图像识别-ResNet-18网络结构图示及解读
ResNet-18网络结构图示及详细解读
- 一、介绍
- 二、网络结构
- 1. 网络参数
- 2. 网络图示
- 三、总结
一、介绍
ResNet系列网络,图像分类领域的知名算法,经久不衰,历久弥新,直到今天依旧具有广泛的研究意义和应用场景。被业界各种改进,经常用于图像识别任务。
今天主要介绍一下ResNet-18网络结构,其他深层次网络,可以依次类推。
ResNet-18,数字代表的是网络的深度,也就是说ResNet18 网络就是18层的吗?实则不然,其实这里的18指定的是带有权重的 18层,包括卷积层和全连接层,不包括池化层和BN层。
二、网络结构
本文主要基于caffe框架,解读Resnet-18网络结构~
1. 网络参数
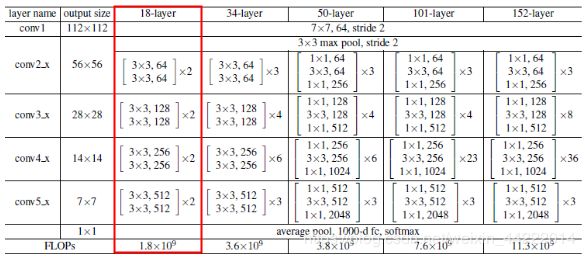
2. 网络图示
网络结构图,由caffe train.prototxt文件内容绘制:
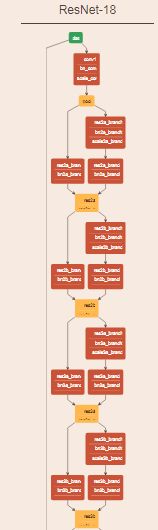
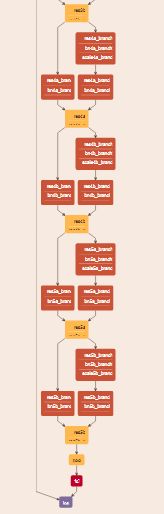
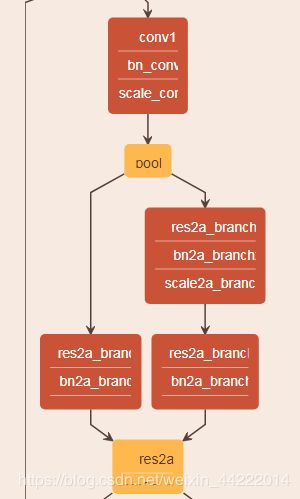
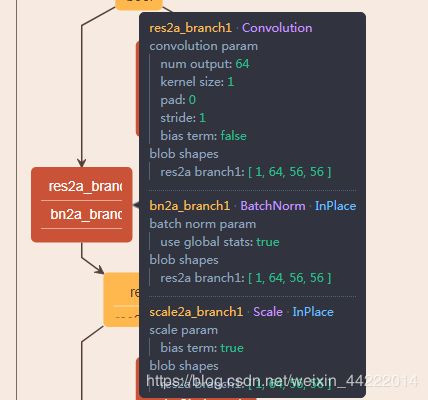
caffe train.prototxt文件内容:
name: "ResNet-18"
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 224
mean_file: "/home/vgenty/git/caffe/build/tools/ub_seven_class_train_mean.binary"
}
data_param {
source: "/home/vgenty/git/caffe/build/tools/ub_seven_class_train.db"
batch_size: 8
backend: LMDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 224
mean_file: "/home/vgenty/git/caffe/build/tools/ub_seven_class_valid_mean.binary"
}
data_param {
source: "/home/vgenty/git/caffe/build/tools/ub_seven_class_valid.db"
batch_size:8
backend: LMDB
}
}
layer {
bottom: "data"
top: "conv1"
name: "conv1"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 7
pad: 3
stride: 2
}
}
layer {
bottom: "conv1"
top: "conv1"
name: "bn_conv1"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "conv1"
top: "conv1"
name: "scale_conv1"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "conv1"
top: "conv1"
name: "conv1_relu"
type: "ReLU"
}
layer {
bottom: "conv1"
top: "pool1"
name: "pool1"
type: "Pooling"
pooling_param {
kernel_size: 3
stride: 2
pool: MAX
}
}
##########################
######first shortcut######
##########################
layer {
bottom: "pool1"
top: "res2a_branch1"
name: "res2a_branch1"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res2a_branch1"
top: "res2a_branch1"
name: "bn2a_branch1"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res2a_branch1"
top: "res2a_branch1"
name: "scale2a_branch1"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "pool1"
top: "res2a_branch2a"
name: "res2a_branch2a"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res2a_branch2a"
top: "res2a_branch2a"
name: "bn2a_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res2a_branch2a"
top: "res2a_branch2a"
name: "scale2a_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res2a_branch2a"
top: "res2a_branch2a"
name: "res2a_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res2a_branch2a"
top: "res2a_branch2b"
name: "res2a_branch2b"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res2a_branch2b"
top: "res2a_branch2b"
name: "bn2a_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res2a_branch2b"
top: "res2a_branch2b"
name: "scale2a_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res2a_branch1"
bottom: "res2a_branch2b"
top: "res2a"
name: "res2a"
type: "Eltwise"
}
layer {
bottom: "res2a"
top: "res2a"
name: "res2a_relu"
type: "ReLU"
}
##########################
######first-2 shortcut####
##########################
layer {
bottom: "res2a"
top: "res2b_branch1"
name: "res2b_branch1"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res2b_branch1"
top: "res2b_branch1"
name: "bn2b_branch1"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res2b_branch1"
top: "res2b_branch1"
name: "scale2b_branch1"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res2a"
top: "res2b_branch2a"
name: "res2b_branch2a"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res2b_branch2a"
top: "res2b_branch2a"
name: "bn2b_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res2b_branch2a"
top: "res2b_branch2a"
name: "scale2b_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res2b_branch2a"
top: "res2b_branch2a"
name: "res2b_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res2b_branch2a"
top: "res2b_branch2b"
name: "res2b_branch2b"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res2b_branch2b"
top: "res2b_branch2b"
name: "bn2b_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res2b_branch2b"
top: "res2b_branch2b"
name: "scale2b_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res2b_branch1"
bottom: "res2b_branch2b"
top: "res2b"
name: "res2b"
type: "Eltwise"
}
layer {
bottom: "res2b"
top: "res2b"
name: "res2b_relu"
type: "ReLU"
}
##########################
######second shortcut#####
##########################
layer {
bottom: "res2b"
top: "res3a_branch1"
name: "res3a_branch1"
type: "Convolution"
convolution_param {
num_output: 128
kernel_size: 1
