【Kaggle实战】Python进行泰坦尼克生存预测
一、问题
——预测泰坦尼克号乘客的存活状态
二、数据理解
1.数据来源: https://www.kaggle.com/c/titanic/data
得到两个csv文件:
① train.csv:包含一部分乘客的基本信息和生存状态。
② test.csv:包含了另一部分乘客的基本信息,无生存状态,需要建模预测。
2.导入包和数据
#导入包
import numpy as np
import pandas as pd
#导入数据
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
print ('训练数据集:',train.shape,'测试数据集:',test.shape)
训练数据集: (891, 12) 测试数据集: (418, 11)
3.查看数据
train.head()
test.head()
train.info()
print ('------------------------------------')
test.info()
4.合并数据,方便后面一起进行数据清理
#合并数据集,方便同时对两个数据集进行清洗
union = train.append( test , ignore_index = True )
print ('合并后的数据集:',union.shape)
union.info()

分析:
数据总共有1309行。变量分别是:Passengerld 乘客编号,Survived 生存情况(1=存活,0=死亡),Pclass客舱等级(1=1等舱,2=2等舱,3=3等舱),Name姓名,Sex性别,Age年龄,SibSp船上兄妹姐妹数、配偶数,Parch 船上父母数、子女数,Ticket 船票编号,Fare船票价格,Cabin 客舱号,Embarked 登船港口
数值型变量:Age,Fare,Parch,Passengerld,Pclass,SibSp,Survived
非数值型变量:Cabin,,Embarked,Name,Sex,Ticket
其中数值型变量中年龄(Age)、船舱号(Cabin)里面有缺失数据;非数值型变量中登船港口(Embarked)和船舱号(Cabin)里面有缺失数据。
1)年龄(Age)里面数据总数是1046条,缺失了1309-1046=263,缺失率263/1309=20%。
2)船票价格(Fare)里面数据总数是1308条,缺失了1条数据。
字符串列:
3)登船港口(Embarked)里面数据总数是1307条,只缺失了2条数据。
4)船舱号(Cabin)里面数据总数是295,缺失了1309-295=1014,缺失率=1014/1309=77.5%,缺失比较大。
三、数据清理
1.缺失值处理
#缺失值处理
#1.数值型:年龄、船票价格
union['Age']=union['Age'].fillna(union['Age'].mean())
union['Fare']=union['Fare'].fillna(union['Fare'].mean())
union.info()
#缺失值处理
#2.字符串型:Cabin、Embarked
union['Cabin'].head()
union['Cabin'].value_counts()
#Cabin缺失数据比较多,可填充为U,表示未知
union['Cabin'] = union['Cabin'].fillna( 'U' )
#Embarked只缺失两个值
union['Embarked'].value_counts()
#在pandas里面常用value_counts确认数据出现的频率。
union['Embarked'] = union['Embarked'].fillna( 'S' )
#将缺失值填充为最频繁出现的值
union.info()
2.数据分类进行特征提取
——还有5个字符串变量,利用one-hot编码处理
其中:Cabin、Embarked、sex进行分类处理,Name、Ticket数据较杂乱,暂不考虑这两个变量,另外Parch和SibSp加总做一个家庭大小分类处理,Pclass做一个客舱等级分类处理。
(1)Cabin
##特征提取
#Cabin——提取首字母
union['Cabin']=union['Cabin'].map(lambda a : a[0])
union['Cabin'].unique()
##特征提取
#Cabin——进行one-hot编码,产生虚拟变量,列名前缀是Cabin
cabindf=pd.get_dummies(union['Cabin'],prefix = 'Cabin')
cabindf.head()
##特征提取
#Cabin——合并、删除
#np.concatenate([arr1, arr2])默认是纵向合并;np.concatenate([arr1, arr2], axis=1)指定轴方向,axis=1时是横向合并
union=pd.concat([union,cabindf],axis=1)
#通过对象的 .drop(labels, axis=0) 方法,删除Series的行元素;通过对象的 .drop(labels, axis=1) 方法,删除Series的列元素
union.drop('Cabin',axis=1,inplace=True)
##特征提取
#Cabin
union.head()
(2)Embarked
##特征提取
#Embarked——看有几类
union['Embarked'].unique()
##特征提取
#Embarked——进行one-hot编码,产生虚拟变量,列名前缀是Embarked
Embarkeddf=pd.get_dummies(union['Embarked'],prefix='Embarked')
Embarkeddf.head()

##特征提取
#Embarked——合并、删除
union=pd.concat([union,Embarkeddf],axis=1)
union.drop('Embarked',axis=1,inplace=True)
union.head()
union.info()

(3)sex
##特征提取
#sex
union['Sex'].unique()
sex_dict={'female':0,'male':1}
union['Sex']=union['Sex'].map(sex_dict)
union.head()
(4)Pclass
##特征提取
#Pclass——进行one-hot编码
pclassdf=pd.get_dummies(union['Pclass'],prefix='Pclass')
pclassdf.head()

