【目标追踪】基于高斯混合学习的视频背景减法
基于高斯混合学习的视频背景减法
- (一)数学概念:
- 1.1 单高斯模型:
- 1.2 样本分布的参数估计:
- 1.3 高斯混合模型:
- (二)算法基础:
- 2.1 最大似然估计:
- 2.1.1 最大似然估计的基本过程:
- 2.1.2 最大似然估计的局限:
- 2.2 最大期望算法(EM算法):
- 2.2.1 EM算法的基本概念:
- 2.2.2 EM算法的实现——初始化:
- 2.2.3 EM算法的实现——E-Step:
- 2.2.4 EM算法的实现——M-Step:
- (三)高斯混合学习实现视频背景建模
- 3.1 论文出处:
- 3.2 基本思想:
- 3.3 程序框图:
- 3.4 python复现代码:
- 3.4.1 建模程序
- 3.4.2 调用程序
- 3.5 OpenCV接口:
- (四)查看检测效果:
论文地址:
《Effective Gaussian Mixture Learning for Video Background Subtraction》
检测效果:
前面我们讲了【目标追踪】python帧差法原理及其实现,【目标追踪】三帧差法原理及实现,【目标追踪】python背景模型减除法原理及其实现,但它们有个共同的问题就是往往会出现空洞、鬼影等现象,而且不能很好地适应环境变化;因此这里我们介绍一个基于高斯混合学习的视频背景减法:
(一)数学概念:
1.1 单高斯模型:
高斯模型是一种常用的变量分布模型,一维高斯分布公式如图:

为了便于描述和应用,常将正态变量作数据转换。将一般正态分布转化成标准正态分布:
X=(x1,x2,…xn) 的多维高斯分布如图:
比如二维高斯分布长这个样子,可以近似描述一组二维数据的分布:

1.2 样本分布的参数估计:
对于一组数据(可以认为是我们视频中输入的图像):

如果我们尝试使用单高斯模型(二维)去拟合这组数据,比如极大似然估计或者矩估计,得到的结果可能是这样的:

其中椭圆越往中心,离散点出现的概率就应该越高。
但是实际上我们观察到,这组数据并不是很符合这样的分布概率,因为似乎这组数据有多个概率中心:

因此这时我们认为,单高斯模型并不很好地拟合这组数据。
1.3 高斯混合模型:

对于复杂的图像,一般是多峰的。通过将直方图的多峰特性看作是多个高斯分布的叠加,可以解决图像的分割问题。
因此我们可以定义高斯混合模型,来拟合这样的分布:
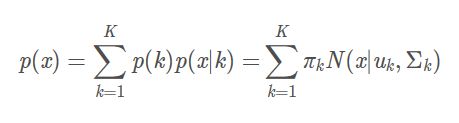
其中:
- K 是表示混合模型的数目;
- p(k) 是表示第k个模型的权重;
- p(x|k) 是表示第k个模型的概率密度函数;
- Σp(k) = 1;
即高斯混合模型实质上就是不同的单高斯多维分布函数的加权组合:

(二)算法基础:
2.1 最大似然估计:
假设我们手里现在有一个样本,这个样本服从某种分布,我们可以观察通过抽样得到的样本进行分析,从而估计出一个较准确的相关参数;这种通过观测来评估模型参数的方法称为最大似然估计。
2.1.1 最大似然估计的基本过程:
其基本过程如下:
- 构造对似然函数L(θ),其中θ是分布函数的参数(未知),p是该样本观察值的概率:

- 对最大似然函数取对数:
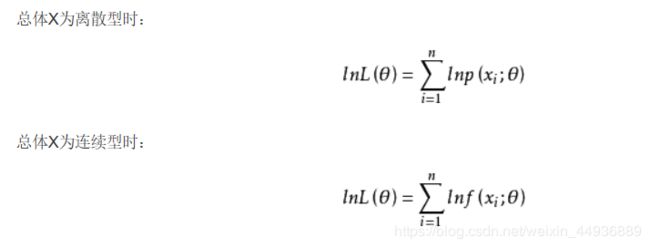
- 求导数并令之为0(多个未知参数时求偏导):

解方程得到的θ即为未知参数的最大似然估计。
2.1.2 最大似然估计的局限:
上面介绍了最大似然估计,可这种方法适用于不存在隐藏变量的概率模型,即所有样本的观测量都需要是已知的。

