Python实现机器学习
1. 机器学习基础知识
传统的数据分析旨在回答关于过去的事实,机器学习的目的是回答关于未来事件的可能性的问题。
- 基于过去的事实和数据,用来发现趋势和模式
- 机器学习模型提供了对于结果的洞察力,机器学习帮助揭示未来的一个结果的概率而不仅仅是过去发生的事情
- 历史的数据和统计建模被用于概率进行预测
1.1 机器学习的方式
-
有监督学习(分类、回归) 同时将数据样本和标签输入给模型,模型学习到数据和标签的映射关系,从而对新数据进行预测。

-
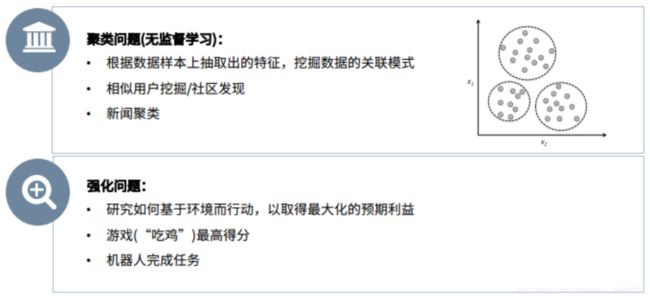
无监督学习(聚类) 只有数据,没有标签,模型通过总结规律,从数据中挖掘出信息。
-
强化学习 强化学习会在没有任何标签的情况下,通过先尝试做出一些行为得到一个结果,通过这个结果是对还是错的反馈,调整之前的行为,就这样不断的调整,算法能够学习到在什么样的情况下选择什么样的行为可以得到最好的结果。
1.2 机器学习的方法及流程
- 选择输入特征:基于什么进行预测?
- 确定目标:预测什么?
- 分析预测功能:回归、聚类、降维…
机器学习的流程如下图所示,包括将数据集随机按比例分割为训练数据集(train set)、验证数据集(validation set)和测试数据集(test set)。通过交叉验证(cross-validation)方法,即在多个训练数据集上训练模型,而且在多个验证集上验证该模型,从而得到多个模型;而后用判定条件选择折中的一个模型,该模型即为最终预测模型。最终模型应用于测试数据集上,该模型在从未遇到的测试数据集即可作为今后该模型可能会遇到的一部分样本,观察该模型真正的预测能力,即泛化能力。 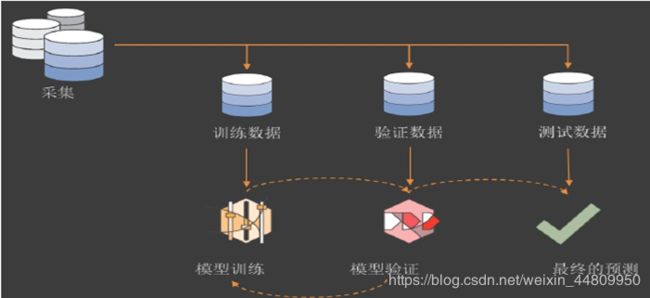
1.3 常见的机器学习算法
- 线性回归
- 逻辑回归
- 决策树
- SVM
- 朴素贝叶斯
- K最近邻算法
- K均值算法
- 随机森林算法
- 降维算法
- Gradient Boost 和 Adaboost 算法
2 机器学习前的准备工作
本文仍然以著名的鸢尾花iris数据为例展开机器学习的示例。在建立机器学习的模型前,通常需要对数据进行准备工作。对数据的准备工作包括但不限于:
- 数据基本情况分析
- 数据可视化
- 数据标准化
- 根据数据选择可能合适的模型
2.1 数据基本情况分析
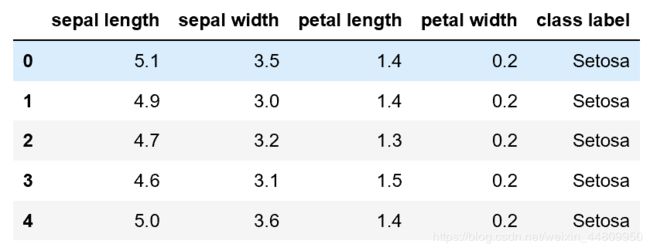
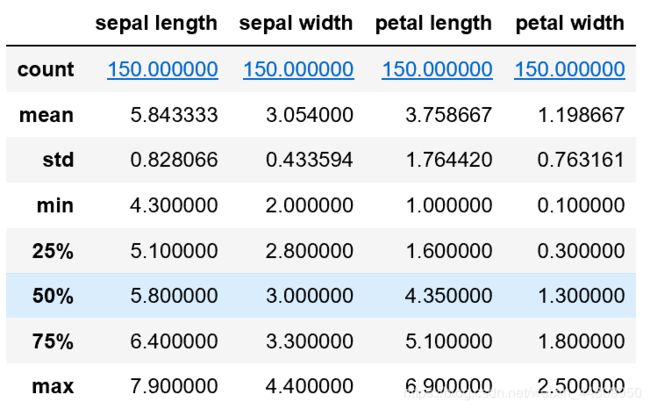
首先读入iris.csv文件中的数据并保存在DataFrame数据框中,然后我们可以通过DataFrame的shape属性查看读入数据的行数和列数;head()函数看一下数据前面几行;describe()函数查看每列的基本统计数据。
import pandas as pd
X=pd.read_csv("D:\\iris.csv")
X.shape
X.head()
X.describe()输出结果包括显示(150, 5),表示150行,5列数据;
数据前面几行的展示,可以看到每列的名称;
还可以看到对连续型数据的基本统计结果,包括每列中包含数据个数,平均值(mean)和方差(sd),最大值(max)和最小值(min)以及处于25%、50%和75%位置的数据。
2.2 数据可视化
这部分在另一个博文中做了简要介绍。请参看Python数据可视化-matplotlib and seaborn
2.3 数据的拆分
- 输入、输出数据拆分
- 训练集、测试集数据拆分
(1)要把读入的数据X分成输入数据和输出数据两个部分。后面的机器学习模型我们会分为分类输出的模型和连续型输出的模型两个类别介绍,因此,这里的输入输出分割也稍微有所不同。
如果我们把iris数据集中的"cllass label"拆分出来作为输出y,剩下的作为输入X,那么我们将建立的就是分类输出模型;
y=X.pop("class label")而如果我们把iris数据集中的"petal width" 拆分出来作为输出y,剩下的iris数据集中鸢尾花的3个参数作为输入X,那么我们将建立的就是连续型输出的模型。
