深度学习基础之-4.2非线性回归-单入单出双层神经网络回归/拟合实例全过程
提出问题
目的:验证前馈神经网络的万能近似定理。
神经网络的万能近似定理:一个前馈神经网络如果具有线性层和至少一层具有"挤压"性质的激活函数(如signmoid等),给定网络足够数量的隐藏单元,它可以以任意精度来近似任何从一个有限维空间到另一个有限维空间的borel可测函数。
要相符上面的定理,也就是想拟合任意函数,一个必须点是“要有带有“挤压”性质的激活函数”。这里的“挤压”性质是因为早期对神经网络的研究用的是sigmoid类函数,所以对其数学性质的研究也主要基于这一类性质:将输入数值范围挤压到一定的输出数值范围。(后来发现,其他性质的激活函数也可以使得网络具有普适近似器的性质,如ReLU 。
问题:给出如下一批训练数据,如何使用神经网络方法来拟合这条曲线?
| 样本 | 1 | 2 | 3 | … | 1000 |
|---|---|---|---|---|---|
| 特征X | 0.606 | 0.129 | 0.643 | … | 0.199 |
| 标签Y | -0.113 | -0.269 | -0.217 | … | -0.281 |
训练数据:
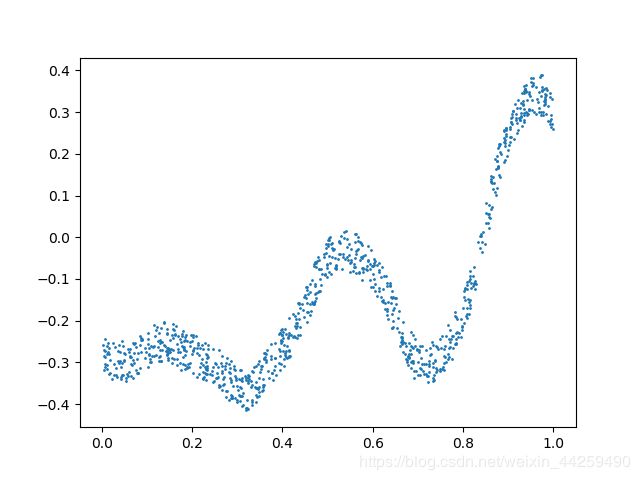
y = 0.4 x 2 + 0.3 x s i n ( 15 x ) + 0.01 c o s ( 50 x ) − 0.3 y=0.4x^2 + 0.3xsin(15x) + 0.01cos(50x)-0.3 y=0.4x2+0.3xsin(15x)+0.01cos(50x)−0.3
我们特意把数据限制在[0,1]之间,避免做归一化的麻烦。
1.前向计算
Z 1 = W 1 ⋅ X + B 1 Z1=W1 \cdot X+B1 Z1=W1⋅X+B1
A 1 = S i g m o i d ( Z 1 ) A1=Sigmoid(Z1) A1=Sigmoid(Z1)
Z 2 = W 2 ⋅ A 1 + B 2 Z2=W2 \cdot A1+B2 Z2=W2⋅A1+B2
(没有激活函数) A 2 = I d e n t i t y ( Z 2 ) A2=Identity(Z2) \tag{没有激活函数} A2=Identity(Z2)(没有激活函数)
以及均方差损失函数:
J ( w , b ) = 1 2 m ∑ i = 1 m ( z i − y i ) 2 J(w,b) = \frac{1}{2m}\sum^m_{i=1}(z_i-y_i)^2 J(w,b)=2m1i=1∑m(zi−yi)2
前向计算图:

1)为什么要用两层神经网络?