如果属于多个类别的样本混在了一起(如图),不同类别样本的参数不同,现在的任务是从总体中抽样,再通过抽样数据估计每个类别的分布参数;
这时就无法通过最大似然估计来估计每个分布模型的参数了(因为抽样得到的每个样本所属的分布未知),也就没有办法使用最大似然估计来预测我们的高斯混合模型了。
2.2 最大期望算法(EM算法):
这样我们就陷入了两难的境地:只有知道了哪些抽样样本是属于同一个分布的,我们才能根据最大似然函数估计这个分布的参数;同样,只有知道了不同类别样本的分布参数,才有可能判断现某个样本到底属于哪个类别的可能性更大。
这时就可以使用最大期望算法来解决;

2.2.1 EM算法的基本概念:
EM算法的标准计算框架由E步(Expectation-step)和M步(Maximization step)交替组成,算法的收敛性可以确保迭代至少逼近局部极大值;
直白地说,既然我们不知道样本分布和分布参数,不如:
(一)在抽样之前先给每种样本分类(即隐藏变量)依照经验赋予一个初始分布,依照分布求取隐藏变量的期望;
(二)再根据这个期望(相当于分类)计算每种分布的最大似然值,根据这个值重新计算隐藏分布的期望;

如此两步循环往复,等到隐藏变量的期望和最大似然值达到一个稳定的值时,就可以说我们得到了样本的分布;
那么这两步操作就分别叫做E步(Expectation-step)和M步(Maximization step),先初始化分布参数,再循环至收敛:
- E步:根据当前的参数值,计算样本隐藏变量的期望;
- M步:根据当前样本的隐藏变量,求解参数的最大似然估计;
2.2.2 EM算法的实现——初始化:
我们首先根据经验,确定使用K个(通常为5~7)个高斯模型来组成我们的高斯混合模型;对每个高斯模型,使用一组数据(μ0,k, Σ0,k,π0,k)来初始化分布函数。
其中:μ代表高斯分布的权重,Σ表示高斯分布标准差,π表示第k个高斯分布在K个高斯分布组成的混合模型中的权重。
2.2.3 EM算法的实现——E-Step:
对于样本Y,yt表示第t个观察的抽样样本):
![]()
对于每个样本,我们用γt,k(1或0)表示这个样本是否属于第k个分类(注意我们只有采样数据yt,γ未知):

为了求这组样本的概率,需要分两步:
- 第t个样本由第k个分类产生的概率是多少?
- 如果第t个样本由第k个分类产生,那么第k类产生第t个样本的概率为多少?
这样我们就得到了EM算法中的最大似然函数:

求对数得:
 这样我们只需要求得一组参数的期望( μ ^ \hat{μ} μ^, Σ ^ \hat{Σ} Σ^, π ^ \hat{π} π^),使得最大似然函数的对数对这些参数的偏导为0;但是由于隐藏参数γ的存在,我们无法最大化lnp,因此就需要先对γ做一个估计:
这样我们只需要求得一组参数的期望( μ ^ \hat{μ} μ^, Σ ^ \hat{Σ} Σ^, π ^ \hat{π} π^),使得最大似然函数的对数对这些参数的偏导为0;但是由于隐藏参数γ的存在,我们无法最大化lnp,因此就需要先对γ做一个估计:
- 如果是第一次运行E-Step,则使用初始化的高斯混合分布函数确定yt属于的概率最大的分类,从而预估隐藏参数γ;
- 如果是第 t 次运行E-Step,则使用经过t-1次迭代、参数为(μt-1,k, Σt-1,k,πt-1,k)高斯混合分布函数确定隐藏参数γ。
但是由于即使划分了样本并得到了γ的估计值,γ依旧不是(或者说不一定是)样本的真实分类,因此我们不最大化lnp(y,γ∣μ,Σ,π)(也无法最大化它),而是最大化Q函数:

其中E就是γ的估计:
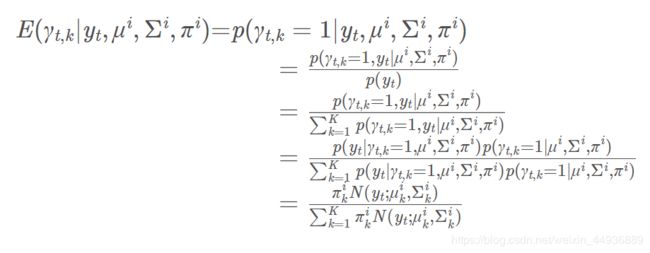
构造Q函数的意义就在于:
有了对于γ的估计之后,Q函数只和样本有关(最大似然函数还与γ有关),而不再含有隐变量,从而使得最大化Q函数成为可能。
2.2.4 EM算法的实现——M-Step:
对Q函数进行最大化,就可以得到下一次迭代的模型参数

即让Q函数对参数求偏导,并令其等于零得到参数的估计值:

