深度学习笔记—线性回归(实战)
线性回归实战—Boston房价预测
在上一篇博客我们讨论了线性回归的理论知识,在文章的结尾,我们利用线性回归解决了简单的预测问题,这篇博客我们来解决上篇博客最开始提出的问题—Boston房价预测。
上篇博客地址如下:
深度学习笔记—线性回归(基础)
数据分析
在我们使用线性回归解决问题之前,我们先来看一下数据集:

Boston房价数据集是一个506行x13列的二维表,包含506个样本,每个样本有13个数值特征其中前12个是特征变量最后的数值特征为该地区的平均房价房价(单价),前12个特征变量分别是:
CRIIM:城镇人均犯罪率‘’
ZN:住在用地超过25000 sq.ft,的比例。
INDUS:城镇非零售商用土地比例。
CHAS:边界河流为1,否则为0。
NOX:一氧化氮浓度。
RM:住宅平均房间数。
AGM:1940年之前建成的自用房屋比例。
DIS:到波士顿五个中心区域的加权距离。
RAD:辐射性公路的靠近指数。
TAX:没10000美元的权值产税率。
PTRATIO:城镇师生比例。
LSTAT:人口中地位低下者的比例。
最后一列标签为:
MEDV:自住房的平均价格,单位:千美元
单纯的看数据只会让我们一头乱麻,我们直接来利用数据做出折线图来看(代码如下):
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
reviews = np.genfromtxt("./data/boston.csv", delimiter=",")#delimiter 分割符号
x = np.linspace(0,506,num=506)
y1, y2,y3,y4,y5,y6,y7,y8,y9,y10,y11,y12 = reviews[1:,0], reviews[1:,1],reviews[1:,2],reviews[1:,3],reviews[1:,4],reviews[1:,5],\
reviews[1:,6],reviews[1:,7],reviews[1:,8],reviews[1:,9],reviews[1:,10],reviews[1:,11]
plt.plot(x, y1, label='CRIM')
plt.plot(x, y2, label='ZN')
plt.plot(x, y3, label='INDUS')
plt.plot(x, y4, label='CHAS')
plt.plot(x, y5, label='NOX')
plt.plot(x, y6, label='RM')
plt.plot(x, y7, label='AGE')
plt.plot(x, y8, label='DIS')
plt.plot(x, y9, label='RAD')
plt.plot(x, y10, label='TAX')
plt.plot(x, y11, label='PTRATIO')
plt.plot(x, y12, label='LSTAT')
plt.title('line chart')
plt.legend()
plt.show()
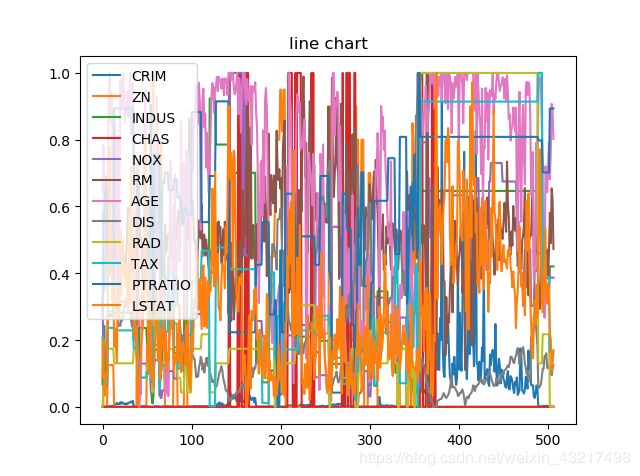
运行结果如下所示(横坐标无意义,竖坐标为数据大小):

做出折线图我们对数据就有直观的感受了,从折线图中我们可以看出,Boston房价预测的数据集有一些特征变量很不稳定,上下波动很大。
权重及其影响因素
我们再重新回归现实,如果我们要买一套房子,我们需要考虑什么因素?房子周围有没有地铁站,五公里范围内有没有大型医院,周围有没有公园等…这一系列的特征变量都会成为我们买房子的考量,也会成为影响房价的直观因素,但是这些变量对房价影响的大小是不是一样呢?很显然不是,那我们用什么去判断一个特征变量重要还是不重要以及判断一个特征变量的程度呢,如果是我们自己去判断,很显然,我们可以凭借生活经验去判断,但是计算机不会,我们这里给计算机衡量特征变量重要程度的依据:权重,特征变量越大权重的值越大,反过来权重越小的特征变量重要性越小,但是这个权重是我们直接告诉计算机的吗,很显然不是,如果我们知道这个权重,我们直接预测就好了,何必告诉计算机多此一举,就像Boston房价数据,我们并不知道什么特征变量更重要,更不能准确的度量它们的重要程度,所以我们需要利用计算机强大的计算能力,将权重算出来,并且利用算出来的权重进行房价的预测,说到这里我们应该都应该反应过来了,这不是就是我们上篇线性回归的参数w吗?是的,我们可以用参数(权重)来衡量特征变量的重要程度。
数据集有12个特征变量,很显然这是一个多元回归问题,跟上篇博客解决的一元回归问题类似,我们也只需要求出多元回归方程即可, 类比一元回归问题预设出回归方程我们可以推出如下回归方程:
![]()
我们再来看损失函数:
![]()
根据梯度下降算法中的参数更新公式:
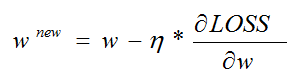

由公式可知,我们需要求出损失函数对于每个权值的偏导,再用偏导去更新权值,我们先来求一个权值的偏导作为示范:
![]()
观察该式我们可以发现,每个权值的偏导都类似于

这种形式,根据权值更新函数和偏导函数我们可以发现当步长一定时,如果特征变量越大,则参数更新的幅度越大,梯度下降的越快,损失也会快速降低,这样会使计算机误以为该特征变量更重要,使梯度下降走向一个不正确的的方向,如上图折线图所示,计算机会误认为 "CRIM’’ 特征变量更为重要,因为其值一直都很大,将梯度下降导向一个错误的方向,实际上我们并不知道该特征变量的重要程度,但是其数值的大小影响了计算机的判断,既然只是数值问题,那么我们想要消除这种影响就变得简单了—数据预处理