X.pop("class label")
y=X.pop("petal width")(2)为了交叉验证算法的需要,对输入数据按比例随机拆分为训练集(train set)和测试集(test set)这两部分数据,相应的输出数据也会被拆分到训练集(train set)和测试集(test set)中。这里我们需要应用sklearn库model_selection的train_test_split函数完成。
需要非常注意的是,通过sklearn库中train_test_split函割获得的训练集(train set)实际是总训练集,已经包括了交叉验证(cross validation)中的训练集(train set)和验证集(validation set)两个部分。意思就是指在交叉验证过程中将总训练集(train set)数据集通常分成 10 部分,轮流将其中 9 份作为训练数据(train set),1份作为验证集(validation set)。训练10个模型并最后折中选择1个作为最终模型的过程。
在许多介绍性文章中,训练集、验证集和测试集概念经常混淆,要注意区分。
#from sklearn import cross_validation #老版本的sklearn
from sklearn import model_selection #新版本的sklearn
#拆分数据为train set训练集和test set测试集
#X:要划分的样本特征集(输入的信息)
#y:需要划分的样本结果(输出结果)
#test_size:样本占比,测试集在总数中的百分比(小数表示)
#random_state:随机数种子,对于模型分割,必须用同一随机数种子,保证每次随机分割后数据集不变。
x_train,x_test,y_train,y_test=model_selection.train_test_split(X,y,test_size=0.2,random_state=10)2.4 输入连续型数据的标准化
读入数据后对数据做标准化,标准化的意义在于使得数据为近似正态分布,这样符合后续多个模型的输入要求。这步如果本身数据分布较为符合正态分布时,可以不用操作。如果需要将输入的连续型数据标准化,那么应该在拆分训练集(train set)和测试集(test set)之前把输入数据统一进行标准化。
from sklearn import model_selection #新版本的sklearn
from sklearn.preprocessing import StandardScaler
#连续型拟合数据在机器学习前先进行标准化
ss = StandardScaler()
X = ss.fit_transform(X)
#拆分数据为train set训练集和test set测试集
#X:要划分的样本特征集(输入的信息)
#y:需要划分的样本结果(输出结果)
#test_size:样本占比,测试集在总数中的百分比(小数表示)
#random_state:随机数种子,对于模型分割,必须用同一随机数种子,保证每次随机分割后数据集不变。
x_train,x_test,y_train,y_test=model_selection.train_test_split(X,y,test_size=0.2,random_state=10)3 机器学习中的分类型输出模型
在python中,机器学习的算法都集合在sklearn中,不仅是算法,而且正如我们前面看到的,对数据的大量预处理方法也在sklearn库中。另外,后面我们也将看到,对模型预测能力的评价方法,也被包含在sklearn中。因此对于机器学习的应用来说,sklearn库是最重要的基础。
在建立模型之前,我们要根据我们前面分析的输入和输出情况,分析可以应用的适合的模型。比如,对于有监督的、输出是分类型(classified)数据而言,那么我们就可能会需要逻辑回归(Logistic Regression)、决策树(Decision Tree)、支持向量机(Support Vector Machine)等;而对于有监督的、输出是连续型(continued)数据而言,则可以选择线性回归(Linear Regression)、回归的决策树(Decision Tree Regression)、回归的支持向量机(Support Vector Machine Regression)等;而对于无监督的、输出是分类型的数据而言,K邻近算法(K-Nearest Neighbor)则是可选择的算法之一;当然面对数据量更大要求更高的场合,集成学习算法,例如AdaBoost,XGBoost则更为推荐。
