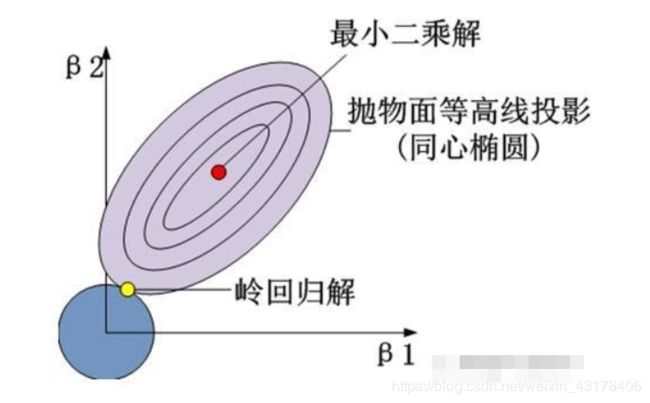
圆柱体即附加约束条件,椭圆柱体就是目标函数(不含L2范数)。黄色的交点就是满足目标函数下的岭回归系数值。进一步,可以将这个三维的立体图映射到二维平面中:
7.2 Lasso与普通最小二乘
与岭回归一样,lasso表现在二维平面上为:

7.3 小结
LASSO回归于岭回归只是在惩罚函数部分有所不同,但这个不同却让LASSO明显占了很多优势,例如在变量选择上就比岭回归强悍的多。就以直观的图形为例,LASSO回归的惩罚函数映射到二维空间的话,就会形成“角”,一旦“角”与抛物面相交,就会导致 ω 1 \omega_1 ω1为0(如上图所示),这样beta1对应的变量就是一个可抛弃的变量。但是在岭回归过程中,没有“角”的圆形与抛物面相交,出现岭回归系数为0的概率还是非常小的。
8.多项式回归
方程 y = ω 0 + ω 1 x 1 2 + ω 2 x 2 2 + ω 3 x 1 x 2 y=\omega_0+\omega_1x_1^2+\omega_2x_2^2+\omega_3x_1x_2 y=ω0+ω1x12+ω2x22+ω3x1x2就是一个多项式回归模型,但本质上仍可看做线性回归,令 z 1 = x 1 2 , z 2 = x 2 2 , z 3 = x 1 x 2 z_1=x_1^2,z_2=x_2^2,z_3=x_1x_2 z1=x12,z2=x22,z3=x1x2就是线性模型了,评估指标仍然不变。
这种方法可以非常容易地通过sklearn中的类PolynomialFeatures来实现

#多项式回归
import numpy as np
x1 = np.random.normal(loc = 10, scale = 3, size = (100,))
x2 = np.random.normal(loc = 8, scale = 4, size = (100,))
X = np.array([x1, x2]).T
X.shape
y = x1 **2 + 2 * x1 + x2 ** 2 + 3 * x2 + 5 * x1 * x2
y.shape
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree = 2)#degree 表示最高为x的几次幂
poly.fit(X)
X_ = poly.transform(X)
X_.shape
poly.powers_ # 获得x1,x2次方的结果。[0,0]表示x1的0次幂,x2的零次幂;[1,0]表示x1的1次幂,x2的0次幂,以此类推
poly.n_input_features_
poly.n_output_features_
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X_, y)
lin_reg.intercept_#截距
lin_reg.score(X_, y)
lin_reg.coef_
lin_reg.get_params(deep = True)

此外也可以通过pipeline管道函数实现,代码实现:
#Pipeline 管道:初始化数据的转化、数据归一化、线性回归融合到一起
x = np.random.uniform(-3, 3, size = 100).reshape(-1, 1)
y = 0.5 * x **2 + x + 2 + np.random.normal(0, 1, 100)
from sklearn.pipeline import Pipeline
poly_reg = Pipeline([
('ploy', PolynomialFeatures(degree = 2)),
('std_scaler', StandardScaler()),
('lin_reg', LinearRegression())
]) #元组构成的列表,每个元组第二个数为相应步骤的初始化
poly_reg.fit(x, y)
poly_reg.predict(x)
poly_reg.score(x,y)
结合