预处理
在上面的折线图中我们可以看出来,各个特征变量的范围不一,变化程度不一,当各个特征变量所在范围不一致时,会导致梯度下降轨迹走的路线不顺滑,这样会使迭代很慢。那我们可以对数据做一些处理,让计算机在建立模型中消除数值特征变量数值范围对于模型建立的影响。所以在我们开始训练之前,我们最好对数据进行一定的处理,消除数值范围对模型的影响,即在训练模型之前,我们需要对数据进行预处理,数据是否进行预处理对训练一个模型至关重要,同时预处理有很多方法,我们这里暂时不一一讲解,我们现在只讲解这次需要用的数据集处理方法—归一化处理。
在Boston房价数据集中,唯一的问题就是,特征变量之间的数值差异太悬殊,如果要解决这个问题,我们只需要用归一化处理,将数值的范围统一,这样特征变量的大小就不会对模型的训练造成影响。并且归一化处理还有其他好处:
1.提升模型的收敛速度
虽然计算机的运算速度很快,但是本着能省一点是一点的原则,我们得多省一点计算资源,数值越小,计算速度越快,模型的收敛速度也会加快。
2.提升模型的精度
归一化的好处之一是提高精度,这在涉及到一些距离计算的算法时效果显著,比如算法要计算欧氏距离,某一特征变量的取值范围比较小,涉及到距离计算时其对结果的影响远比另一取值范围较大的特征变量带来的小,所以这就会造成精度的损失。所以归一化很有必要,他可以让各个特征对结果做出的贡献相同。
常用的归一化方法
-
min-max标准化
-
z-score 标准化
min-max标准化
min-max标准化(Min-max normalization) / 0-1标准化(0-1 normalization) / 线性函数归一化 / 离差标准化
是对原始数据的线性变换,使结果落到[0,1]区间,转换函数如下:
,其中max为样本数据的最大值,min为样本数据的最小值。
def Normalization(x):
return [(float(i)-min(x))/float(max(x)-min(x)) for i in x]
如果想要将数据映射到[-1,1],则将公式换成:
x* = x* * 2 -1
或者进行一个近似
x* = (x - x_mean)/(x_max - x_min), x_mean表示数据的均值。
def Normalization2(x):
return [(float(i)-np.mean(x))/(max(x)-min(x)) for i in x]
z-score 标准化(zero-mean normalization)
最常见的标准化方法就是Z标准化,也是SPSS中最为常用的标准化方法,spss默认的标准化方法就是z-score标准化。
也叫标准差标准化,这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。
经过处理的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为:
x* = (x - μ ) / σ
其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
z-score标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。该种归一化方式要求原始数据的分布可以近似为高斯分布,否则归一化的效果会变得很糟糕。
标准化的公式很简单,步骤如下
1.求出各变量(指标)的算术平均值(数学期望)xi和标准差si ;
2.进行标准化处理:
zij=(xij-xi)/si
其中:zij为标准化后的变量值;xij为实际变量值。
3.将逆指标前的正负号对调。
标准化后的变量值围绕0上下波动,大于0说明高于平均水平,小于0说明低于平均水平。
在Boston房价数据集中,我们使用min-max标准化即可满足要求,我们直接来看代码:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
'''
df = pd.read_csv("./data/boston.csv")
df = df.values
df = np.array(df)
'''
reviews = np.genfromtxt("./data/boston.csv", delimiter=",") # delimiter 分割符号
# 归一化数据
for i in range(12):
reviews[1:, i] = (reviews[1:, i] - reviews[1:, i].min()) / (reviews[1:, i].max() - reviews[1:, i].min())
x = np.linspace(0,506,num=506)
y1, y2,y3,y4,y5,y6,y7,y8,y9,y10,y11,y12 = reviews[1:,0], reviews[1:,1],reviews[1:,2],reviews[1:,3],reviews[1:,4],reviews[1:,5],\
reviews[1:,6],reviews[1:,7],reviews[1:,8],reviews[1:,9],reviews[1:,10],reviews[1:,11]