首先,一层神经网络肯定不能完成这个复杂函数的拟合过程。**因为一层神经网络,只能完成线性任务。**这里的“线性任务”的定义,从简单到复杂,列表如下:
| 名称 | 形式 | 能力 |
|---|---|---|
| 单变量线性回归 | y = w 0 + w 1 ⋅ x y=w_0+w_1·x y=w0+w1⋅x | 拟合二维平面直线 |
| 多变量线性回归 | y = w 0 + w 1 ⋅ x 1 + w 2 ⋅ x 2 . . . y=w_0+w_1·x_1+w_2·x_2... y=w0+w1⋅x1+w2⋅x2... | 拟多高维空间直线或平面 |
| 高阶线性回归 | y = w 0 + w 1 ⋅ x 1 + w 2 ⋅ x 1 2 . . . y=w_0+w_1·x_1+w_2·x^2_1... y=w0+w1⋅x1+w2⋅x12... | 拟合二维平面高阶曲线 |
| 多变量高阶线性回归 | y = w 0 + w 1 ⋅ x 1 + w 2 ⋅ x 2 + w 3 ⋅ x 1 2 + w 4 ⋅ x 2 2 . . . y=w_0+w_1·x_1+w_2·x_2+w_3·x^2_1+w_4·x^2_2... y=w0+w1⋅x1+w2⋅x2+w3⋅x12+w4⋅x22... | 拟合多维空间高阶曲线或曲面 |
所谓的“高阶”,指的是特征变量其实只有一个x1,但是把x1的平方也算作第二个特征向量。比如一栋房子的长度x1,宽度x2,占地面积x3=x1*x2。这里的x3并不是独立存在的,真正的自变量只有x1和x2。
这些高次线性回归问题,可以用单层的神经网络来解决,但是是有前提条件的,即假设函数必须和实际问题吻合。满足这个条件的实际工程问题并不多见,并且这种情况完全可以用两层的神经网络来解决,所以我们没有在单层的神经网络中涉及这个问题。
2)为什么在输出层没有用到激活函数?
神经网络不管有多少层,最后的输出层决定了这个神经网络能干什么。在单层神经网络中,我们学习到了以下示例:
| 网络 | 输入 | 输出 | 激活函数 | 功能 |
|---|---|---|---|---|
| 单层 | 单变量 | 单输出 | 无 | 二维线性回归/拟合 |
| 单层 | 多变量 | 单输出 | 无 | 多维线性回归/拟合 |
| 单层 | 多变量 | 单输出 | 二分类函数 | 二分类 |
| 单层 | 多变量 | 多输出 | 多分类函数 | 多分类 |
对于多层神经网络也是如此,我们要完成拟合任务,而不是分类,所以用不到激活/分类函数。通常把激活函数和分类函数混淆在一起说,如果明确地区分二者,则可以这样说:神经网络的最后一层不用激活函数,只可能用到分类函数。Sigmoid既是激活函数,又是分类函数,是个特例。
神经网络的拟合原理是这样的:在第一层神经网络,通过 W 1 ∗ X + B 1 W1*X+B1 W1∗X+B1的计算做线性变化,把非线性问题转换成线性问题;在第二层神经网络做线性回归。所以在第二层是不需要激活函数的,否则就没法画出一条直线来。这个可以想象两个独立的神经网络,第一个网络已经把数据处理成线性的了,以便让我们使用上一章的方法,做一次线性回归就好了。
简言之:
- 神经网络最后一层不需要激活函数
- 激活函数只用于连接前后两层神经网络 (非常重要)
2.1)对激活函数在多层神经网络中做线性分类或回归的进一步解释:
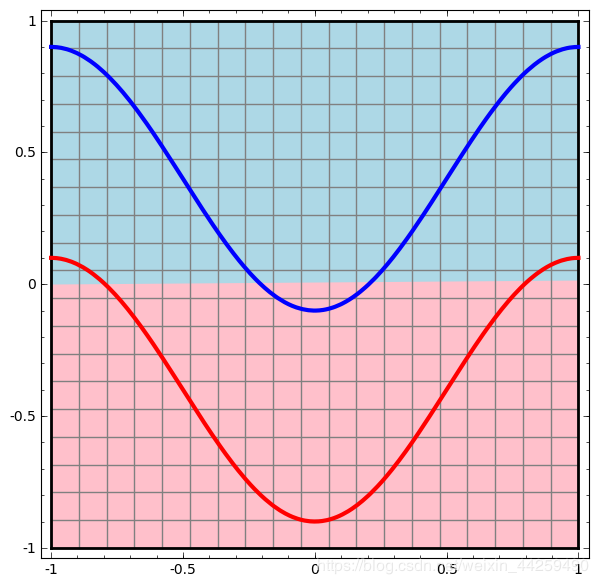
在两层神经网络的输出层,可以用和单层神经网络一样的结构来完成分类任务,而用隐层来完成非线性到线性的转换工作。我们可以通过以下几张图的比较来理解一下非线性到线性的转换。
假设有两组点组成的红蓝两色曲线如下图:

我们如何用神经网络画一条直线或者曲线来把红蓝两线分开呢?
