利用Python爬取虎扑上你喜爱的球员的基本数据
最近一有时间就看NBA凯尔特人的比赛,当然一有比赛就会有输赢和各种数据的统计,所以我就想要了解自己喜欢的球员的一些数据
作为一个“文密”也就是Kyrie irving的球迷,自然是想关注一下他的各项数据。也是想要了解一下他在这个赛季中的一些变化。

当然也可以打开虎扑主页点击相关的球员
https://nba.hupu.com/players
这里面包含了所有的球员。
进入了球员页面后对网页进行分析,我用的是谷歌浏览器,右键选择检查。
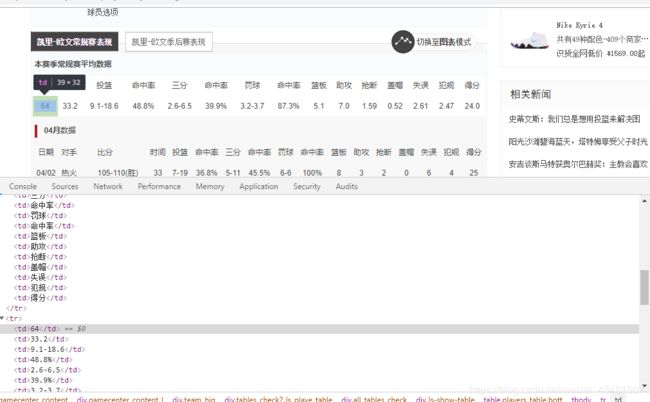
这样我们可以看到我们想要的数据,可以用很多方法将我们的数据提取出来,因为比较容易,所以我用的BeautifulSoup库对页面进行解析。
接下来就是将这些数据保存到文件或者数据库中
这里我之前就已经创建好了一个数据库列表,因此我就将其放入MySQL中
为了方便直观,我选择 Navicat查看数据信息

也包括了每一场次的详细数据

整个过程就是这样。希望能帮助到喜爱NBA的你。
#这是获取球员的本赛季场均数据
import requests
from bs4 import BeautifulSoup
import MySQLdb
db = MySQLdb.connect("localhost", "username", "passwd", "name", charset='utf8' )
cur=db.cursor()
def getHtmlText(url,headers):
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print("Error(GetHtmlText)")
def HtmlParser(html,shuju_list):
soup = BeautifulSoup(html,'html.parser')
infos = soup.find('div',{'class':'team_hig'}).find('table',{'class':'players_table bott'})
shuju = infos.find('tr',{'class':''}).find_all('td')
for i in shuju:
shuju_list.append(i.get_text())
return shuju_list
def insert_into_mysql(shuju_list):
name = 'Kyrie'
cursor = db.cursor()
# SQL 插入语句
sql = "INSERT INTO avegshow VALUES\
('%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s')"\
%(name,shuju_list[0],shuju_list[1],shuju_list[2],shuju_list[3],shuju_list[4],shuju_list[5],shuju_list[6]\
,shuju_list[7],shuju_list[8],shuju_list[9],shuju_list[10],shuju_list[11],shuju_list[12],shuju_list[13],shuju_list[14])
print(sql)
try:
#cursor.executemany(sql, usersvalues)
# 执行sql语句
cursor.execute(sql)
# 提交到数据库执行
db.commit()
except UnicodeEncodeError:
# Rollback in case there is any error
print("error")
# 关闭数据库连接
db.close()
if __name__ == '__main__':
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
url = "https://nba.hupu.com/players/kyrieirving-3554.html"
shuju_list = []
html = getHtmlText(url,headers)
HtmlParser(html,shuju_list)
insert_into_mysql(shuju_list)
#这是对阵每一球队的详细数据
import requests
from bs4 import BeautifulSoup
import time
import MySQLdb
db = MySQLdb.connect("localhost", " username", " passwd", "name", charset='utf8' )
cur=db.cursor()
def getHtmlText(url,headers):
try:
r = requests.get(url, headers=headers,timeout = 20)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print("Error(GetHtmlText)")
def HtmlParser(html):
soup = BeautifulSoup(html,'html.parser')
shuju_list = []
cursor = db.cursor()
infos = soup.find('div',{'class':'all_tables_check'}).find_all('table',{'class':'players_table bott bgs_table'})
for info in infos:
shuju = info.find_all('tr',{'class':'color_font1 borders_btm'})
for shuju2 in shuju:
shuju_final = shuju2.find_all('td')
for i in shuju_final:
shuju_list.append(i.get_text())
if shuju_list[0] != '日期':
sql = "INSERT INTO battle VALUES\
('%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s')" \
% (shuju_list[0], shuju_list[1], shuju_list[2], shuju_list[3], shuju_list[4], shuju_list[5],
shuju_list[6] , shuju_list[7], shuju_list[8], shuju_list[9], shuju_list[10], shuju_list[11],
shuju_list[12], shuju_list[13], shuju_list[14],shuju_list[15],shuju_list[16])
print(sql)
try:
# 执行sql语句
cursor.execute(sql)
# 提交到数据库执行
db.commit()
except UnicodeEncodeError:
print("error")
shuju_list = []
time.sleep(1)
# 关闭数据库连接
db.close()
if __name__ == '__main__':
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
url = "https://nba.hupu.com/players/kyrieirving-3554.html"
shuju_list = []
html = getHtmlText(url,headers)
HtmlParser(html)
获取详细数据虽说能实现,但是代码确实太“丑”,如果有大神路过的话,希望能指点一下我这位Python小白。