3.1 逻辑回归模型
Logistic Regression和线性回归一样,是回归中常见的算法。很多人刚接触Logistic Regression,不知道回归的含义。其实在念中学的时候学到的用最小二乘法求解线性回归方程,就是我们最早接触到的回归。在二维平面上有很多的点
而逻辑回归则通过sigmoid函数将映射值限定在(0,1)。sigmoid函数如下图所示:
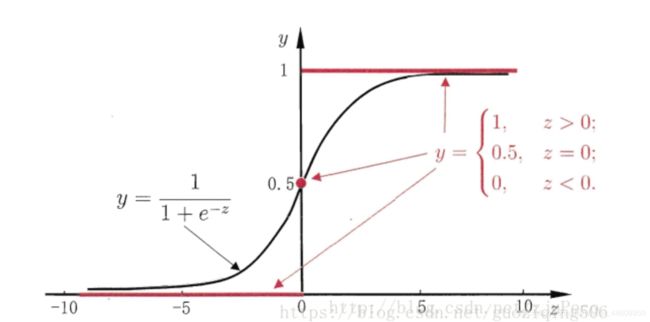
在本例中,我们的输入的X是iris鸢尾花的4个参数,输出的y是iris鸢尾花的细分类型,它不是0和1的二分类变量,而是一个多分类的变量。但是,应用逻辑回归模型的原理是类似的。在下面的程序段中,我们首先用LogisticRegression()函数建立了一个模型model;然后用前面随机拆分的x_train和它对应的输出y_train用fit函数训练了一个逻辑回归模型;获得的模型用x_test测试集输入后得到预测结果y_pred;另外我们还用score函数,不仅用x_test测试集输入得到预测结果,而且和真实的x_test测试集对应的y_test结果做比较,简单检查一下前面建立的逻辑回归模型的预测性能。
#from sklearn import cross_validation #老版本的sklearn
from sklearn import model_selection #新版本的sklearn
from sklearn.preprocessing import StandardScaler
#将数据分成输入的X矩阵和输出的一列y
#y是iris数据库中class label一列数据,分类变量,代表iris的三种子分类
y=X.pop("class label")
#拟合数据在机器学习前要先进行标准化
ss = StandardScaler()
X = ss.fit_transform(X)
#拆分数据为train set训练集和test set测试集
x_train,x_test,y_train,y_test=model_selection.train_test_split(X,y,test_size=0.2,random_state=1)
from sklearn.linear_model import LogisticRegression
model=LogisticRegression()
model.fit(x_train, y_train)
#输出预测结果
y_pred=model.predict(x_test)
#输出预测准确性
score=model.score(x_test, y_test)
print("1. 逻辑回归模型预测准确性:{:.2}".format(score))但是,我们可以从上述程序发现,这段程序里只建立了一个模型并进行了预测,并没有实现象前面介绍的机器学习中的交叉验证过程,即多次划分train set训练集和validation set验证集,由此建立多个模型并选择其中最均衡的模型作为机器学习的最终模型。在下面的程序段中,我们应用LogisticRegressionCV()函数,这个函数帮助我们实现了上述的机器学习过程中重要的交叉验证过程。并且我们还比较了默认参数和设置优化参数后得到的逻辑回归模型和预测结果。
from sklearn.linear_model import LogisticRegressionCV
model=LogisticRegressionCV()
model.fit(x_train, y_train)
y_pred=model.predict(x_test)
score=model.score(x_test, y_test)
print("2. 交叉验证后逻辑回归模型预测准确性:{:.2}".format(score))