##特征提取
#Pclass——合并、删除
union=pd.concat([union,pclassdf],axis=1)
union.drop('Pclass',axis=1,inplace=True)
union.head()
union.info()
(5)Parch 和SibSp
##特征提取
#Parch 和SibSp ——家庭大小
familydf=pd.DataFrame()
familydf['familysize']=union['Parch']+union['SibSp']+1
familydf['bigfamily']=familydf['familysize'].map(lambda b:1 if b>=5 else 0)
familydf['midfamily']=familydf['familysize'].map(lambda b:1 if 2<=b<=4 else 0)
familydf['smallfamily']=familydf['familysize'].map(lambda b:1 if b==1 else 0)
familydf.head()
##特征提取
#Parch 和SibSp ——合并、删除
union=pd.concat([union,familydf],axis=1)
union.drop(['Parch','SibSp','familysize'],axis=1,inplace=True)
union.info()
3.特征删除
##特征删除
#删除Name和Ticket
union.drop(['Name','Ticket'],axis=1,inplace=True)
union.info()

4.特征选择
——根据所有变量的相关系数矩阵,筛选出与预测标签Survived最相关的特征变量。
##特征选择
tz=union.corr()
tz.head()

##选择特征
tz['Survived'].sort_values(ascending=False)
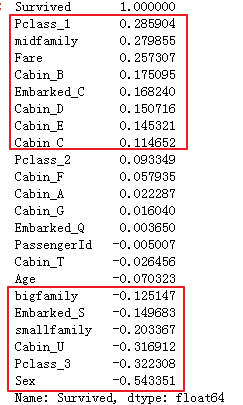
分析:从相关性大小,可以看出可以选择pclassdf,familydf,fare,cabindf,sex作为特征。
5.建立特征数据集
##建立特征数据集
# 选择pclassdf,familydf,fare,cabindf,sex作为特征
union_new=pd.concat([pclassdf,familydf,union['Fare'],cabindf,union['Sex']],axis=1)
union_new.head()

四、建立模型和预测结果
——使用loc属性拆分出891行原始数据集、481行预测数据集。
##建立模型
union_a=union_new.loc[0:890,:]
union_b=union.loc[0:890,'Survived']
pred_a=union_new.loc[891:,:]
#引入sklearn分割数据模块包
from sklearn.cross_validation import train_test_split
train_a, test_a, train_b, test_b= train_test_split(union_a,union_b,train_size=0.8)
——建模的时候,需要将原始数据集进行二八拆分:80%训练集+20%测试集。训练集用于训练模型;测试集用于评估模型效果。利用sklearn分割数据模块包。
#输出数据集大小
print ('原始数据集特征:',union_a.shape,
'训练数据集特征:',train_a.shape,
'测试数据集特征:',test_a.shape)
print ('原始数据集标签:',union_b.shape,
'训练数据集标签:',train_b.shape,
'测试数据集标签:',test_b.shape)
原始数据集特征: (891, 18) 训练数据集特征: (712, 18) 测试数据集特征: (179, 18)
原始数据集标签: (891,) 训练数据集标签: (712,) 测试数据集标签: (179,)
注:train_a 训练数据集特征test_a 训练数据集标签
test_a 测试数据集特征 test_b 测试数据集标签
1.使用逻辑回归算法
###选择机器学习算法
##使用逻辑回归算法
#导入包
from sklearn.linear_model import LogisticRegression
model=LogisticRegression()
(1)训练函数
##使用逻辑回归算法
#训练函数
model.fit(train_a,train_b)
(2)评估函数
##使用逻辑回归算法
#评估函数
model.score(test_a,test_b)
= 0.8268156424581006
(3)预测
##使用逻辑回归算法
#预测
pred_b=model.predict(pred_a)
#passenger_id = union.loc[891:,'PassengerId']
#preddf=pd.DataFrame({ 'PassengerId':passenger_id ,'Survived':pred_b})
preddf=pd.DataFrame({ 'Survived':pred_b})
preddf.shape
preddf.head()
2.使用随机森林算法
(1)建立模型和训练模型
#建立模型和训练模型
#model=RandomForestClassifier(random_state = 20,warm_start = True,n_estimators = 18,max_depth = 6,max_features = 'sqrt')
model=RandomForestClassifier(n_estimators = 30,max_depth = 6,max_features = 'sqrt')
model.fit(train_a,train_b)
(2)评估模型
#评估模型
model.score(test_a,test_b)
= 0.8212290502793296
(3)预测
#预测
pred_b=model.predict(pred_a)
preddf1=pd.DataFrame({ 'Survived':pred_b})
preddf1.shape
preddf1.head()
3.两个算法模型预测结果对比
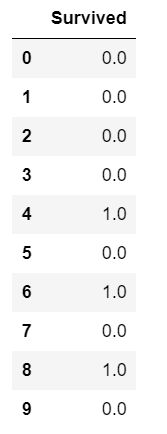
#随机森林算法预测结果(前10条)
preddf1.head(10)
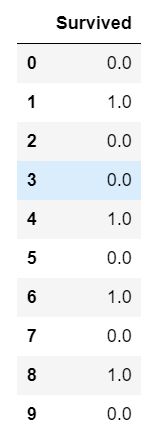
##逻辑回归算法预测结果(前10条)
preddf.head(10)
print ('逻辑回归预测结果:',preddf.apply(pd.value_counts))
print ('随机森林预测结果:',preddf1.apply(pd.value_counts)
逻辑回归预测结果: Survived
0.0 254
1.0 164
随机森林预测结果: Survived
0.0 277
1.0 141
分析:
逻辑回归算法预测结果:418人中存活160人;
随机森林算法预测结果: 418人中存活139人
两个模型预测结果还算比较接近。
4.模型的优化
思路:可以考虑将逻辑回归算法预测结果和随机森林算法预测结果放在一起再做一个集成分类算法,使预测结果更优,更准确。