plt.plot(x, y1, label='CRIM')
plt.plot(x, y2, label='ZN')
plt.plot(x, y3, label='INDUS')
plt.plot(x, y4, label='CHAS')
plt.plot(x, y5, label='NOX')
plt.plot(x, y6, label='RM')
plt.plot(x, y7, label='AGE')
plt.plot(x, y8, label='DIS')
plt.plot(x, y9, label='RAD')
plt.plot(x, y10, label='TAX')
plt.plot(x, y11, label='PTRATIO')
plt.plot(x, y12, label='LSTAT')
plt.title('line chart')
plt.legend()
plt.show()
我们预处理后再做出折线图:
看着更杂乱无章了,但是很明显,所有的特征变量都处于[0,1]的闭区间内,经过归一化处理,我们排除了特征变量数据大小对于训练结果的影响,
万事具备,实战开始
我们已经对数据进行了预处理,消除了数据范围对模型的影响,接下来我们就可以根据公式进行模型训练,首先我们来罗列公式:
![]()
![]()
![]()
看着这12个权重的方程看的我们一头乱麻,算也不好算,看也不好看,那我们是不是可以改变一下表达形式。很显然,我们可以利用矩阵,对这个超长复杂的表达式进行变形,很简单,我们把特征变量转换为矩阵,并且把权重也设为一个矩阵,这样我们的线性回归表达式又回到了简单的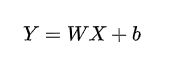
ok 这个看着扎眼的公式被处理掉了,我们就可以按照上篇博客案例的套路愉快的训练模型了:
- 损失计算函数
根据损失函数的计算公式我们可以写出如下python代码:
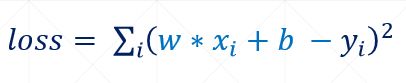
#损失计算函数
#损失计算函数
def compute_error_for_line_given_points(b, w, points):
totalError = 0
for i in range(1, len(points)):#len(points)数据量
x = points[i, 0:12]
y = points[i, 12]
# computer mean-squared-error
totalError += (y - (np.matmul(w,x) + b)) ** 2 # 所有数据的损失和
# average loss for each point
# print(totalError)
return totalError / float(len(points))
代码的核心就是循环求出所有的数据的平均损失
- 梯度计算和参数更新
因为该例子有一个12个自变量一个因变量,我们需要求损失函数关于每个w和唯一一个b的偏导,代码如下:
#梯度计算函数
def step_gradient(b_current, w_current, points, learningRate):#w_current 矩阵
b_gradient = 0
w_gradient = np.array(np.zeros((1,12)))
N = float(len(points))
for i in range(1, len(points)):#i 控制行 j控制列
for j in range(0,12):
x = points[i,0:12]
y = points[i, 12]
# grad_b = 2(wx+b-y)
b_gradient += (2 / N) * ((np.matmul(w_current,x) + b_current) - y)
# grad_w = 2(wx+b-y)*x
w_gradient[0,j] += (2 / N) * points[i, j] * ((np.matmul(w_current,x) + b_current) - y)
# update w'
new_b = b_current - (learningRate * b_gradient)
new_w = w_current - (learningRate * w_gradient)
return [new_b, new_w]
梯度计算函数的核心为根据偏导公式grad_b = 2(wx+b-y)和grad_w = 2(wx+b-y)*x(公式中的x为矩阵)迭代求解每一个自变量对应的梯度,并且求和。
有了梯度计算有了损失计算,剩下的就是根据损失和梯度更新参数,使其逼进函数最低点。
- 开始迭代
根据梯度下降法的解决问题的流程,和规定的迭代次数进行参数计算
# 更新参数
def gradient_descent_runner(points, starting_b, starting_w, learning_rate, num_iterations):
b = starting_b#矩阵
w = starting_w
# update for several times
for i in range(num_iterations): # 控制迭代次数
b, w = step_gradient(b, w, np.array(points), learning_rate)
return [b, w]
- 完整代码
import numpy as np