pad: 0
stride: 2
bias_term: false
}
}
layer {
bottom: "res3a_branch1"
top: "res3a_branch1"
name: "bn3a_branch1"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res3a_branch1"
top: "res3a_branch1"
name: "scale3a_branch1"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res2b"
top: "res3a_branch2a"
name: "res3a_branch2a"
type: "Convolution"
convolution_param {
num_output: 128
kernel_size: 3
pad: 1
stride: 2
bias_term: false
}
}
layer {
bottom: "res3a_branch2a"
top: "res3a_branch2a"
name: "bn3a_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res3a_branch2a"
top: "res3a_branch2a"
name: "scale3a_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res3a_branch2a"
top: "res3a_branch2a"
name: "res3a_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res3a_branch2a"
top: "res3a_branch2b"
name: "res3a_branch2b"
type: "Convolution"
convolution_param {
num_output: 128
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res3a_branch2b"
top: "res3a_branch2b"
name: "bn3a_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res3a_branch2b"
top: "res3a_branch2b"
name: "scale3a_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res3a_branch1"
bottom: "res3a_branch2b"
top: "res3a"
name: "res3a"
type: "Eltwise"
}
layer {
bottom: "res3a"
top: "res3a"
name: "res3a_relu"
type: "ReLU"
}
##########################
######second-2 shortcut#####
##########################
layer {
bottom: "res3a"
top: "res3b_branch1"
name: "res3b_branch1"
type: "Convolution"
convolution_param {
num_output: 128
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res3b_branch1"
top: "res3b_branch1"
name: "bn3b_branch1"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res3b_branch1"
top: "res3b_branch1"
name: "scale3b_branch1"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res3a"
top: "res3b_branch2a"
name: "res3b_branch2a"
type: "Convolution"
convolution_param {
num_output: 128
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res3b_branch2a"
top: "res3b_branch2a"
name: "bn3b_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res3b_branch2a"
top: "res3b_branch2a"
name: "scale3b_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res3b_branch2a"
top: "res3b_branch2a"
name: "res3b_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res3b_branch2a"
top: "res3b_branch2b"
name: "res3b_branch2b"
type: "Convolution"
convolution_param {
num_output: 128
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res3b_branch2b"
top: "res3b_branch2b"
name: "bn3b_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res3b_branch2b"
top: "res3b_branch2b"
name: "scale3b_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res3b_branch1"
bottom: "res3b_branch2b"
top: "res3b"
name: "res3b"
type: "Eltwise"
}
layer {
bottom: "res3b"
top: "res3b"
name: "res3b_relu"
type: "ReLU"
}
##########################
######third shortcut#####
##########################
layer {
bottom: "res3b"
top: "res4a_branch1"
name: "res4a_branch1"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 1
pad: 0
stride: 2
bias_term: false
}
}
layer {
bottom: "res4a_branch1"
top: "res4a_branch1"
name: "bn4a_branch1"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res4a_branch1"
top: "res4a_branch1"
name: "scale4a_branch1"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res3b"
top: "res4a_branch2a"
name: "res4a_branch2a"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 3
pad: 1
stride: 2
bias_term: false
}
}
layer {
bottom: "res4a_branch2a"
top: "res4a_branch2a"
name: "bn4a_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res4a_branch2a"
top: "res4a_branch2a"
name: "scale4a_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res4a_branch2a"
top: "res4a_branch2a"
name: "res4a_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res4a_branch2a"
top: "res4a_branch2b"
name: "res4a_branch2b"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res4a_branch2b"
top: "res4a_branch2b"
name: "bn4a_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res4a_branch2b"
top: "res4a_branch2b"
name: "scale4a_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res4a_branch1"
bottom: "res4a_branch2b"
top: "res4a"
name: "res4a"
type: "Eltwise"
}
layer {
bottom: "res4a"
top: "res4a"
name: "res4a_relu"
type: "ReLU"
}
###########################
######third-2 shortcut#####
##########################
layer {
bottom: "res4a"
top: "res4b_branch1"
name: "res4b_branch1"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res4b_branch1"
top: "res4b_branch1"
