二进制与逻辑电路-CA
文章目录
- 计算机中数的表示
- 二进制“1”和“0”的表示
- 定点数的表示
- 浮点数的表示
- CMOS电路及工艺
- P管与N管
- 反相器
- N沟道MOS晶体管的示意图
- MOS晶体管的工作状态
- MOS基本工艺---光刻
- P衬底 nWell CMOS工艺
- 版图
- CMOS逻辑电路
- 基本逻辑电路
- 逻辑表达式
- CMOS组合电路的组成
- 真值表
- 逻辑图
- 时序逻辑电路:
- CMOS电路延迟原理
- 从Verilog到版图:
- Verilog语言:
- 从Verilog 到GDSII(以3-8译码器为例)
- 其它“0”和“1”的表示方法
计算机中数的表示
二进制“1”和“0”的表示
- 用电压的高低表示,半导体工艺,CMOS
- 用磁通量的有无表示,超导体工艺
- 用能级的高低表示,量子计算机
- 用基因序列表示,A, G, C, T, DNA计算机(本质也是二进制)
定点数的表示
- 原码:A=an-1 an-2…… a1 a0表示
- 最高位an-1为符号位,0表示正,1表示负;其它位an-2…… a1 a0表示数值。
- 原码的问题:加减法效率低,两个“0”
- 补码
- 本质:取模运算,不包含符号位的n位数,[Y]补=2^(n+1)+y,如-2%12=10
- 最高位an-1为符号位,0表示正,1表示负。

- 原码补码转换
最高位为0时,一样;
最高位为1时,最高位不变,其余位“按位取反加一”。 - 补码运算
A-B=A+B的负数=A+(B求补) - 加法溢出判断
A和B的最高位一样,且结果的最高位与A和B的最高位不一样。
浮点数的表示
-
由来
定点数表示范围有限,太大或太小的数都不能表示,且除法不精确 -
表示:IEEE 754标准
-
组成:符号位,阶码(exponent),尾数(fraction)
符号位:最高位
阶码(exponent):
i. 阶码的移码表示:底为2,2(阶码-偏移值)(阶码=指数+偏移)
ii. 范围:0
②. e=0:非规格化数或正负0
IEEE 754允许特别小的非规格化数:阶码能表示的最小指数为-126,那更小的呢?
此时阶码为0,尾数前的1不再加,即浮点数:0.f * 2^(e-126)。
例如: 2 − 128 = ( 0.01 ) 2 ∗ 2 − 126 2^{-128}=(0.01)_2 * 2^{-126} 2−128=(0.01)2∗2−126。
这样,就填补了最小规格化数和0之间的一段空隙。

尾数(fraction)
规格化表示,尾数的最高位总为1,因此可以不存;
例如:0.0012=1.02*2^-3(最高位1.0不存) -
单精度32和双精度64(扩展的单双精度)

-
IEEE 754 浮点格式参数

NaN(not a number)实现方式:
① Singaling NaN:抛出异常的方式,无需定义NaN宏;
②Quiet NaN:计算机出现异常时不抛出异常来中断程序,而是把结果表示为一个特殊值NaN,此时NaN宏会被定义;
CMOS电路及工艺
P管与N管
- CMOS:Complementary互补的 Metal金属 Oxide氧化物 Semiconductor半导体,有NMOS和PMOS两种;
- NMOS:(绘图时“无圈”)
门电压为高时导通,门电压为低时关闭;
门电压现在在不断降低,现在在1v左右,甚至更低;

- PMOS:(绘图时“有圈”)
门电压为高时关闭,门电压为低时导通;

反相器
由上下两个互补的PN管组成电路:
 这样设计上开下关,上关下开的好处是:没有直流电流,总有一头关死,能大幅降低功耗;
这样设计上开下关,上关下开的好处是:没有直流电流,总有一头关死,能大幅降低功耗;
取代了TTL和ECL;
N沟道MOS晶体管的示意图
-
工作原理
栅极不加电时,源漏之间是一对PN结,不导通;
栅极加电后,吸引电子到栅氧化层下面,形成导电的沟道。 (附近会形成耗尽区) -
示意图


-
有关Bulk
原理:空穴移动,加上电场,周围电子就会跑来填补空穴;
○ N型材料:通过掺杂而形成多余电子的材料;
○ P型材料:通过掺杂而形成多余空穴的材料;
(+:掺杂含量大,-:掺杂含量小) -
P管和N管沟道长度一定,但宽度不同(常为:2:1或1.5:1)