| 一层的神经网络 | 两层神经网络 |
|---|---|
 |
 |
为什两层神经网络可以做到这样呢?第二层也是一个线性的变化,关键在于第一层添加了激活函数之后,做到了坐标转换和空间扭曲:(第一层计算,把坐标空间扭曲,然后第二层神经网络轻松地画了一条直线,就把二者完美分开了)

3)为什么用均方差而不是交叉熵损失函数?
我们把上面的表格拿来再扩充一下:
| 网络 | 输入 | 输出 | 激活函数 | 损失函数 | 功能 |
|---|---|---|---|---|---|
| 单层 | 单变量 | 单输出 | 无 | 均方差 | 二维线性回归/拟合 |
| 单层 | 多变量 | 单输出 | 无 | 均方差 | 多维线性回归/拟合 |
| 单层 | 多变量 | 单输出 | 二分类函数 | 交叉熵 | 二分类 |
| 单层 | 多变量 | 多输出 | 多分类函数 | 交叉熵 | 多分类 |
交叉熵函数是用于分类的,均方差函数是用于拟合的,可以理解为计算拟合的点和样本标签点的距离之平方和。
拟合/回归的目的是减少预测值和样本标签值之间的差距,差距通过均方差的欧氏距离来表示。
在多层神经网络模型中,不论是回归/拟合问题还是分类问题,最后一层均不需要激活函数,需要激活函数的都是前面几层,最后一层如果做分类,则会添加分类函数如sigmoid/softmax,如果是拟合/回归问题则什么都不需要添加(个人见解,如有不妥,敬请指正)
2.反向传播
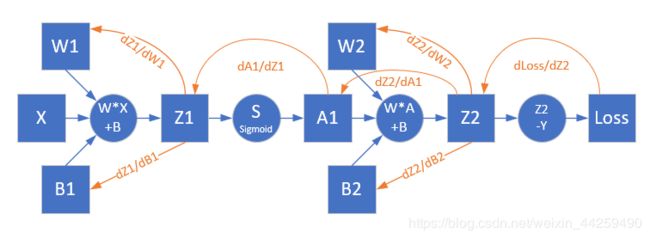
梯度生成
对损失函数求导,可以得到损失函数对输出层的梯度值,即上图中的Z2部分。
因为:
J ( w , b ) = 1 2 m ∑ ( z i − y i ) 2 J(w,b) = \frac{1}{2m} \sum (z_i-y_i)^2 J(w,b)=2m1∑(zi−yi)2
∂ J ∂ z i = 1 2 m ∑ ∂ ( z i − y i ) 2 ∂ z i = 1 m ∑ ( z i − y i ) {\partial{J} \over \partial{z_i}}=\frac{1}{2m} \sum {\partial{(z_i-y_i)^2} \over \partial{z_i}}=\frac{1}{m} \sum (z_i-y_i) ∂zi∂J=2m1∑∂zi∂(zi−yi)2=m1∑(zi−yi)
用于矩阵运算,可以简写为:
(1) d Z 2 = ∂ J ∂ Z 2 = Z 2 − Y dZ2 = \frac{\partial{J}}{\partial{Z2}} = Z2-Y \tag{1} dZ2=∂Z2∂J=Z2−Y(1)
求W2的梯度
Z 2 = W 2 ⋅ A 1 + B 2 Z2 = W2 \cdot A1+B2 Z2=W2⋅A1+B2
∂ Z 2 ∂ W 2 = ∂ ( W 2 ⋅ A 1 + B 2 ) ∂ W 2 {\partial{Z2} \over \partial{W2}}=\frac{\partial{(W2 \cdot A1+B2)}}{\partial{W2}} ∂W2∂Z2=∂W2∂(W2⋅A1+B2)