model=LogisticRegressionCV(multi_class="multinomial",fit_intercept=True,cv=10,penalty="l2",solver="lbfgs",tol=0.01)
model.fit(x_train, y_train)
y_pred=model.predict(x_test)
score=model.score(x_test, y_test)
print("3. 交叉验证并参数优化后逻辑回归模型预测准确性:{:.2}".format(score))以上三个逻辑回归模型对test set测试集进行预测,并且它们的预测结果和真实结果y_test对比结果的score分数分别如下。score分数代表了预测的准确性,结果全部正确为1,完全错误则为0。由此我们可以看到结果是逐步提升的。

但是请注意,机器学习中交叉验证后的选择的模型预测性能未必一定高于没有经过交叉验证一次性选出的模型。因为机器学习做交叉验证的目的是为了即防止预测发生欠拟合也防止预测的过拟合。意思就是一次性选出的模型可能效果由于输入数据的随机性而波动很大,性能可能很好或者很差,通过交叉验证则尽可能折中的保证了模型的预测能力。
3.2 决策树
决策树(Decision Tree)是一种基本的分类与回归方法,当决策树用于分类时称为分类树,用于回归时称为回归树。决策树由结点和有向边组成。结点有两种类型:内部结点和叶结点,其中内部结点表示一个特征或属性,叶结点表示一个类。一般的,一棵决策树包含一个根结点、若干个内部结点和若干个叶结点。叶结点对应于决策结果,其他每个结点则对应于一个属性测试。
同样的,我们应用sklearn库建立一个决策树模型。其过程和3.1中建立逻辑回归模型的过程一致。
from sklearn.tree import DecisionTreeClassifier
model=DecisionTreeClassifier()
model.fit(x_train, y_train)
y_pred=model.predict(x_test)
score = model.score(x_test, y_test)
print("决策树对test集预测准确性:{:.2}".format(score))同样的,我们应用机器学习中的交叉验证方法建立一个决策树模型。和前述3.1中不同的是,这里我们用到了GridSearchCV函数,用于设置搜索模型参数。GridSearchCV()函数中的一个参数parameters可以是一个字典,这个字典包括针对不同模型的各种参数名、候选参数值列表。GridSearchCV()函数中还有一个参数是cv。cv参数指的是交叉验证次数,意思就是将train set训练集分成3份,每次其中2份作为train set训练集,另外1份作为validation set验证集。在建立了3个模型后,选择最优的作为最终模型。同样,在建立了模型后,对test set测试集进行了预测和比较,结果用score分数表示。
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
parameters = {'max_depth':range(3,20)}
cvmodel = GridSearchCV(model, parameters, cv=3)
cvmodel.fit(x_train, y_train)
tree_model = cvmodel.best_estimator_
y_pred=tree_model.predict(x_test)
score=tree_model.score(x_test, y_test)
print("交叉验证优化后决策树对test集预测准确性:{:.2}".format(score)) 这两个模型对test set测试集的预测结果和真实结果比对后,score分数都是0.97。
3.3 模型的预测能力评价
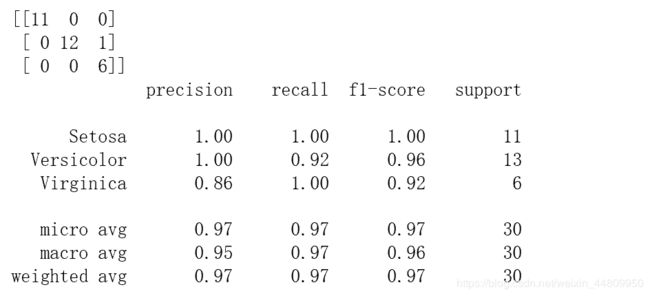