MOS晶体管的工作状态
 Vgs:产生耗尽区,形成桥梁;
Vgs:产生耗尽区,形成桥梁;
Vds:形成电压差,吸引电流从源端到漏端;
MOS基本工艺—光刻

P衬底 nWell CMOS工艺





版图
- 反相器版图

- NAND2 和 NOR2 的电路及版图

CMOS逻辑电路
基本逻辑电路
组合逻辑电路:电路中没有存储单元,逻辑电路的输出完全由当前的输入决定
○ 单输入单输出有四种电路:输出恒0,输出恒1,输出反向,直通;
时序逻辑电路:电路中有存储单元,逻辑电路的输出由原来状态和当前的输入决定
○ 单输入单输出有无数种电路;
逻辑表达式
- Boolean代数的基本操作:与(*)、或(+)、非(^)
- 基本定律:

- CMOS中基本门:非、与非、或非

| 非门 | 于非门 | 或非门 | |
|---|---|---|---|
| 晶体管数 | 2 | 2 | 4 |
因此,逻辑表达式最好写成上述操作的组合。如,((AB)^(CD))=AB+C*D
CMOS组合电路的组成
- 用NMOS组成正逻辑
串联表示与;并联表示并; - 用PMOS组成反逻辑
(A*B)=A+^B,P管并联;
(A+B)=A*^B,P管串联; - 正反逻辑串联
由于N网络导通时接地,因此输出是反向的。
例: ~(A&B | C&D)=(AB)*(CD)=(A+B)*(C+D)

注意:串联级数不能太大,一般不超过四级,因为串联电阻大,延迟就大;
真值表
对于每一种可能的输入组合,给出输出值。对于一个 n输入的电路,有2^n项。
- 卡诺图:
便于逻辑表达式优化的输入输出关系表示。
在图中相临的“1”或“X”合并成一项。
例:一位全加器

逻辑图
直接用门及互连表示输入输出的逻辑关系;
- 与门,或门画法:

- 例:一位全加器

对应的CMOS电路:

补充问题:有关晶体管数目
上述逻辑图中,标明的数字即每个门所需的晶体管数,最终一位全加器共需要56个晶体管;

(相当于每一个输入都需要2个晶体管)
时序逻辑电路:
-
特点:时序逻辑电路内部有存储单元,其行为由输入和内部单元的值共同决定
-
组成结构

-
分类
同步时序逻辑电路:所有存储单元的变化由时钟统一触发。功耗大,简单;(计算机常用)
异步时序逻辑电路:低功耗,复杂; -
RS触发器:其他寄存器的基础

例题:加深理解


-
D触发器
D门闩(D锁存器)

工作原理:由时钟C电平进行控制,电平高时输入,低时保持
-C为0时:R和S都为1,输出保持原有状态。
-C为1时:输出和输⼊D相同,相当于直通。
D触发器:由两个D锁存器串联形成

工作原理:通过时钟C跳沿(非电平)来锁存数据:
-C=1时,锁1直通,锁2保持;
-C=0时,锁1保持,锁2直通;
-C从1->0时,把D的值锁存;
触发器延迟=Setup+CLK-to-Q
三个重要时间参数:Setup、Hold、CLK-to-Q
– Hold:时钟下降后数据变化不影响第一级D-Latch(可负)
• 在本电路中为0
– Setup:时钟沿下降之前保证数据已采到第一级D-latch(可负)
• 1级反相器 + 3级与非门(Q端从1变0)
– Clock-to-Q:时钟沿下降后引起Q的变化
• 1级反相器(C反相器与D方向器并行)+ 3级与非门
(上述只是初略计算,具体的值需要仿真)
EDFF电路:带输入使能的D触发器(只有E有效,才能输入)
 例题:加深理解
例题:加深理解


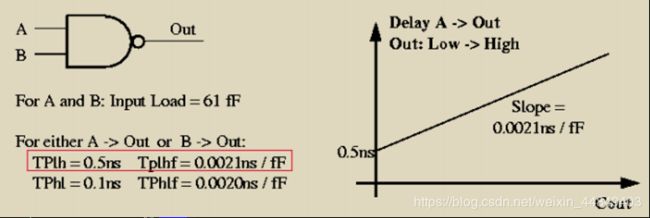
CMOS电路延迟原理
输入电压变化时,输出电压的变化不是瞬时完成的;

(1)out:0->1,通过P管电阻充电(P管电阻+输出电容决定延迟)

(2)out:1->0,通过N管电阻放电至地(N管电阻+输出电容决定延迟)

(3)CMOS电路延迟模型
1)与延迟有关的因素:输入transition、内部延迟、输出负载
2)CMOS延迟=自身延迟(ns)+负载延迟(ns/fF*负载)
– 负载包括:下一级负载、连线延迟等
– ns是电容单位,fF是负载单位
3)例:二输入与非门
4)例:全加器

(4)标准单元延迟的计算
①深亚微米电路中连线延迟占总延迟的大部分;
②连线延迟的计算是一个不断迭代求精的过程,
– 综合时根据负载个数估计线长,非常初略
– 布局后根据距离估计线长,比较准确了
– 布线后进一步考虑具体连线、互相干扰、过孔等精确连线信息
(5)降低延迟的方法
①通过结构设计降低延迟:
– 如流水级的划分、CACHE读出和命中比较是否在同一级、浮点流水级设计、Pipeline stalling signal 的设置
②逻辑设计:
– 减少门的级数;