= ∂ ( W 2 ⋅ A 1 ) ∂ W 2 + ∂ ( B 2 ) ∂ W 2 =\frac{\partial{(W2 \cdot A1)}}{\partial{W2}}+\frac{\partial{(B2)}}{\partial{W2}} =∂W2∂(W2⋅A1)+∂W2∂(B2)
= A 1 T + 0 = A 1 T =A1^T+0=A1^T =A1T+0=A1T
结合损失函数对Z2的偏导结果,使用链式法则:
d W 2 = ∂ J ∂ W 2 = ∂ J ∂ Z 2 ⋅ ∂ Z 2 ∂ W 2 dW2 = \frac{\partial{J}}{\partial{W2}} = \frac{\partial{J}}{\partial{Z2}} \cdot \frac{\partial{Z2}}{\partial{W2}} dW2=∂W2∂J=∂Z2∂J⋅∂W2∂Z2 (2) = ( Z 2 − Y ) A 1 T =(Z2-Y)A1^T \tag{2} =(Z2−Y)A1T(2)
求B2的梯度
d B 2 = ∂ J ∂ B 2 = ∂ J ∂ Z 2 ⋅ ∂ Z 2 ∂ B 2 dB2 = \frac{\partial{J}}{\partial{B2}} = \frac{\partial{J}}{\partial{Z2}} \cdot \frac{\partial{Z2}}{\partial{B2}} dB2=∂B2∂J=∂Z2∂J⋅∂B2∂Z2
(3) = ( Z 2 − Y ) ⋅ 1 = Z 2 − Y =(Z2-Y) \cdot 1=Z2-Y \tag{3} =(Z2−Y)⋅1=Z2−Y(3)
求损失函数对隐层的梯度
对于深度神经网络,需要把梯度从最后一层逐层向前传递,经过激活函数的导数,直接达到线性计算部分,即下图中的Z1部分:
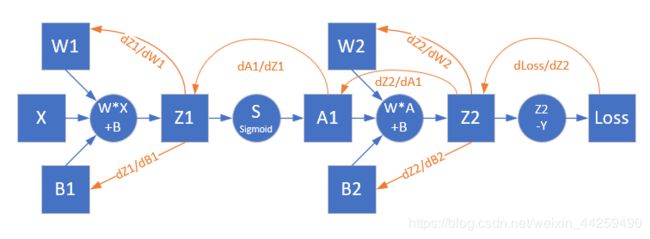
链式求导公式如下:
∂ J ∂ Z 1 = ∂ J ∂ Z 2 ⋅ ∂ Z 2 ∂ A 1 ⋅ ∂ A 1 ∂ Z 1 \frac{\partial{J}}{\partial{Z1}} = \frac{\partial{J}}{\partial{Z2}} \cdot \frac{\partial{Z2}}{\partial{A1}} \cdot \frac{\partial{A1}}{\partial{Z1}} ∂Z1∂J=∂Z2∂J⋅∂A1∂Z2⋅∂Z1∂A1
公式(1)已经有了第一项的结果,现在来解决后面两项:
∂ Z 2 ∂ A 1 = ∂ ( W 2 ⋅ A 1 + B 2 ) ∂ A 1 = W 2 T \frac{\partial{Z2}}{\partial{A1}} = \frac{\partial{(W2 \cdot A1 + B2)}}{\partial{A1}}=W2^T ∂A1∂Z2=∂A1∂(W2⋅A1+B2)=W2T
∂ A 1 ∂ Z 1 = ∂ ( S i g m o i d ( Z 1 ) ) ∂ Z 1 = A 1 ⊙ ( 1 − A 1 ) \frac{\partial{A1}}{\partial{Z1}}=\frac{\partial{(Sigmoid(Z1))}}{\partial{Z1}}=A1 \odot (1-A1) ∂Z1∂A1=∂Z1∂(Sigmoid(Z1))=A1⊙(1−A1)