对于分类型输出的预测模型,score是一个非常笼统的指标,我们还需要更详细的指标来说明模型的预测效果,包括混淆矩阵(confusion matrix)和(precision),(recall), (f1-score)等指标。同样还是在sklearn库中,confusion_matrix和classification_report函数可以查看这些对预测进行评价的指标。
from sklearn.metrics import classification_report, confusion_matrix
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))对上述某个模型的混淆矩阵和评价指标显示结果如下图。混淆矩阵在图左上角的二维矩阵,是指预测值和真实值的比对。其他指标不在此给出详细解释。
4 连续型输出模型的建立
一个最基础的连续型输出模型就是前面3.1中所述的线性回归,当只有一个输入变量x对应一个输出变量y时,即我们在念中学的时候学到的用最小二乘法求解线性回归方程,也就是说在二维平面上用一条直线拟合所有数据。在机器学习算法中,则被称为线性回归模型。当然还有回归的决策树模型、回归的SVM模型等可以应用于这种输出为连续变量的场合。
同样的,对于连续型输出结果如iris鸢尾花中的"petal width",我们应用sklearn库建立一个线性回归模型。其过程和3.1中建立逻辑回归模型的过程一致。
X=pd.read_csv("D:\\iris.csv")
#将数据分成输入的X矩阵和输出的一列y
#X是iris数据库中其它三个参数
#y是iris数据库中petal width一列数据,连续变量
X.pop("class label")
y=X.pop("petal width")
#拟合数据在机器学习前要先进行标准化
ss = StandardScaler()
X = ss.fit_transform(X)
#拆分数据为train set训练集和test set测试集
x_train,x_test,y_train,y_test=model_selection.train_test_split(X,y,test_size=0.2,random_state=1)
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(x_train, y_train)
model.predict(x_test)
score=model.score(x_test, y_test)
print("1. 线性回归模型预测准确性:{:.2}".format(score))同样的,我们应用机器学习中的交叉验证方法建立一个线性回归模型。和前述3.1中不同的是,这里我们用到了GridSearchCV,用于设置搜索模型参数。在fit模型训练后,选择最优模型作为最终的决策树模型。在这里,GridSearchCV函数里的parameters参数并没有设置,仅仅设置了cv=5,意思就是将train set训练集在交叉验证过程中分成了5份,每次其中的4分作为train set,而剩下的1份作为validation set验证集。最后在5个模型中,选择最优模型作为最终的线性回归模型。
from sklearn.model_selection import GridSearchCV
parameters = {}
cvmodel = GridSearchCV(model, parameters, cv=5)
cvmodel.fit(x_train, y_train)
tree_model = cvmodel.best_estimator_
y_pred=tree_model.predict(x_test)
score=tree_model.score(x_test, y_test)
print("2. 交叉验证后线性回归test集预测准确性:{:.2}".format(score)) 线性回归模型和交叉验证后的线性回归模型对test set测试集的预测结果和真实结果比对后,score分数都是0.9。
4.3 模型的预测能力评价
同样,对于连续型输出的预测模型,score仍然是一个非常笼统的指标,我们还需要更详细的指标来说明模型的预测效果,R-Squared,Adjusted R-Squared, F Statistics,RMSE / MSE / MAE这些指标都可以用来评价连续型输出的预测效果。同样还是在sklearn库中,metrics函数可以查看这些评价指标。