– 负载平衡:CMOS的负载能力较低,分推
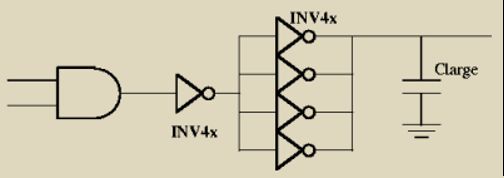
(如多选一通路的选择次序、加法器算法、流水级间的局部调整等)
③物理设计
– 动态电路、clock skew、clock jitter、transition time、布局布线
从Verilog到版图:
Verilog语言:
-
组合逻辑:assign

-
时序逻辑:always (@posedge clock)

-
模块调用

-
实例一:四位计数器

从Verilog 到GDSII(以3-8译码器为例)
- 3-8译码器

- Verilog

- 网表

- 布线后

- 版图

其它“0”和“1”的表示方法
1.方法
- 用磁通量的有无表示,超导体工艺
- 用能级的高低表示,量子计算机
- 用基因序列表示,A, G, C, T, DNA计算机
2.超导计算—RSFQ技术
(1)基本原理:超导(4-5K)环中的磁通量具有量子化特性,设计电路使超导环中的磁通量只变化一个磁通量,用磁通量的有无来表示二进制数位的“1” 和 “0”。磁通量的变化由外加电流控制。
(2)特点:
①. 工作频率高–100 GHz (实验室已达370 GHz, 1.5P 工艺)。
②. 每个门的功率0.1PW。
③. 工艺比较简单。
3.量子计算
(1)量子力学特性:
量子叠加态(superposed state)
□ 量子器件的信息位称为量子位(qubit),它可处于叠加态。
□ 叠加态可以是 “0” 也可以是 “1”。
□ 通过测量或与其他物体发生相互作用可呈现出 “0” 态或 “1” 态。
□ 由于每个量子位都可以是 “0” 或 “1”, n 个量子位就可以表示 2n 个 n 位数。
□ 常规计算机的一个 n 位存储单元只能存放一个 n 位数,而 n 个量子位可以存放 2n 个 n 位数,可以实现超大容量的存储器。
量子纠缠态(entangled state)
□ 用作运算的多个量子位还应处于纠缠态,即所有量子位的状态紧密相关。
□ 当测量某个量子位时,会影响其他量子位的测量结果。
量子并行 (quantum parallelism)
□ 计算 f(x) 时,可同时计算出 x 的所有值的 f(x)。所以不需要多次循环,也不需要多个处理机并行计算。
(2)应用领域
大数 N 因子分解:令 n = log2N , 经典算法所需步骤为 2^(n/2),Shor 量子并行算法所需步骤为 Poly(n),Poly(n) 为 n 的多项式。该算法将 NP 问题转换为 P 问题。
搜寻算法:在 N 个元素的集合中搜寻某个元素,经典算法搜寻 N/2 次后,找到的概率为 1/2, Grover 量子搜寻算法则只需 N^(1/2) 次,即可达到同样概率。
量子系统模拟:常规计算机不可能有效地模拟量子系统,因为它们的物理机制不同。用常规计算机模拟量子系统,所需的信息量和时间都远大于模拟经典系统。量子计算可用于研究高温高密度等离子体、量子色动力学、晶体固态模型、分子行为的量子模型等。
(3)物理实现
量子位的实现:任何两态的量子系统都可作为量子位,如原子的能级、电子或原子核的自旋、光子的正交偏振态等。
量子计算机的实现:有多种可能,包括:核磁共振(用磁场中的原子核自旋作为量子位)、离子阱(用被俘获在线性量子阱中的离子作为量子位)、硅基半导体量子器件(杂质核自旋与电子自旋相互作用)等。
(4)存在问题
□ 量子位的缠结态容易崩溃,位数越多,越难实现。
□ 量子器件之间的连接。
□ 为了维持量子逻辑的一致性,量子系统和环境的隔离。
□ 设备缺陷所引起的逻辑错误
4.分子计算机
(1)原理:
DNA 计算机利用 DNA 分子保存信息。DNA 分子是由 A, G, C, T 四种核苷酸(碱基)组成的序列。不同的序列可用来表示不同的信息。通过 DNA 分子之间的一系列生化反应来进行运算,可产生表示结果的 DNA 分子。已解决了 7 个城市的旅行售货员等问题。
(2)优点:
□ 高度并行:所有 DNA 分子同时运算。
□ 能耗低:半导体计算机的 10^10 之一。
□ 存储密度大:磁存储器的 10^12 倍。
(3)缺点:
□ 生化反应慢、操作有随机性、DNA 分子容易水解、DNA 分子之间难以通信。