所以:
d Z 1 = ∂ J ∂ Z 1 = ∂ J ∂ Z 2 ⋅ ∂ Z 2 ∂ A 1 ⋅ ∂ A 1 ∂ Z 1 dZ1=\frac{\partial{J}}{\partial{Z1}} = \frac{\partial{J}}{\partial{Z2}} \cdot \frac{\partial{Z2}}{\partial{A1}} \cdot \frac{\partial{A1}}{\partial{Z1}} dZ1=∂Z1∂J=∂Z2∂J⋅∂A1∂Z2⋅∂Z1∂A1 (4) = W 2 T × d Z 2 ⊙ A 1 ⊙ ( 1 − A 1 ) =W2^T \times dZ2 \odot A1 \odot (1-A1) \tag{4} =W2T×dZ2⊙A1⊙(1−A1)(4)
求W1的梯度
∂ Z 1 ∂ W 1 = ∂ ( W 1 ⋅ X + B 1 ) ∂ W 1 = X T \frac{\partial{Z1}}{\partial{W1}} = \frac{\partial{(W1 \cdot X+B1)}}{\partial{W1}} = X^T ∂W1∂Z1=∂W1∂(W1⋅X+B1)=XT
(5) d W 1 = ∂ J ∂ W 1 = ∂ J ∂ Z 1 ∂ Z 1 ∂ W 1 = d Z 1 × X T dW1=\frac{\partial{J}}{\partial{W1}} = \frac{\partial{J}}{\partial{Z1}} \frac{\partial{Z1}}{\partial{W1}}= dZ1 \times X^T \tag{5} dW1=∂W1∂J=∂Z1∂J∂W1∂Z1=dZ1×XT(5)
求B1的梯度
∂ Z 1 ∂ B 1 = ∂ ( W 1 ⋅ X + B 1 ) ∂ B 1 = 1 \frac{\partial{Z1}}{\partial{B1}} = \frac{\partial{(W1 \cdot X+B1)}}{\partial{B1}} = 1 ∂B1∂Z1=∂B1∂(W1⋅X+B1)=1
(6) d B 1 = ∂ J ∂ B 1 = ∂ J ∂ Z 1 ∂ Z 1 ∂ B 1 = d Z 1 dB1=\frac{\partial{J}}{\partial{B1}} = \frac{\partial{J}}{\partial{Z1}} \frac{\partial{Z1}}{\partial{B1}}= dZ1 \tag{6} dB1=∂B1∂J=∂Z1∂J∂B1∂Z1=dZ1(6)
用于拟合的双层神经网络的实现
观察样本:
| 样本 | 1 | 2 | 3 | … | 1000 |
|---|---|---|---|---|---|
| 特征X | 0.606 | 0.129 | 0.643 | … | 0.199 |
| 标签Y | -0.113 | -0.269 | -0.217 | … | -0.281 |
首先观察一下样本数据的范围,x是在[0,1],y是[-0.5,0.5],这样我们就不用做数据归一化了。这条线看起来像一条处于攻击状态的眼镜蛇!