(三)高斯混合学习实现视频背景建模
3.1 论文出处:
《Effective Gaussian Mixture Learning for Video Background Subtraction》
3.2 基本思想:
高斯混合学习实现视频背景建模的基本思想就是,对视频每个点(随时间更新)使用K高斯模型建立模型,其分布认为符合高斯混合分布:
- 对于背景点,其像素值p分布在高斯模型的均值附近( | p - μ |<=2.5 σ) ;
- 对于运动目标点,其像素值p偏离均值(| p - μ |>2.5 σ);
- 同时,运动的物体也可能成为新的背景(比如一辆车停下前认为是运动目标,停下后认为是新的背景),因此我们需要在背景分布的均值中加入运动物体的部分权重α×p,α称为学习率;
- 对于像素值连续分布在均值附近的高斯模型,我们认为能够较好符合期望分布,更新其均值和标准差,标准差变小,并且其权重在混合高斯模型中增加;
- 对于像素值分布不均匀的高斯模型,使其权重减小,并且我们认为可能需要更新分布;
- 如果某一点均不符合K个模型的分布,我们认为此时混合模型已经不能很好地描述背景,因此需要删除权重最小的分布,根据此时的像素点均值增加新的分布;

3.3 程序框图:
论文中也给出了程序框图:

其中normalize的作用是使混合模型的权重和归一;
3.4 python复现代码:
3.4.1 建模程序
注意python的for循环效率很低,远远不能满足实时监控的需求,因此这里使用numpy进行操作(但依然会有许多冗余操作不可避免):
import numpy as np
class GaussianDistribution(object):
def __init__(self, model_nums, w, gray, sigma):
height, width = gray.shape[:2]
tmp = np.empty((height, width), dtype=np.float)
self.w = [] # 高斯模型权重
for _ in range(model_nums):
tmp.fill(w)
self.w.append(tmp)
self.sigma = [] # 高斯模型标准差
for _ in range(model_nums):
tmp.fill(sigma)
self.sigma.append(tmp + np.random.random(tmp.shape) * sigma/10)
self.u = [] # 高斯模型均值
for _ in range(model_nums):
self.u.append(gray + np.random.random(tmp.shape) * 8)
# mask
self.q = []
for _ in range(model_nums):
self.q.append(np.zeros(gray.shape, dtype=np.float))
class Mog(object):
def __init__(self, model_num=5, alpha=2e-3, init_sigma=50, init_w=0.05, T=2.5):
self.model_num = model_num
self.alpha = alpha
self.init_sigma = init_sigma
self.min_sigma = init_sigma / 3
self.init_w = init_w
self.T = T
self.init = True
self.Foreground = None
def apply(self, gray):
if self.init:
self.init_Gaussian(gray)
self.init = False
for m in range(self.model_num):
mask = np.abs(
gray - self.models.u[m]) < self.T * self.models.sigma[m]
self.models.q[m] = mask.astype(np.float)
mask = np.where(mask)
# 更新参数
self.update_parameter(mask, gray, m)
# 舍取模型
self.update_model(gray)
background = np.zeros(gray.shape)
background[self.Foreground] = 255
return background
def update_model(self, gray):
pixel_scores = np.sum(
np.stack(self.models.q, axis=-1), axis=-1
)
non_pos_index = np.where(pixel_scores == 0)
self.Foreground = non_pos_index
if non_pos_index[0].shape[0] == 0:
return None
stack_w = np.stack(self.models.w, axis=-1)[non_pos_index]
min_arg = np.argmin(stack_w, axis=-1)
for i in range(min_arg.shape[0]):
y = non_pos_index[0][i]
x = non_pos_index[1][i]
m = min_arg[i]
self.models.w[m][y, x] = self.init_w
# self.models.u[m][y, x] = 0.2 * \
# gray[y, x] + 0.8 * self.models.u[m][y, x]
self.models.u[m][y, x] = self.init_w * gray[y, x] + \
(1 - self.init_w) * self.models.u[m][y, x]
self.models.sigma[m][y, x] = self.init_sigma
return None
def update_parameter(self, mask, gray, m):
self.models.w[m] = (1 - self.alpha) * \
self.models.w[m] + self.alpha * self.models.q[m]
# 模型u和sigma更新
u = (1 - self.alpha) * \
self.models.u[m][mask] + self.alpha * gray[mask]
self.models.u[m][mask] = u
sigma = self.models.sigma[m][mask]
sigma = (1 - self.alpha) * np.square(sigma) + \
self.alpha * np.square(gray[mask] - self.models.u[m][mask])
sigma = np.sqrt(sigma)
index = np.where(sigma < self.min_sigma)
sigma[index] = self.min_sigma
self.models.sigma[m][mask] = sigma
def init_Gaussian(self, gray):
self.models = GaussianDistribution(
self.model_num, self.init_w, gray, self.init_sigma)
if __name__ == "__main__": mog = Mog()3.4.2 调用程序
import cv2
import numpy as np
from nms import py_cpu_nms
from time import sleep