name: "bn4b_branch1"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res4b_branch1"
top: "res4b_branch1"
name: "scale4b_branch1"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res4a"
top: "res4b_branch2a"
name: "res4b_branch2a"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res4b_branch2a"
top: "res4b_branch2a"
name: "bn4b_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res4b_branch2a"
top: "res4b_branch2a"
name: "scale4b_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res4b_branch2a"
top: "res4b_branch2a"
name: "res4b_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res4b_branch2a"
top: "res4b_branch2b"
name: "res4b_branch2b"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res4b_branch2b"
top: "res4b_branch2b"
name: "bn4b_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res4b_branch2b"
top: "res4b_branch2b"
name: "scale4b_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res4b_branch1"
bottom: "res4b_branch2b"
top: "res4b"
name: "res4b"
type: "Eltwise"
}
layer {
bottom: "res4b"
top: "res4b"
name: "res4b_relu"
type: "ReLU"
}
##########################
######forth shortcut#####
##########################
layer {
bottom: "res4b"
top: "res5a_branch1"
name: "res5a_branch1"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 1
pad: 0
stride: 2
bias_term: false
}
}
layer {
bottom: "res5a_branch1"
top: "res5a_branch1"
name: "bn5a_branch1"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res5a_branch1"
top: "res5a_branch1"
name: "scale5a_branch1"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res4b"
top: "res5a_branch2a"
name: "res5a_branch2a"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 3
pad: 1
stride: 2
bias_term: false
}
}
layer {
bottom: "res5a_branch2a"
top: "res5a_branch2a"
name: "bn5a_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res5a_branch2a"
top: "res5a_branch2a"
name: "scale5a_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res5a_branch2a"
top: "res5a_branch2a"
name: "res5a_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res5a_branch2a"
top: "res5a_branch2b"
name: "res5a_branch2b"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res5a_branch2b"
top: "res5a_branch2b"
name: "bn5a_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res5a_branch2b"
top: "res5a_branch2b"
name: "scale5a_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res5a_branch1"
bottom: "res5a_branch2b"
top: "res5a"
name: "res5a"
type: "Eltwise"
}
layer {
bottom: "res5a"
top: "res5a"
name: "res5a_relu"
type: "ReLU"
}
##########################
######forth-2 shortcut#####
##########################
layer {
bottom: "res5a"
top: "res5b_branch1"
name: "res5b_branch1"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res5b_branch1"
top: "res5b_branch1"
name: "bn5b_branch1"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res5b_branch1"
top: "res5b_branch1"
name: "scale5b_branch1"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res5a"
top: "res5b_branch2a"
name: "res5b_branch2a"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res5b_branch2a"
top: "res5b_branch2a"
name: "bn5b_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res5b_branch2a"
top: "res5b_branch2a"
name: "scale5b_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res5b_branch2a"
top: "res5b_branch2a"
name: "res5b_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res5b_branch2a"
top: "res5b_branch2b"
name: "res5b_branch2b"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res5b_branch2b"
top: "res5b_branch2b"
name: "bn5b_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res5b_branch2b"
top: "res5b_branch2b"
name: "scale5b_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res5b_branch1"
bottom: "res5b_branch2b"
top: "res5b"
name: "res5b"
type: "Eltwise"
}
layer {
bottom: "res5b"
top: "res5b"
name: "res5b_relu"
type: "ReLU"
}
layer {
bottom: "res5b"
top: "pool5"
name: "pool5"
type: "Pooling"
pooling_param {
kernel_size: 7
stride: 1
pool: AVE
}
}
layer {
bottom: "pool5"
top: "fc7"
name: "fc7"
type: "InnerProduct"
inner_product_param {
num_output: 7
}
}
#layer {
# bottom: "fc7"
# top: "prob"
# name: "prob"
# type: "Softmax"
# }
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "fc7"
bottom: "label"
top: "loss"
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "fc7"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
详细参数设置,可查看以上文件内容定义。
三、总结
ResNet及其变体网路系列,对于一般的图像识别任务表现优异,具体场景的算法应用,可以结合实际情况,进行具体网络结构改进,如网路裁剪,网络加深或其它策略,可以进行实践改进。
码字不易,如有不对,欢迎留言交流~
您的支持,是我不断创作的最大动力~
欢迎点赞,关注,留言交流~
深度学习,乐此不疲~
个人微信公众号,欢迎关注~