定义神经网络结构
我们定义一个两层的神经网络,输入层不算,一个隐藏层,含4个神经元,一个输出层。
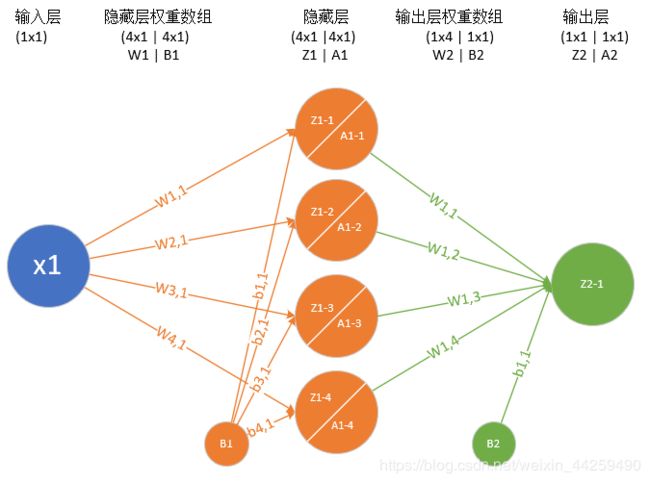
输入层
输入层就是一个标量x值。
权重矩阵W1/B1
W 1 = ( w 1 , 1 w 2 , 1 w 3 , 1 w 4 , 1 ) W1= \begin{pmatrix} w_{1,1} \ w_{2,1} \ w_{3,1} \ w_{4,1} \ \end{pmatrix} W1=(w1,1 w2,1 w3,1 w4,1 )
其实这里的B1所在的圆圈里应该是个常数1,而B1连接到Z1-1…Z1-4的权重线B1-1…B1-4应该是个浮点数。我们为了说明问题方便,就写了个B1,而实际的B1是指B1-1…B1-4的矩阵/向量。
B 1 = ( b 1 , 1 b 2 , 1 b 3 , 1 b 4 , 1 ) B1= \begin{pmatrix} b_{1,1} \ b_{2,1} \ b_{3,1} \ b_{4,1} \ \end{pmatrix} B1=(b1,1 b2,1 b3,1 b4,1 )
隐藏层
我们用一个4个神经元的网络来模拟函数,每个神经元的输入 Z 1 = W 1 ⋅ X + B 1 Z1 = W1 \cdot X + B1 Z1=W1⋅X+B1,我们在这里使用sigmoid函数,所以输出是 A 1 = S i g m o i d ( Z 1 ) A1 = Sigmoid(Z1) A1=Sigmoid(Z1)。
Z 1 = ( z 1 , 1 z 2 , 1 z 3 , 1 z 4 , 1 ) , A 1 = ( a 1 , 1 a 2 , 1 a 3 , 1 a 4 , 1 ) Z1 = \begin{pmatrix} z_{1,1} \ z_{2,1} \ z_{3,1} \ z_{4,1} \end{pmatrix}, A1 = \begin{pmatrix} a_{1,1} \ a_{2,1} \ a_{3,1} \ a_{4,1} \end{pmatrix} Z1=(z1,1 z2,1 z3,1 z4,1),A1=(a1,1 a2,1 a3,1 a4,1)
权重矩阵W2/B2
W2的尺寸是1x4,B2的尺寸是1x1。 W 2 = ( w 1 , 1 w 1 , 2 w 1 , 3 w 1 , 4 ) W2= \begin{pmatrix}w_{1,1} & w_{1,2} & w_{1,3} & w_{1,4} \end{pmatrix} W2=(w1,1w1,2w1,3w1,4)
B 2 = ( b 1 , 1 ) B2= \begin{pmatrix} b_{1,1} \end{pmatrix} B2=(b1,1)
输出层
由于我们只想完成一个拟合任务,所以输出层只有一个神经元, Z 2 = W 2 ⋅ A 1 + B 2 Z2=W2 \cdot A1+B2 Z2=W2⋅A1+B2。
前向计算图
刚开始学习神经网络时,总没有矩阵尺寸的概念,所以建议大家用下图的方式来加强一下认识,其中矩形的宽和高象征性地表示了这个矩阵的形状。

至此,我们得到了以下一串公式:
Z 1 = W 1 ⋅ X + B 1 Z1=W1 \cdot X+B1 Z1=W1⋅X+B1
A 1 = S i g m o i d ( Z 1 ) A1=Sigmoid(Z1) A1=Sigmoid(Z1)
Z 2 = W 2 ⋅ A 1 + B 2 Z2=W2 \cdot A1+B2 Z2=W2⋅A1+B2
(这一步可以省略) A 2 = I d e n t i t y ( Z 2 ) A2=Identity(Z2) \tag{这一步可以省略} A2=Identity(Z2)(这一步可以省略)