from writing import Mog
class Detector(object):
def __init__(self, name='my_video', frame_num=10, k_size=7, color=(0, 255, 0)):
self.name = name
self.color = color
def catch_video(self, video_index=0, min_area=360):
cap = cv2.VideoCapture(video_index) # 创建摄像头识别类
if not cap.isOpened():
# 如果没有检测到摄像头,报错
raise Exception('Check if the camera is on.')
self.frame_num = 0
self.mog = Mog()
while cap.isOpened():
mask, frame = self.gaussian_bk(cap)
_, cnts, _ = cv2.findContours(
mask.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
bounds = [cv2.boundingRect(
c) for c in cnts if cv2.contourArea(c) > min_area]
for b in bounds:
x, y, w, h = b
thickness = (w*h)//min_area
thickness = thickness if thickness <= 3 else 3
thickness = thickness if thickness >= 1 else 1
cv2.rectangle(frame, (x, y), (x+w, y+h), self.color, thickness)
# 在window上显示背景
# cv2.imshow(self.name+'_bk', background)
cv2.imshow(self.name, frame) # 在window上显示图片
cv2.imshow(self.name+'_frame', mask) # 边界
cv2.waitKey(10)
if cv2.getWindowProperty(self.name, cv2.WND_PROP_AUTOSIZE) < 1:
# 点x退出
break
if cv2.getWindowProperty(self.name+'_frame', cv2.WND_PROP_AUTOSIZE) < 1:
# 点x退出
break
# 释放摄像头
cap.release()
cv2.destroyAllWindows()
def gaussian_bk(self, cap, k_size=3):
catch, frame = cap.read() # 读取每一帧图片
if not catch:
if self.is_camera:
raise Exception('Unexpected Error.')
else:
print('The end of the video.')
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
mask = self.mog.apply(gray).astype('uint8')
# mask = cv2.medianBlur(mask, k_size)
return mask, frame
if __name__ == "__main__":
detector = Detector(name='test')
detector.catch_video('./test.avi', min_area=360)
3.5 OpenCV接口:
如果仅要求实用而不深入研究的话,也可以直接调用opencv的接口:
import cv2
import numpy as np
from nms import py_cpu_nms
from time import sleep
class Detector(object):
def __init__(self, name='my_video', frame_num=10, k_size=7, color=(0, 255, 0)):
self.name = name
self.color = color
def catch_video(self, video_index=0, min_area=360):
cap = cv2.VideoCapture(video_index) # 创建摄像头识别类
if not cap.isOpened():
# 如果没有检测到摄像头,报错
raise Exception('Check if the camera is on.')
self.frame_num = 0
self.mog = cv2.createBackgroundSubtractorMOG2()
while cap.isOpened():
sleep(0.1)
mask, frame = self.gaussian_bk(cap)
_, cnts, _ = cv2.findContours(
mask.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
bounds = [cv2.boundingRect(
c) for c in cnts if cv2.contourArea(c) > min_area]
for b in bounds:
x, y, w, h = b
thickness = (w*h)//min_area
thickness = thickness if thickness <= 3 else 3
thickness = thickness if thickness >= 1 else 1
cv2.rectangle(frame, (x, y), (x+w, y+h), self.color, thickness)
# 在window上显示背景
# cv2.imshow(self.name+'_bk', background)
cv2.imshow(self.name, frame) # 在window上显示图片
cv2.imshow(self.name+'_frame', mask) # 边界
cv2.waitKey(10)
if cv2.getWindowProperty(self.name, cv2.WND_PROP_AUTOSIZE) < 1:
# 点x退出
break
if cv2.getWindowProperty(self.name+'_frame', cv2.WND_PROP_AUTOSIZE) < 1:
# 点x退出
break
# 释放摄像头
cap.release()
cv2.destroyAllWindows()
def gaussian_bk(self, cap, k_size=3):
catch, frame = cap.read() # 读取每一帧图片
if not catch:
if self.is_camera:
raise Exception('Unexpected Error.')
else:
print('The end of the video.')
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
mask = self.mog.apply(gray).astype('uint8')
mask = cv2.medianBlur(mask, k_size)
return mask, frame
if __name__ == "__main__":
detector = Detector(name='test')
detector.catch_video('./test.avi', min_area=360)