最简单深度学习Python实现(二分类问题)
二分类问题指的是所有数据的标签就只有两种,正面或者负面。
一,准备数据
我们使用的数据是内置于Keras的IMDB数据集。它包含50000条两极分化的电影评论,正面评论和负面评论各占一半。其中25000用于训练,25000用于测试。
rom keras.datasets import imdb
#加载imdb数据集
(train_data,train_labels),(test_data,test_labels) = \
imdb.load_data(num_words=10000)#保留前10000个最常出现的单词数据已经被预处理,单词被转换成了整数,每个整数代表了某个单词,所以我们看到的是由单词索引组成的列表:
![]() 而标签则是0和1组成的列表,0代表负面,1代表正面:
而标签则是0和1组成的列表,0代表负面,1代表正面:

接下来我们要对数据进行one-hot编码,即所有数据都是10000维向量(因为数据最多也就出现一万个字,你只载入了前一万个最常出现的单词)他出现的数字的索引的值为1,其余为0,举个简单的例子,如果某个评论只有两个单词,即只有两个数字(假设为3和5),那么它就是[3,5],转为one-hot就变成10000维向量,只有索引3,5,的元素是1,其余都是0.
#将数据向量化
def vectoriza_sequences(sequences,dimension=10000):
results = np.zeros((len(sequences),dimension))
#生成一个元素全部为0,形状是数据长度*10000的二维numpy数组
for i, sequence in enumerate(sequences):
#enumerate()函数返回两个参数:元素下标,对应的元素
results[i,sequence] = 1
#这里i返回的就是0-24999,sequence返回的是一个列表。
return results
x_train = vectoriza_sequences(train_data)
x_test = vectoriza_sequences(test_data)如果对于 vectoriza_sequences不是很理解可以看一下这个简单的代码
import numpy as np
a = np.zeros((3,4))
a[0,[1,3]] = 1
#数组a的第一行,第二列第四列就变成一了
print(a)
标签可以直接向量化为numpy数组
#标签向量化
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')二,构建网络
网络使用带有relu激活层的全连接层(Dense)的简单堆叠,最后一层用sigmoid来激活以输出一个0~1范围的概率值
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(16,activation='relu',input_shape=(10000,)))
model.add(layers.Dense(16,activation='relu'))
model.add(layers.Dense(1,activation='sigmoid'))接下来是编译模型,我们选择rmsprop优化器和binary_crossentropy损失函数来配置模型。损失函数用来衡量我们的输出值和标签的差距大小。优化器就是根据这个差距每次更新参数的方法(简单说就是梯度下降,复杂了我也不会说)。
#编译模型
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])三,训练与预测
接下来是训练模型,没啥说的
#训练模型
model.fit(x_train,y_train,epochs=4,batch_size=512)
#每训练512个样本计算一次梯度下降,调整一次参数
#把所有25000个数据一共训练四轮
results = model.evaluate(x_test,y_test)
print(results)
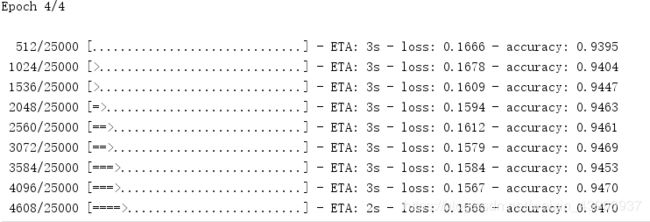
可以看到准确率越来越高
再看下在测试集的表现
![]()
损失0.34,准确率0.86.也还不错
最后预测一下
print(model.predict(x_test))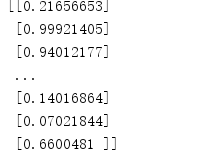
输出的是概率,因为用sigmoid激活的(此代码主要参考《Python深度学习》中的内容,有补充和错误之处请指出,谢谢)。
以下是完整代码:
import numpy as np
from keras.datasets import imdb
#加载imdb数据集
(train_data,train_labels),(test_data,test_labels) = \
imdb.load_data(num_words=10000)#保留前10000个最常出现的单词
#将数据向量化
def vectoriza_sequences(sequences,dimension=10000):
results = np.zeros((len(sequences),dimension))
#生成一个元素全部为0,形状是数据长度*10000的二维numpy数组
for i, sequence in enumerate(sequences):
#enumerate()函数返回两个参数:元素下标,对应的元素
results[i,sequence] = 1
#这里i返回的就是0-24999,sequence返回的是一个列表。
return results
x_train = vectoriza_sequences(train_data)
x_test = vectoriza_sequences(test_data)
#标签向量化
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
#构建网络
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(16,activation='relu',input_shape=(10000,)))
model.add(layers.Dense(16,activation='relu'))
model.add(layers.Dense(1,activation='sigmoid'))
#编译模型
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
#训练模型
model.fit(x_train,y_train,epochs=4,batch_size=512)
#每训练512个样本计算一次梯度下降,调整一次参数
#把所有25000个数据一共训练四轮
results = model.evaluate(x_test,y_test)
print(model.predict(x_test))