代码结构

四个底层模块
- Data Reader 读取数据,处理数据
- Activations 激活函数库,包括正向和反向
- Loss Function
损失函数库,损失值历史记录
WeightsBias 权重参数,初始化,更新
双层网络主模块
流程说明:
def train(self, dataReader, params, loss_history):
# 初始化权重参数
wb1 = WeightsBias(params.num_input, params.num_hidden, params.eta)
wb1.InitializeWeights()
wb2 = WeightsBias(params.num_hidden, params.num_output, params.eta)
wb2.InitializeWeights()
# 初始化损失值记录器
loss = 0
lossFunc = CLossFunction(params.loss_func_name)
# 计算批大小和内循环次数
max_iteration = (int)(dataReader.num_example / params.batch_size)
# 外循环,控制epoch次数
for epoch in range(params.max_epoch):
# 每个epoch都要打乱数据顺序
#dataReader.Shuffle()
# 控制内循环次数
for iteration in range(max_iteration):
# 获得当前批次的样本数据和标签
batch_x, batch_y = dataReader.GetBatchSamples(params.batch_size,iteration)
# 前向计算
dict_cache = self.ForwardCalculationBatch(batch_x, wb1, wb2)
# 反向计算梯度
self.BackPropagationBatch(batch_x, batch_y, dict_cache, wb1, wb2)
# 更新权重数组
self.UpdateWeights(wb1, wb2)
# end for
# 计算全批量损失值并记录
output = self.ForwardCalculationBatch(dataReader.X, wb1, wb2)
loss = lossFunc.CheckLoss(dataReader.Y, output["Output"])
print("epoch=%d, loss=%f" %(epoch,loss))
loss_history.AddLossHistory(loss, epoch, iteration, wb1, wb2)
# 检查停止条件
if loss < params.eps:
break
# end if
# end for
# 返回训练好的权重值
return wb1, wb2
# end def
运行结果
| 损失函数值 | 拟合结果 |
|---|---|
 |
 |
参数调优
可调的参数
| 参数 | 缺省值 | 是否可调 | 注释 |
|---|---|---|---|
| 输入层神经元数 | 1 | No | |
| 隐层神经元数 | 4 | Yes | 影响迭代次数 |
| 输出层神经元数 | 1 | No | |
| 学习率 | 0.1 | Yes | 影响迭代次数 |
| 批样本量 | 10 | Yes | 影响迭代次数 |
| 最大epoch | 30000 | Yes | 影响终止条件,建议不改动 |
