Cache – 主存的地址映射及相关计算问题
Cache – 主存的地址映射及相关计算问题
在开始本篇博文之前,首先来介绍下问题背景,以便于初学者能更好的理解(当然其实我也是个小白),如果大家已经了解问题背景,直接跳过下面两段,不用听我多BB。
对于Cache,即高速缓存,是用来解决主存与CPU速度不匹配问 题,Cache的出现使得CPU可以不直接访问主存而直接与高速Cache交换信息。由于程序访问的局部性原理可以很容易设想只要将 CPU近期要用到的程序和数据提前从主存送到Cache,那么就可以做到CPU在一定时间内只访问Cache,这样CPU与高速Cache进行通信,就大大提高了计算机的运行速度。
在Cache – 主存的地址映射之前,首先要将主存与Cache都分成若干块,每块又包括若干个字,并使得它们的大小相同(即快内的字数相同)。在划分好块后,下面要做的就是将主存块与Cache块形成映射就行了。而这里的映射则是通过块的地址形成映射关系。对于地址映射,首先将主存地址分成两块,高n1位为主存的快地址,低n2位为快内地址。Cache同理也是这样划分。这里我原来一直有一个误区,就是认为字块中存放的是数据地址,其实不然,字块中存放的就是真正使用的数据,只是映射时使用地址来映射。在一切准备就绪后,就可以进行映射了,下面开始本篇博文的正文。
Cache – 主存的地址映射方式有很多,有直接映射,全相联映射,组相联映射。
1.直接映射
在这种映射方式下,每个主存块至于一个缓存块相对应,映射关系为:
i=j mod C 或 i=j mod 2c2c
其中,i为缓存块号,j为主存块号。在这种取模方式下,很容易就知道每个缓存块对应若干个主存块。
不废话直接上图:
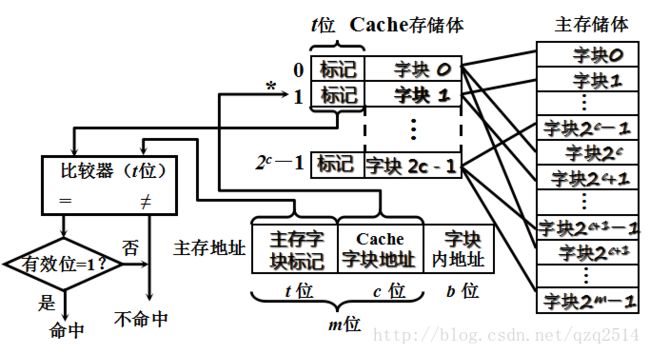
下面针对该映射方式,举一个小例子:
当缓存接收到CPU发送来的主存地址后,只需根据中间c位字段(假设为00…01)找到缓存块1,然后根据字块1的”标记”是否与主存地址的高t位相符合,若符合且有效位为1(这里的有效位用来识别Cache存储块中的额数据是否有效,因为有时Cache中的数据是无效的,例如,在初始时刻Cache中的额内容为空,是无意义的),则表示该Cache块已和主存中的某块建立了对应关系,则可根据b位块内地址从Cache块中取得对应的字,即找到CPU发来的主存地址在缓存中所对应的信息;若不符合,或者有效位为”0”,则主存读入心得字块来代替旧的字块,同时将信息送往CPU,并修改Cache“标记”位。如果有效位为”0”,还得将有效位置为 “1”。
小结:直接相联映射方式的缺点是不灵活,每个主存块只能按照取模固定地映射到某个缓存块,即使缓存内其他块空着,也不能用来映射。因而如果程序恰好要重复地使用对应同一缓存块的不同主存块,那么久需要不同的替换,这样会降低命中率。
2.全相联映射
为了解决直接相联映射不灵活的问题,出现了全相联映射。全相联映射不是通过字块号来寻找字块,而是将主存地址中的标记与缓存中每个字块的标记进行比较,如果找到与之相同标记的缓存块,则表明所访问的主存地址在缓存中,之后在Cache中找到缓存块后,再根据主存地址的低b位找到快内地址,这样就找到对应的字,也就是需要的数据。因而在这种映射方式下,主存地址中只需要主存字块标记和字块内地址就行。具体的映射和主存地址格式如下:
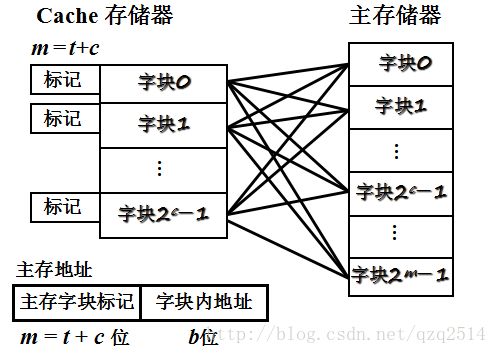
小结:全相联映射允许将主存中的每一字块映射到Cache中的任意一块位置上。显然这种映射方式相对于直接映射,更加灵活,因而命中率也更高,缩小了块冲突。
由于需要将主存地址中的标记与每一个缓存块的标记进行比较,也就使其具有了”按内容寻址”的特点。同时也因为这个特点,所需的逻辑电路较多,成本也比较高,实际的Cache还要采用各种措施来减少比较次数。
3.组相联映射
针对上述直接映射和全相联映射出现的问题,现在出现一种折中的映射方式,即下面介绍的组相联映射。该映射方式将所有Cache分为Q组,每组有R块,则有以下关系:
i =j mod Q
其中i,j的含义与直接映射中的含义一致。上述表达式意思即为某一主存块按模Q将其映射到缓存的第i组内,具体步骤即主存地址格式如下:
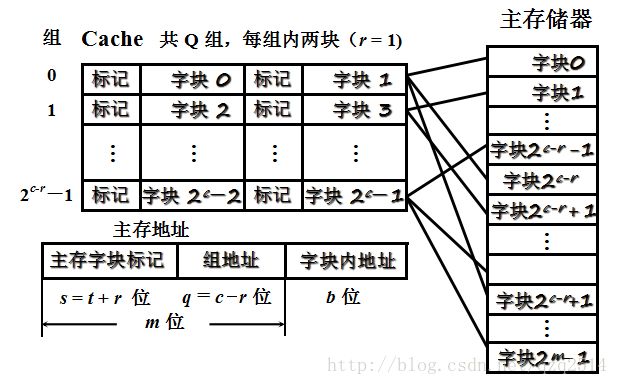
这里之所以说组相联映射是直接映射和全相联映射的折中,是因为按照直接映射中取模的方式,某个主存块映射到Cache中的组是固定的,但是在组内,又按照全相联映射原则,”按内容寻址”,即通过主存字块标记可以映射到该组中任意一块Cache块。
这样就更好理解了该映射方式下主存的地址格式,首先通过组地址找到Cache块所在的组,之后按照全相联映射方式,通过和组内的每一块比较主存字块标记来寻找需要的具体字块,最后通过字块内地址在Cache块中找到有效的物理地址。
这里看似主存地址很复杂,其实只要知道Cache一共有多少组即可确定组地址的位数,之后字块内地址与前面两种映射方式所说的一致,最后通过总位数减去组地址位数和字块内地址位数即得主存字块标记位数。
有个需要记住的小知识点:若每组内有n块Cache块,则该种映射方式又称为n路组相联。
其实这里有个转化方式,当r=0,即每组内有2r=20=12r=20=1块,即所有的Cache字块都在一组,那么此时组相联即变为全相联映射。
空口吹谁都会,下面将通过两个例子更加详细和直观地介绍下主存地址格式(这两题都是唐朔飞老师《计算机组成原理》中的题目,我将用自己的语言平实简单表达出来,希望大家更好的理解):
例1.假设主存容量为512KB,Cache容量为4KB,每个字块为16个字,每个字为32位。问:
(1).Cache地址为多少位?可容纳多少块?
(2).主存地址为多少位?可容纳多少块?
(3).在直接映射方式下,主存的第几块映射到Cache中的第五块(设起始字块号为1)
(4).画出直接映射方式下主存地址字段中各段的位数。
答:
(1).这里没有说按照字还是字节编址,那么按照其给的容量的格式,可以得出其默认按照字节编址。那么根据容量的计算方法:地址数*字长,则Cache的4KB可得地址数为4K,即212212地址才能访问到每个Cache块,即c=位,所以最终 主存字块标记位数=主存地址数-字块地址数-字块内地址数,即t=19-6-6=7位,所以得到主存地址格式为:

