基于cdh5的spark测试
1.cdh集群环境
cdh版本 5.13.2
jdk 1.8
scala 2.10.6
zookeeper 3.4.5
hadoop 2.6.0
yarn 2.6.0
spark 1.6.0 、2.1.0
kafka 2.1.0
备注: 基于CDH进行Spark开发时,使用高版本的apache原生包即可;不需要使用CDH中的spark开发包,另外,其它生态项目也如此。在IDEA开发的时候用原生包,实际往生产环境部署时默认就使用CDH的包了。
2.pom.xml配置
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.xxxx.xxxgroupId>
<artifactId>sparkartifactId>
<version>1.0-SNAPSHOTversion>
<properties>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<scala.compat.version>2.10scala.compat.version>
<maven.compiler.encoding>UTF-8maven.compiler.encoding>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8project.reporting.outputEncoding>
<scala.version>2.10.6scala.version>
<spark.version>1.6.0spark.version>
properties>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.orgid>
<name>Scala-tools Maven2 Repositoryname>
<url>http://scala-tools.org/repo-releasesurl>
pluginRepository>
pluginRepositories>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.10artifactId>
<version>${spark.version}version>
<scope>providedscope>
dependency>
dependencies>
<build>
<sourceDirectory>src/main/scalasourceDirectory>
<testSourceDirectory>src/test/scalatestSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-toolsgroupId>
<artifactId>maven-scala-pluginartifactId>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
execution>
executions>
<configuration>
<scalaVersion>${scala.version}scalaVersion>
<args>
<arg>-target:jvm-1.5arg>
args>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-eclipse-pluginartifactId>
<configuration>
<downloadSources>truedownloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilderbuildcommand>
buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanatureprojectnature>
additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINERclasspathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINERclasspathContainer>
classpathContainers>
configuration>
plugin>
plugins>
build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-toolsgroupId>
<artifactId>maven-scala-pluginartifactId>
<configuration>
<scalaVersion>${scala.version}scalaVersion>
configuration>
plugin>
plugins>
reporting>
project>- 执行模式

- 本地测试
需要修改hdfs上文件输入、输出路径的权限:hadoop fs -chmod -R 777 /xxx
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ArrayBuffer
object WordCount {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName(this.getClass.getName).setMaster("local[1]")
val sc: SparkContext = new SparkContext(conf)
sc.setCheckpointDir("hdfs://192.168.226.88:8020/test/checkPoint")
//入参:文件读取路径 文件输出路径
//F:\\ideaProjects\\spark_kafka\\src\\main\\resources\\words
//hdfs://192.168.226.88:8020/test/input/wordcountInput.txt
val inputFile: String = args(0)
val outputFile: String = args(1)
val lineRDD: RDD[String] = sc.textFile(inputFile)
val wordsRDD: RDD[String] = lineRDD.flatMap(line => line.split(" "))
val tupsRDD: RDD[(String, Int)] = wordsRDD.map(word => (word,1))
val wordCountRDD: RDD[(String, Int)] = tupsRDD.reduceByKey((tupValue1, tupValue2) => tupValue1 + tupValue2)
if (wordCountRDD.isCheckpointed == false) {
wordCountRDD.checkpoint()
}
//println(wordCountRDD.collect().toBuffer)
val charRDD: RDD[ArrayBuffer[(Char, Int)]] = wordCountRDD.map(wordCountTup => {
//val listBuffer = new ListBuffer[Tuple2[Char,Int]]
val arrayBuffer = new ArrayBuffer[Tuple2[Char,Int]]()