| 损失门限值 | 0.001 | Yes | 影响终止条件,建议不改动 |
| 损失函数 | MSE | No | |
| 参数初始化方法 | Xavier | Yes | 下一章提到 |
初始化
初始化是神经网络训练非常重要的环节之一,不同的初始化方法,甚至是相同的方法但不同的随机值,都会给结果带来或多或少的影响。
在后面的几组比较中,都是用Xavier方法初始化的。另外,两次使用Xavier初始化,也会得到不同的结果,为了避免这个随机性,我们在代码Level0_TwoLayerFittingNet.py中,使用了一个小技巧,调用下面这个函数:
def InitializeWeights(self, create_new = False):
self.__GenerateWeightsArrayFileName()
if create_new:
self.__CreateNew()
else:
self.__LoadExistingParameters()
# end if
self.dW = np.zeros(self.W.shape)
self.dB = np.zeros(self.B.shape)
第一次调用时,会得到一个随机初始化矩阵。以后再次调用时,如果参数值为False,只要隐层神经元数量不变并且初始化方法不变,就会用第一次的初始化结果,否则后面的各种参数调整的结果就没有可比性了(笔者不大清楚这是为什么)。
学习率调整
我们固定其它参数,改变学习率,下面是损失函数值的曲线:

| 学习率 | 迭代次数 | 说明 |
|---|---|---|
| 0.1 | 9540 | 学习率小,收敛最慢 |
| 0.3 | 4360 | 学习率增大,收敛增快 |
| 0.5 | 2780 | 最快 |
| 0.7 | 3040 | 学习率进一步增大,但收敛不一定快 |
对于拟合曲线这个特定问题,较大的学习率可以带来很快的收敛速度,但是有两点:
- 并不是对所有问题都这样,有的问题可能需要0.001或者更小的学习率
- 学习率大时,开始时收敛快,但是到了后来有可能会错失最佳解
批大小的调整
我们固定其它参数,调整批大小,比较结果如下:

| 批大小 | 迭代次数 | 说明 |
|---|---|---|
| 1 | 4680 | 批数据量小到1,收敛慢 |
| 5 | 2540 | 批数据量增大,收敛最快 |
| 10 | 2780 | 批数据量进一步增大,收敛变慢 |
| 20 | 4670 | 批数据量太大,反而会降低收敛速度 |
合适的批样本量会带来较快的收敛,前提是我们固定了学习率。如果想用较大的批数据,底层数据库计算的速度较快,但是需要同时调整学习率,才会相应地提高收敛速度。
这个结论的前提是我们用了0.5的学习率,如果用0.1的话,将会得到不同结论。
隐层神经元数量的调整
这次我们调整隐层神经元的数量:
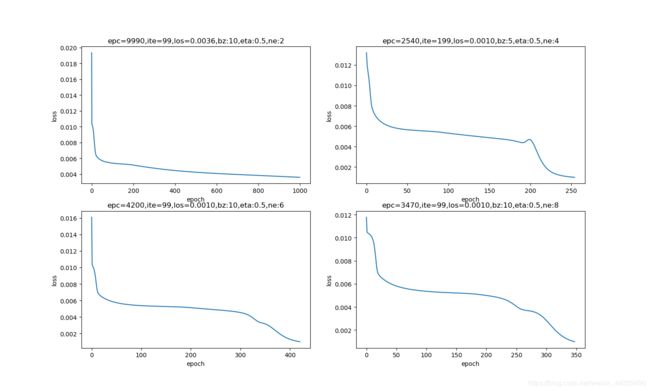
| 隐层神经元数量 | 迭代次数 | 说明 |
|---|---|---|
| 2 | 9990 | 神经元数量少,拟合能力低 |
| 4 | 2540 | 神经元数量对于这个问题最合适 |
| 6 | 4200 | 神经元多了不一定能帮上忙,还有可能帮倒忙 |
| 8 | 3470 | 再多一些神经元会有一些用处 |
https://github.com/microsoft/ai-edu/blob/master/B-教学案例与实践/B6-神经网络基本原理简明教程/09.3-参数调优.md
https://github.com/microsoft/ai-edu/blob/master/B-教学案例与实践/B6-神经网络基本原理简明教程/09.2-双层拟合网络的实现.md