先来提出问题和给出答案,之后再刨根问底的揭开面纱:
问:volatile 的可见性和禁止指令重排序是怎么实现的?
答:可见性:是通过缓存一致性协议来达到的
禁止指令重排序:JMM 模型里有 8 个指令来完成数据的读写,通过其中 load 和 store 指令相互组合成的 4 个内存屏障实现禁止指令重排序。
可见性
我们知道线程中运行的代码最终都是交给CPU执行的,而代码执行时所需使用到的数据来自于内存(或者称之为主存)。但是CPU是不会直接操作内存的,每个CPU都会有自己的缓存,操作缓存的速度比操作主存更快。
因此当某个线程需要修改一个数据时,事实上步骤是如下的:
1、将主存中的数据加载到缓存中
2、CPU对缓存中的数据进行修改
3、将修改后的值刷新到内存中
多个线程操作同一个变量的情况,则可以用下图表示(这个图下面会出现几次)

第一步:线程1、线程2、线程3 操作的是主存中的同一个变量,并且分别交由 CPU1、CPU2、CPU3 处理。
第二步:3个CPU分别将主存中变量加载到缓存中
第三步:各自将修改后的值刷新到主存中
问题就出现在第二步,因为每个CPU操作的是各自的缓存,所以不同的CPU之间是无法感知其他CPU对这个变量的修改的,最终就可能导致结果与我们的预期不符。
而使用了volatile关键字之后,情况就有所不同,volatile关键字有两层语义:
1、立即将缓存中数据写回到内存中
2、其他处理器通过嗅探总线上传播过来的数据监测自己缓存的值是不是过期了,如果过期了,就会对应的将缓存中的数据置为无效。而当处理器对这个数据进行修改时,会重新从内存中把数据读取到缓存中进行处理。
在这种情况下,不同的CPU之间就可以感知其他CPU对变量的修改,并重新从内存中加载更新后的值,因此可以解决可见性问题。
补充:
缓存一致性协议有多种,但是日常处理的大多数计算机设备使用的都属于“窥探(snooping)”协议。
“窥探” 背后的基本思想是,所有内存传输都发生在一条共享的总线上,而所有的处理器都能看到这条总线。
缓存本身是独立的,但是内存是共享资源,所有的内存访问都要经过仲裁(arbitrate):同一个指令周期中,只有一个缓存可以读写内存。窥探协议的思想是,缓存不仅仅在做内存传输的时候才和总线打交道,而是不停地在窥探总线上发生的数据交换,跟踪其他缓存在做什么。所以当一个缓存代表它所属的处理器去读写内存时,其他处理器都会得到通知,它们以此来使自己的缓存保持同步。只要某个处理器一写内存,其他处理器马上就知道这块内存在它们自己的缓存中对应的段已经失效。
实际使用场景
在实际开发中,我们在程序中通常会有一些标记标记变量。程序运行时根据根据这个标记变量值的不同决定是否执行某段业务逻辑处理代码。例如:
public class VolatileDemo { volatile static Boolean flag = true; public static void main(String[] args) { //该线程每隔1毫秒,修改一次flag的值 new Thread(){ public void run() { try { this.sleep(1); flag=!flag; } catch (InterruptedException e) {e.printStackTrace();} } }.start(); //主线程通过死循环不断根据flag进行判断是否要执行某段代码 while(true){ if(flag){ System.out.println("do some thing..."); }else { System.out.println("..."); } } } }
在这段代码中,由于我们在 flag 标识字段上使用了volatile关键字,因此自定义线程每次修改时状态变量的值时,主线程都可以实时的感知到。
特别的,对于多个线程都依赖于同一个状态变量的值来判断是否要执行某段代码时,使用volatile关键字更为有用,其可以保证多个线程在任一时刻的行为都是一致的。
禁止指令重排序
我们先来看一道面试题:
在单例 DCL 方式下,有没有必要加 volatile 关键词,为什么?
读到这里不会有不知道 DCL 是什么东东?那就有点孤陋寡闻了,DCL=双重检索,看以下单例代码就应该可以明白了:
public class Singleton { // 有没有必要增加 volatile 关键字 private volatile static Singleton instance; private Singleton() {} public static Singleton getInstance() { if (instance == null) { // 第一次判断 synchronized (Singleton.class) { if (instance == null) { // 第二次判断 instance = new Singleton(); } } } reurn instance; } }
这么看的话,代码应该没有问题呀,那我们再定义 instance 时,增加了 volatile 关键字,作用到底是什么?不加可不可以呢?
1、分配对象内存空间 2、初始化对象 3、设置 instance 指向刚刚分配的内存地址,此时 instance != null (重点)
1、分配对象内存空间 2、设置 instance 指向刚刚分配的内存地址,此时 instance != null (重点) 3、初始化对象
volatile底层如何实现指令重排
volatile 是通过 内存屏障 来防止指令重排序的。再上刚才那个图:
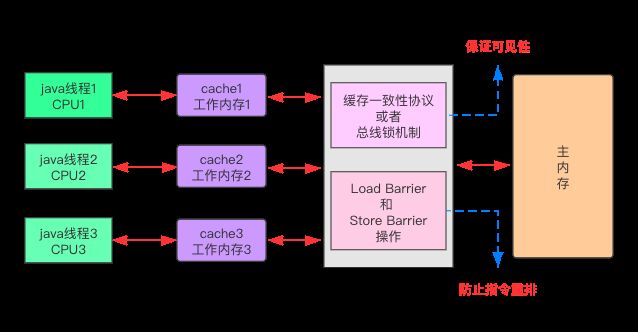
硬件层面的内存屏障分为 Load Barrier 和 Store Barrier 即 读屏障 和 写屏障。
对于 Load Barrier 来说,在指令前插入 Load Barrier,可以让高速缓存中的数据失效,强制从主内存加载数据。
对于 Store Barrier 来说,在指令后插入 Store Barrier,能让写入缓存中的最新数据更新写入主内存,让其他线程可见。
java 的内存屏障通常所谓的四种即:
1. LoadLoad
2. StoreStore
3. LoadStore
4. StoreLoad
实际上也是上述两种的组合,完成一系列的 屏障 和 数据同步 功能。
LoadLoad 屏障:对于这样的语句 Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
StoreStore屏障:对于这样的语句 Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
LoadStore屏障:对于这样的语句 Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
StoreLoad屏障:对于这样的语句 Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。它的开销是四种屏障中最大的。在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能
volatile防止指令重排序具体步骤
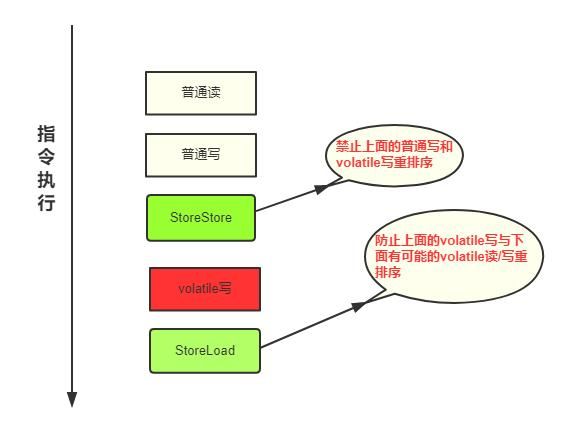
1、在每个 volatile写操作 前面插入一个 StoreStore屏障。
2、在每个 volatile写操作 后面插入一个 StoreLoad屏障。
3、在每个 volatile读操作 后面插入一个 LoadLoad屏障。
4、在每个 volatile读操作 后面插入一个 LoadStore屏障。