val charArr: Array[Char] = wordCountTup._1.toCharArray
for (char <- charArr) {
val tuple: (Char, Int) = (char, wordCountTup._2)
arrayBuffer += tuple
}
arrayBuffer
})
val charCountRDD: RDD[(Char, Int)] = charRDD.flatMap(arrBuf => arrBuf).reduceByKey(_+_)
charCountRDD.saveAsTextFile(outputFile)
//println(charCountRDD.collect().toBuffer)
}
}
- 集群提交,集群运行(spark on yarn模式)
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ArrayBuffer
object WordCount {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName(this.getClass.getName)
val sc: SparkContext = new SparkContext(conf)
sc.setCheckpointDir("hdfs://192.168.226.88:8020/test/checkPoint")
//入参:文件读取路径 文件输出路径
//F:\\ideaProjects\\spark_kafka\\src\\main\\resources\\words
//hdfs://192.168.226.88:8020/test/input/wordcountInput.txt
val inputFile: String = args(0)
val outputFile: String = args(1)
val lineRDD: RDD[String] = sc.textFile(inputFile)
val wordsRDD: RDD[String] = lineRDD.flatMap(line => line.split(" "))
val tupsRDD: RDD[(String, Int)] = wordsRDD.map(word => (word,1))
val wordCountRDD: RDD[(String, Int)] = tupsRDD.reduceByKey((tupValue1, tupValue2) => tupValue1 + tupValue2)
if (wordCountRDD.isCheckpointed == false) {
wordCountRDD.checkpoint()
}
//println(wordCountRDD.collect().toBuffer)
val charRDD: RDD[ArrayBuffer[(Char, Int)]] = wordCountRDD.map(wordCountTup => {
//val listBuffer = new ListBuffer[Tuple2[Char,Int]]
val arrayBuffer = new ArrayBuffer[Tuple2[Char,Int]]()
val charArr: Array[Char] = wordCountTup._1.toCharArray
for (char <- charArr) {
val tuple: (Char, Int) = (char, wordCountTup._2)
arrayBuffer += tuple
}
arrayBuffer
})
val charCountRDD: RDD[(Char, Int)] = charRDD.flatMap(arrBuf => arrBuf).reduceByKey(_+_)
charCountRDD.saveAsTextFile(outputFile)
//println(charCountRDD.collect().toBuffer)
}
}
#!/bin/sh
BIN_DIR=$(cd `dirname $0`; pwd)
#BIN_DIR="$(cd $(dirname $BASH_SOURCE) && pwd)"
LOG_DIR=${BIN_DIR}/../logs
LOG_TIME=`date +%Y-%m-%d`
#main函数传入参数
inputFile='hdfs://192.168.226.88:8020/test/input/wordcountInput.txt'
outputFile='hdfs://192.168.226.88:8020/test/output'
spark-submit --class WordCount \
--master yarn \
--deploy-mode client \
--queue default \
--executor-memory 512m \
--num-executors 1 \
--jars /opt/cloudera/parcels/HADOOP_LZO/lib/hadoop/lib/hadoop-lzo.jar \
/home/spark/jars/spark_kafka-1.0-SNAPSHOT.jar $inputFile $outputFile > ${LOG_DIR}/wordcount_${LOG_TIME}.log 2>&16.错误记录
6.1 依赖libgplcompression.so
cp /opt/cloudera/parcels/HADOOP_LZO/lib/hadoop/lib/native/libgplcompression.so /usr/local/jdk1.8.0_152/jre/lib/amd64
参考:https://blog.csdn.net/u011750989/article/details/49306439
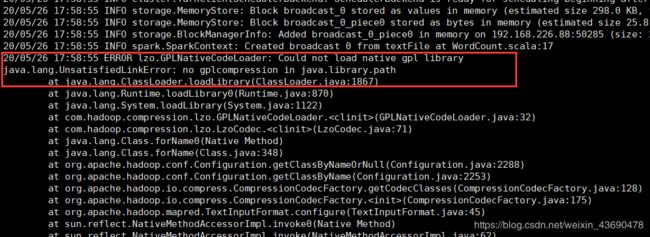
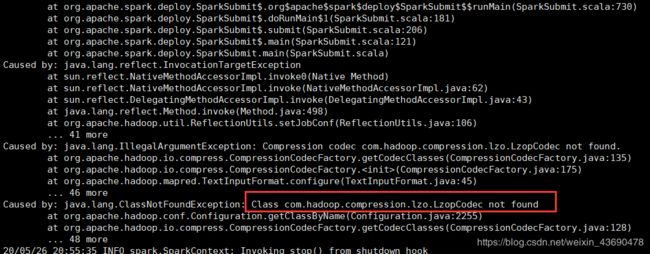
6.2 添加hadoop-lzo.jar
spark-submit脚本添加–jars /opt/cloudera/parcels/HADOOP_LZO/lib/hadoop/lib/hadoop-lzo.jar
参考:https://www.cnblogs.com/francisYoung/p/6073842.html
6.3 内存配置
修改节点内存和单个container内存,hadoop02,hadoop03物理内存3g,可分配给节点内存2g
yarn.scheduler.minimum-allocation-mb 1g 每个节点单个container可申请最小内存
yarn.scheduler.maximum-allocation-mb 2g 每个节点单个container可申请最大内存
yarn.nodemanager.resource.memory-mb 2g 每个节点可用的最大内存
参考:
https://zhuanlan.zhihu.com/p/69703968
http://blog.chinaunix.net/uid-28311809-id-4383551.html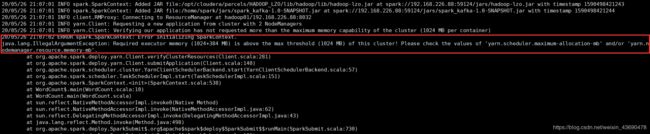
参考文献:
https://docs.cloudera.com/documentation/enterprise/5-13-x/topics/spark.html