例2.假设主存容量为512K*16位,Cache容量为4096*16位,块长为4个16位的字,访存地址为字。
(1).在直接映射下,设计主存的地址格式。
(2).在全相联映射下,设计主存的地址格式。
(3).在二路组相联映射方式下,设计主存的地址格式。
(4).若主存容量为512K*32位,块长不变,在四路组相联映射下,设计主存的地址格式。
答:
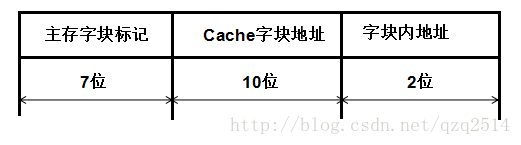
(1).按照例1中,用容量除以块大小得到块的个数,个数为:(4096*16位)/4*16位=1024=210210,所以Cache块地址位数为10,即c=10,由于这里按照字访存,主存地址也很容易得到为19位,对于字块内地址,字块内共有4*16位/16位=4个访存单元,所以就有4个字块内地址,所以字块内地址就有2位,即b=2,所以最后求得主存字块标记有19-10-2=7位,得到主存字块地址格式:
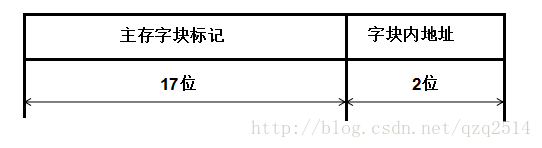
(2).在全相联映射下,主存地址仅由字块内地址和主存字块标记构成,而字块内地址在(1)中求得为2位,所以这里的字块内地址为19-2=17位。此时的主存地址格式为:
(3).在二路组相联映射中,每组有两个字块,所以一共有210/2=29210/2=29组,故组地址有9位,即q=9,由于每个字块到这里都是没有变化的,所以字块内地址仍为2位,即b=2,所以主存字块标记为19-9-2=8位,故得到主存地址格式为:

(4).主存容量为512K*32位,即双字宽存储器,即每次可以访问两个字(最小访存单元),这里的访存地址单元仍为字没有变,并且块长仍为4个16位的字,所以字块内地址仍为2位,而主存容量可以转为512K*32位=1024K*16位,这样就可以得到共有1024K个字,即220220组,所以组地址为8位,即q=8,这样得到主存字块标记有20-8-2=10位,得到如下主存字块地址格式:

总结:
1.直接映射为固定的映射关系,不灵活。
2.全相联映射为灵活性映射关系,通过主存字块标记,以按内容寻址的方式查找缓存块。
3.组相联映射为上述两种的折中,主存块被分配到固定组的任意一个缓存块。
4.在求主存地址格式时,要找好各字段的位数,尤其要注意访存地址单元是字还是字节。