# y = wx + b
#损失计算函数
def compute_error_for_line_given_points(b, w, points):
totalError = 0
for i in range(1, len(points)):#len(points)数据量
x = points[i, 0:12]
y = points[i, 12]
# computer mean-squared-error
totalError += (y - (np.matmul(w,x) + b)) ** 2 # 所有数据的损失和
# average loss for each point
# print(totalError)
return totalError / float(len(points))
# 梯度计算函数
def step_gradient(b_current, w_current, points, learningRate):#w_current 矩阵
b_gradient = 0
w_gradient = np.array(np.zeros((1,12)))
N = float(len(points))
for i in range(1, len(points)):#i 控制行 j控制列
for j in range(0,12):
x = points[i,0:12]
y = points[i, 12]
# grad_b = 2(wx+b-y)
b_gradient += (2 / N) * ((np.matmul(w_current,x) + b_current) - y)
# grad_w = 2(wx+b-y)*x
w_gradient[0,j] += (2 / N) * points[i, j] * ((np.matmul(w_current,x) + b_current) - y)
# update w'
new_b = b_current - (learningRate * b_gradient)
new_w = w_current - (learningRate * w_gradient)
return [new_b, new_w]
# 更新参数
def gradient_descent_runner(points, starting_b, starting_w, learning_rate, num_iterations):
b = starting_b#矩阵
w = starting_w
# update for several times
for i in range(num_iterations): # 控制迭代次数
b, w = step_gradient(b, w, np.array(points), learning_rate)
return [b, w]
# 开始训练
def run():
points = np.genfromtxt("./data/boston.csv", delimiter=",") # delimiter 分割符号
learning_rate = 0.0001 # 学习率
initial_b = 0 # initial y-intercept guess
initial_w = np.array(np.zeros((1,12))) # initial slope guess
num_iterations = 1000 # 迭代次数
for i in range(12):
points[1:, i] = (points[1:, i] - points[1:, i].min()) / (points[1:, i].max() - points[1:, i].min())
print("Starting gradient descent at b = {0}, w = {1}, error = {2}"
.format(initial_b, initial_w,
compute_error_for_line_given_points(initial_b, initial_w, points))
) # 刚开始的w和b参数 以及初始损失
print("Running...")
[b, w] = gradient_descent_runner(points, initial_b, initial_w, learning_rate, num_iterations)
print("After {0} iterations b = {1}, w = {2}, error = {3}".
format(num_iterations, b, w,
compute_error_for_line_given_points(b, w, points))
)
if __name__ == '__main__':
run()
运行结果

很明显,从计算结果中我们可以很清楚的看到损失的下降,w和b的具体数值也计算出来了,但是这个很显然这个损失依然有些大,同时我们在真正运行中会发现,会花费很长时间才能训练好这个模型,我们在代码中加入计时,结果如下:

114秒多,这个时间确实挺长,在这个少量的数据集中就需要花销那么长时间,很明显这个模型不太合格,仅做线性回归原理理解用,我们在下个博客中会告诉你如何解决这个问题,敬请期待。
数据集下载
链接:https://pan.baidu.com/s/1oOO09yVSllJ7hwPQLFackw
提取码:nxnf