from sklearn import metrics
print('Mean Absolute Error (MAE, 平均绝对误差): ', round(metrics.mean_absolute_error(y_test, y_pred),2))
print('Mean Squared Error (MSE,均方误差):', round(metrics.mean_squared_error(y_test, y_pred),2))
print('Root Mean Squared Error (RMSE,均方根误差):', round(metrics.mean_squared_error(y_test, y_pred)**0.5 , 2))5 机器学习的总结
5.1 sklearn的小结
sklearn中常用的模块有分类、回归、聚类、降维、模型选择、预处理。
- 分类:识别某个对象属于哪个类别,常用的算法有:SVM(支持向量机)、nearest neighbors(最近邻)、random forest(随机森林),常见的应用有:垃圾邮件识别、图像识别。
- 回归:预测与对象相关联的连续值属性,常见的算法有:SVR(支持向量机)、 ridge regression(岭回归)、Lasso,常见的应用有:药物反应,预测股价。
- 聚类:将相似对象自动分组,常用的算法有:k-Means、 spectral clustering、mean-shift,常见的应用有:客户细分,分组实验结果。
- 降维:减少要考虑的随机变量的数量,常见的算法有:PCA(主成分分析)、feature selection(特征选择)、non-negative matrix factorization(非负矩阵分解),常见#的应用有:可视化,提高效率。
- 模型选择:比较,验证,选择参数和模型,常用的模块有:grid search(网格搜索)、cross validation(交叉验证)、metrics(度量)。它的目标是通过参数调整提高精度。
- 预处理:特征提取和归一化,常用的模块有:preprocessing,feature extraction,常见的应用有:把输入数据(如文本)转换为机器学习算法可用的数据。
5.2 机器学习算法的小结
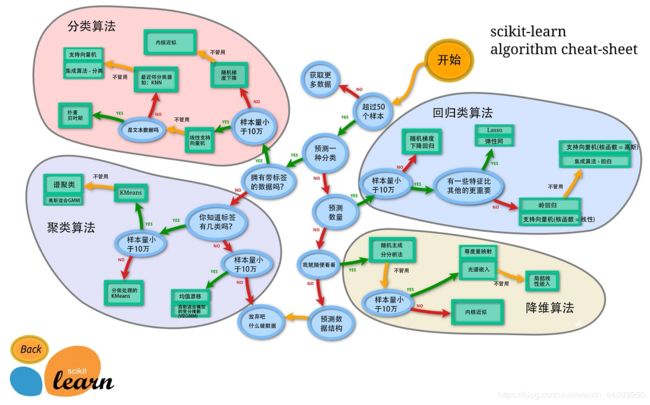 以下列出了sklearn库中大部分常用机器学习算法。应用的方法和流程基本同上,但是一定首先理解这些机器学习的算法才能够真正完成这些模型的预测能力。但是本文篇幅有限,在本文中对这些算法是没有介绍的。
以下列出了sklearn库中大部分常用机器学习算法。应用的方法和流程基本同上,但是一定首先理解这些机器学习的算法才能够真正完成这些模型的预测能力。但是本文篇幅有限,在本文中对这些算法是没有介绍的。
#支持向量机
from sklearn.svm import SVC
from sklearn.svm import SVM
#K领域
from sklearn.neighbors import KNeighborsClassifier
#K均值
from sklearn.cluster import KMeans
#主成分分析
from sklearn.decomposition import PCA
#lasso回归和岭回归
from sklearn.linear_model import Lasso,LassoCV,LassoLarsCV
from sklearn.linear_model import Ridge,RidgeCV
#朴素贝叶斯
from sklearn.naive_bayes import BernoulliNB
from sklearn.naive_bayes import GaussianNB
#集成学习
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import RandomForestClassifier